
parallel_programming_theory
并行程序设计
并行计算基础
传统的并行计算
- 程序在一台只有一个CPU的电脑上运行
- 问题被分解成离散的指令序列
- 指令被一条接一条的执行
- 在任何时间CPU上最多只有一条指令在运行
并行计算
- 调用多个CPU
- 一个问题分解成多个部分,可以被同时解决
- 每一部分被细分成一系列指令
- 每一部分的指令可以在不同的CPU上同时执行
并发vs并行
- 并发:一个逻辑流的执行在时间上与另一个流重叠,在某时间段内可能是交替执行,也可能是同时执行。
- 并行:两个逻辑流在任意时刻同时执行
从并行计算的角度,并行是并发的真子集。注意:某些情况下,并发特指交替执行。

并行vs分布式
并行与分布式的涵义不同,但没有非常明显的界限
- 并行计算中,线程(或者进程)间通信往往通过共享内存,处理器间的交互一般很频繁。
- 分布式计算,进程间的通信依赖网络,例如,利用多台机器或者处于不同地理位置的机器进行计算。
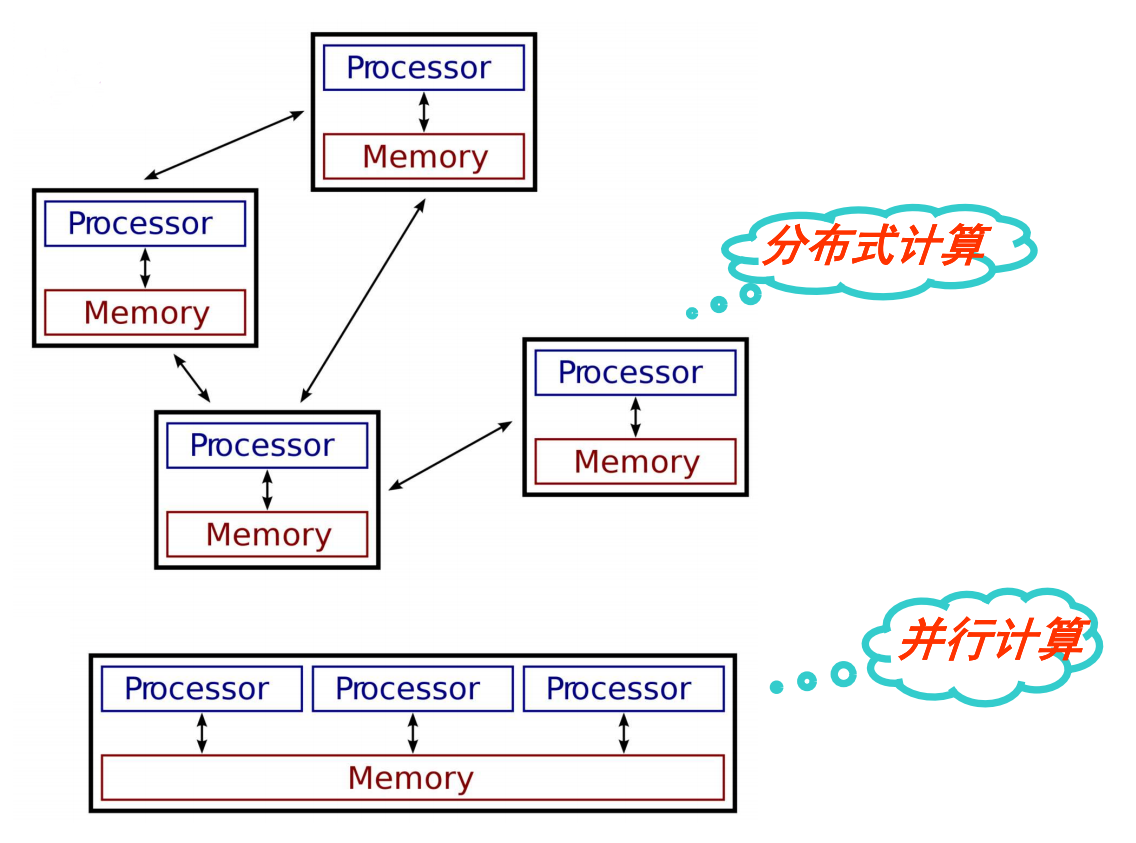
并行计算的应用
- 历史上并行计算被认为是“高端计算”,并用于为复杂的科学计算和真实世界的工程问题建模。
- 今天商业应用是推动并行计算机发展的更大的推动力,这些应用需要用复杂的方法处理大量数据。
并行的层次
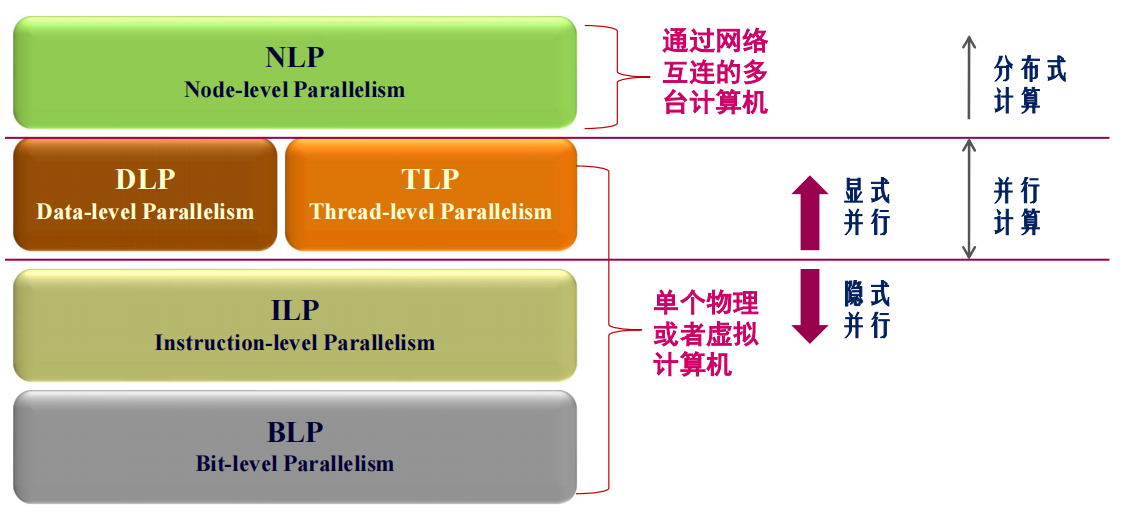
并行计算机分类
| 单指令 (Single Instruction) |
多指令 (Multiple Instruction) |
|
|---|---|---|
| 单数据 Single Data |
SISD | MISD |
| 多数据 Multiple Data |
SIMD | MIMD |
-
SISD
- 串行计算机
- 一个时钟周期,只有一条指令被执行,只有一个数据流作为输入。
-
SIMD
- 并行计算机
- 一个时钟周期,所有执行单元执行相同的指令,每个执行单元处理不同的数据元素。比较适合向量计算。
-
MISD
- 并行计算机
- 一个时钟周期,单个数据流同时被多个执行单元执行。
-
MIMD
- 并行计算机
- 多个处理单元都是根据不同的控制流程执行不同的操作,处理不同的数据。目前多数计算机属于此类。
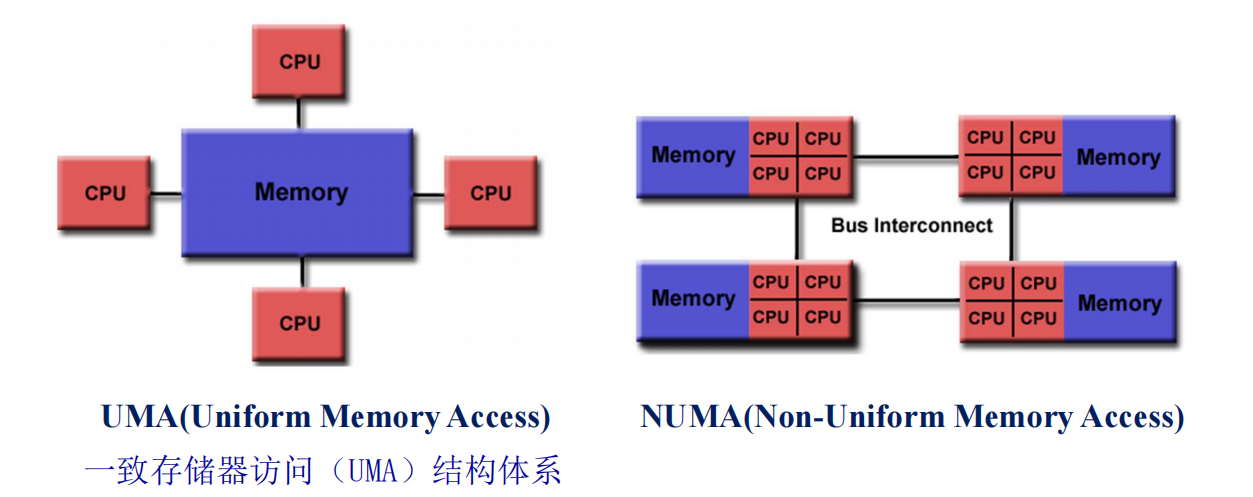
根据访问内存的方式,可将并行计算机分为共享内存、分布式内存、分布式共享内存:
共享内存(Shared Memory)
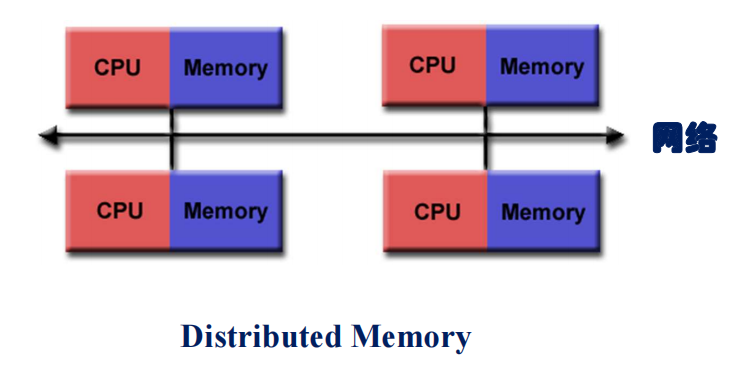
分布式内存(Distributed Memory)
每个处理器都有自己独享的物理内存,只能通过网络与其它处理器交换数据。
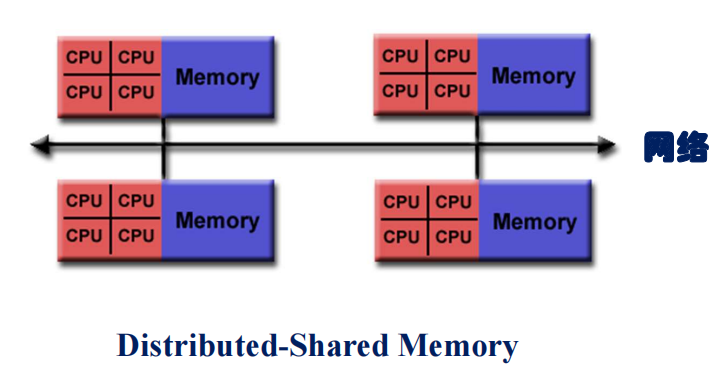
分布式共享内存(Distributed-Shared Memory)
共享内存并行计算机通过网络互连,目前高性能计算、超级计算机多属于此类。
多进程程序设计
进程的概念和特点
进程相关的概念
- 进程:执行中的程序的实例。系统中的每一个进程都运行在上下文(context)中。
- 上下文:由程序正确运行所需要的状态组成,包括:
- 存放在内存中的代码和数据
- 堆栈、寄存器内容、程序计数器、环境变量、文件描述符
- 系统调用:由操作系统提供的应用程序编程接口(API)
- 上下文切换:就是从一个可执行进程切换到另一个可执行进程。引发上下文切换的原因:
- I/O request: Process is placed on I/O queue for a device
- Spawn and wait: Sometimes when a process creates a new process, it must wait until the child completes
- Time slice expiration
- Sleep request
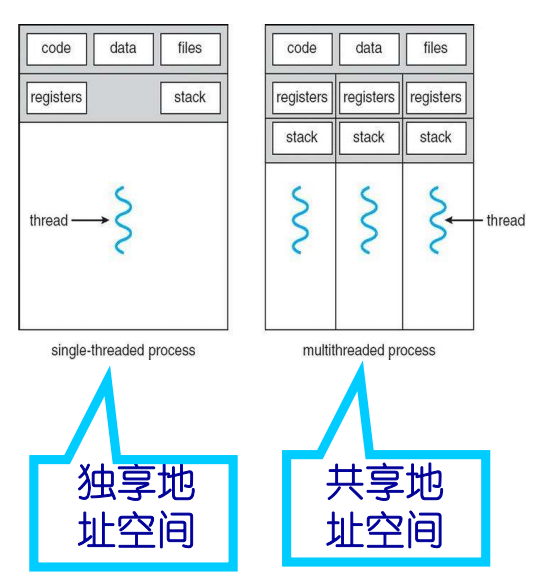
进程与线程区别
- 一个进程可以包括多个线程
- 线程间共享地址空间,因此,一个线程修改一个变量(全局或静态),其它线程都能获知
- 线程间通信直接通过共享变量,而进程间通信则需要通过管道、消息队列等
进程间通信模型
进程控制
进程ID
每一个进程都有唯一的非零正数ID(PID)
1 |
|
进程创建
"fork":把当前进程复制出一个新的进程,当前的进程就是新进程的父进程,新进程称为子进程。
1 |
|
-
调用一次,返回两次
- 返回到父进程;
- 返回到新创建的子进程;
-
并发执行
- 宏观上,父子进程并发执行
- 微观上(多核系统),可能是交替执行或者并行执行
-
相同但是独立的地址空间
- 复制:相同的用户栈、相同的本地变量、相同的堆、相同的全局变量
