
ML-paper-PTQ4SAM
PTQ4SAM
paper
**核心问题:**SAM 在许多计算机视觉任务中取得了令人印象深刻的性能,但巨大的内存和计算成本阻碍了它的实际部署.
核心方法(贡献):
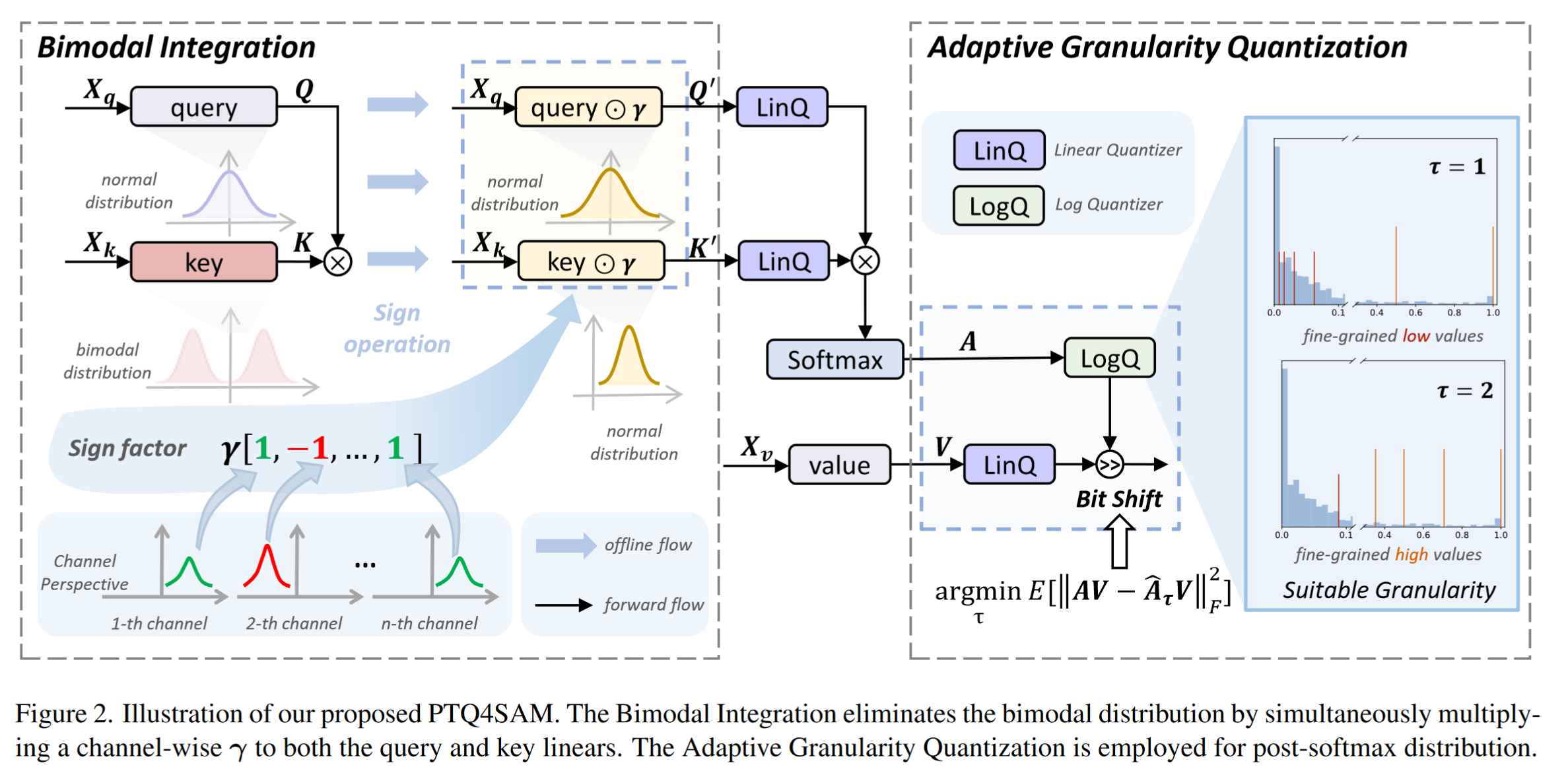
- 第一个 SAM 量身定制的 PTQ 框架,命名为 PTQ4SAM
- SAM 中 post-Key-Linear 激活的量化范围较大不利于量化执行,因此提出了双峰整合(BIG)策略,自动检测双峰分布,并将双峰分布等价转换为正态分布
- 由于 SAM 包含不同的注意机制,导致 Softmax 后的分布有很大的变化,因此论文提出了自适应粒度量化(AGQ),以适当的粒度精确地表示了不同的 post-Softmax 分布
**实验效果:**当 SAM-L 量化到 6 位时,实例分割的准确率达到无损,在理论 3.9× 加速下下降了约 0.5%
改进方向: SAM 中出现双峰分布的原因尚不清楚。这个方向为我们未来的研究提供了一个潜在的途径
背景与相关工作
SAM 的 transformer 架构需要密集的计算和内存占用,阻碍了在边缘设备上的部署
选用 PTQ,相比于量化感知训练(QAT),训练后量化(PTQ)使用非标记样本来校准预训练模型,实际使用时效率更高
对于 SAM 而言,直接采用这些方法对任何事物模型进行分割会带来两个独特的挑战,需要重新审视传统的 PTQ 方案——post-Key-Linear 双峰分布和 post-Softmax 分布,而这两点在之前的论文中没有在量化 SAM 时特意考虑
-
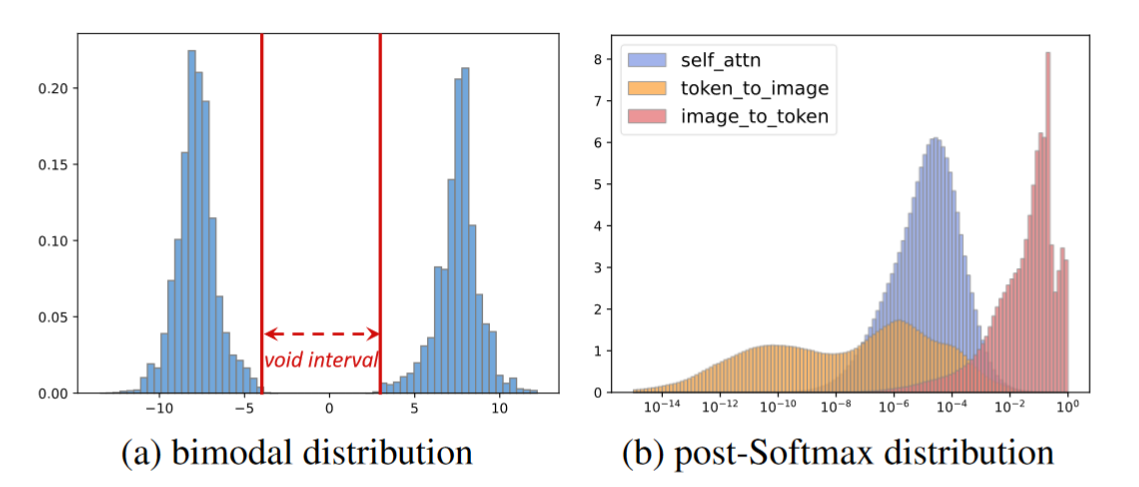
