
ML-paper-SAM
SAM
核心问题:
通过引入三个相互关联的组件来构建分割的基础模型:一个可提示的分割任务,一个通过提示工程为数据标注提供动力并允许零样本转移到一系列任务的分割模型( SAM ),以及一个用于收集 SA-1B 的数据引擎,我们的数据集超过 10 亿个掩码。
对于 CV 领域而言,基础模型的发展不如 NLP 领域如 GPT 那样蓬勃发展,但本篇论文提出的 SAM 模型可以在多个下游任务上实现 zero-shot 能力,很好地填补了 CV 在这一领域的空缺,换言之,Segment Anything 项目是将图像分割提升到基础模型时代的一次尝试。
核心方法(贡献):
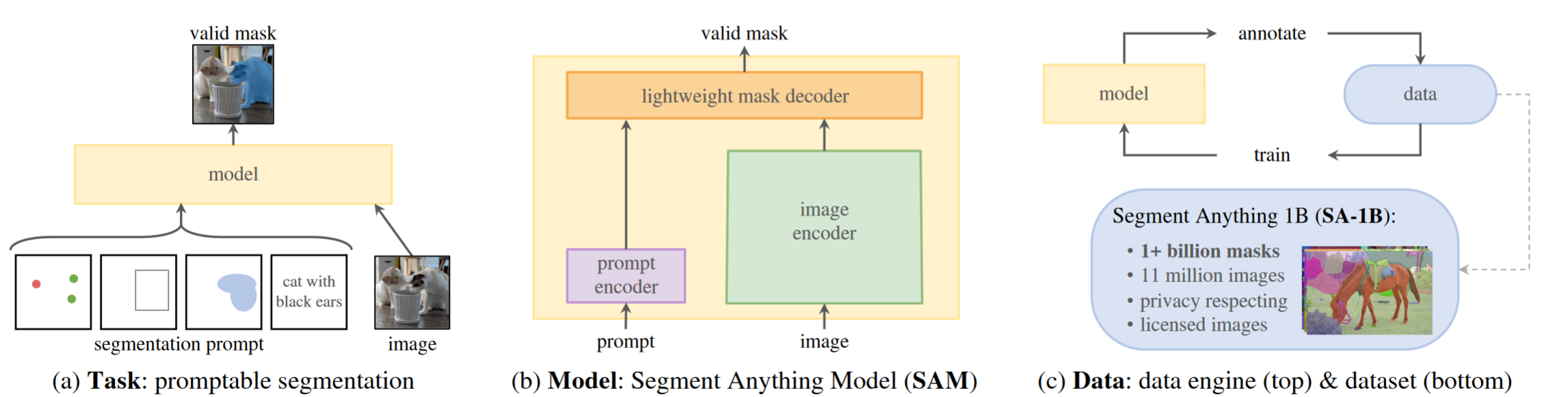
- 利用我们在数据收集循环中的高效模型,我们构建了迄今为止(迄今为止)最大的分割数据集,在 11M 授权和隐私保护图像上有超过 10 亿个掩码
- 该模型被设计和训练为可提示的,因此可以将零样本转移到新的图像分布和任务中
实验效果:
- 我们评估了它在许多任务上的能力,发现它的零样本性能令人印象深刻——往往与之前的完全监督结果竞争,甚至优于之前的完全监督结果
- 我们在使用提示工程的零样本传输协议下的各种下游任务上发现了一致的强大的定量和定性结果,包括边缘检测,目标建议生成,实例分割,以及文本到掩码预测的初步探索
改进方向:
-
SAM 有时会遗漏精细结构、产生幻觉、边界不够清晰等问题
-
虽然 SAM 可以实时处理提示,但是当使用较重的图像编码器时,SAM 的整体性能并不实时
-
我们对文本到掩码任务的研究是探索性的,并不完全稳健,尽管我们相信它可以通过更多的努力来改进
-
虽然 SAM 可以执行许多任务,但是如何设计简单的提示来实现语义和全景分割还不清楚
背景与相关工作
目前在图像分割领域缺乏大规模的数据集。为了解决数据集的问题,我们构建了一个"数据引擎",即在使用我们的高效模型来辅助数据收集和使用新收集的数据来改进模型之间进行迭代
- 交互式分割(Interactive Segmentation)是一种图像处理和计算机视觉中用于分离图像不同区域的方法,通常用于隔离图像中的兴趣对象或结构。