- 独立:父子进程都有独立的私有地址空间,对变量的任何更改不会影响另外一个进程对应的变量
-
文件共享
- 父进程打开的文件描述符,子进程可以继续使用
进程终止
- 进程终止的三种方式:
- 收到一个信号,信号的默认行为是终止运行
- 从主程序返回
- 调用exit函数
1 |
|
子进程回收
- 僵尸进程:子进程先于父进程终止运行,但是尚未被父进程回收,内核并未清除该进程,保持在一种已终止状态,该进程称为"僵尸进程"(僵死进程)
1 |
|
- wait:父进程阻塞,直到一个子进程运行结束。
- waitpid:比wait更加灵活,可以是非阻塞的。
- 参数:pid_t pid
- pid > 0: 等待进程id为pid的子进程。
- pid == 0: 等待与自己同组的任意子进程。
- pid == -1: 等待任意一个子进程
- pid < -1: 等待进程组号为-pid的任意子进程。
- 参数:int options
- 0:阻塞,即挂起调用进程;
- WNOHANG:非阻塞,即如果指定的子进程都还没有终止运行,立即返回0;否则返回,终止运行进程ID;
- WUNTRACED:如果子进程挂起(暂停),则立即返回;默认只返回终止运行的进程;
- 参数:pid_t pid
wait(&stat)等价于waitpid(-1, &stat, 0)
1 | //退出状态解析 |
执行一个新程序
启动一个新的程序,新的地址空间完全覆盖当前进程的地址空间
1 |
|
- 参数
- path:执行文件
- argv:参数表
- envp:环境变量表,一般直接用environ就行
信号(signal)
- 信号:也称作软中断,是Linux操作系统用来通知进程发生了某种异步事件的一种手段。
- 常见信号
- SIGINT:前台程序执行过程中按下Ctrl-c就会向它发出SIGINT信号,默认终止进程
- SIGKILL:立即中止进程,不能被捕获或忽略
- SIGTERM:kill命令默认的中止程序信号
- SIGALRM:定时器到期,可用alarm函数来设置定时器。默认动作终止进程
- SIGCHLD:子进程终止或停止,默认动作为忽略(waitpid)
- SIGSEGV:无效的内存引用
发送信号
- 内核通过更新目的进程上下文的某个状态(pending位向量,blocked位向量),来实现信号的发送。
- 信号发送起因
- 内核检测到一个系统事件:除零、子进程终止、非法内存引用
- 一个进程调用了kill函数:显式要求内核向目的进程发送信号,目的进程可以是调用进程自身
1 | //kill 函数 |
接收信号
- 当进程接收到一个信号(可能是自己发出,也可能是别的有权限的进程发出),它可以采取的动作可以是下面任意一种:
- 信号处理
- 忽略信号:SIGSTOP与SIGKILL除外
- 捕获信号:通过系统调用,自定义接收到信号后采取的行动。SIGSTOP与SIGKILL除外
- 执行信号的默认动作
1 |
|
同时接收多个信号
- 情况1:如果SIGUSR1的信号处理函数正在执行,第二个SIGUSR1到达
- SIGUSR1存入pending位向量,针对该信号的处理函数随后执行
- 情况2:pending位向量内已经存在一个SIGUSR1,一个新的SIGUSR1到达?
- 新的SIGUSR1信号被丢弃
信号阻塞
信号阻塞:目的进程接收但是不处理该信号,直到取消阻塞。
1 |
|
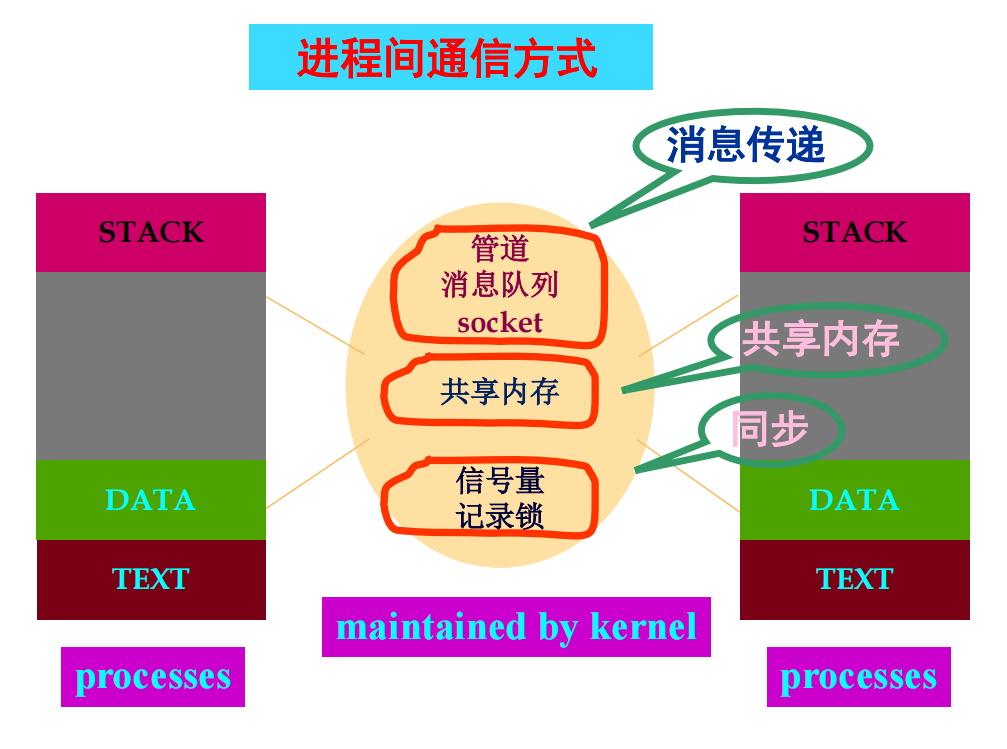
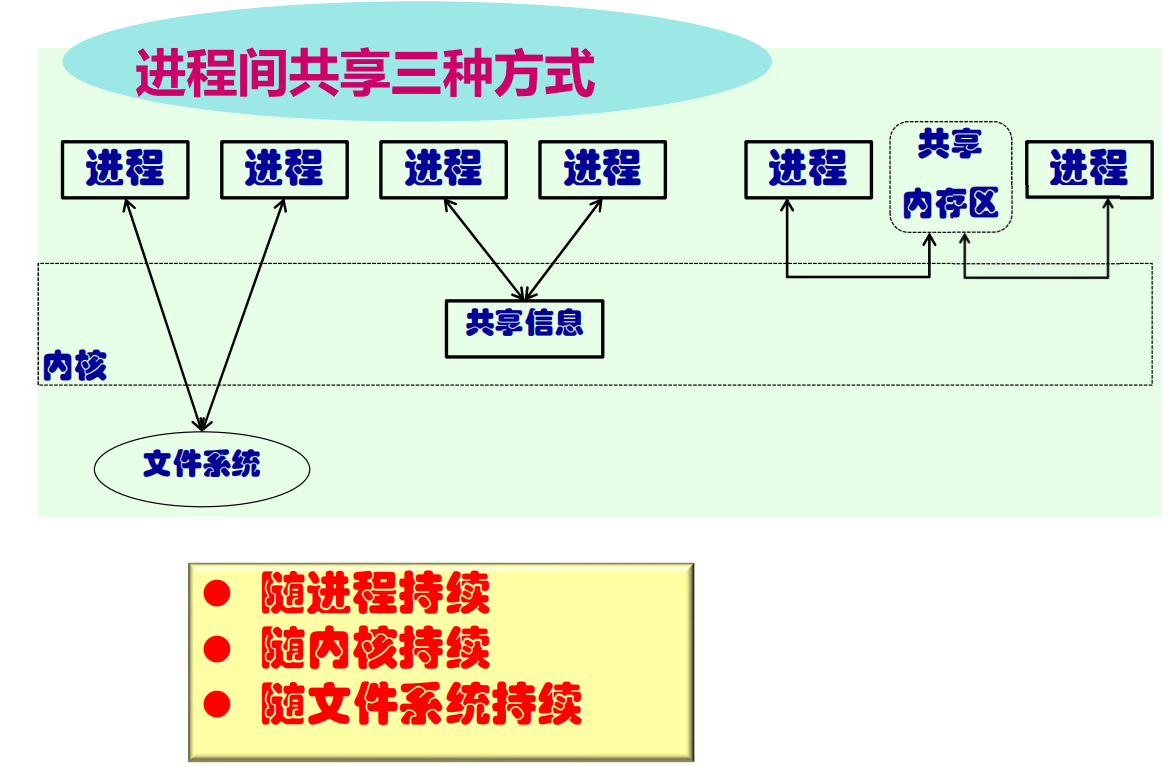
进程间通信
- 进程间通信(IPC):多个进程间协作或沟通的桥梁
消息队列
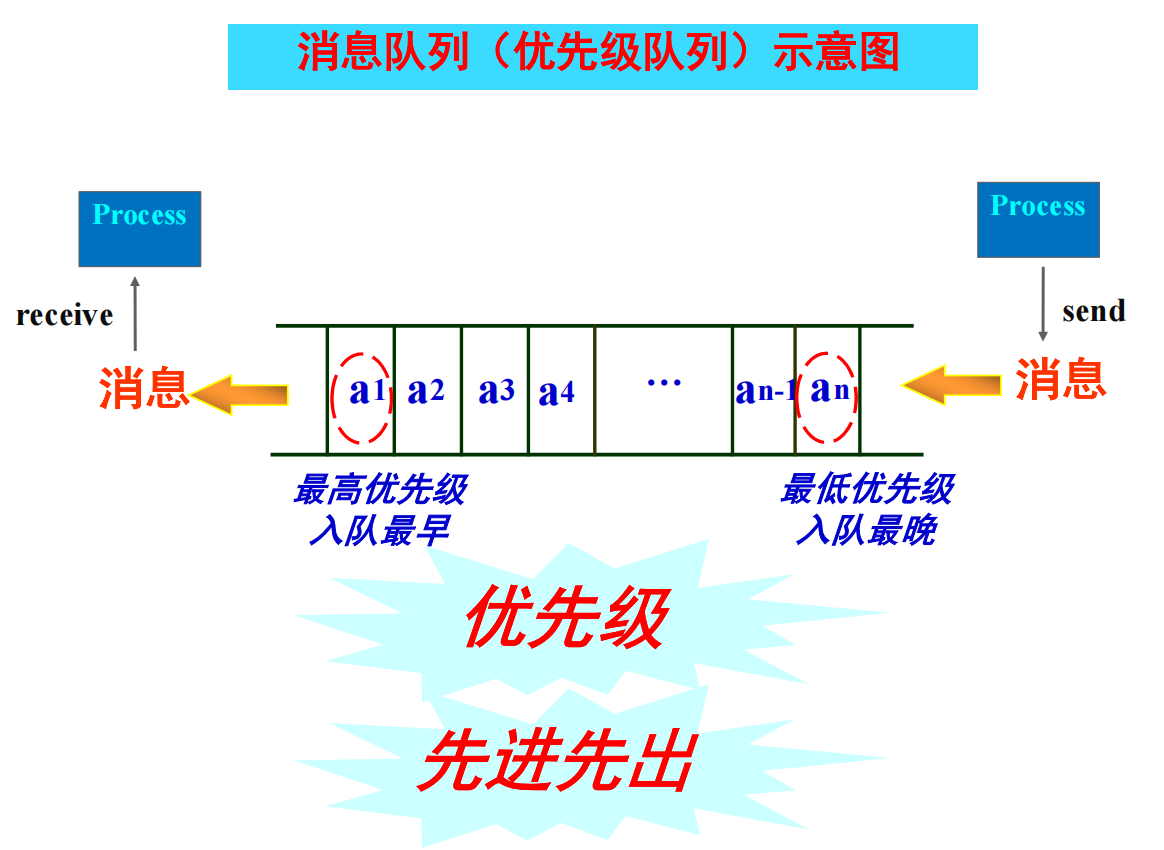
特殊情况
- 队列满(发送进程)
- 阻塞
- 失败返回(非阻塞)
- 队列空(接收进程)
- 阻塞
- 失败返回(非阻塞)
消息队列操作
- 打开消息队列
1 |
|
- 队列属性
1 |
|
- 发送消息
1 |
|
msg_ptr: 发送的消息缓冲区(传入)
msg_len: 消息实际长度(传入)
msg_prio: 消息优先级(传入)
- 接收消息
1 |
|
msg_ptr: 接收到的消息缓冲区(传出)
msg_len: 消息缓冲区大小(传入)
msg_prio: 接收消息的优先级(传出)
- 关闭队列
1 |
|
- 删除队列
1 |
|
信号量(named semaphores)
- 信号量(semaphore):用来对共享资源进行并发访问控制。
信号量相关操作
- 打开信号量
1 |
|
- 关闭信号量
1 |
|
- 删除信号量
1 |
|
- test and decrement
1 |
|
sem_wait:
- (1) 若信号量的值等于0,阻塞,直到值大于0;
