
CUDA_note_4
CUDA应用程序编程接口(API)
C 语言的扩展
CUDA 编程接口的目标是为熟悉C 语言的用户提供一个相对简单的途径来编写设备执行程序。 它包括:
-
一个小的C 语言扩展集,允许程序员专注于在设备执行的原代码的部分;
-
一个runtime 库分成:
- 一个主机组件,它在主机上运行并且提供函数来控制和访问一个或多个计算设备;
- 一个设备组件,它在设备运行并且提供特定设备的函数;
- 一个公共的组件,它提供内置矢量类型和主机与设备编码都支持的C 标准库的一个子集。
应该强调的是,只有来自C 标准库的函数支持在设备上运行,是由公共Runtime 的组件提供的函数。
C 语言扩展集
C 语言的扩展是四重的:
-
函数类型限定句指定一个函数是否执行在主机或者执行在设备,和是否从主机或者从设备上调用;
-
变量类型限定句指定设备上一个变量的内存位置;
-
一个新的指令指定一个来自主机的kernel 如何在设备上执行 ;
-
四个内置的变量指定栅格和块的维数,还有块和线程的指标 。
每个包含CUDA 语言扩展的源文件必须通过CUDA 编译器nvcc 编译
函数类型限定词
| 函数类型限定词 | 执行 | 调用 |
|---|---|---|
| __device__ | 设备 | 设备 |
| __global__ | 设备 | 主机 |
| __host__ | 主机 | 主机 |
如果没有任何限定词默认为__host__
相关限定
- __host__ 限定词也可以用于与 __device__ 限定词的组合,这种的情况下,这个函数是为主机和设备双方编译。
- __device__ 和 __global__ 函数不支持递归。
- __device__ 和 __global__ 函数不能声明静态变量在它们体内。
- __device__ 和 __global__ 函数不能有自变量的一个变量数字。
- __device__ 函数不可能取得它们的地址; 另一方面,函数指向 __global__ 函数是支持的。
- 不能一起使用 __global__ 和 __host__ 限定词。
- __global__ 函数必须有void 的返回类型。任何调用到一个 __global__ 函数必须指定它的执行配置,对一个 __global__ 函数的调用是同步的,意味着在设备执行完成前返回。
- __global__ 函数参数目前是通过共享内存到设备的,并且被限制在256 个字节。
变量类型限定词
__device__
__device__限定词声明驻留在设备上的一个变量。 最多的一个其它类型限定词被定义在下面的三项里,可以与__device__一起共同用于进一步指定变量归属在哪些内存空间(即 __device__ 定义的内存空间失效)。如果它们都不存在,这个变量:
-
驻留在全局内存空间。
-
具有应用的生存期。
-
从栅格内所有线程和从主机通过runtime 库是可访问的。
__constant__
__constant__ 限定词,与 __device__ 一起随机使用,声明一变量:
-
驻留在常量内存空间。
-
具有应用的生存期。
-
从栅格内所有线程和从主机通过runtime 库的是可访问的。
__shared__
__shared__ 限定词,与 __device__ 一起选择使用,声明一个变量:
-
