
ML-paper-SlimSAM
SlimSAM
Slim SAM 的精髓被封装在交替瘦身框架中,在训练数据可获得性严重受限和异常剪枝比例的情况下,有效地增强了知识的继承性
核心问题: SAM 从头训练需要大量的数据,如果使用传统剪枝方式可以减少数据需求量但会造成模型表现的退化,如果更改模型架构则需要重新训练耗时耗力
核心方法(贡献):
- 一种数据高效的 SAM 压缩方法称为 SlimSAM,该方法有效地重用了预训练的 SAM,而不需要进行大量的再训练
- 通过提出替代瘦身框架,并引入 disturbed Taylor importance 的概念,我们实现了材料限制情境下知识保持能力的大幅提升
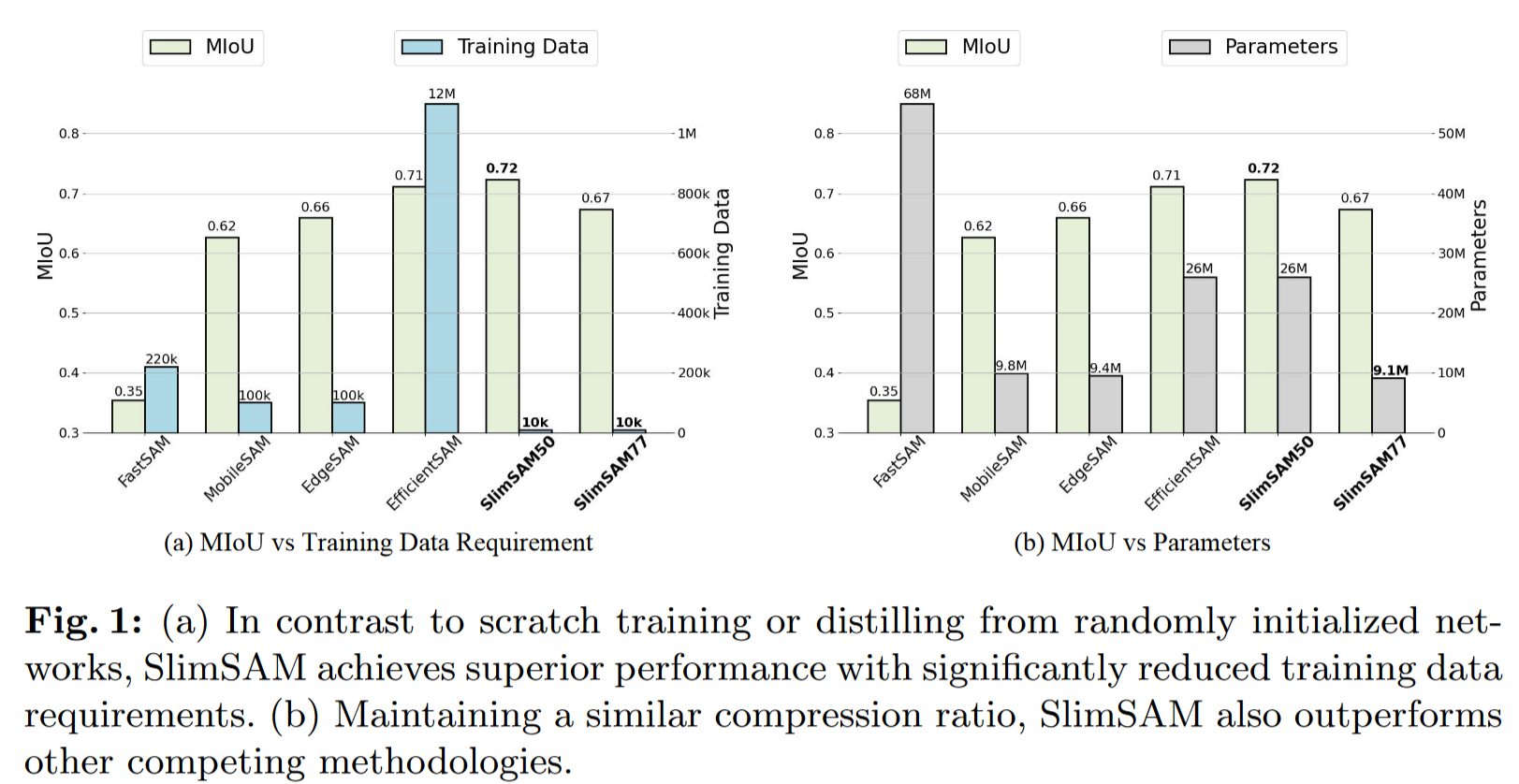
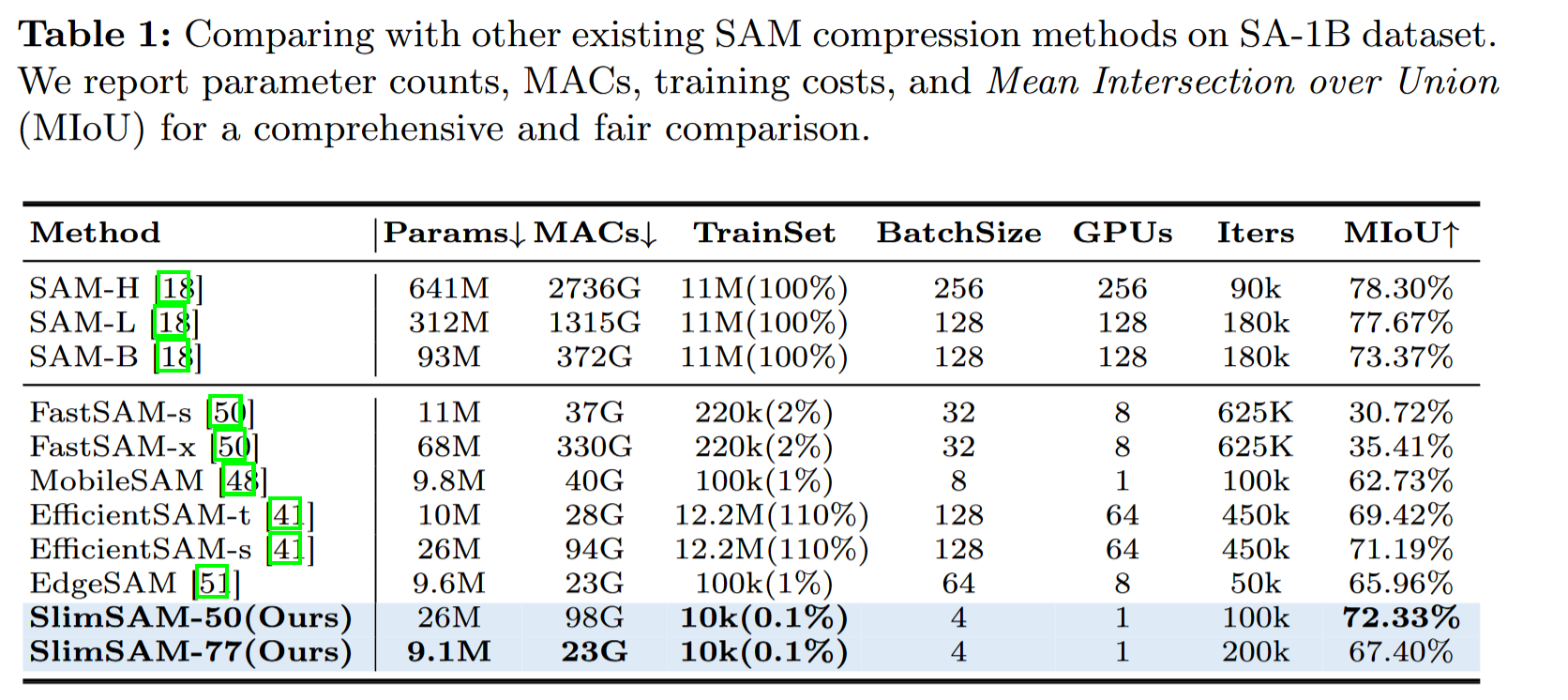
**实验效果:**与原始 SAM - H 相比,Slim SAM 在降低参数数量至 1.4 % ( 9.1M )、MACs 至 0.8 % ( 23G )、仅需要 0.1 % ( 10k )的训练数据的情况下,获得了接近的性能
改进方向:
背景与相关工作
-
尽管 SAM 具有出色的性能,但其庞大的模型规模和高计算需求使其在资源受限设备上的实际应用中显得力不从心。