- (2) 若信号量的值大于0,值减1;
sem_trywait:
- 不会阻塞,返回-1,errno == EAGAIN;
- increment
1 |
|
sem_post:
- (1) 信号量的值加1,唤醒等待进程;
- (2) 若信号量的值大于0,值减1;
- 取得等待的进程数目
1 |
|
多线程程序设计
线程基础
线程定义
- 线程可认为是进程内部的执行流,一个进程内可包括多个线程,一个显著特点是线程间共享地址空间。
- 线程:进程内独立的执行流
- 进程开始执行时只有一个线程,称为主线程(main thread)
- 独立执行:线程间互相独立,与进程类似
- 共享地址空间:共享堆(指针)、数据段(静态变量、全局变量) 、代码段
- 独立的栈:临时变量可间接共享
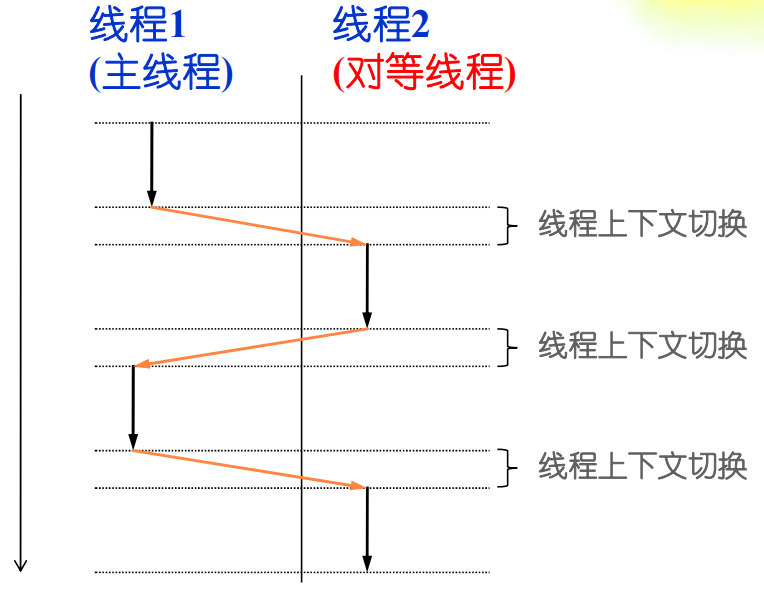
线程优势
- 提高性能(相比进程)
- 线程创建快:与进程共享资源,因此,创建线程不需要复制整个地址空间
- 上下文切换快:从同一个进程内的一个线程切换到另一个线程时需要载入的信息比进程少
- 便捷的数据共享(相比进程)
- 不必通过内核就可以共享和传递数据。线程间通信比进程间通信高效、方便
使用线程
-
工作可以被多个任务同时执行,或者数据可以同时被多个任务操作
-
阻塞与潜在的长时间I/O等待
-
在某些地方使用很多CPU循环而其他地方没有
-
对异步事件必须响应
-
一些工作比其他的重要(优先级中断)
-
线程风险
- 增加程序复杂性
- 难于调试(竞态条件、死锁……)
线程的基本操作
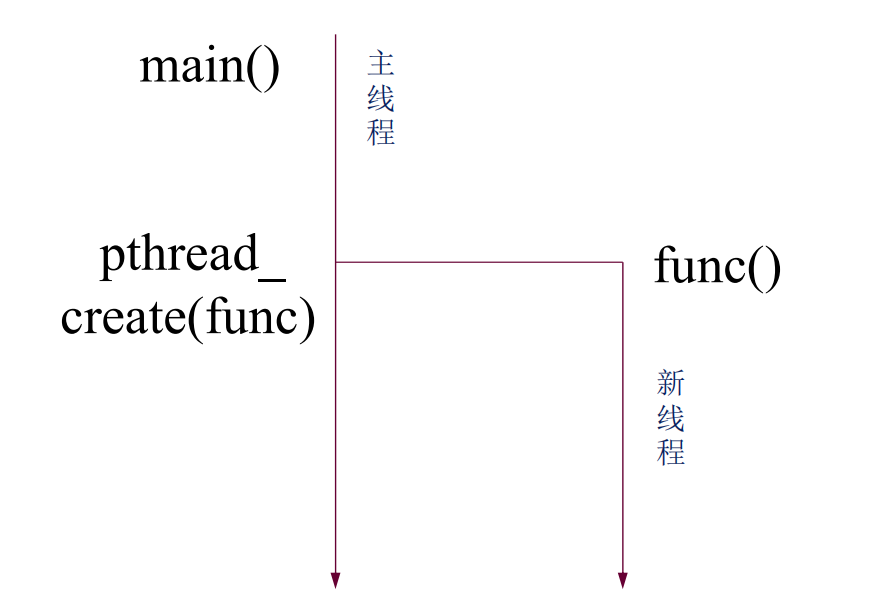
线程创建
1 |
|
pthread_t* tid:新创建线程的ID (传出参数)
pthread_attr_t* attr:设置线程属性,可以是NULL(传入参数)
start_routine* f:在新线程中运行的函数地址(传入参数)
void* arg:函数f的参数,如果要传多个参数,使用结构体指针
线程标识
1 |
|
- 获取当前线程的ID,在线程内调用该函数
- pthread_t有可能是无符号整型(linux)、结构体、指针,为了可移植性,尽量不要打印。
线程回收
1 | //等待(回收)线程 |
等待tid线程终止运行,如果该线程已经终止,立即返回;否则,阻塞直到该线程终止
与wait不同,pthread_join只能等待一个指定的线程终止,不能等待任意一个线程终止
- pthread_t tid:要等待的线程ID (传入参数)
- void* thread_return:线程函数返回的 (void *)指针赋给thread_return所指的地址,可以是NULL(传出参数)*
线程终止
线程终止的三种方式:
- 从线程函数返回;
- 被同进程内的其它线程取消(pthread_cancel);
- 调用pthread_exit函数;
1 |
|
pthread_cancel并不会立即终止另一个线程,只是发送了请求,另一个线程在到达cancellation point(系统调用)的时候才终止
线程分离
- 线程分离:在任何时间点上,线程是 可结合的(joinable) 或者是分离的(detached)。可结合的线程如果没有被回收,存储资源(栈等)不会被释放;分离的线程不能被回收或者杀死,线程终止时,存储资源由系统自动释放。
1 |
|
多线程的共享变量

线程同步
利用共享变量进行线程间通信,但容易引起"同步错误"
互斥(Mutex)
互斥:可以看作一把锁,保护共享资源同一时刻只能被一个线程访问。
- 互斥初始化和销毁
1 |
|
- 加锁和解锁
1 |
|
信号量(semaphore)
- 信号量初始化和销毁
1 |
|
- P和V
1 |
|
条件变量
-
条件变量:是一种等待某事件发生的一种同步机制。即,线程挂起,直到共享数据上的某些条件得到满足。
-
注意要点:
- 条件变量是用来等待而不是用来上锁。它是通过一种能够挂起当前正在执行的进程或者放弃当前进程,直到在共享数据上的一些条件得到满足。
- 条件变量的操作过程是:首先通知条件变量,然后等待,同时挂起当前进程直到有另外一个进程通知该条件变量为止。
条件变量初始化和销毁
1 |
|
等待条件成立
1 |
|
唤醒等待线程
1 |
|
解锁线程
1 | pthread_mutex_lock(&mutex); |
多线程信号处理
- 同步信号(synchronous signals):进程(线程)的某个操作产生的信号,例如SEGILL、SIGSEGV、SIGFPE等。
- **异步信号(asynchronous signals):**类似用户击键这样的进程外部事件产生的信号叫做异步信号,例如kill命令、ctrl+c产生的信号。
线程信号处理函数
1 |
|
- 异步信号由哪一个线程接收?