双峰分布的中心空隙区间严重扩大了整个分布的范围,这对量化性能产生了负面影响
- 我们提出了一种双峰整合( Bimodal Integration,BIG )策略来巧妙地消除双峰分布
- 我们利用它的 per-tensor 特性来判断是否为双峰分布,并利用它的 per-channel 特性将这种双峰分布转换为正态分布
-
由于注意机制的多样性,SAMs 表现出更加复杂的 post-Softmax 分布,具体表现为大约 72.5 %的 image-to-token 的 Softmax 后激活大于 0.01,而在 token-to-image 中只有 0.4%
- 我们提出了一种自适应粒度量化( AGQ ),它针对不同的后 Softmax 分布进行了明确的裁剪,为较低和较高的注意力分数提供了粒度上的适当折衷。
Segment Anything
Segment Anything Model(SAM)是 Meta AI 推出的一款图像分割模型,旨在实现广泛、精确和高效的图像分割任务。它具有广泛的适用性,能处理多种图像和对象,从简单的前景-背景分割到复杂的物体分割。SAM 支持用户通过点击、绘制或文本提示等方式引导分割过程,提升用户交互友好性。模型基于 Transformer 和卷积神经网络(CNN),结合两者的优势,既能捕捉全局特征,又能保留局部细节。经过大规模数据集预训练,SAM 拥有出色的泛化能力和高精度。应用场景涵盖医学影像分析、自动驾驶、智能制造和内容创作等领域。未来,SAM 有望在更高效的分割算法、更好的用户交互界面和更多应用场景上不断进步,展示出广泛的应用潜力,为各行各业提供强大的图像分割工具。
| SAM 相关工作论文 | 贡献 |
|---|---|