- 基础模型(Foundation Models),就指的是一种基于深度神经网络和自监督学习技术的,在大规模、广泛来源数据集上训练的 AI 模型。基础模型主要有四个特点:基于深度神经网络和自监督学习技术;采用大规模、广泛来源的数据集进行训练;通过微调等方式,可以直接在一系列下游任务上使用;参数规模越来越大。基础模型包括多种预训练模型,如 BERT、GPT-3、CLIP、DALL·E 等。
受到 NLP 领域提示词的启发,我们提出了可提示的分割任务,目标是在给定任何分割提示的情况下返回一个有效的分割掩码
- 有效输出掩码的要求是指,即使当一个提示是模糊的并且可以引用多个对象(例如,衬衫上的一个点可能表示衬衫或穿着它的人)时,输出应该是这些对象中至少一个的合理掩码,为了使 SAM 具有歧义感知能力,我们设计它来预测单个提示的多个掩码,使 SAM 能够自然地处理歧义
- 我们使用可提示的分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务
- 我们重点关注点、方框和掩码提示,并使用自由形式的文本提示呈现初始结果
尽管基础模型的典型方法是在线获取数据,但掩码并不是天然丰富的,为此我们将我们的模型与模型在环数据集标注共同开发
方法理论
Segment Anything Task
为了建立分割的基础模型,我们的目标是定义一个具有类似能力的任务
Task:提示分割任务就是在给定任何提示的情况下返回一个有效的分割掩码
- 我们选择这个任务是因为它引出了一个自然的预训练算法和通过提示将零样本转移到下游分割任务的通用方法
提示分割任务提出了一种自然的预训练算法,为每个训练样本模拟一个提示序列(例如,点、盒子、面具等),并将模型的掩码预测与真实值进行比较。我们注意到,在这个任务中表现良好是具有挑战性的,需要专门的建模和训练损失选择。
我们的预训练任务赋予模型在推理时对任何提示做出适当反应的能力,因此下游任务可以通过工程适当的提示来解决
我们的即时分割任务的目标是产生一个具有广泛能力的模型,可以通过快速工程适应许多(虽然不是全部)现有和新的分割任务。(注意这里提到 SAM 还可以 zero-shot 到一些目前还没有提出的分割任务中,而不是单纯具有多个任务的分割能力[论文中提到区分二者的主要方法是 SAM 允许训练集和测试集的任务不相同])
Segment Anything Model
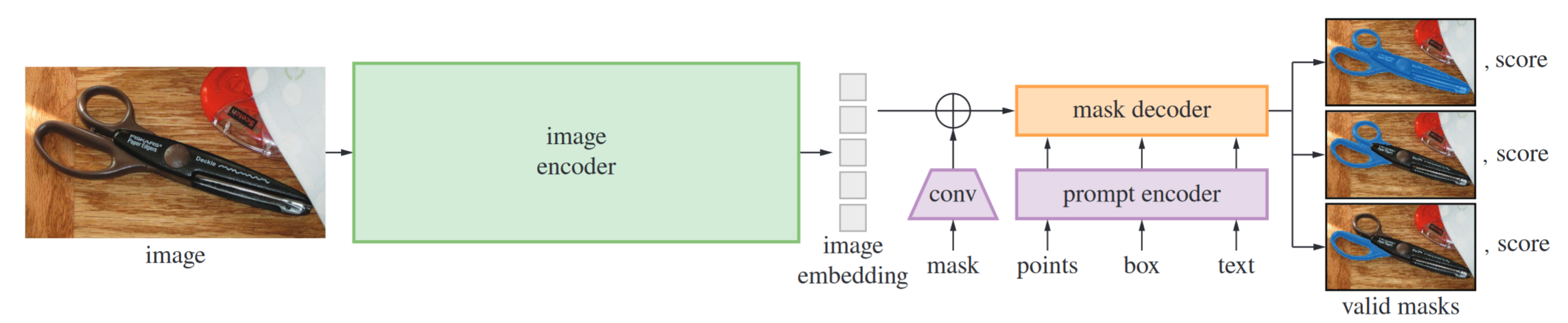
