
compiler-theory-5
生成目标程序
目标代码生成
任务
-
代码生成器在编译系统中的位置
graph LR A(源程序)-->B(前端)-->|中间代码|C{优化器} -->|中间代码|D(代码生成器)-->E(目标程序) F(符号表)-->B F(符号表)-->C F(符号表)-->D -
代码生成器的输入
-
源程序的中间表示
-
线性表示(波兰式)
-
三地址码(四元式)
-
栈式中间代码(P-CODE/Java Bytecode)
-
图形表示
-
-
符号表信息
-
-
代码生成器对输入的要求
-
编译器前端已经将源程序扫描、分析和翻译成足够详细的中间表示
-
中间语言中的标识符表示为目标机器能够直接操作的变量(位、整数、浮点数、指针等)
-
完成了必要的类型检查,类型转换/检测操作已经加入到中间语言的必要位置
-
完成语法和必要的语义检查,代码生成器可以认为输入中没有与语法或语义错误
-
-
目标程序的种类
-
汇编语言
- 生成宏汇编代码,再由汇编程序进行编译,连接,从而生成最终代码(.S/.ASM文件)
-
包含绝对地址的机器语言
-
执行时必须被载入到地址空间中(相对)固定的位置
-
EXE (MS-WIN)、COM (MS-WIN)、A.OUT (Linux)
-
-
可重定位的机器语言
- 一组可重定位的模块/子程序可以用连接器装配后生成最终的目标程序(.obj/.o文件组)
- 可动态加载的模块/子程序(DLL/.SO动态连接库)
-
-
面向特定的目标体系结构生成目标代码
-
目标体系结构可以是:
-
某种微处理器,如X86、MIPS、ARM等
-
某种虚拟机或运行时系统,如Java虚拟机、C#运行时系统、P-code虚拟机等
-
-
虚拟机:
-
P-code栈式虚拟机
-
虚拟机的代码需要解释器解释或者即时编译器编译后才能运行
-
-
-
运行栈结构与地址空间
graph LR A(全局和静态变量)-->B(代码区)-->C(运行栈)-->D(内存堆)
代码空间
-
代码区
-
存放目标代码
-
静态数据区
-
全局变量
-
静态变量
-
部分常量,例如字符串
-
动态内存区
-
也被称为内存堆Heap
-
程序员管理:C、C++