-
之前论文为了压缩模型的做法均选择将原本重量级的图像编码器替换为具有轻量级、高效的架构,但这导致需要从头开始重新训练模型。
-
当使用非常有限的数据进行训练时,现有的方法都不可避免地降低了性能。
-
为了解决上述问题,应当应用剪枝技术通过从网络中移除冗余参数和用最小数据集微调精简模型来直接压缩规模庞大的 SAM,但直接进行传统剪枝会造成意想不到的陡峭的性能下降,特别是当剪枝率设置得非常高并且可用的数据非常稀缺时。
-
从标准的剪枝-微调工作流程开始,我们逐步"现代化"压缩过程,引入我们的新设计,定制严重受限的数据可用性和 SAM 的复杂耦合结构,最终在需要最少的训练数据的情况下实现了卓越的效率。
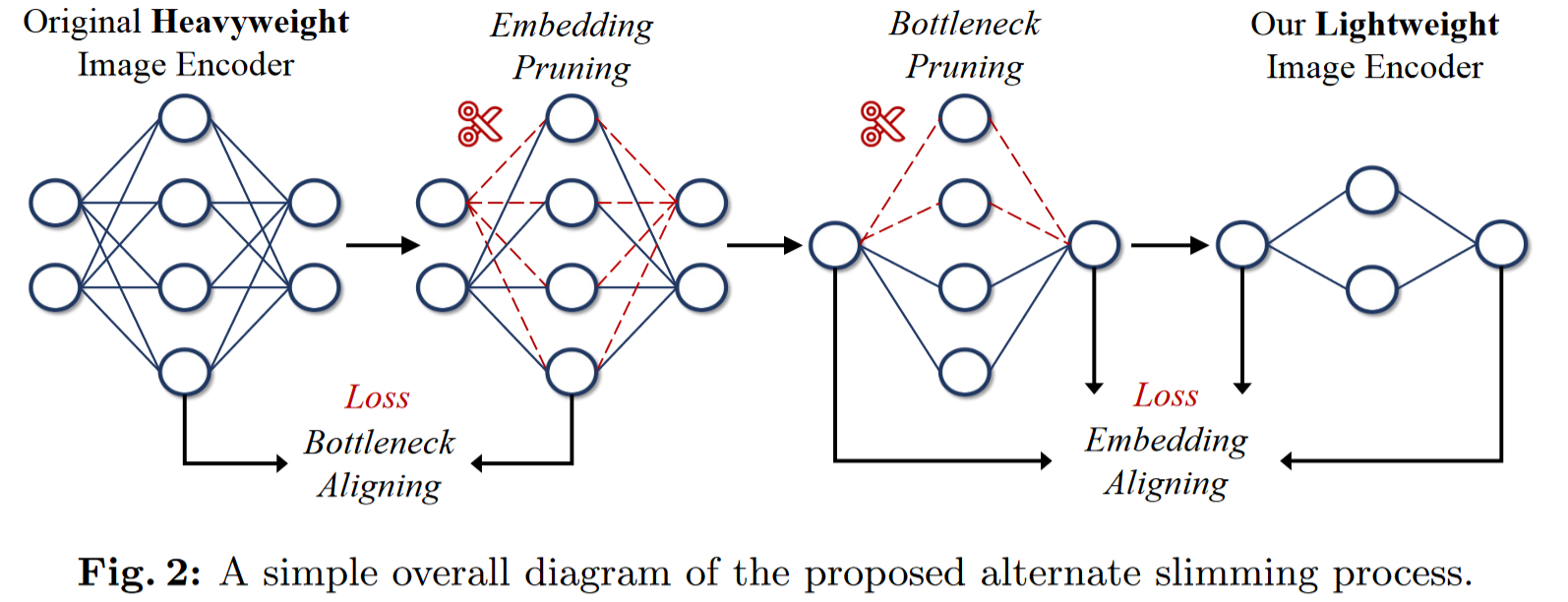
- 交替瘦身框架:该过程从目标嵌入维度开始进行剪枝,并对齐一致的瓶颈维度进行蒸馏。然后,它将重点转移到剪枝
ViT中的瓶颈维度,对齐未改变的嵌入维度进行蒸馏 - 扰动泰勒剪枝:修剪对象和蒸馏目标之间的不对齐性阻碍了压缩的功效,我们引入了一种新的无标签重要性估计准则,称为扰动泰勒重要性,以解决这种不对称性
- 交替瘦身框架:该过程从目标嵌入维度开始进行剪枝,并对齐一致的瓶颈维度进行蒸馏。然后,它将重点转移到剪枝