- 如果所有线程都未阻塞该信号,则接收线程不确定,可能是任意线程;
- 如果只有一个线程未阻塞该信号,则信号将送达该线程。
并发常见问题
线程安全
- 线程安全:一段代码(函数)被称为线程安全的,当且仅当被多个线程反复调用时,一直产生正确的结果。
- 线程不安全分类:
- 共享资源(变量)未做保护
- 不保护共享变量
- 意外共享
- 共享资源操作未保护
- 返回指向静态变量的指针的函数
- 调用线程不安全的函数
- 共享资源(变量)未做保护
可重入函数(reentrant function)
- 显示可重入:所有的函数参数都是传值传递的,并且所有的数据引用都是本地的自动栈变量
竞争
- 竞争:当一个程序的正确性依赖于一个线程在另一个线程到达y点之前,到达它的控制流中的x点时,就会发生竞争。
死锁
- 死锁:信号量引入死锁。一组线程被阻塞了,等待一个永远也不会为真的条件。
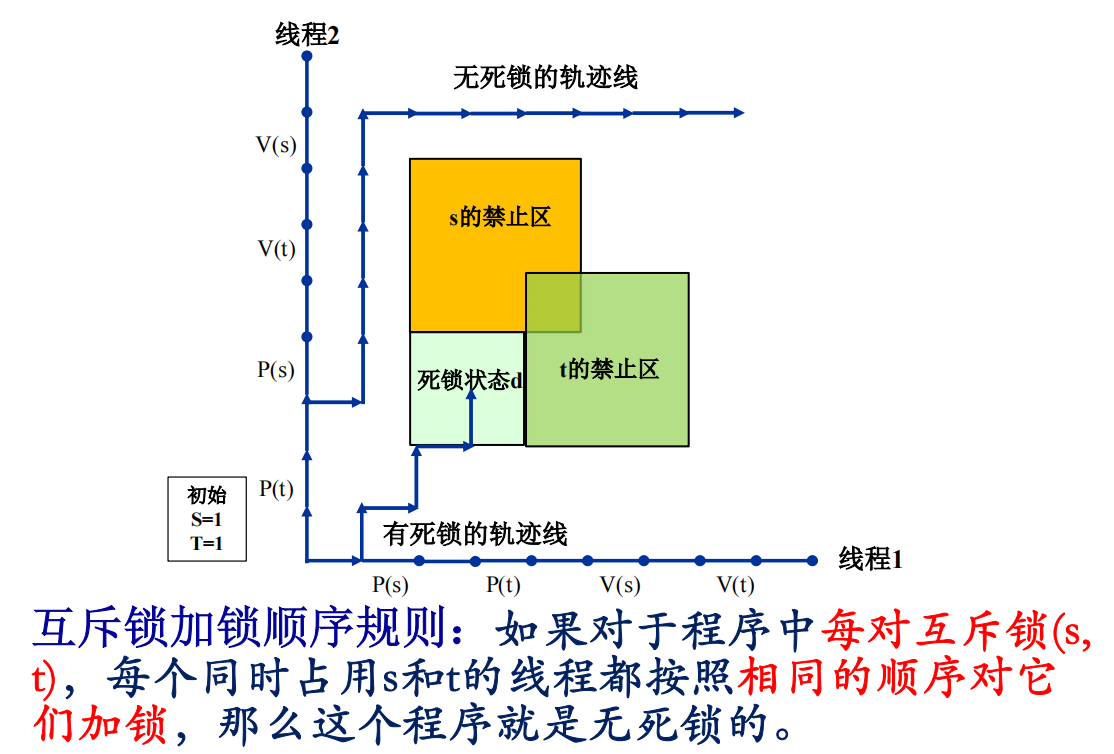
假共享
- 假共享:分别被两个线程使用的变量,由于存储位置靠得太近,有可能被放到一个cache line(通常64字节)内,此时会引起假共享,严重影响性能。
线程个数限制

MPI并行程序设计
这部分可以参考Category: MPI - Charles’s Castle (charles2530.github.io)
认识MPI
什么是MPI
- MPI:Message Passing Interface,消息传递接口。是很多公司和组织共同制定的标准,用于进程间通信。是集群系统最流行的编程模型。有名的免费实现有:MPICH、 LAM/MPI 。
消息通信模型
- 消息传递特点:
- 通过网络传递数据(消息);
- send和receive必须配对使用;
- send和receive分阻塞和非阻塞;
MPI编程基础
MPI初始化
1 |
|
- MPI_INIT必须在其它MPI函数之前调用,它完成MPI程序所有的初始化工作
- main函数必须带参数运行,否则出错
MPI结束
1 |
|
- MPI_FINALIZE是MPI程序的最后一个调用
- 标志并行代码的结束,结束除主进程外其它进程
当前进程ID
1 |
|
- 返回调用进程在给定的通信域中的进程ID(整型,从0开始编号)
- 根据ID,不同的进程就可以将自身和其它的进程区别开来,实现各进程的并行和协作
通信域内的进程数
1 |
|
- 返回给定的通信域中所包括的进程的个数
通信域也可翻译为通信子,在MPI中用来定义进程通信的范围。MPI_COMM_WORLD是MPI预定义的全局通信域
- 一个MPI程序可以有多个通信域,每一个进程组只能与组内的成员通信进程组:进程的集合,可根据进程组创建通信域
发送消息
1 |
|
- 将消息发送至另外一个进程
- 阻塞发送:直到消息被发送出去,该函数才返回
接收消息
1 |
|
- 从其它进程接收消息,如果从其它任意进程接收消息,source参数使MPI_ANY_SOURCE
- 阻塞接收:直到接收到消息后,该函数才返回
死锁的产生
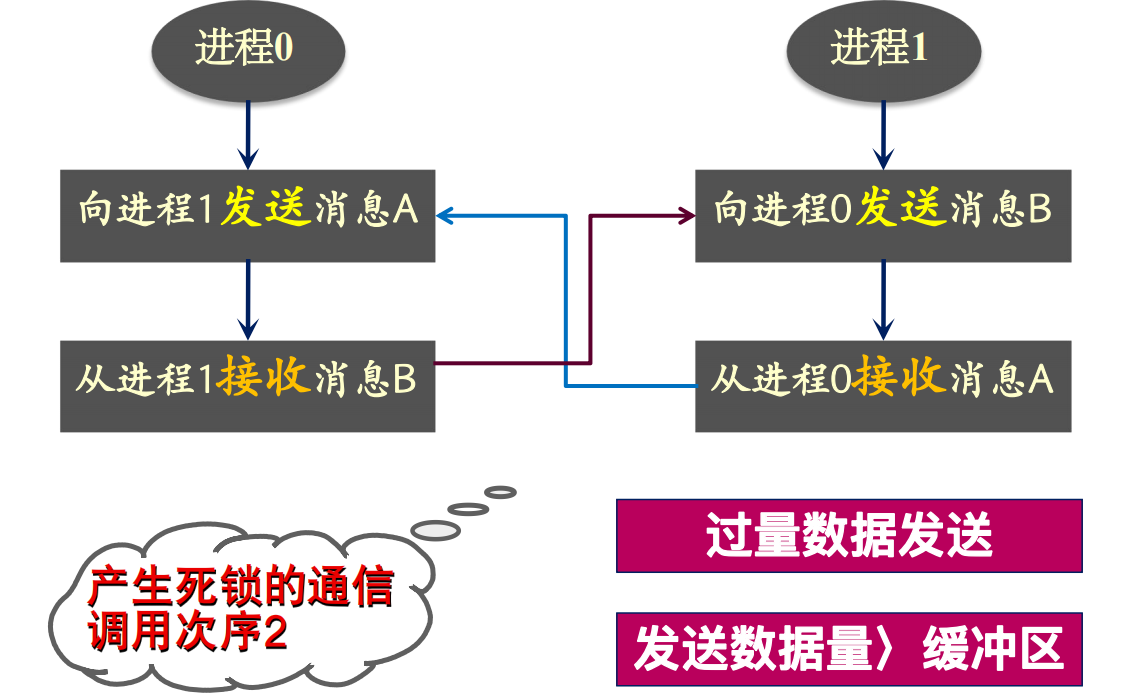
- 确保一次发送数据量小于环境所能提供缓冲区容量
- 利用MPI环境消息的顺序性约束,调整语句的执行顺序
- 使用缓冲发送模式(MPI_Buffer_attach(); MPI_Buffer_detach()…)
- 使用非阻塞通信(MPI_Isend()…)
- 利用组合发送接收(MPI_Sendrecv()…)
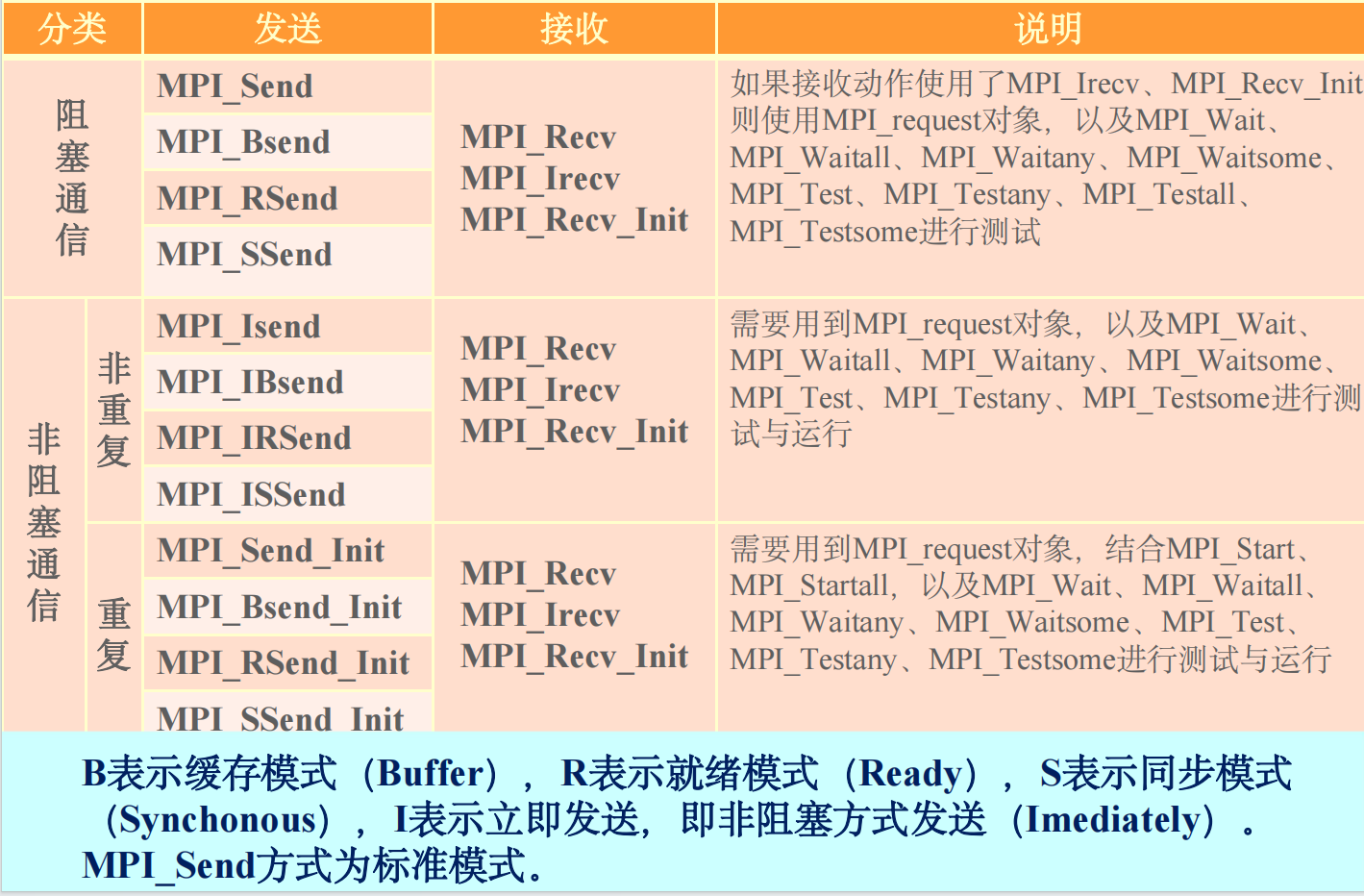
各种模式对缓冲区使用的方式
- 标准方式:MPI环境提供的默认缓冲区
- Bsend:MPI环境提供的buffer放到用户空间
- Rsend:不要缓冲区,发送端不能提前等待
- Ssend:不要缓冲区,允许等待
- 异步模式可以理解为MPI环境另起一个线程在后台做实际的消息传输,并通过MPI_waitxxx、MPI_Testxxx 等机制与MPI进行的主线程进行通讯和同步
阻塞与非阻塞
- 阻塞操作
- 发送操作,返回意味着发送缓冲区可以再次使用,不影响接收端结果,不表示接收端完成接收
- 发送可以同步方式,发送和接收间需要握手协议
- 发送可以异步方式,需要系统缓冲区进行消息缓存
- 阻塞的接收操作仅当消息接收完成后才返回
- 非阻塞操作
- 发送操作和接收操作行为类似,调用后都立即返回
- 在MPI环境中,在可能的时候启动通信,用户无法预测何时启动
- 通过某种手段确定MPI环境执行通信之前,修改发送缓冲区中的数据都是不安全的
- 非阻塞通信的主要目的之一是把计算和通信重叠起来,提高效率
操作的执行顺序及“公平性”
-
顺序规定
- MPI环境保证了消息传递的顺序,及先后发送的消息在接收端不会发生顺序颠倒