驻留在线程块的共享内存空间中。
-
具有块的生存期。
-
只有块之内的所有线程是可访问的。
在线程中共享的变量有完全的顺序一致性。只有执行过一个 __syncthreads() 函数,从其他线程的写才保证可见。除非变量被定义为可挥发的,否则只要前一个状态到达,编译器将自由的优化共享内存中的读写。
相关限定
-
这些限定词不允许的一个函数之内的 struct 和 union 成员,形式参数和局部变量在主机上执行。
-
__shared__ 和 __constant__ 变量隐含了静态存储。
-
__device__,__shared__ 和 __constant__ 变 量 不 能 被 用 extern 关 键 字 定 义 为 外 部 使 用 。
-
__device__ 和 __constant__ 变量只允许在文件范围。
-
__constant__ 变量不能从设备上赋值,仅可以通过主机 runtime 函数从主机上赋值。
-
__shared__ 变量不能作为它们声明的一部分得到初始化。
执行配置
所有 __global__ 函数的调用必须指定执行配置。 执行配置定义了通常在设备执行的函数的栅格和块的维数,同样相关的stream。它通过在函数名称和用括弧括起来的参数表之间插入表达式的形式 <<< Dg, Db, Ns, S>>> 来指定,如:
-
Dg 是类型dim3 并且指定栅格的维数和大小,这样Dg.x * Dg.y 等于被发送的块的数量;
-
Db 是类型dim3 并且指定每个块的维数和大小,这样Db.x * Db.y * Db.z 等于每个块的线程数量;
-
Ns 是类型size_t 并且指定在共享内存中的字节数量,这个共享内存是静态分配的内存之外的动态分配每个块的内存; 这个动态分配的内存是被任何一个声明为外部数组的变量使用的,Ns 是一个默认为0 的可选参数。
-
S 是类型cudaStream_t 并且指定相关的stream;S 是一个默认为0 的可选数。
执行配置的函数参数在调用前将被评估,且通过共享内存传至设备。 如果Dg 或Db 大于设备允许的最大值(,或者Ns 的值大于((设备共享内存的最大值)减去(共享内存中的静态分配的内存,函数参数,和执行配置))的值,函数将无法被调用。
内置变量
| 内置变量 | 简介 |
|---|---|
| gridDim | 这个变量是类型dim3 并且包含栅格的维数。 |
| blockIdx | 这变量是类型uint3 并且包含栅格之内的块索引。 |
| blockDim | 这变量是类型dim3 并且包含在块的维数。 |
| threadIdx | 这变量是类型uint3 并且包含块之内的线程索引。 |
相关限定
-
内置变量不允许取得任何地址。
-
不允许赋值到任何内置变量。
NVCC编译
NVCC可以直接参考gcc和g++理解即可,使用起来也十分类似
nvcc 是编译CUDA 代码过程的编译器驱动程序的简称:它提供简单和熟悉的命令行选项,并且通过调用实施不同编译阶段汇集的工具来执行它们。
nvcc 的基本工作流程在于从主机代码中分离出设备代码,并且编译设备代码成为一个二进制格式的对象或cubin 对象。生成的主机代码输出,作为使用其他工具提交编译的C 代码,或者作为在最后编译阶段期间直接调用主机编译器的对象代码。