Model Pruning
Model pruning 是一种优化深度学习模型的方法,主要目的是减少模型的复杂度和提高模型的效率,同时尽量保持模型的性能。这种方法在处理大型模型或需要在资源受限的设备上运行模型时特别有用。
-
由于深度神经网络固有的参数冗余,模型剪枝已被证明是加速和压缩模型的有效方法。
-
结构化剪枝侧重于根据预定义的标准消除参数组,而非结构化剪枝涉及到个体权重的去除,通常需要硬件支持。
Knowledge Distillation
知识蒸馏(Knowledge Distillation)是一种将大型复杂模型(通常称为“教师模型”)的知识转移到小型模型(称为“学生模型”)的技术。这种方法在深度学习领域中非常有用,尤其是在资源受限的设备上运行模型时。
- 知识蒸馏旨在将知识从更大、更强大的教师模型转移到更轻、更高效的学生模型,这个过程通常涉及软目标函数和一个温度参数,以方便学习
- 温度调整:通过调整温度参数,可以控制教师模型输出的软标签的“软度”。较高的温度会使分布更加平滑,较低的温度则接近硬标签。
- 损失函数:学生模型的损失函数不仅包括预测错误的惩罚,还可以包括与教师模型输出的距离度量(如 KL 散度)。
- 软标签学习:教师模型不仅输出最终的标签,还可以输出每个类别的软概率分布。学生模型学习这些软标签,而不仅仅是硬标签。
SAM Compression
- Fast SAM 以高效的基于 CNN 的 YOLOv8-seg 模型取代 SAM 广泛的基于 ViT 的架构
- Mobile SAM 采用轻量级的 Tinyvit 代替图像编码器,并对原始编码器进行知识蒸馏
- Edge SAM 引入 prompt-in-the-loop 知识蒸馏,精确捕捉用户输入和掩码生成之间的复杂动态
- Efficient SAM 创新性地采用 MAE 框架来获得分割任意模型的高效图像编码器,但需要比 SA-1B 数据集更广泛的训练数据
上述方法都不可避免地要经历从无到有的训练过程,导致在训练数据有限的情况下性能并不理想
方法理论
为了在保持出色的性能和丰富的训练数据的必要性之间进行具有挑战性的权衡,我们采用了直接继承原始 SAM 中核心权重的策略。该方法利用 SAM 强大的先验知识,从 1100 万张图像中获得
对模型进行初始剪枝,然后通过后蒸馏进行精化
Identifying SAM Redundancy
初始阶段致力于估计每个参数的重要性,确定要修剪的图像编码器的非必要和冗余参数
-
我们试图通过量化一个参数被移除后所产生的预测误差来估计该参数的重要性
