
CUDA_note_3
CUDA硬件实现
本文介绍了使用CUDA的一些硬件方面的限制
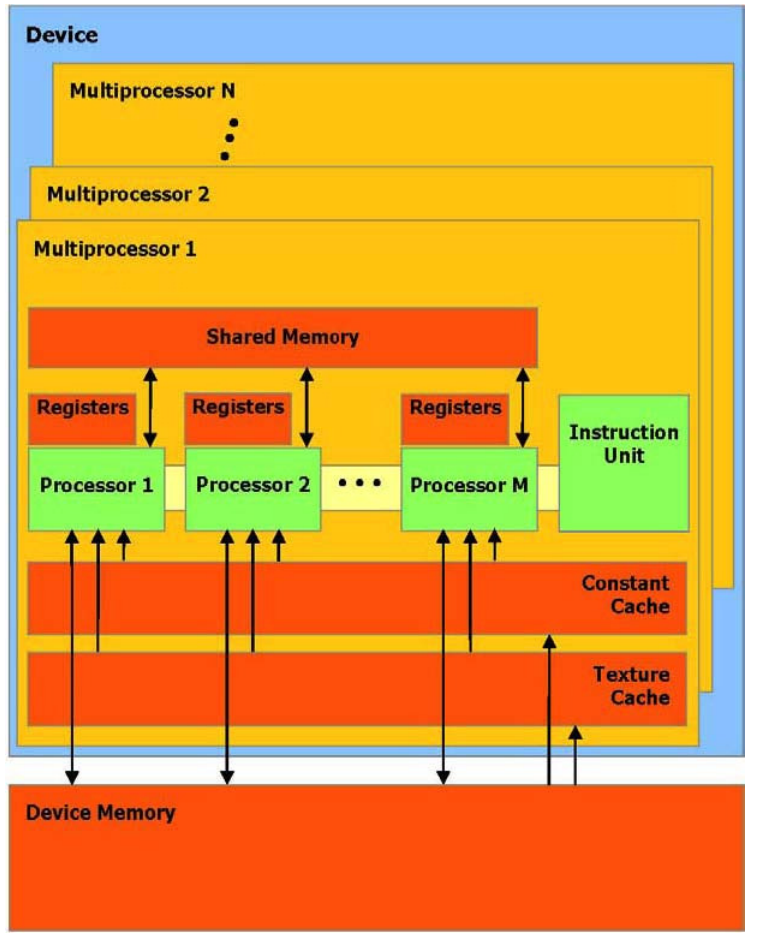
一组带有on-chip 共享内存的SIMD 多处理器
设备可以被看作一组多处理器,每个多处理器使用单一指令,多数据架构(SIMD) :在任何给定的时钟周期内,多处理器的每个处理器执行同一指令,但操作不同的数据。
每个多处理器使用四个以下类型的on-chip 内存:
-
每个处理器一组本地32 位寄存器。
-
并行数据缓存或共享内存,被所有处理器共享实现内存空间共享。
-
通过设备内存的一个只读区域,一个只读常量缓冲器被所有处理器共享。
-
通过设备内存的一个只读区域,一个只读纹理缓冲器被所有处理器共享, 本地和全局内存空间作为设备内存的读写区域,而不被缓冲。
每个多处理器通过纹理单元访问纹理缓冲器,它执行各种各样的寻址模式和数据过滤。
执行模式
一个线程块栅格是通过多处理器规划执行的。每个多处理器一个接一个的处理块批处理。一个块只被一个多处理器处理,因此可以对驻留在on-chip 共享内存中的共享内存空间形成非常快速的访问。
一个批处理中每一个多处理器可以处理多少个块,取决于每个线程中分配了多少个寄存器和已知内核中每个时钟需要多少的共享内存,因为多处理器的寄存器和内存在所有的线程中是分开的。如果在至少一个块中,每个多处理器没有足够的寄存器或共享内存可用,那么内核将无法启动。
线程块在一个批处理中被一个多处理器执行,被称作active。每个active 块被划分成为SIMD 线程组,称为warps; 每一条这样的warp 包含数量相同的线程,叫做warp 大小,并且在SIMD 方式下通过多处理器执行; 线程调度程序周期性地从一条warp 切换到另一条warp,以达到多处理器计算资源使用的最大化。
块被划分成为warp 的方式总是相同的; 每条warp 包含连续的线程,线程索引从第一个warp 包含着的线程0 开始递增。
一个多处理器可以处理并发地几个块,通过划分在它们之中的寄存器和共享内存。更准确地说,每条线程可使用的寄存器数量,等于每个多处理器寄存器总数除以并发的线程数量,并发线程的数量等于并发块的数量乘以每块线程的数量。
在一个块内的warp 次序是未定义的,但通过协调全局或者共享内存的存取,它们可以同步的执行。如果一个通过warp 线程执行的指令写入全局或共享内存的同一位置,写的次序是未定义的。
在一个线程块栅格内的块次序是未定义的,并且在块之间不存在同步机制,因此来自同一个栅格的二个不同块的线程不能通过全局内存彼此安全地通讯。
多设备
为一个应用程序使用多GPU 作为CUDA 设备,必须保证这些GPU 是一样的类型。如果系统工作在SLI 模式下,那么只有一个GPU 可以作为CUDA 设备,由于所有的GPU 在驱动堆栈中被底层的融合了。SLI 模式需要在控制面板中关闭,这样才能事多个GPU 作为CUDA 设备。
模式切换
GPU 指定一些DRAM 来存储被称作primary surface 的内容,这些内容被用于显示输出。如果用户改变显示的分辨率或者色深,那么primary surface 的存储需求量将改变。如果模式切换增加了primary surface 的内存空间,系统将占用CUDA 指定的内存空间,导致程序崩溃。
参考资料
[1]. CUDA C++ Programming Guide
- Title: CUDA_note_3
- Author: Charles
- Created at : 2023-07-27 21:18:02
- Updated at : 2026-05-11 20:11:12
- Link: https://charles2530.github.io/2023/07/27/cuda-note-3/
- License: This work is licensed under CC BY-NC-SA 4.0.