编译器处理CUDA 源文件的前端部分完全遵照C++的语法。主机代码完全支持C++。但是设备代码只支持C++中的C 子集 ;在基本块中的C++的特性,比如:classes, inheritance, 或者变量的声明是不支持的。作为使用C++语法的结果,void 指针(例如,通过 malloc() 返回)在没有使用typecast 的情况下不能分配给non-void 的指针。
NVCC 编译器侦测
-
__noinline__ 使用
-
默认下,__device__函数总是inline 的。__noinline__ 函数可以作为一个非inline 函数的提示。函数本身必须放在调用的文件中,编译器不能保证函数带有指针参数和函数带有大量参数表的 __noinline__ 的限定词正常工作。
-
#pragma unroll
-
默认下,编译器为已知的行程计数展开小型循环。 #pragma unroll 可以侦测和控制任何展开的循环。它必须放在这个循环之前,并只作用于这个循环。同时,可以通过一个参数指定循环可以展开多少次。 如果 #pragma unroll 后面没有附值,当行程计数为常数时,循环完全展开,否则不会展开。
-
例如:
1
2
For (int i = 0; i < n; i++)
-
公共Runtime 组件
内置矢量类型
内置矢量类型主要分为两类。
第一类是比如 char1, uchar1, char2, uchar2, char3, uchar3, char4, uchar4, short1, ushort1,short2, ushort2, short3, ushort3, short4, ushort4, int1, uint1, int2, uint2, int3,uint3, int4, uint4, long1, ulong1, long2, ulong2, long3, ulong3, long4, ulong4,float1, float2, float3, float4这些矢量类型是源于基本的整型和浮点类型。它们是结构和第1,第2,第3,还有第4 个组件可通过域 x, y, z, 和 w 分别访问。例如可以通过赋值 (x,y) 创建一个类型int2 的矢量。
1 | int2 make_int2(int x,int y); |
第二类是dim3类型,这个类型是基于uint3 的用于指定维数的整型矢量类型。当定义一个类型dim3 的变量时,所有剩余的非特指的组件初始化为1。
数学函数
加法和乘法为IEEE 兼容的,所以拥有最大误差0.5 ulp。它们通常被合并成一个乘-加指令(FMAD)。
求浮点数运算到整型时,使用 rintf() ,而不是roundf()。因为roundf() 映射8 个指令序列,而rintf()只映射一个指令。truncf(),ceilf(),和floorf() 同样也只映射一个指令。
CUDA runtime 库也支持整型的min()和max(),同样映射一个指令。
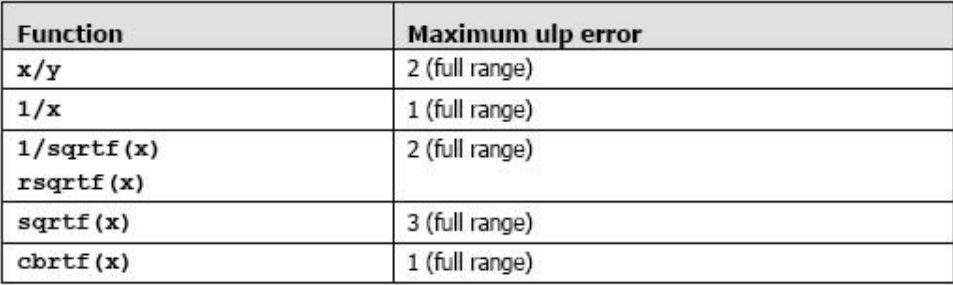
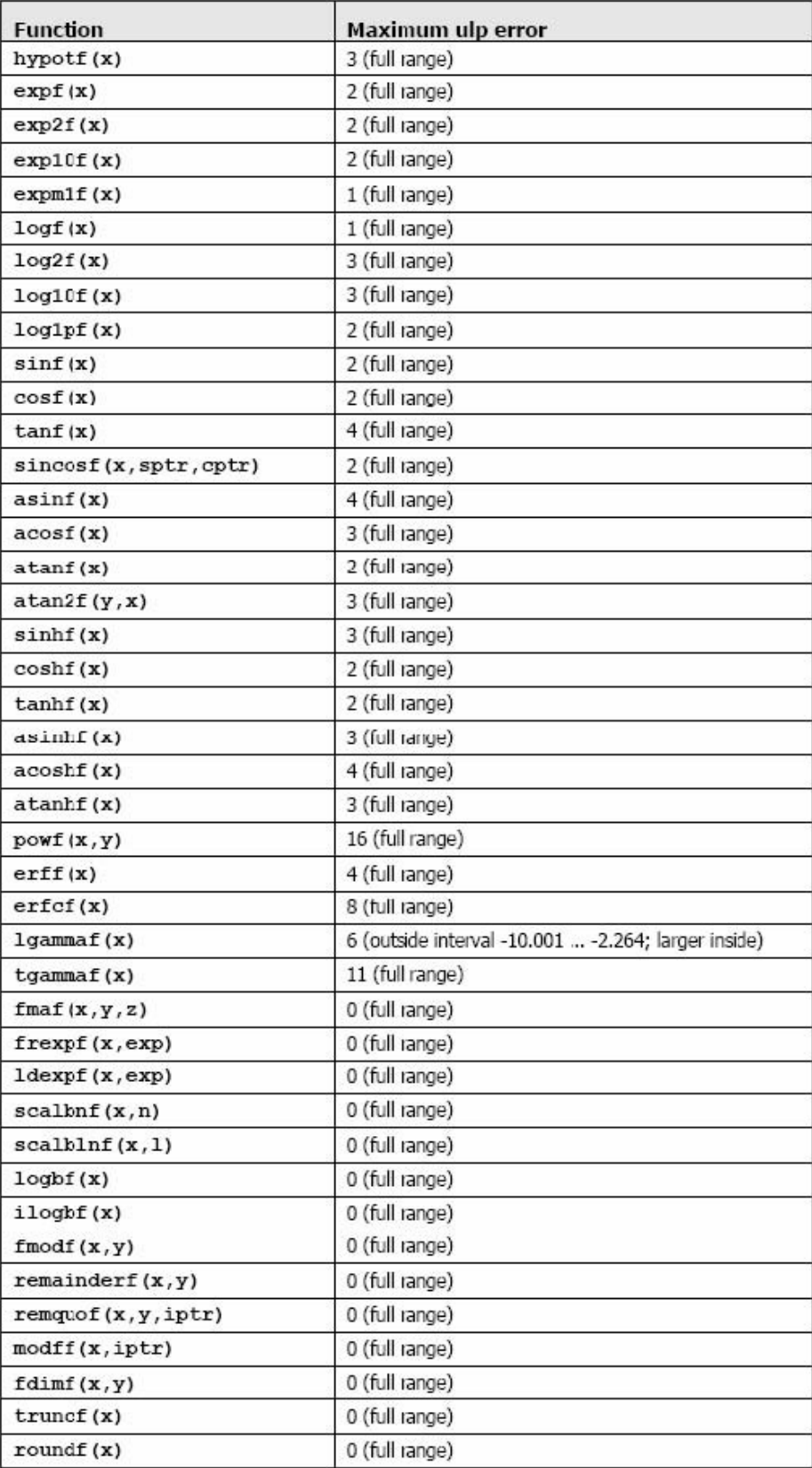
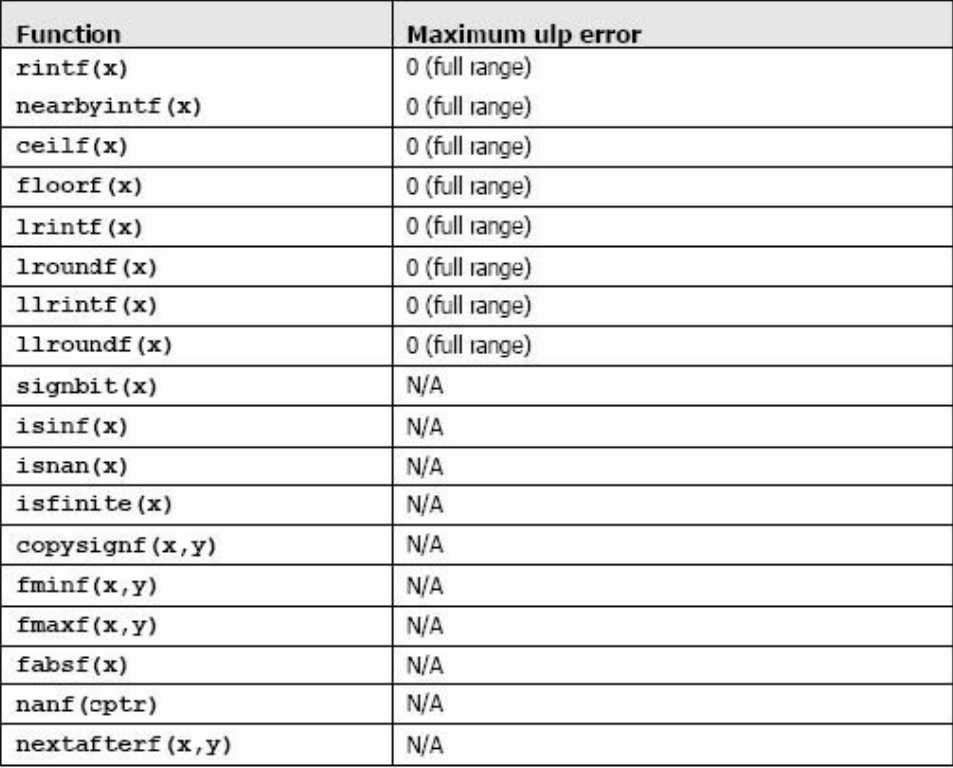