| HQ-SAM | 设计了可学习的 tokens 和全局-局部融合方案来获得高质量的掩码 |
| SEEM | 将指称图像扩展为提示类型,并整合了一个联合的视觉-语义空间 |
问题:SAM 仍然存在不可维持的资源密集型消耗,其实时处理能力需要改善
Post-Training Quantization
PTQ 分为基于统计的 PTQ(statistic-based PTQ)和基于学习的 PTQ(learning-based PTQ),基于统计的 PTQ 方法只寻求最优的量化参数来最小化量化误差,而基于学习的 PTQ 方法微调模型参数,包括权重和量化参数。
- Statistic-Based PTQ 根据收集到的统计信息,确定每一层的量化参数(如量化比例和零点)。常见的方法包括均匀量化(Uniform Quantization)和非均匀量化(Non-Uniform Quantization),使用确定的量化参数,将浮点权重和激活值映射到低比特位的整数值(如 8 位),并将其存储为量化模型。这种方法不需要再训练模型,仅通过统计分析来确定量化参数,因此实现简单且快速。但在某些情况下,量化后的模型性能可能会有所下降。适用于计算资源有限、对模型精度要求不高的场景,如边缘设备和移动设备。优点是实现简单、快速;缺点是对模型性能影响较大。
- learning-based PTQ 首先对模型进行初始量化,类似于基于统计的 PTQ 方法,确定初始的量化参数,在初始量化的基础上,使用一小部分训练数据对模型进行微调训练。通过反向传播算法同时优化权重和量化参数,使模型在量化后的环境中依然能够保持良好的性能。基于学习的 PTQ 方法可以显著提升量化模型的性能,尤其在高精度要求的任务中表现突出。然而,这种方法需要额外的计算资源和训练时间。适用于计算资源充足、对模型精度要求高的场景,如服务器端推理和高精度应用。优点是能够显著提升量化模型的性能;缺点是需要额外的训练时间和计算资源。