-
估计一个参数重要性的公式:

-
上述泰勒重要性估计在剪枝 SAM 的图像编码器时存在两个明显的局限性
- 在知识蒸馏的背景下,某些技术(如泰勒展开)的准确性依赖于硬标签的可用性,但由于联合优化图像编码器和解码器的复杂性,后蒸馏过程需要专注于图像嵌入的处理,这使得软标签的使用变得排他性,即在这种情况下,可能无法同时利用硬标签和软标签的优势。
- 在深度学习中,训练数据通常包括输入数据和对应的标签。硬标签(hard labels)指的是明确的、确定的标签,比如在分类任务中,标签是具体的类别编号。
- 软标签(soft labels)指的是表示类别概率的标签,而不是具体的类别编号。在知识蒸馏中,教师模型通常会输出软标签,而不是硬标签。
- 在使用泰勒重要性估计进行 SAM 剪枝时,损失函数的一致性引起了关注,即分别使用硬标签$y_i$和软标签$t_i$带入上述公式进行参数重要性计算时,会形成不同的损失函数计算,这种优化目标的不对称性可能会阻碍精馏过程的效率
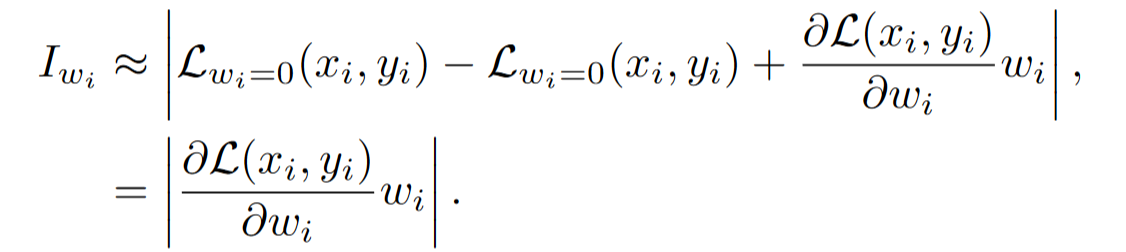
Disturbed Taylor importance
- 扰动泰勒重要度的公式为