-
自动管理(内存垃圾收集器):Java、Ada
-
程序运行栈
-
子程序/函数运行时所需的基本空间:活动记录
-
函数的返回地址
-
全局寄存器的保存区
-
临时变量的保存区
-
未分配到全局寄存器的局部变量的保存区
-
其他辅助信息的保存区
-
-
函数调用的上下文现场
- 由调用方保存的一些临时寄存器
- 被调用方保存的一些全局寄存器
-
进入子程序/函数时分配,地址空间向下生长(从高地址到低地址)
-
从子程序/函数返回时,当前运行栈将被废弃
-
递归调用的同一个子程序/函数,每次调用都将获得独立的运行栈空间,从而保证了递归程序和多线程程序的正确运行。
面向微处理器体系结构的代码生成技术
-
主要内容:
-
目标代码地址空间的划分,目标体系结构上存贮单元(如寄存器和内存单元)的分配和指派
-
从中间代码(或者源代码)到目标代码转换过程中所进行的指令选择
-
面向目标体系结构的优化
-
-
技术挑战:
-
在内存找到目标,并最大限度的利用目标体系结构特点(存储层次、缓存、指令架构)
-
这一过程对程序员“透明”
-
指令集架构
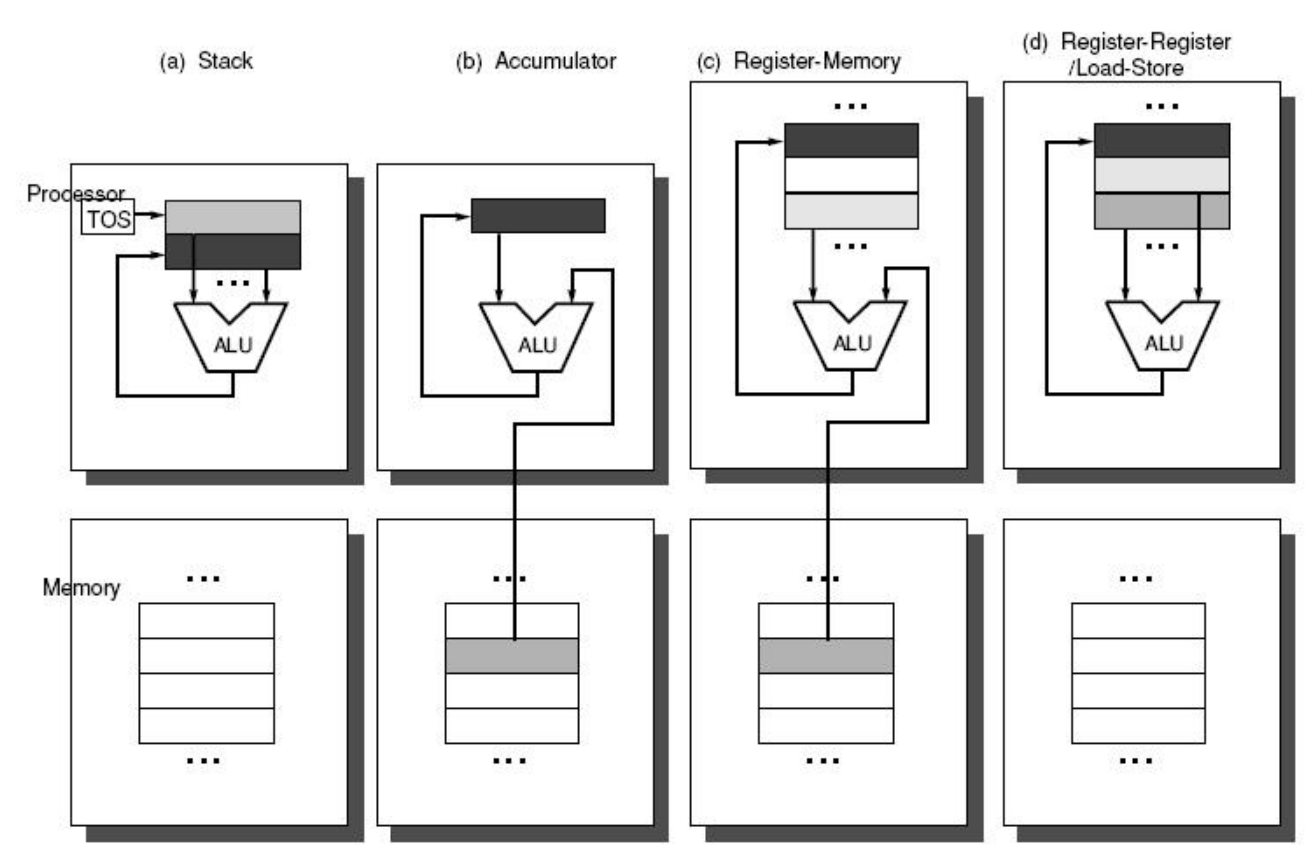
栈式指令集架构
- 类似于P-code和Java虚拟机
1 | D=(A*B)+(B*C) |
累加器式指令集架构
1 | C=A+B |
- 代码短了,开销不一定小。直接访问内容
寄存器指令集架构
- 区别: 是否可以直接内存寻址
- 共性: 内部有多个寄存器可以直接作为ALU指令的任一操作数
- 优点: 减少内存访问,减少指令数
寄存器-内存指令集架构
1 | D=(A*B)+(B*C) |
寄存器-寄存器指令架构
1 | D=(A*B)+(B*C) |
寄存器分配(Register Allocation)
-
寄存器通常分为
-
通用寄存器
-
X86:EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP, etc
-
ARM: R0~R15, etc
-
-
专用寄存器
- X86:浮点寄存器栈, etc
-
-
通用寄存器
-
保留寄存器
- 例如,X86的ESP栈指针寄存器,ARM的返回寄存器LR