| 量化算法相关工作 | 方法类别 | 贡献 |
|---|---|---|
| AdaRound | learning-based PTQ | 优化了量化权重时的取整操作,以最小化模型的整体损失 |
| BRECQ | learning-based PTQ | 提出了一种分块重构算法来优化量化模型 |
| QDrop | learning-based PTQ | 在重建过程中引入下落操作,增加了优化模型的平整度 |
| PD- Quant | learning-based PTQ | 在优化量化参数时引入了全局信息 |
| MRECG | learning-based PTQ | 首次在大型语言模型上提出了一种新的可学习权重舍入方案 |
这些技术主要是基于 CNN 架构模型进行的。类似于 SAM 的 transformer 结构模型还未被探索
方法理论
均匀量化和对数量化
-
均匀量化是一种简单且常用的量化方法,通过将浮点数值映射到固定范围内的整数值,且步长(scale)是均匀的。该方法首先确定数据的最小值和最大值,然后计算量化步长和零点,并利用这些参数将浮点数值转换为整数。均匀量化的优点在于实现简单、计算效率高,适用于数据分布较为均匀的场景。然而,对于数据分布不均匀的情况,其量化误差可能较大,影响模型性能。

-
对数量化根据数据的实际分布情况,自适应选择量化步长,使量化误差最小化。这种方法在数据密集的区域使用较小的步长,在数据稀疏的区域使用较大的步长,从而更好地处理具有复杂分布的数据。对数量化的优点在于能够显著减少量化误差,适用于数据分布复杂、精度要求高的场景。然而,其实现较为复杂,计算效率较低,量化和反量化过程可能需要额外的计算资源。