- 利用我们的扰动泰勒重要度,剪枝目标与后续精馏的优化目标无缝对齐
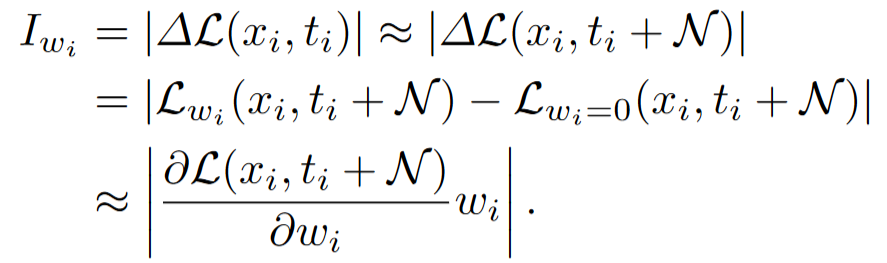
Alternate Slimming
在估计权重的重要性后,我们的方法在扩展的图像编码器上执行通道结构剪枝,然后基于蒸馏的模型微调。
当剪枝率超过 75%时,剪枝后的模型与原模型相比性能明显下降
- 我们引入了一个创新的替代瘦身框架,以两个原则为基础:减少原始模型和修剪模型之间的差异,以及增强蒸馏后的效果。
- 我们的框架将模型分解为两个独立的子结构:嵌入(每个块的输出尺寸)和瓶颈(每个块的中间特征)
交替瘦身过程可以描述为以下渐进过程:嵌入剪枝、瓶颈对齐、瓶颈剪枝和嵌入对齐。
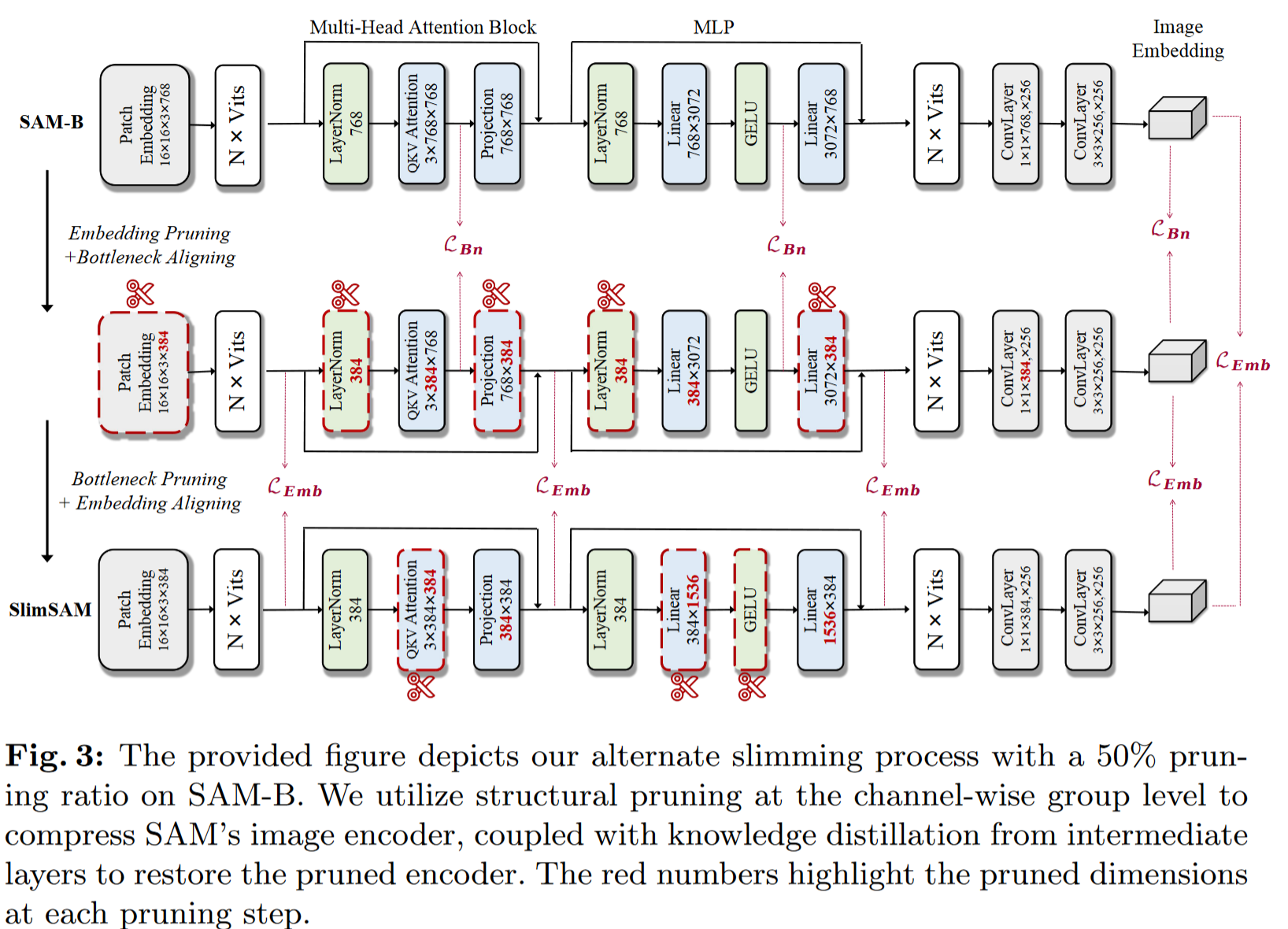
Embedding Pruning
嵌入维数显著影响编码器的性能,因为它决定了编码器中提取的特征的宽度
Bottleneck Aligning
剪枝后的编码器从原始编码器的输出 tv0 中学习,并在每个块中与其维度一致的瓶颈特征 Hv0 对齐
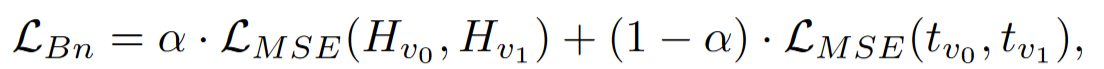
Bottleneck Pruning