- 如果发送进程向同一个目标进程先后发送了m1和m2两个消息,即时他们都被同一接收函数匹配,接收进程只能先接m1,再接收m2
- 如果接收进程先后启动两个接收动作r1和r2,都尝试接收同一消息,则r1必定在r2之前接收消息
- 使用了多线程的MPI环境而言,上述顺序规定不一定成立
-
公平性
- MPI环境不保证“公平性”的措施,用户自己必须在程序设计中解决“操作饥饿”问题,如进程0和进程1同时向进程2发送消息,并与其中的同一个接收操作相匹配,则只有一个进程的发送动作能够完成
MPI集合通信
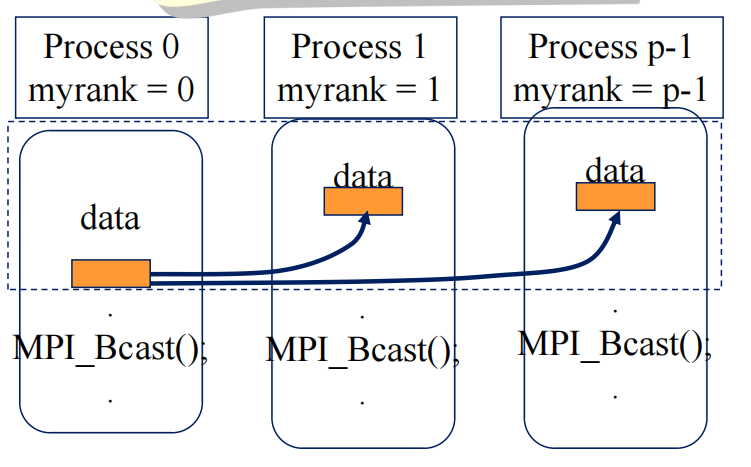
广播消息
1 |
|
-
从root进程广播消息至所有其它的进程(同一个通信域内)
-
广播注意事项:
-
通信域内的所有进程必须调用MPI_Bcast
-
所有的进程收到消息之后,MPI_Bcast才返回
-
不管是广播消息的根进程,还是从根接收消息的其它进程在调用形式上完全一致,即指明相同的根、相同的元素个数、以及相同的数据类型

-
同步(栅栏)
1 |
|
- 当每个进程都到达MPI_Barrier调用后,程序才接着往下执行
非数值并行算法MPI实现
- 非数值算法 基于比较关系的运算,包括排序、串匹配、图论、组合优化和计算几何等。
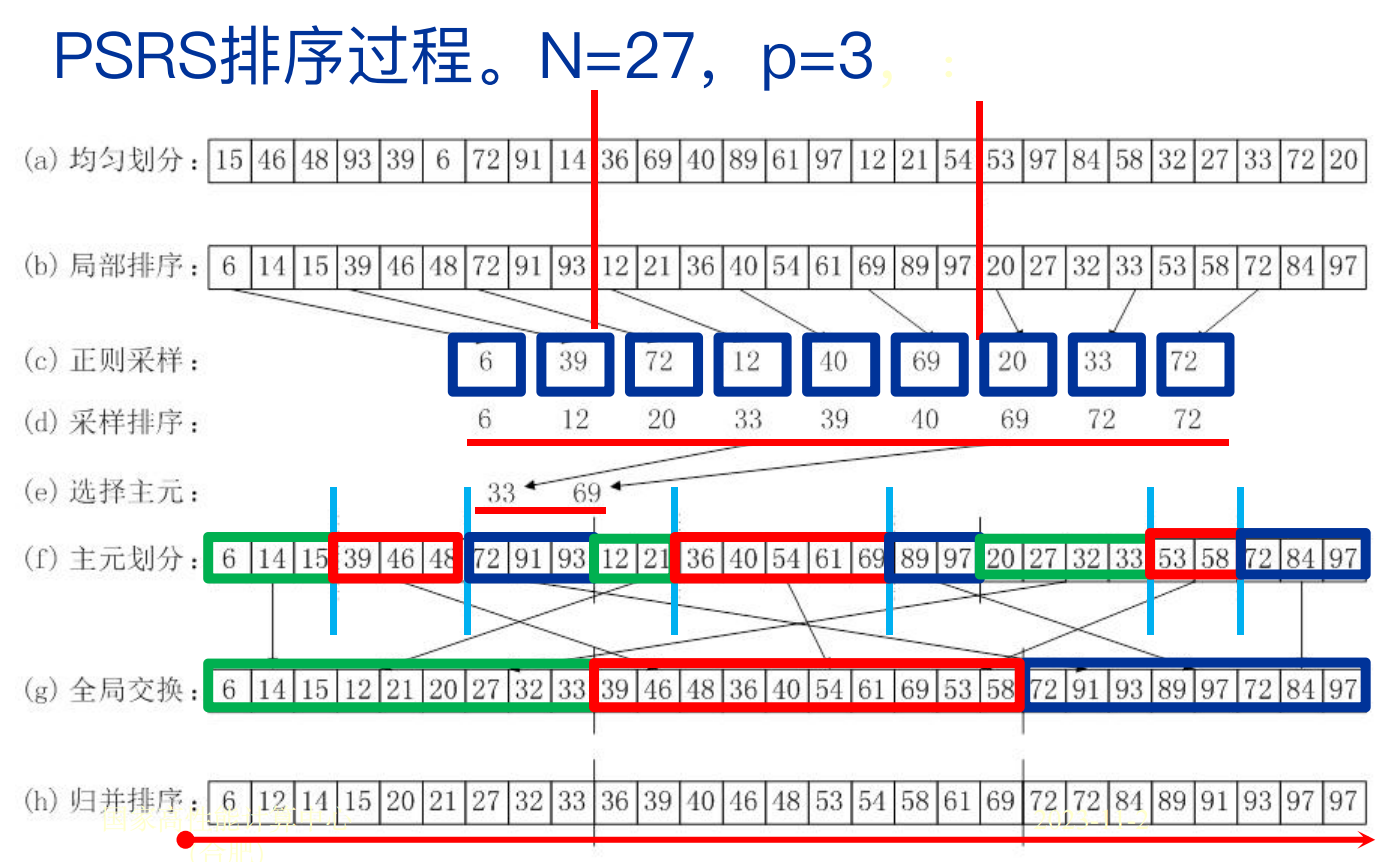
并行正则采样排序(PSRA)
- Parallel Sorting by Regular Sampling
- 基于均匀划分(Uniform Partition)原理的负载均衡的并行排序算法
- 假定待排序的元素有n个,系统中有p个处理器
- 首先将n个元素均匀地分割为p段,每段含有n/p个元素
- 每段指派一个处理器进行局部排序
- 从各段中抽取几个代表元素(为了使各段中诸局部有序的元素在整个序列中也能占据正确的位置)
- 再从几个代表元素中产生p-1个主元
- 然后,按这些主元与原局部有序元素之间的偏序关系,将各个局部有序段划分为p段
- 接着,通过全局交换将各个段中的对应部分集合在一起,采用多路归并的方法进行排序
- 最后,合并起来形成全局有序序列
串匹配
串匹配问题实际上就是一种模式匹配问题,即在给定的文本串中找出与模式串匹配的子串的起始位置。
- KMP串匹配的并行算法思想
- 首先将长度为n的文本串S均匀划分成互不重叠的p段,分布于处理器0~p-1中,且使得相邻的文本段分布在相邻的处理器中,每个处理器中局部文本段的长度为n/p(最后一个处理器可以在其段尾补上特殊字符,使其长度与其他处理器相同)
- 其次,将长为m的模式串T和模式串的next[n]函数广播到各处理器中。
- 每一个局部段i(第p-1段除外),段尾m-1字符中的匹配位置必须跨段才能找到。每个处理器(p-1除外),将本段尾m-1个字符传送给下一个处理器i+1,i+1处理器结合本段首的m-1个字符构成2*(m-1)的段间字符串,进行匹配
单源最短路径问题
输入:边权邻接矩阵W(约定顶点i,j之间无边连接时)w(i,j)=∞ ,且w(i,i)=0,待计算顶点的标号s输出:dist(0:N-1),其中**dist(i)**表示顶点s到顶点i的最短路径(1≤i≤N)
主要函数:
- Main(): 初始化MPI环境;调用读入矩阵函数,传输顶点个数和待计算节点标号到各从线程;给其它的从进程均匀分配顶点数。调用init()、FindMinWay()等函数
- Init(): 各处理器数据初始化,proc 0向各处理器发送各处理器处理顶点数据,各处理器接收数据
- FindMinWay(): 执行并行Dijsktra’s算法计算最短路径长度
并行算法设计与并行模式
并行算法设计基本方法
PCAM设计方法学
- 设计并行算法的四个阶段
- 任务划分(Partitioning)
- 通讯分析(Communication)
- 任务组合(Agglomeration)
- 处理器映射(Mapping)
- 划分:分解成小的任务,开拓并发性;
- 通讯:确定诸任务间的数据交换,监测划分的合理性;
- 组合:依据任务的局部性,组合成更大的任务;
- 映射:将每个任务分配到处理器上,提高算法的性能。
划分
-
定义: 先进行数据分解(称域分解),再进行计算功能的分解(称功能分解);使数据集和计算集互不相交。划分阶段忽略处理器数目和目标机器的体系结构。
-
数据分解: 数据并行。将数据分成很多块,每个计算任务处理一部分数据。
-
功能分解: 任务并行。将计算根据功能划分,每个任务处理整个工作的一部分。
数值并行算法MPI实现
- 数值算法: 基于代数关系的运算,包括矩阵运算、线性方程组的直接求解、迭代解法、矩阵特征值计算、FFT和DWT等。
MPI与Pthread混合编程
如何发挥多核的性能?