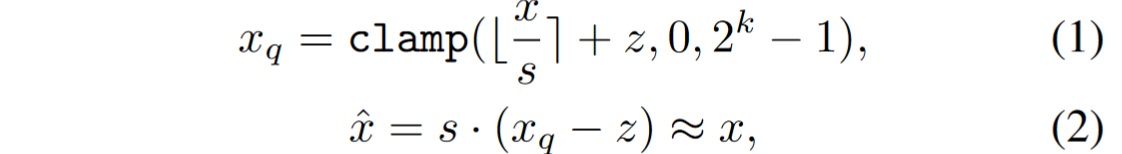
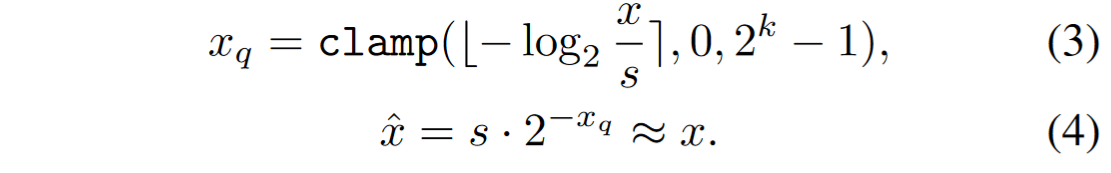
| 特性 | 均匀量化 | 对数量化 |
|---|---|---|
| 实现复杂度 | 简单 | 复杂 |
| 计算效率 | 高 | 低 |
| 量化步长 | 固定 | 自适应 |
| 适用数据分布 | 均匀 | 不均匀 |
| 量化误差 | 较大(对于不均匀分布数据) | 较小 |
| 适用场景 | 移动设备、嵌入式系统等 | 服务器端推理、高精度应用等 |
Bimodal Integration
双峰伴随着它们的中心空洞或稀疏间隔,大大扩展了分布范围,导致实验上超过 5 倍于正态分布的量化误差
-
从张量的角度来看:分布包含两个峰,且它们的中心是对称的
-
从每个通道的角度来看:每个通道的激活只持续在一个固定的峰值,这表明一个通道内部存在明显的不对称性
一般来说,大约一半的通道(例如,在 SAM - B 中为 46.1 %)聚集在正峰,其余的通道聚集在负峰
 我们观察到双峰分布显著地集中于post=Key-Linear的激活,公式表示为
我们观察到双峰分布显著地集中于post=Key-Linear的激活,公式表示为
BIG 包括三个步骤:发现双峰、γ 计算和等效变换
-
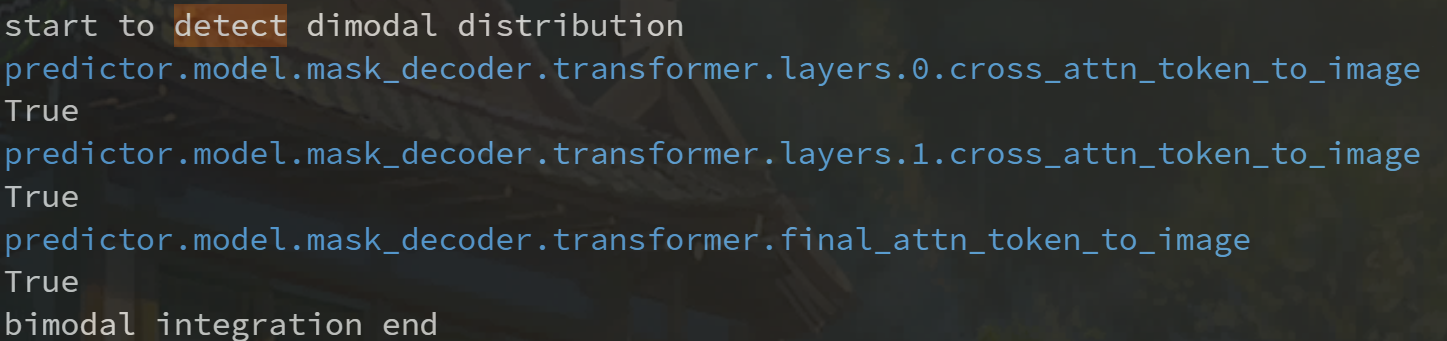
在 SAM 中,并不是所有的 post-Key-Linear 激活都是双峰分布,为了区分双峰分布,我们首先采用高斯核密度估计来计算整个张量的概率密度函数( PDF ) ,为了避免将两个小凸点识别为两个峰,我们限制了峰的高度和两个峰之间的距离