由于每个分块中的中间特征的维度是完全解耦的,因此我们可以在保持预定的整体剪枝比例的同时,对每个分块系统地进行不同比例的维度剪枝
Embedding Aligning
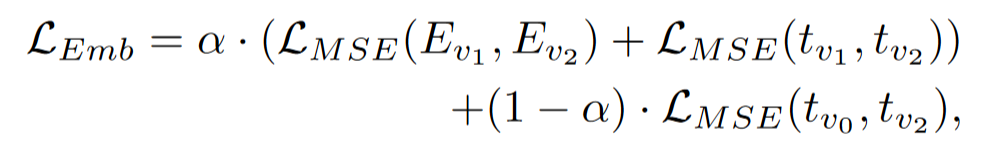
实验工作
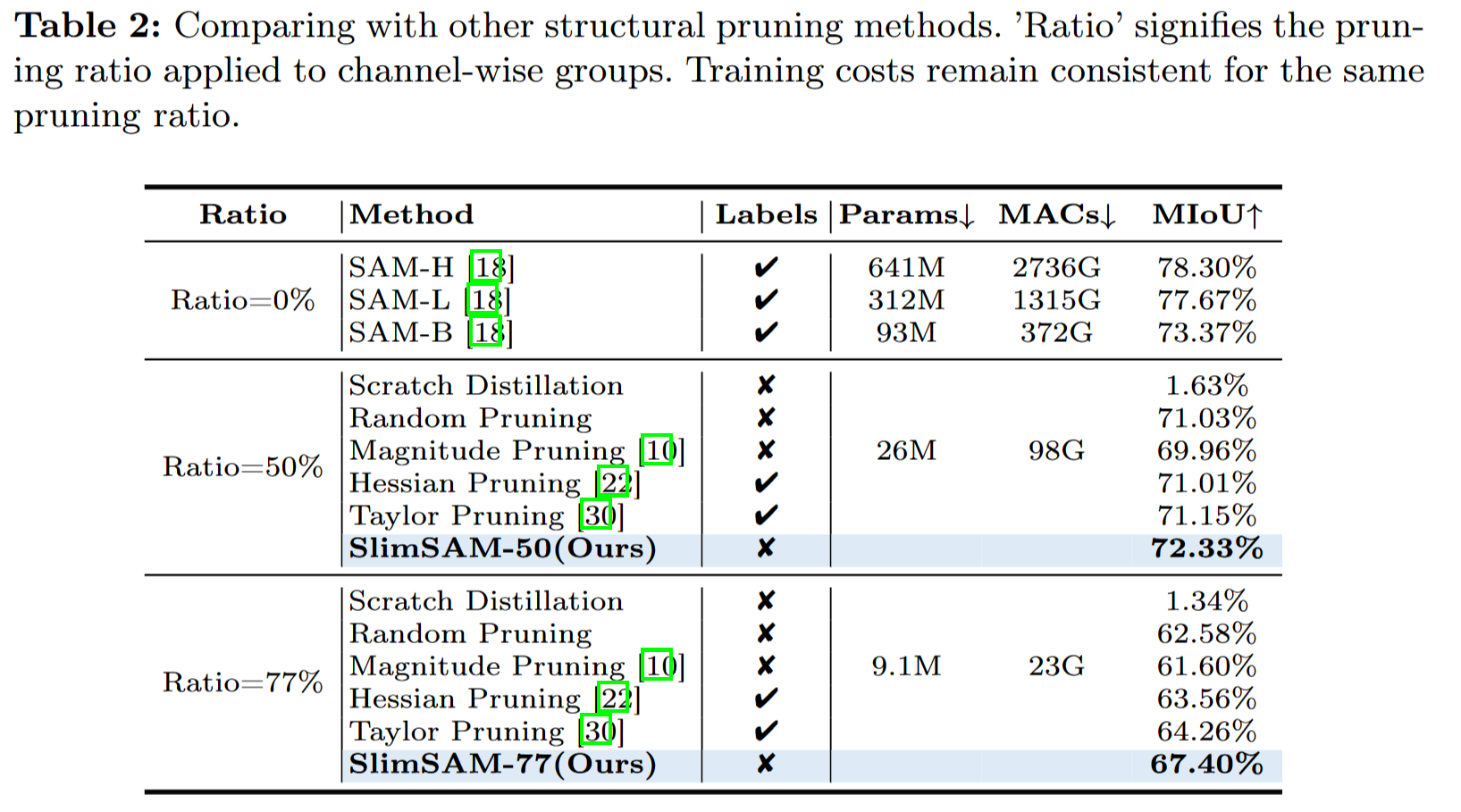
-
为了保证对压缩后的 SAM 模型进行公正的定量评估,我们计算了模型预测的掩码与 SA-1B 数据集的真实掩码之间的 MIoU
MIoU(Mean Intersection over Union)是一种常用于语义分割任务的评价指标。它通过比较预测的分割结果与真实的分割结果,计算它们的交集和并集,然后计算交集与并集的比值来衡量算法的性能。
- Title: ML-paper-SlimSAM
- Author: Charles
- Created at : 2024-07-25 16:53:03
- Updated at : 2024-07-29 14:38:05
- Link: https://charles2530.github.io/2024/07/25/ml-paper-slimsam/
- License: This work is licensed under CC BY-NC-SA 4.0.