SAM 有 3 个组成部分,Image encoder、Prompt encoder 和 Mask decoder。
-
Image encoder:使用 MAE 预训练的 ViT 作为 Image encoder
- 由于我们的运行时目标是实时处理每个提示符,所以我们可以提供大量的图像编码器 FLOP,因为它们只计算每张图像一次,而不是每一个提示符一次

- 由于我们的运行时目标是实时处理每个提示符,所以我们可以提供大量的图像编码器 FLOP,因为它们只计算每张图像一次,而不是每一个提示符一次
-
Prompt encoder:我们考虑两组提示:稀疏(点、框、文字)和稠密(掩码)。
- 稀疏提示被映射为 256 维向量嵌入
- 我们用位置编码来表示点和框,这些位置编码是由 CLIP 提供的一个现成的文本编码器对每个提示类型和自由形式文本的学习嵌入加总得到的
- 密集提示(mask)使用卷积嵌入,并与图像嵌入按元素求和
-
Mask decoder:掩码解码器有效地将图像嵌入、提示嵌入和输出 token 映射到掩码
- 我们改进的解码器块使用两个方向的提示自注意力和交叉注意力(即 prompt-to-image embedding 和 image-to-prompt embedding)来更新所有嵌入
- 我们对图像嵌入进行上采样,MLP 将输出 token 映射到一个动态线性分类器,然后在每个图像位置计算掩码前景概率
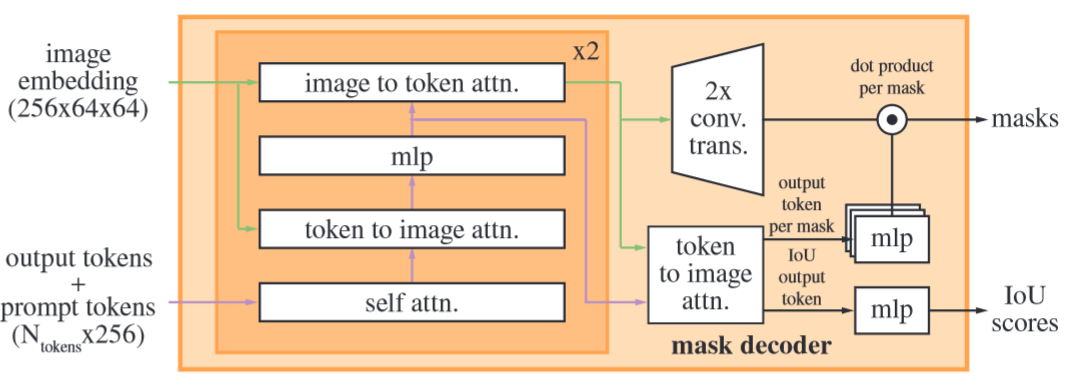
对于一个输出,如果给定一个模糊的预测,模型将平均多个有效的掩码,为了解决这个问题,我们修改模型来预测单个提示的多个输出掩码

- 我们发现 3 个掩码输出足以处理大多数常见情况
在 CPU 上 SAM 推理完成在 50ms 内,这种运行时性能使得我们的模型能够实现无缝、实时的交互提示。
Segment Anything Data Engine
该数据引擎分为 3 个阶段:
- 模型辅助的人工标注阶段;
- 自动预测掩码和模型辅助标注混合的半自动阶段;
- 全自动阶段,模型无需标注器输入即可生成掩码
| stage | retrain model times | images number | mask number | average number of masks per image |
|---|---|---|---|---|