- 每一个计算节点只启动一个MPI进程;
- MPI进程内启动多个线程,其中一个线程处理通信。
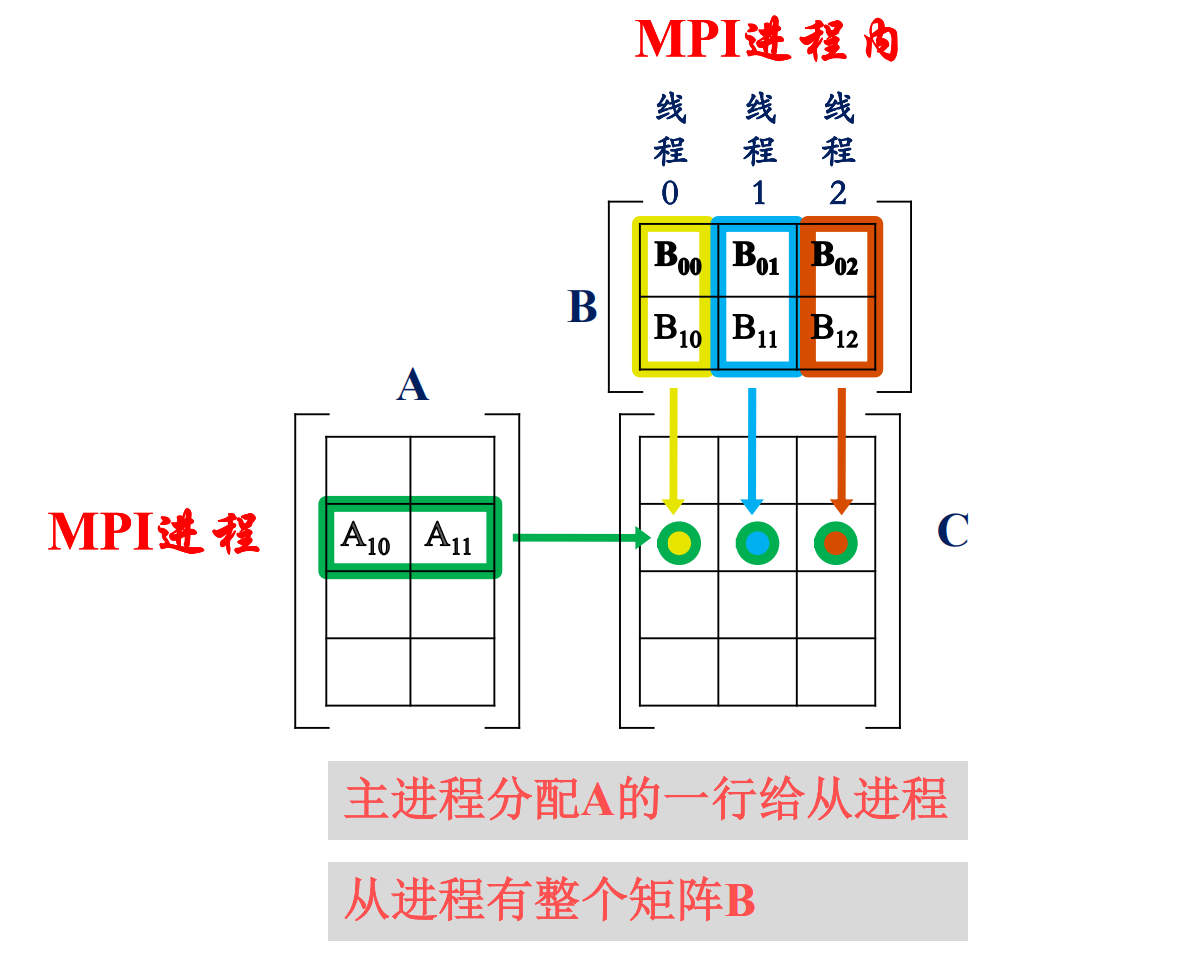
- 主-从并行模式: 一个进程作为主进程负责分派任务,从进程执行任务
- 0号进程(主进程)将矩阵B广播给所有MPI进程(从进程)
- 主进程将矩阵A的各行依次发送给从进程
- 从进程内启动多个线程
- 每一个线程分配B矩阵中的一列,与A中的一行相乘
- 计算结果发给主进程汇总
- 主进程搜集完所有的结果,结束
- 混合编程优点
- 每一个节点只需要一个线程参与通信,其它线程共享数据,具备较高的性能,例如广播
- 较快的上下文切换
- 混合编程缺点
- 编程难度大
- 多个线程同时调用MPI函数(注意看使用的MPI版本是否支持MPI_THREAD_MULTIPLE),可能崩溃
通讯
-
定义: 划分产生的诸任务,一般不能完全独立执行,需要在任务间进行数据交流;从而产生了通讯;功能分解确定了诸任务之间的数据流;诸任务是并发执行的,通讯则限制了这种并发性。
-
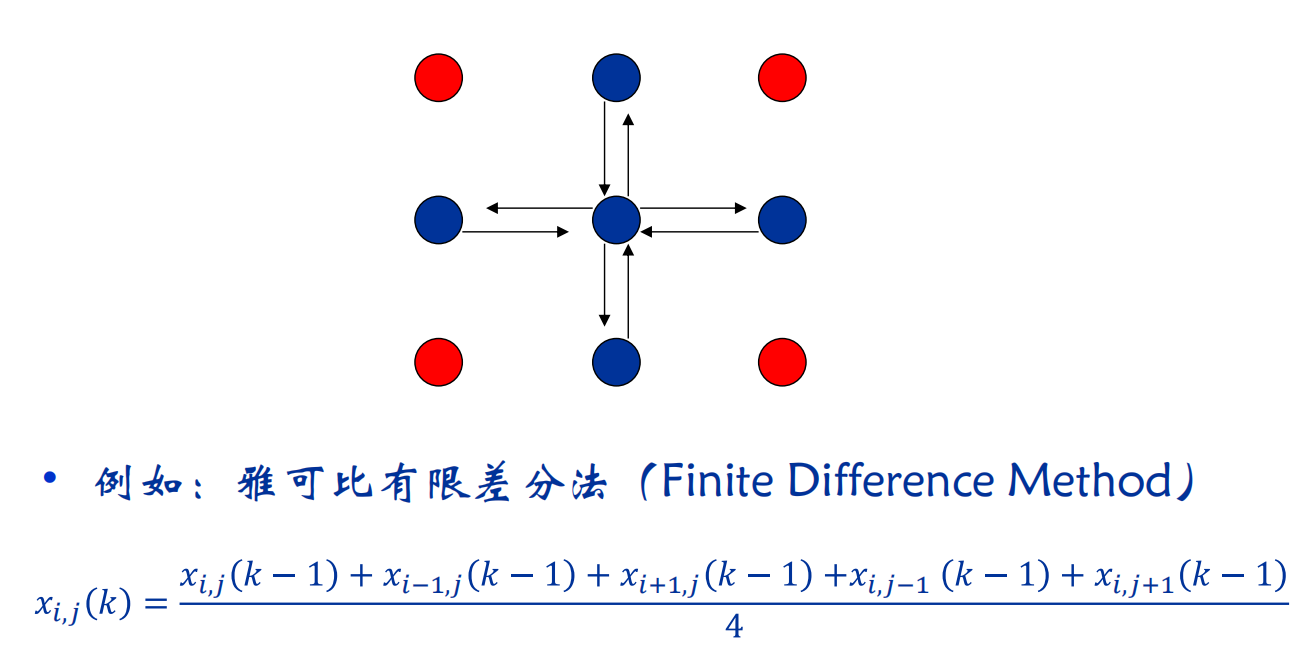
局部通讯:通讯限制在一个邻域内。
-
全局通讯:
-
结构化通讯:每个任务的通讯模式是相同的。
-
非结构化通讯:没有一个统一的通讯模式
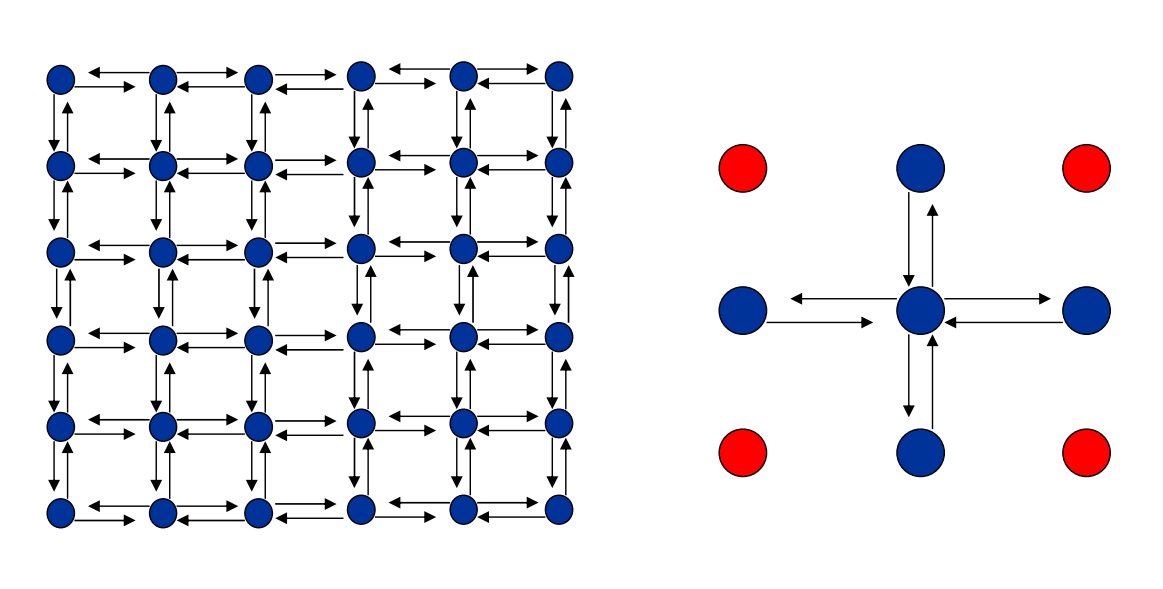
组合
-
定义: 组合是由抽象到具体的过程,是将组合的任务能在一类并行机上有效的执行;合并小尺寸任务,减少任务数。如果任务数恰好等于处理器数,则也完成了映射过程;通过增加任务的粒度和重复计算,可以减少通讯成本;保持映射和扩展的灵活性,降低软件工程成本。
-
增加粒度:
-
重复计算:
- 重复计算减少通讯量,但增加了计算量,应保持恰当的平衡
- 重复计算的目标应减少算法的总运算时间
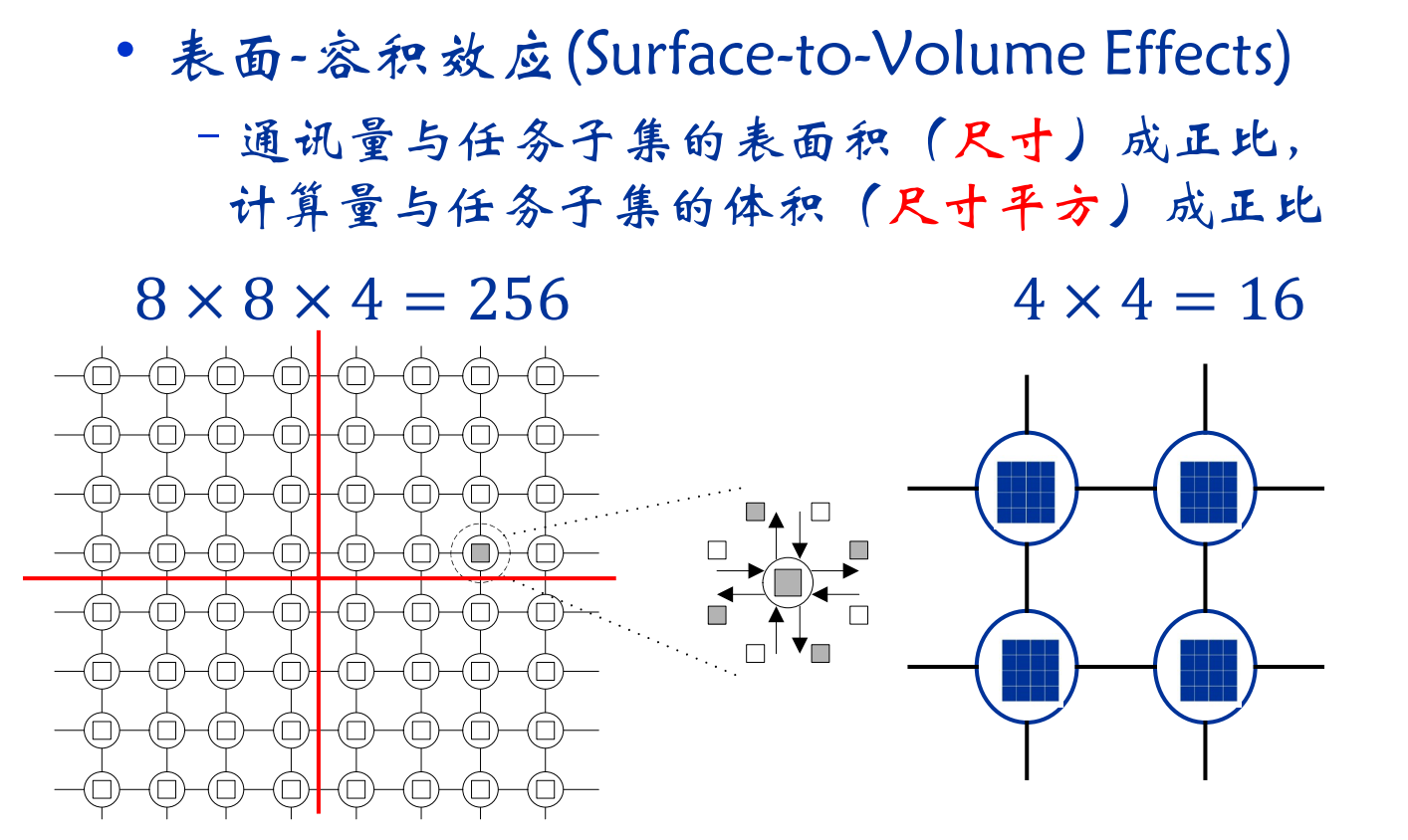
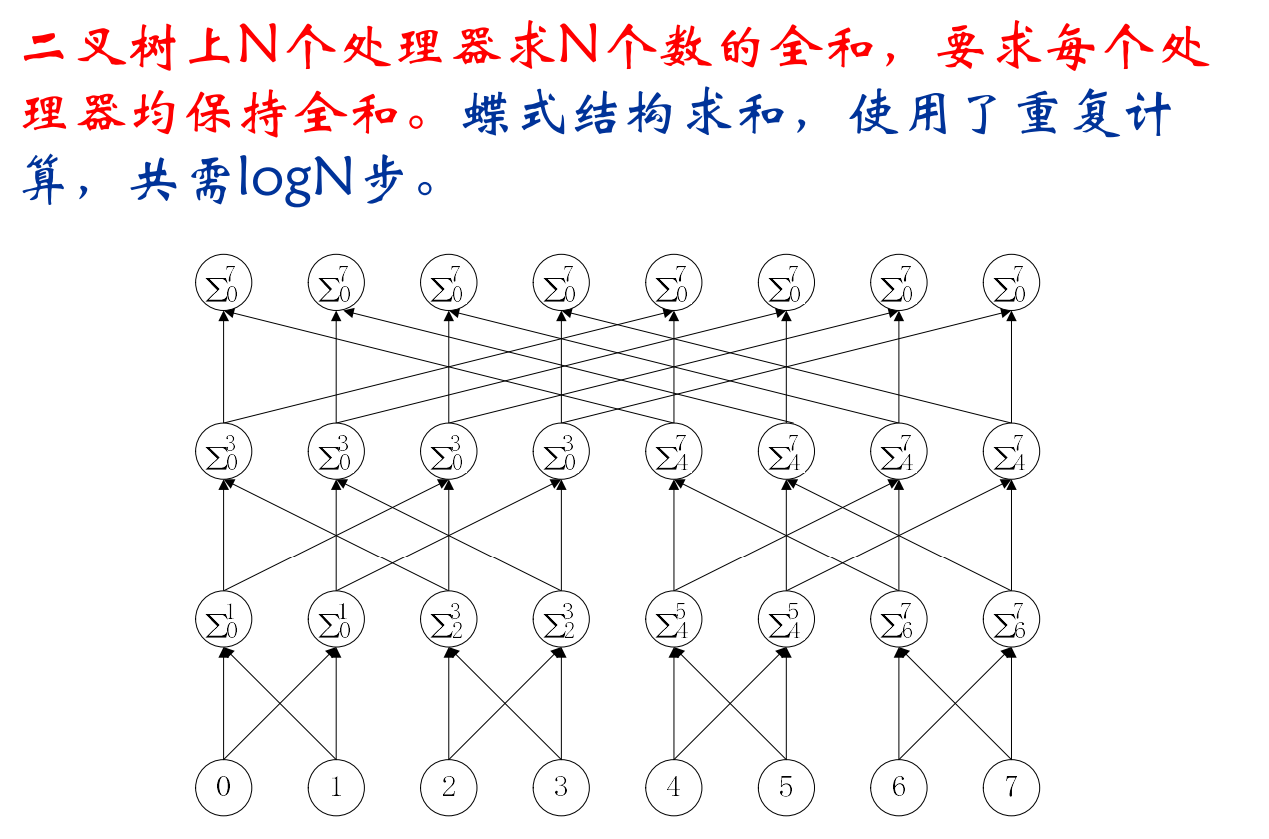
映射
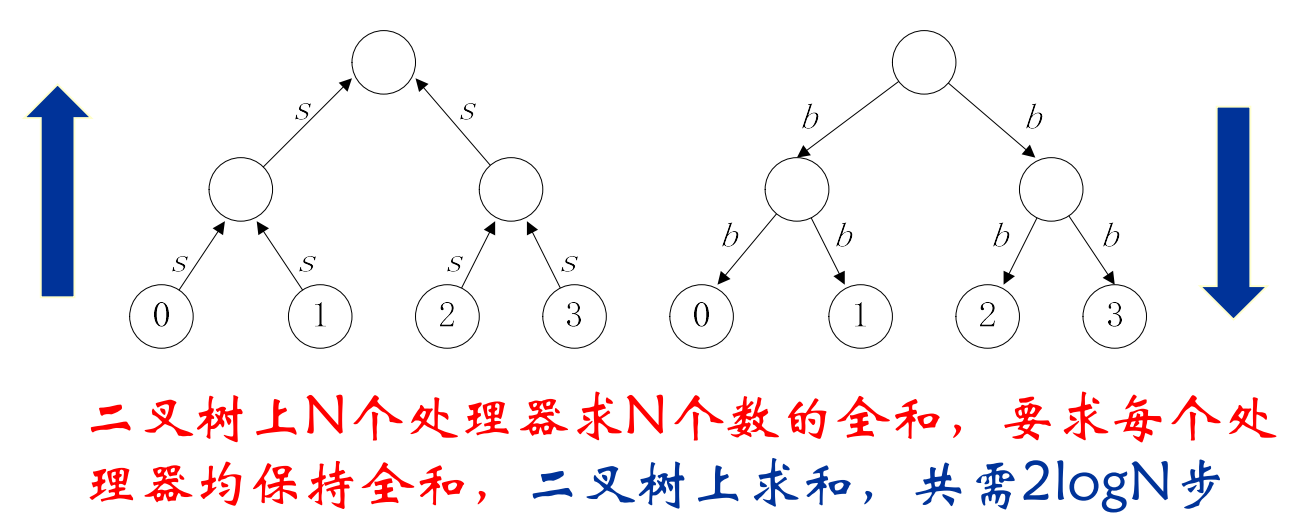
-
定义: 每个任务要映射到具体的处理器,定位到运行机器上;任务数大于处理器数时,存在负载平衡和任务调度问题;映射的目标是为了减少算法的执行时间;映射实际是一种权衡,属于NP完全问题。
-
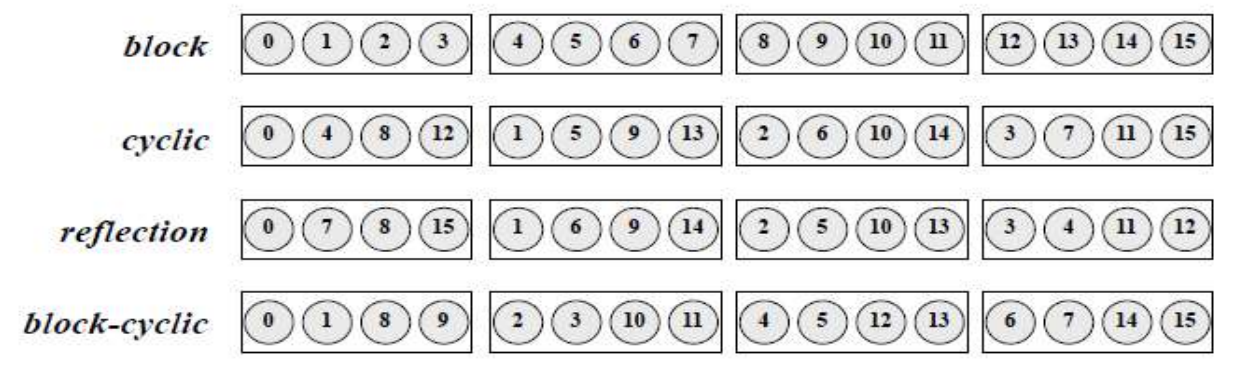
映射方法:
-
任务和处理器拥有同样的顺序编号
- 块映射(block mapping)
- 循环映射(cyclic mapping)
- 反射映射(reflection mapping)
- 块循环映射(block-cyclic mapping)
- 块反射映射(block-reflection mapping)
-
对于高维网格,这种映射方式可以应用于每一个维度
-
-
负载平衡算法:
- 静态的:事先确定
- 概率的:随机确定
- 动态的:执行期间动态负载
-
基于域分解:
- 试图将划分阶段产生的细粒度任务组合成每一个处理器上的一个粗粒度的任务
- 递归对剖:将一个域划分为计算成本大致相等的子域,同时试图使通信代价最小
- 局部算法:使用邻近处理器的负载信息,周期性的调整自己的负载,或转移到邻居,或从邻居迁入
- 概率方法:将任务随机的分配给处理器
- 循环映射:轮流将各种处理器分配给诸计算任务
- 试图将划分阶段产生的细粒度任务组合成每一个处理器上的一个粗粒度的任务
-
任务调度算法:
-
任务放在集中的或分散的任务池中,使用任务调度算法将池中的任务分配给特定的处理器。
-
常用调度模式:
-
常用的并行模式
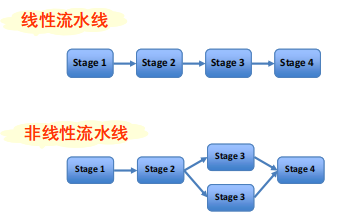
流水线并行
定义:流水线是生产者-消费链。数据流通过一串计算任务,前一计算任务的输出是下一个计算任务的输入。
分类:
- 线性流水线
- 非线性流水线
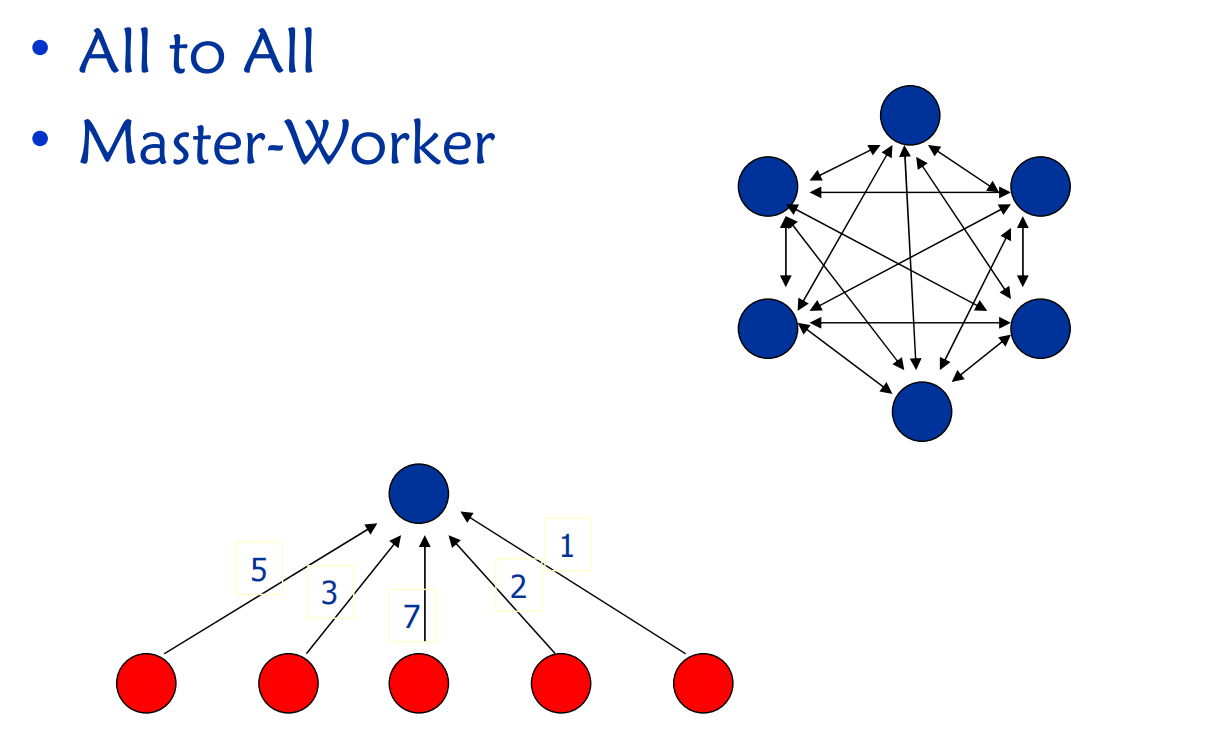
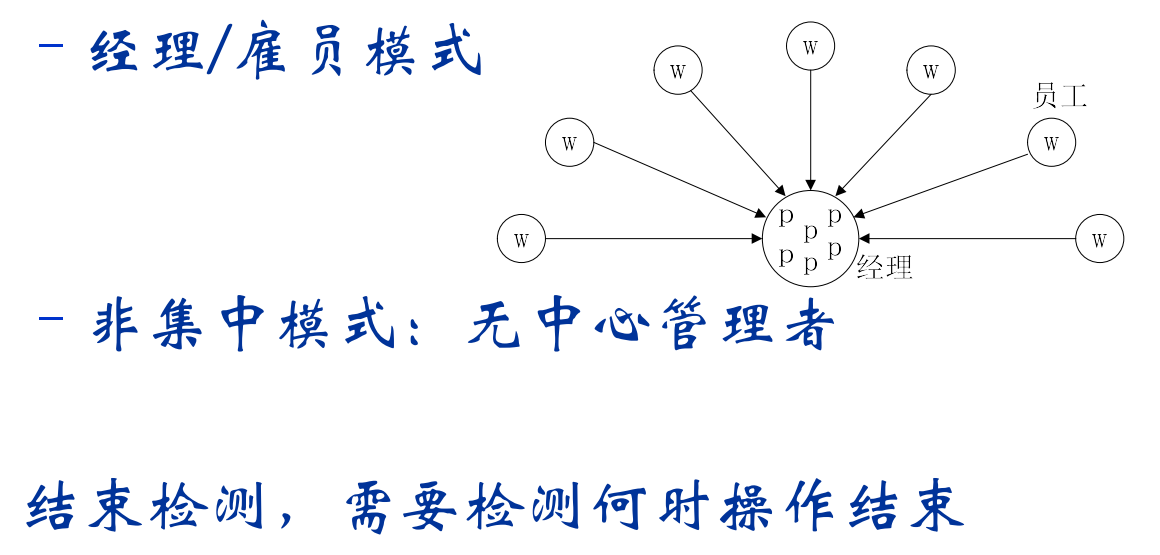
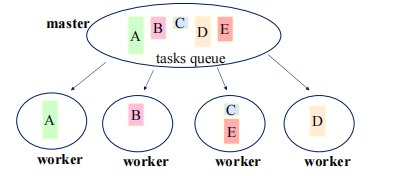
主从并行模式
定义:一个进程(线程)作为master,其它进程(线程)作为worker:
- master产生和管理任务;
- master调度并分派任务给worker;
- worker完成分派的任务之后,向master请求更多的任务
线程池
定义:创建一定数量线程,配备一个任务队列,存放其它线程提交的任务。线程池内的线程从队列中取任务执行,如果队列中没任务,线程池内的线程挂起。