高斯核密度估计(KDE, Kernel Density Estimation)是一种非参数统计方法,用于估计随机变量的概率密度函数(PDF)。与直方图不同,KDE 不依赖于特定的区间划分,而是使用核函数(kernel function)平滑数据,提供一个连续的密度估计。
-
通过引入 channel 级超参数 r 来将双峰分布转化为正态分布,通过计算每个通道 key linear 后的激活函数均值来将结果转化为正数
-
等效变换
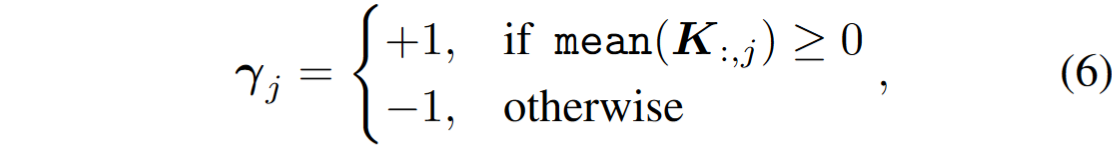
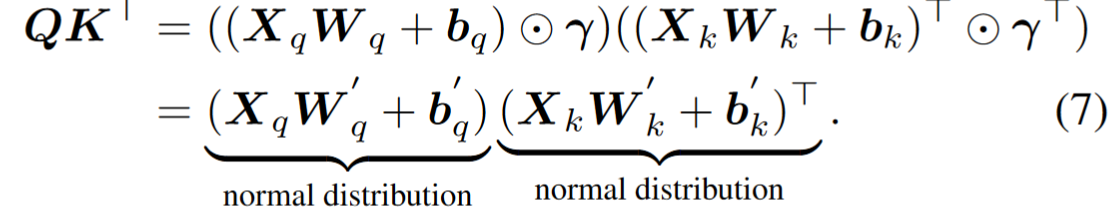
Adaptive Granularity Quantization
由于前人工作主要针对自注意力机制中的 softmax 进行设计,而 SAM 中有多种注意力机制如 cross-attention,故论文重新研究了对数量化器,提出了一种自适应粒度量化( AGQ ),并引入自适应参数 τ 来调整 base
- 较小的 τ 可以代表较低的注意力分数。并且随着 τ 的增加,较高的注意力分数变得更加细粒度,从而根据不同的注意力机制类型使用不同的参数
- LUT 表示小查找表,可用于各种神经网络加速器,值得注意的是,由于 τ∈{ 20,21,…,2n - 1 }的 LUT 可以合并到 τ = 2n 的 LUT 中,因此整个网络只需要一个 LUT。
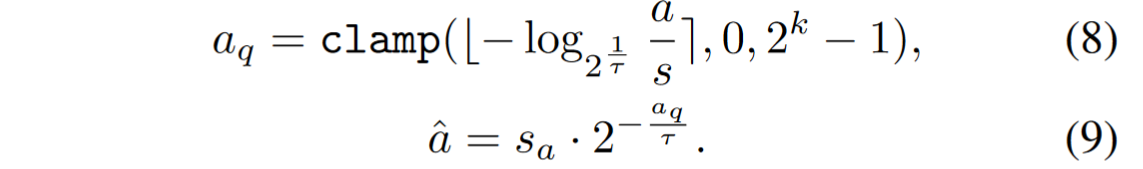
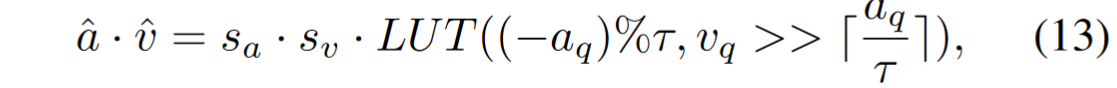
实验工作