在主机上执行时,一个给定的函数使用C runtime 执行。
时间函数
1 | clock_t clock(); |
每个时钟周期递增下的计数器的返回值。
在 kernel 开始和的结束时采样这个计数器,取得这个二个采样的差,并且记录着每线程每时钟周期通过设备完全地执行线程取得的结果,而不是设备执行线程指令时实际花费的时钟周期数量。前着的数字是比后者更大是因为线程是被切成时间段的。
纹理类型
CUDA 支持硬件纹理渲染的一个子集,通过GPU 为图形使用纹理内存。通过纹理内存读取数据相比全局内存有很多性能上的优势,纹理内存通过一个叫texture fetches 的设备函数从kernel 读取。
Texture reference 定义纹理内存的哪一个部分被fetch 。在被kernel 使用之前,它必须通过主机的runtime 函数绑定到一些内存区域。一些texture reference 也许绑定在同一个纹理下或者纹理映射的内存中。
Texture reference 有一些属性。其中的一个就是,它可以通过一个纹理坐标指定纹理是否使用一维数组寻址,或者通过两个纹理坐标指定纹理是否使用二维数组寻址。数组的元素被简称为texels,texture elements 的缩写。 另一个属性是,为纹理的fetch 定义输入输出数据类型。
设备Runtime 组件
设备runtime 的组件只能用于设备函数。
数学函数
某些函数在设备Runtime 的组件中有低准确性而更快速的版本, 它有相同的加__前缀(例如 __sin(x) )。
编译器有一个选项(-use_fast_math)来强制每个函数编译到它的不太准确的副本。
同步函数
1 | void __syncthreads(); |
在一个块内同步所有线程。一旦所有线程到达了这点,恢复正常执行。
__syncthreads() 通常用于调整在相同块之间的线程通信。当在一个块内的有些线程访问相同的共享或全局内存时,对于有些内存访问潜在着read-after-write, write-after-read, 或者 write-after-write 的危险。这些数据危险可以通过同步线程之间的访问得以避免。
__syncthreads() 允许放在条件代码中,但只有当整个线程块有相同的条件贯穿时,否则代码执行可能被挂起或导致没想到的副作用。
类型转换函数
| 函数 | 后缀指定IEEE-754 的舍入模式 |
|---|---|
| rn | 求最近的偶数 |
| rz | 逼近零 |
| ru | 是向上舍入(到正无穷) |
| rd | 是向下舍入(到负无穷) |
1 | int __float2int_[rn,rz,ru,rd](float); |
用指定的舍入模式转换浮点参数到整型。
1 | Unsignde int __float2unit_[rn,rz,ru,zd](float); |
用指定的舍入模式转换浮点参数到无符号整型。
1 | float __int2float_[rn,rz,ru,rd](int); |
用指定的舍入模式转换整型参数到浮点数。
1 | float __int2float_[rn,rz,ru,rd](unsigned int); |
用指定的舍入模式转换无符号整型参数到浮点数。
Type Casting 函数