-
调用方保存的寄存器——临时寄存器
-
X86:EAX, ECX, EDX
-
ARM:R0~R3, R12, LR
-
-
被调用方保存的寄存器——全局寄存器
-
X86:EBX, ESI, EDI, EBP (ESP为运行栈寄存器,不参与寄存器分配)
-
ARM:R4~R11
-
-
-
寄存器特点:
-
访问快
-
有些寄存器和指令执行有关系
-
数量少,分配策略
-
-
寄存器分配的目标:
-
将变量与寄存器之间建立对应关系
-
从程序优化的角度来说,我们希望所有指令的执行都仅在寄存器中完成
-
-
全局寄存器分配:
-
“全局”相对于“基本块”而言,不是“程序全局”
-
全局寄存器分配的对象主要是函数的局部变量,包括函数入口参数。
-
-
分配原则
-
优先分配给跨基本块仍然活跃的变量,尤其是循环体内最活跃的变量
-
局部变量参与全局寄存器分配
- 为了线程安全,全局变量/静态变量一般不参与全局寄存器分配。
-
寄存器分配:优化
-
改进目标:
-
尽可能映射更多的变量到寄存器
-
减少内存读写次数
-
-
本质问题:当活跃变量数量超过寄存器个数时,如何做出取舍
寄存器分配:引用计数
-
引用计数
-
通过统计变量在函数内被引用的次数,并根据被引用的特点赋予不同的权重,最终为每个变量计算出一个唯一的权值
-
根据权值的大小排序,将全局寄存器依次分配给权值最大的变量
-
-
原则:如果一个局部变量被访问的次数较多,那么它获得全局寄存器的机会也较大
出现在循环,尤其是内层嵌套循环中的变量的被访问次数应该得到一定的加权
- 分配算法:如果有N个全局寄存器可供分配,则前N个变量拥有全局寄存器,其余变量在程序运行栈(活动记录)分配存贮单元
**寄存器分配:**图着色算法
-
算法目的:
-
给定冲突图,给出寄存器分配方案
-
基本思想:如果可供分配 k个全局寄存器,就尝试用 k 种颜色给冲突图着色
-
(原则:两个冲突变量不能着相同颜色)
-
-
算法步骤:
- 通过数据流分析,构建变量的冲突图
-
什么是变量的冲突图?
-
它的结点是待分配全局寄存器的变量
-