| Assisted-manual stage | 6 | 120K | 4.3M | 20->44 |
| Semi-automatic stage | 5 | 180K | 5.9M | 44->72 |
| Fully automatic stage | 11M | 1.1B | 100 |
Fully automatic stage 的输出是数据集 SA-1B
Assisted-manual stage
我们的模型辅助标注直接在浏览器(使用预计算的图像嵌入)内部实时运行,实现了真正的交互体验
Semi-automatic stage
在这一阶段,我们旨在增加掩码的多样性,以提高模型对任何事物的分割能力。我们向注释者展示预先填充这些 masks 的图像,并要求他们标注任何额外的未标注对象
Fully automatic stage
在最后阶段,注释是完全自动的
- 首先,在这个阶段开始时,我们已经收集了足够的掩码来极大地改进模型,包括上一阶段的多样化掩码。
- 其次,在这个阶段,我们开发了歧义感知模型,该模型允许我们即使在歧义的情况下也能预测有效的掩码。
- 在歧义感知模型中,如果一个点位于某个部分或子部分,我们的模型将返回子部分、部分和整个对象。
Segment Anything Dataset
我们的数据集 SA - 1B 由我们的数据引擎收集的 11M 多样、高分辨率、许可和隐私保护的图像和 1.1 B 高质量的分割 masks 组成
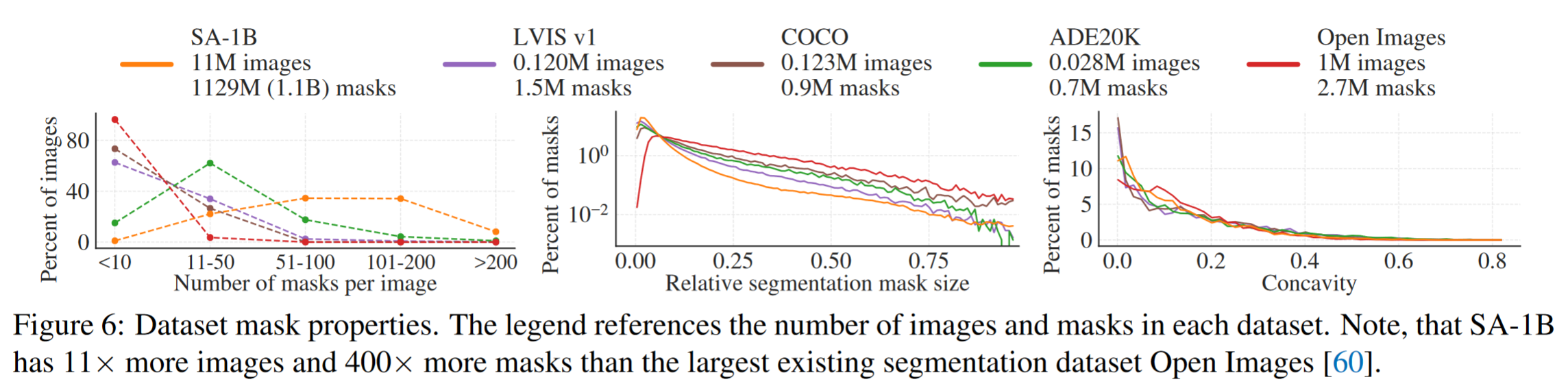
实验工作
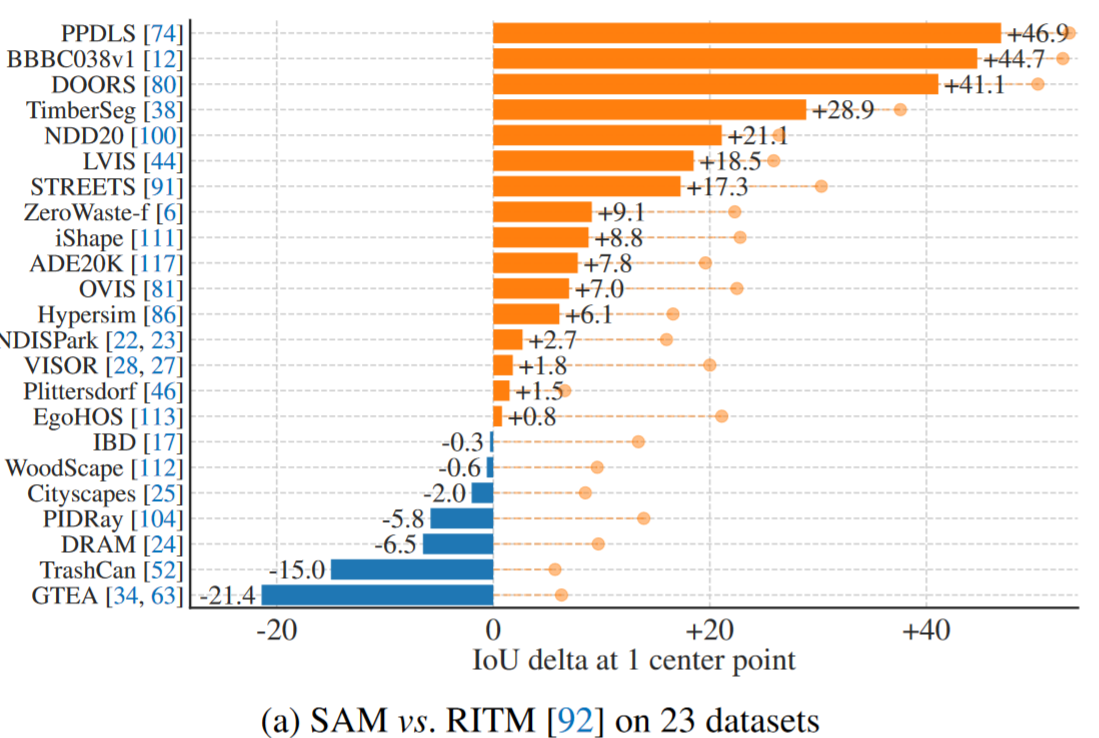
我们的实验从测试提示分割的核心目标开始:从任何提示中产生有效的掩码
- 特别地,在使用 oracle 进行模糊度解算时,SAM 在所有数据集上都优于 RITM
- Title: ML-paper-SAM
- Author: Charles
- Created at : 2024-07-22 08:06:47
- Updated at : 2026-05-11 20:11:22
- Link: https://charles2530.github.io/2024/07/22/ml-paper-sam/
- License: This work is licensed under CC BY-NC-SA 4.0.