1 | float __int_as_float(int); |
在整型自变量上执行一个浮点数的type cast,保持值不变。例如,__int_as_float(0xC0000000) 等于 -2 。
1 | int __float_as_int(float); |
在浮点自变量上执行的一个整型的type cast ,保持值不变。例如,__float_as_int (1.0f)等于0x3f800000。
纹理函数
设备内存纹理操作
设备内存中的纹理通过 tex1Dfetch() 函数访问.
1 | template<class Type> |
这些函数通过纹理坐标x 拾取线性内存中绑定到texture reference texRef 的区域。对于整型来说,不允许纹理过滤和选择寻址模式。对于这些函数,可能需要将整型数升级到32-bit 浮点数。 下面的函数展示了2-和4-元组的支持:
1 | float4 tex1Dfetch( |
通过纹理坐标x 拾取线性内存中绑定到texture reference texRef 的区域.
CUDA 数组纹理操作
从CUDA 数组中的纹理通过 tex1D() 或 tex2D() 函数访问:
1 | template<class Type, enum cudaTextureReadMode readMode> |
这些函数通过纹理坐标x 和y 拾取CUDA 数组中绑定到texture reference texRef 的区域。Texture reference 的编译时(固定的)和运行时(可变的)的属性决定了,坐标如何被解释,纹理拾取时将有哪些处理发生,和纹理拾取返回的值.
原子函数
原子函数在全局内存中的一个32-bit 字中执行一个读-修改-写的原子操作。例如,atomicAdd() 在全局内存中的同一个地址读取一个32-bit 字,加一个整型进去,并写回结果到同一个地址。所谓“原子”就是保证操作不会干扰其它线程。在操作完成之前,其它线程也无法访问这个地址。
原子操作只能用于32-bit 有符号和无符号的整型数。
主机Runtime 组件
主机Runtime 的组件只能被主机函数使用。
它提供函数来处理:
-
设备管理
-
Context 管理
-
内存管理
-
编码模块管理
-
执行控制
-
Texture reference 管理
-
OpenGL 和Direct3D 的互用性
它由二个API 组成:
-
一个低级的API 调用CUDA 驱动程序API
-
一个高级的API 调用的CUDA runtime API ,在CUDA 驱动程序API 之上运行的API
这些API 是互相排斥:一个应用程序应该选择其中之一来使用。
参考资料
[1]. CUDA C++ Programming Guide
- Title: CUDA_note_4
- Author: Charles
- Created at : 2023-07-28 07:27:56
- Updated at : 2026-05-11 20:11:12
- Link: https://charles2530.github.io/2023/07/28/cuda-note-4/
- License: This work is licensed under CC BY-NC-SA 4.0.