当两个变量中的一个变量在另一个变量定义(赋值)处是活跃的,它们之间便有一条边连接。所谓变量i在代码n处活跃,是指程序运行时变量i在n处拥有的值,在从n出发的某条路径上会被使用(活跃变量分析)。
-
直观的理解:
-
有边相连的变量,它们无法共用一个全局寄存器,或者同一存贮单元,否则程序运行将可能出错
-
无连接关系的变量,即便它们占用同一全局寄存器,或同一存贮单元,程序运行也不会出错
-
-
-
尝试用k种颜色给该冲突图着色(k个全局寄存器可用)

-
一种启发式图着色算法:Chaitin-Briggs算法
- 步骤1、找到第一个连接边数目小于K的结点,将它从图G中移走,形成图G’
- 步骤2、重复步骤1,直到无法再从G’中移走结点
- 步骤3、在图中选取适当 的结点,将它记录为“不分配全局寄存器”的结点,并从图中移走
- 步骤4、重复上述步骤,直到图中仅剩余1个结点
- 步骤5、按照结点移走的反向顺序将点和边添加回去,并分配颜色

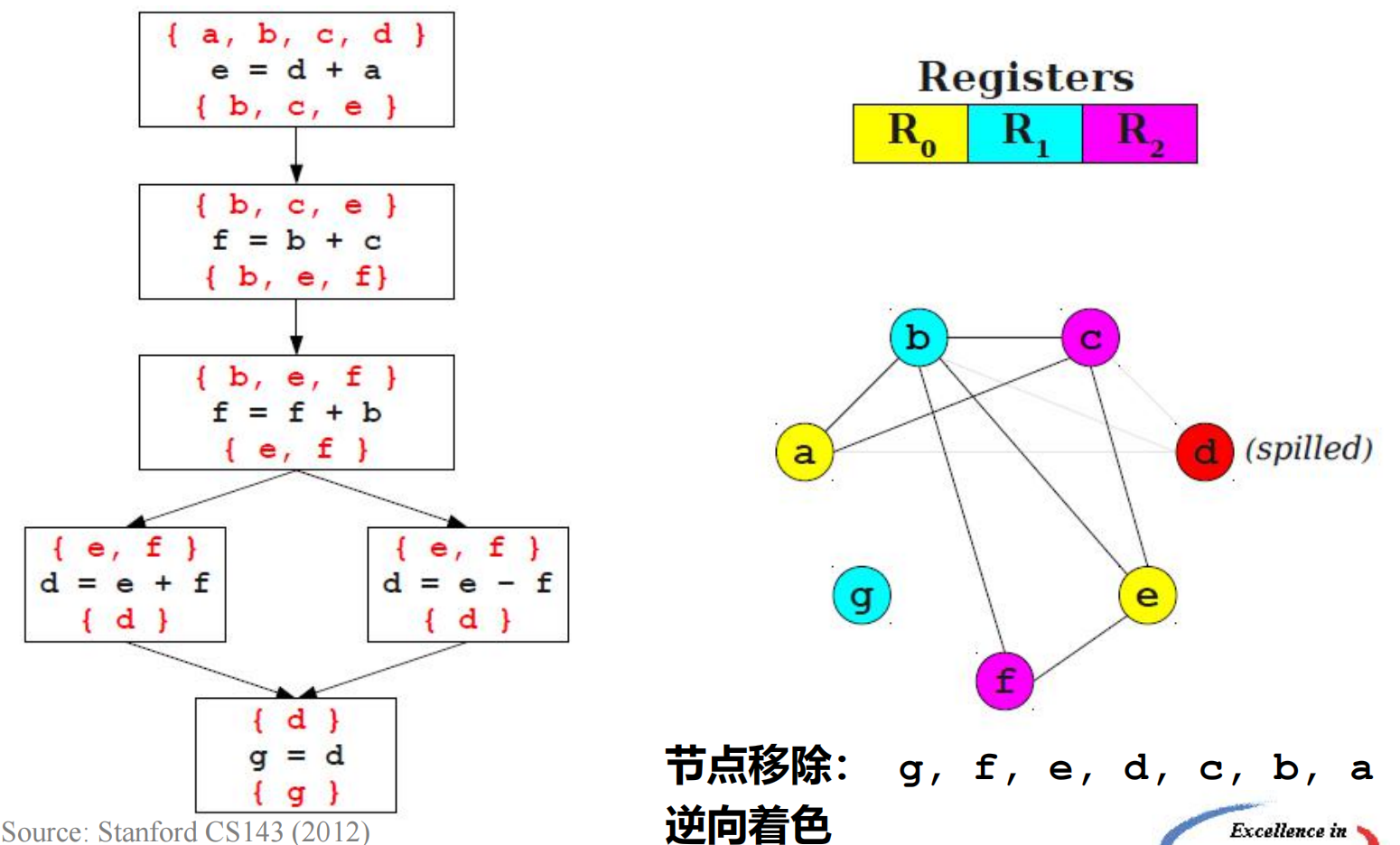
寄存器分配:线性扫描

寄存器分配:临时寄存器分配
-
临时寄存器的生存范围
-
不超越基本块
-
不跨越函数调用
-
-
临时寄存器的管理方法
- 寄存器池
-
临时寄存器池:基本思想 FIFO
-
进入基本块: 清空临时寄存器池
-
全局变量、局部变量使用临时寄存器: 向临时寄存器池申请
-
申请处理:
-
有空闲寄存器:分配申请,做标识
-
没有空闲寄存器:(启发式)选取一个在即将生成代码中不会被使用的寄存器写回相应的内存空间,标识该寄存器被新的变量占用,返回该寄存器
-
-
退出基本块(或函数调用发生前): 将寄存器池中的值写回内存,清空临时寄存器池
- Title: compiler-theory-5
- Author: Charles
- Created at : 2023-07-20 11:48:09
- Updated at : 2024-06-04 19:25:05
- Link: https://charles2530.github.io/2023/07/20/compiler-theory-5/
- License: This work is licensed under CC BY-NC-SA 4.0.