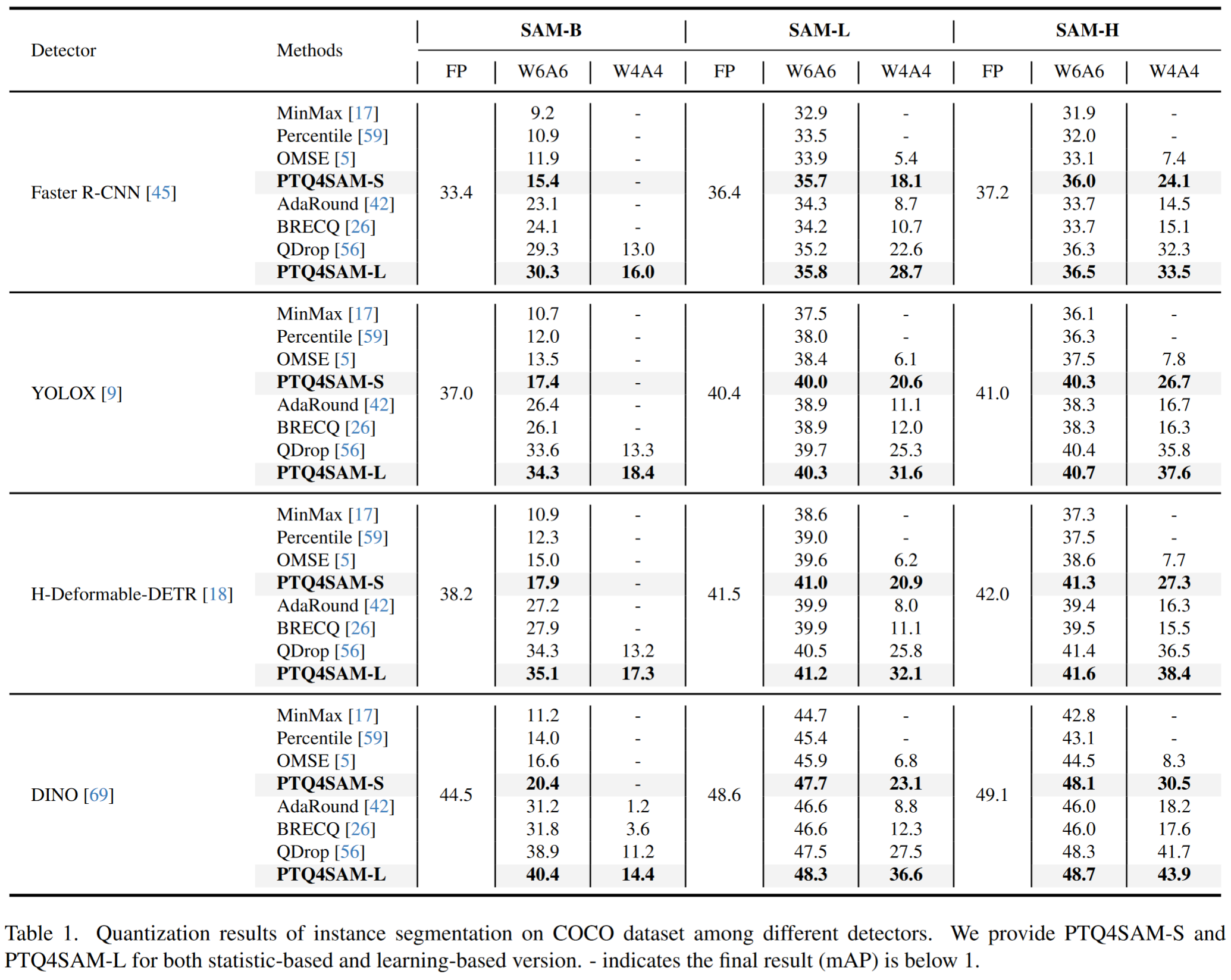
- 在不同的检测器中,我们的方法一致地优于其他方法。
- 我们的 PTQ4SAM-S 甚至在 SAM-L 的 W6A6 数据集上显著地超过了目前最好的基于学习的方法 QDrop
- 在 SAM-L 和 SAM-H 上,6 位 PTQ4SAM-L 甚至取得了比全精度模型更好的性能。在 W4A4 设置下,我们的方法在 SAM-L 上提供了 1.04%的精度提升,比 QDrop 提高了 0.15 %。
-
为了验证 PTQ4SAM 在两种 PTQ 方法中的有效性,我们将我们的方法集成到基于统计的 OMSE 和基于学习的 QDrop 中,称为 PTQ4SAM-S 和 PTQ4SAM-L
-
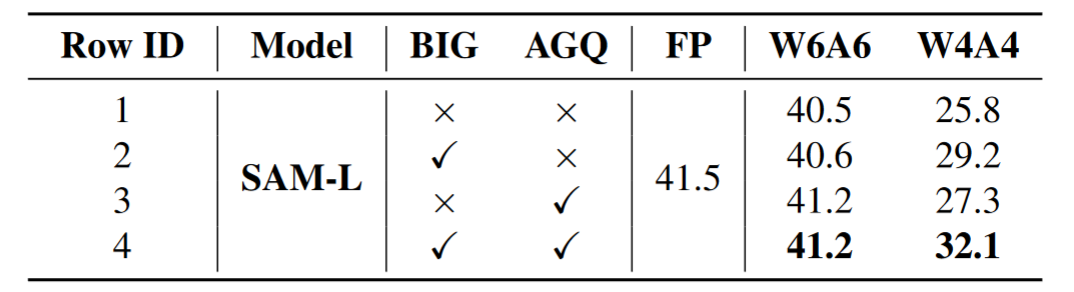
消融实验中我们证明了每个组分对 PTQ4SAM 都有贡献,而当两个组分共同应用时,性能达到最佳
-
在 W4A4 上,我们的方法将计算的 FLOP 降低了 70 %以上,存储减少了 85 %以上。随着模型规模的增大,加速比和内存节省都变得更加显著,而性能下降则变得更少。
code
PTQ4SAM 源码分析
1 | ├── ckpt #源模型权重 |
1 | export CUDA_VISIBLE_DEVICES=2 |
Bimodal distributions mainly occur in the
mask decoderof SAM-B and SAM-L.
运行结果:
- quant_model 主要是 quant 了 SAM 中的 image_encoder,mask_decoder 部分代码,没有量化 prompt_encoder
- BIG 策略用于