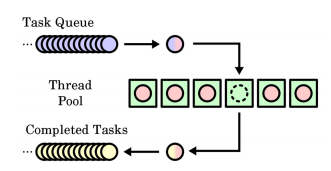
使用线程池的优势:
- 消除频繁创建撤销线程的开销
- 较快的响应速度
- 避免过量占用系统资源(相比每到达一个任务就创建一个线程的方式)
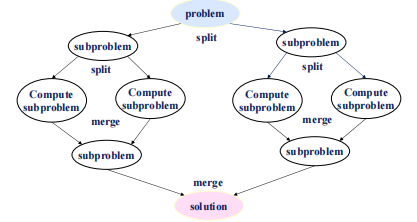
分而治之模式
定义:将问题被分成许多并行的子问题,最后合并结果。
并行计算性能分析
并行程序性能度量
并行运行时间(parallel runtime) :是指从第一个处理器(线程)开始执行程序到最后一个处理器(线程)完成运算所花费的时间。
加速比(speedup) :顺序执行程序执行时间除以计算同一问题的并行程序的执行时间。即: 加速比 是顺序执行时间,是运行在P个处理器上并行时间
效率 (efficieny) :是处理器被有效利用情况的度量。它定义为加速比与处理器数目的比率,即: S是加速比,P是处理器数目
- 理性情况下:加速比等于P,效率等于1
- 实际情况:效率在0和1之间
- 极其稀有情况:效率大于1
影响并行程序性能的因素
开销
并行程序需要付出的开销
- 线程(进程)创建 :尽量避免在计算过程中频繁创建和撤销线程(进程)
- 通信 :处理器间的通信(假共享时)、共享内存的进程间通信(内存拷贝)、分布式内存的进程间通信(网络传输+内存拷贝)
- 同步开销 :同步开销存在于:一个线程等待另外一个线程出现某一事件,例如,等待其它线程释放锁
- 冗余计算 :进行任务分配需要的计算、并行任务间的重复计算
不可并行的代码

Amdahl’s Law和加速比的关系
- 根据Amdahl’s Law很难获得好的加速比
- :串行执行时间
- :并行执行时间
- 是可以并行的部分
竞争
为争夺共享资源而引起的竞争将使系统性能衰减
- 竞争锁 :自旋锁和互斥锁,其中自旋锁尤其耗资源
- I/O带宽 :内存I/O、磁盘I/O、网络I/O
处理器闲置
高性能并行程序的追求: 处理器要得到充分利用,即,所有处理器任意时刻都忙于计算
引起处理器闲置的原因:
- 负载不均衡 :任务分配不均匀、计算能力不均衡(相同的硬件配置不代表相同的计算能力)
- 等待数据 :等待来自网络、磁盘或者存储器的数据
并行程序的可扩展性
可扩展性(Scalability) :如果处理器从P-1增加到P,加速比仍旧在提高,那么称该并行程序能够扩展到P个处理器
影响扩展性的因素:
- I/O:网络、内存带宽、磁盘
- 并行算法
- 并行开销
- 编码实现
改进并行程序性能的几种策略
数据相关性(依赖性)
数据相关性 (Data Dependencies) :是指对存储器操作的顺序,为了保证正确性必须保持这种排序关系。
如果两个计算没有依赖性,即,执行顺序不影响程序正确性,则这两个计算能够并行
并行粒度
并行粒度 (Parallel Granularity ) :由线程或者进程间的交互频率决定,是计算与通信频率比例的定性度量。
- 粗粒度并行 :线程或者进程两次通信之间,进行相对大量的计算工作。
- 细粒度并行 :指的是线程或者进程间交互频繁的计算。
有关并行粒度的探讨
应用:
- 如果通信延迟大,适合粗粒度并行,例如消息传递、进程间通信
- 如果通信延迟小,可以采用细粒度并行,例如GPU的数据并行、多线程
经验:
- 不要用固定的并行粒度,应该使计算的粒度与可用的计算资源以及求解问题具体需求相匹配
- 粗粒度并行会降低同步开销,提高性能,但可能引起:
- 计算的不均衡(处理器闲置)
- 影响可扩展性(降低并发度)
局部性
局部性(Locality):主要分为“时间局部性”和“空间局部性”,是提升程序性能的一个重要因素
- 空间局部性(Spatial locality):加载一个地址的数据之后,继续加载它附近的数据
- 时间局部性(Temporal locality):在加载一个地址的数据之后,短时间内重新加载这块数据
重叠通信和计算
通过并发执行计算和通信,通信的延迟就可部分或者完全被隐藏
任务动态分配
即使同样的计算任务,在同样的硬件配置上运行,执行时间也会产生差异,长时间运行情况会更加恶化:
- 慢节点
- 其它作业干扰
并行程序性能分析工具
并行程序分析及其复杂性
-
更好的利用高性能计算机器
- 必须会写高性能并行程序
- 需要综合了解和优化编程模型、算法、语言和平台等
-
并行性能测量、分析和优化是一个复杂的过程
-
并行性能研究是研究重点
性能测量的基准
- 测量基准:通常包括对一类程序评估的测量度量
- 一种实验方法的标准
- 一种基准程序收集的标准
- 一组量纲的标准
并行程序性能分析动机
- 并行、分布式系统是复杂的
- 四个层次
- 应用层(application)
- 算法和数据结构
- 并行编程接口/中间件应用层(Interface/Middleware)
- 编译器、并行库、通讯、同步
- 操作系统(Operating system)
- 进程、线程、内存、IO管理
- 硬件(Hardware)
- CPU、内存、网络等
- 应用层(application)
- 四个层次
- 不同层之间的映射和互操作
性能因素
-
确定一个程序的性能因素是复杂的,相互关联的,甚至是隐含的。
-
应用相关的因素
- 算法数据集大小、任务粒度、内存使用模式、负载均衡、I/O通讯模式等
-
硬件相关的因素
- 处理器体系结构、分级存储体系结构、I/O通讯网络等
-
软件相关的因素
- 操作系统、编译器/预处理器、通讯协议、函数库等
计算资源的使用
- 资源通常低效使用或无效使用
- 识别出这些情况可知存在性能问题
- 资源通常是“Virtual”
- 不是真实的物理资源(如线程、进程等)
- 性能分析工具
- 帮助程序员了解程序是如何真正运行的
- 提供建议如何进行性能调优
性能分析和调优:基础
-
性能调优的目标是减少程序的执行时间
- 迭代以优化效率
- 效率和执行时间是相关的
-
程序的热点并消除性能瓶颈
-
热点:程序中的一段代码,不成比例的使用高处理器时间
-
性能瓶颈:程序中的一段代码,无效的使用处理器资源,因此产生不必要的延迟
-
串行性能(Sequential Performance)
-
串行性能
-
时间是如何分布的
-
何时和何地使用了什么资源
-
-
串行因素
-
计算
-
选择正确的算法是最重要的
-
编译器支持
-
-
存储系统(缓存和内存)
-
很难评定和决定效果
-
模型支持
-
-
输入/输出
-
-
并行性能
-
串行性能+并行交互
-
串行性能是每一个进程/线程的执行时间
-
并行交互是进程/线程之间的通讯时间
-
-
“并行”导致额外开销
-
并发(进程/线程)
-
进程间通讯(消息传递)
-
同步(显式/隐式)
-
-
并行之间的互操作也会导致并行无效
- 负载不均衡
-
串行性能调优(Tuning)
-
串行性能调优是一个时间驱动(time-driven )过程
-
寻找花费最多时间的代码,使其花费少量的时间
-
通常进行程序重组
-
数据存储和组织结构的变化
-
重排任务或操作过程
-
-
更好利用资源的方法
-
缓存管理
-
本地化
-
虚拟内存管理
-
-
更好的处理器使用方法
并行性能调优(Tuning)
-
并行性能调优是冲突驱动(conflict-driven or interaction-driven)
-
寻找并行互操作点,分析其开销
-
开销包括互操作的花费
-
数据传输
-
协调过程中的额外操作
-
-
开销也包括等待时间
执行时间(Execution Time)
-
不同类型的时间
-
Wall-clock time
-
基于实际时钟 (不间断运行)
-
包括花费在所有活动上的时间
-
-
Virtual process time虚过程时间 (aka CPU time)
-
进程执行时间 (CPU运行)
- 用户时间和系统时间
-
不包括进程内在等待的时间
-
-
并行执行时间
-
任何并行部分执行过程中的时间
-
需要定义一个全局时间基准
-
Observation类型
-
根据不同的测量方法
-
直接性能观察
-
间接性能观察
-
-
直接性能观察基于测量的科学理论,考虑到开销的精确性
-
间接性能观察基于测量的采样理论,假设一定程度上的统计稳定性
直接性能观察
-
执行行为描述为事件
-
行为反映为一些执行状态
-
事件编码
-
-
观察是直接的
-
直接在代码中插桩 (探针)
-
插桩代码调用性能测量程序
-
事件测量 = 性能数据 + 上下文
-
-
性能实验
- 实际事件 + 性能测量
并行性能分析的未来
-
性能是高性能计算的最基本驱动力
- Performance的观察,建模和工程学设计是开发并行潜能和高性能计算机的关键方法论
-
在并行程序分析工具和并行计算之间的关系
- 关注性能是必要的,但是是事后的
-
需要研究在并行计算的整个过程中强制推行性能分析的方法和技术
-
获得、学习和推进性能知识
-
处理扩展性和复杂性问题
-
在程序的语义(计算模型)和具体执行模型上考虑性能分析的功能
-
- Title: parallel_programming_theory
- Author: Charles
- Created at : 2023-11-06 12:47:19
- Updated at : 2026-05-11 20:11:26
- Link: https://charles2530.github.io/2023/11/06/parallel-programming-theory/
- License: This work is licensed under CC BY-NC-SA 4.0.