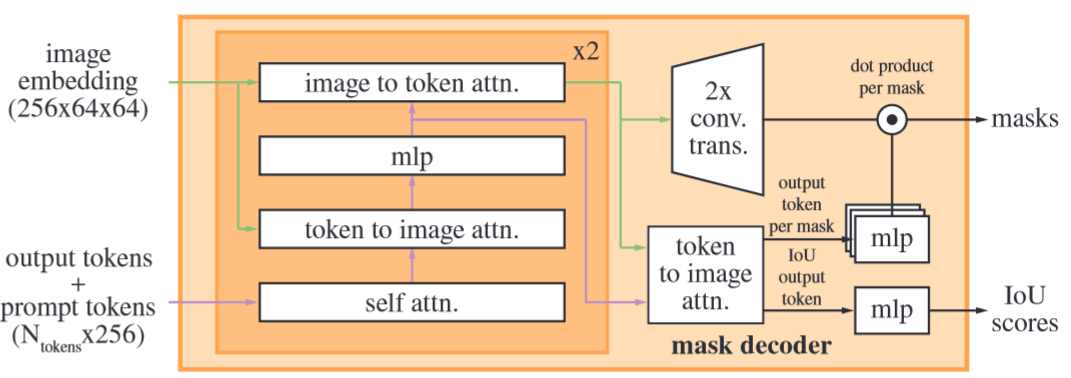
DecoderAttention(mask_decoder),而双峰分布主要集中于 mask decoder 中 image-embedding 后,具体在 token-to-image 这个 cross-attn 处使用了双峰聚合
1 | def bimodal_adjust(model): |
- AGQ 策略用于
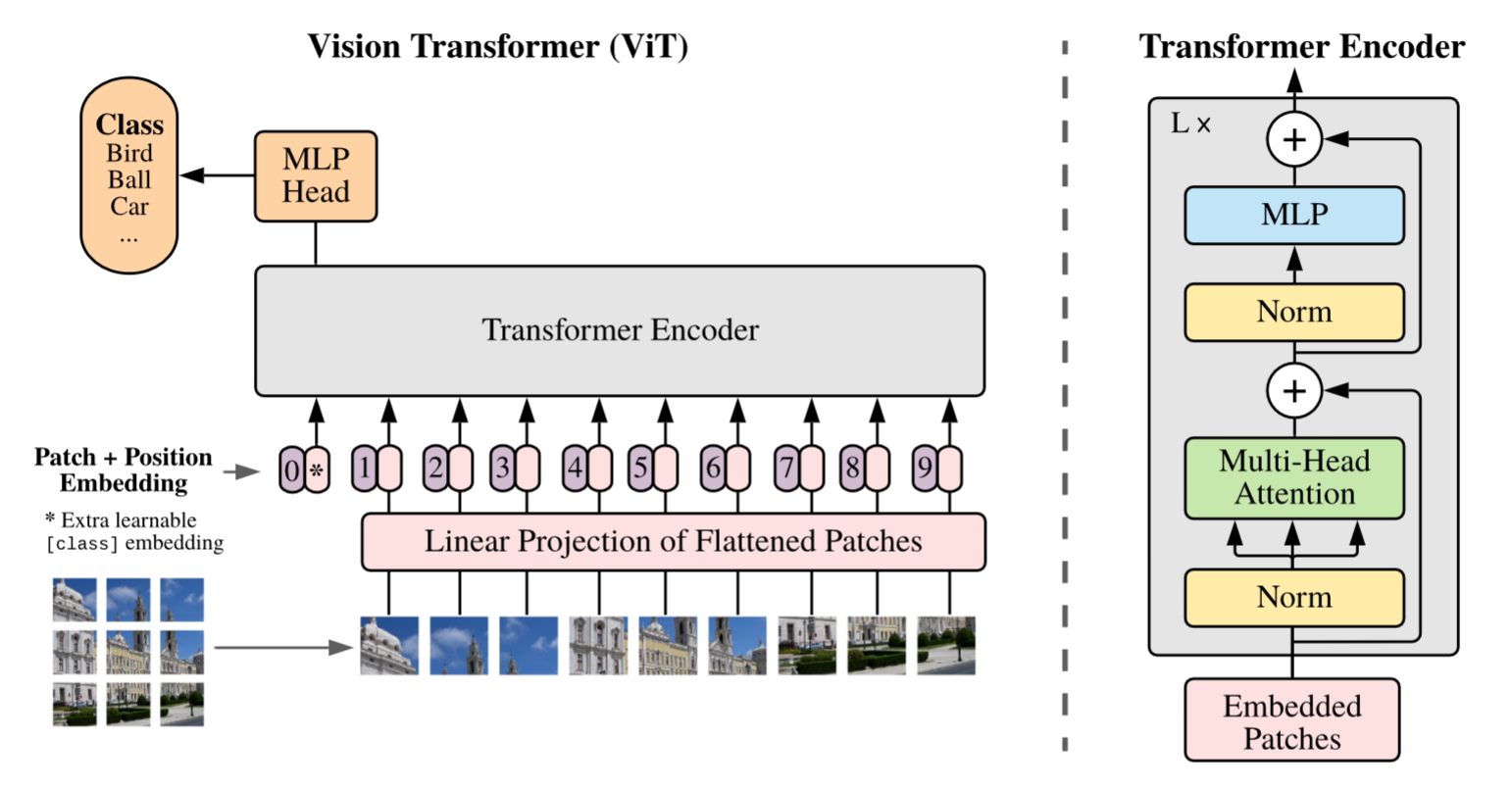
EncoderAttention(image_encoder)和DecoderAttention(mask_decoder),image_encoder 中为下图中使用的 Multi-Head Attention 处的 self-attn 使用,mask_decoder 具体为下图中 self-attn 和 token-to-image 和 image-to-token 两个 cross-attn 中
- 将提供的 base 模型进行了运行,模型占用显存约 20G,单卡运行平均约 9h
--quant-encoder的作用(提速)
- Title: ML-paper-PTQ4SAM
- Author: Charles
- Created at : 2024-07-14 13:50:29
- Updated at : 2024-07-29 14:38:07
- Link: https://charles2530.github.io/2024/07/14/ml-paper-ptq4sam/
- License: This work is licensed under CC BY-NC-SA 4.0.


