
ML-paper-QQQ
QQQ: Quality Quattuor-Bit Quantization for Large Language Model
**核心问题:**如何有效地压缩大型语言模型(LLMs)以减少存储和计算开销,同时保持模型性能,并加速推理过程。
核心方法(贡献):
- QQQ 量化方法:一种 4 位权重和 8 位激活(W4A8)的量化方法,通过自适应平滑和基于 Hessian 的补偿显著提高量化模型的性能。
- W4A8 GEMM 内核:为每通道和每组权重量化精心设计的 W4A8 GEMM 内核,,可以同时为每个通道权重和每个组权重量化定制,显著提高了推理速度。
- 将 QQQ 集成到 vLLM 中
实验效果:
- QQQ 在与现有最先进的 LLM 量化方法相当的性能下,显著加速了推理过程。
- 实验表明,QQQ 在不同模型上实现了高达 2.24 倍、2.10 倍和 1.25 倍的速度提升,分别与 FP16、W8A8 和 W4A16 相比。
改进方向:
- 量化模型的时间:两阶段量化方法需要更多的时间来量化模型。
- 混合精度 GEMM 的支持:目前只支持 4 位权重。
背景与相关工作
近年来,大型语言模型(LLMs)在各种任务中表现出色,但由于其庞大的参数数量和长时间的推理时间,限制了其在资源有限的设备和实时场景中的应用。量化是减少 LLMs 内存和计算需求的关键技术。现有的量化策略主要包括权重-激活量化和仅权重量化。
weight-activation-quant
- Smooth Quant、LLM.int8()、QUIK 和 Outlier Suppression+均通过管理激活异常值来提升量化模型性能。
- LLM.int8()和 QUIK 使用混合精度分解,而 SmoothQuant 和 Outlier Suppression+使用通道尺度变换。
- Omni-Quant 提出了可学习的权重裁剪和可学习的等价变换。
weight-only-quant
- GPTQ 采用二阶信息来最小化精度损失。
- SpQR 和 AWQ 优先保留重要权重以减少量化误差,SpQR 采用混合精度,AWQ 优化每通道缩放。
- QuIP 进一步将权重量化到 2-bit,其依据是模型参数在理想情况下应该是不相干的。
方法理论
QQQ 是一种两阶段的权重-激活量化方法,集成了自适应平滑和基于 Hessian 的量化补偿,以增强量化模型的性能。QQQ 通过自适应平滑机制对具有显著异常值的激活通道进行平滑处理,同时保留其他通道。平滑处理后,QQQ 采用基于 Hessian 的补偿技术来抵消权重量化的损失。
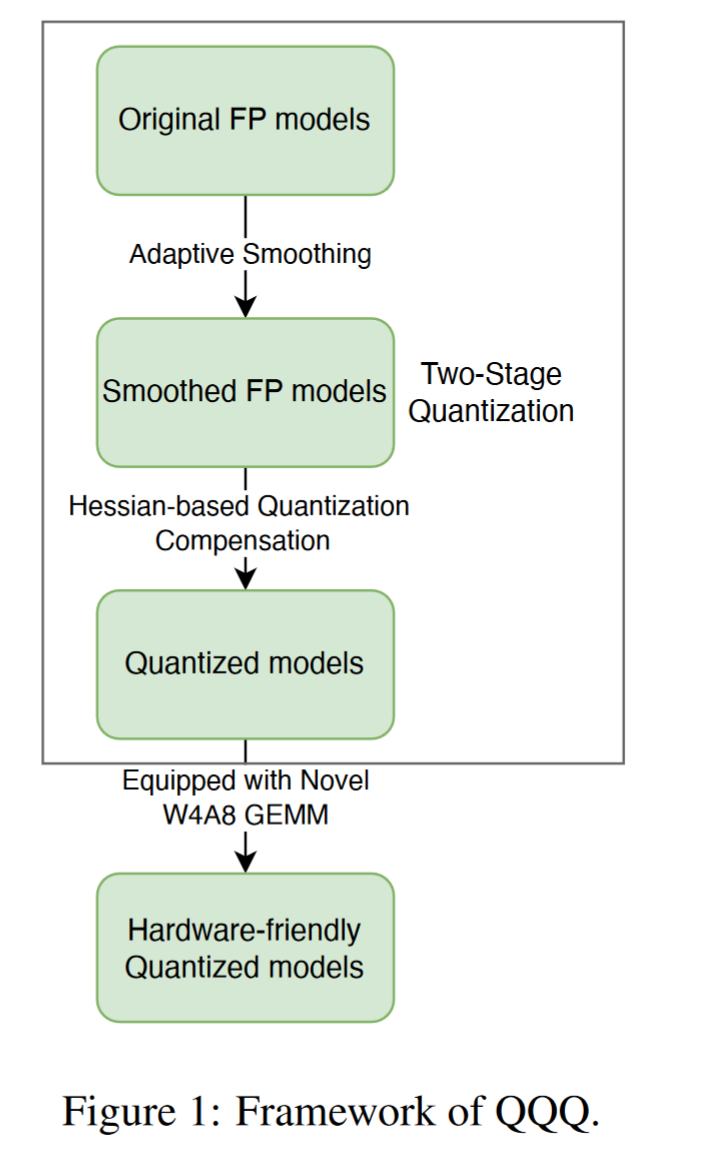
自适应平滑
通过通道平滑来改进具有异常值的激活通道,使其更适合量化。
- 只对存在显著异常值的激活通道进行平滑处理,而保持其他通道不变,可以提高量化模型的性能
- 通过设置离群值阈值来判断是否进行平滑处理
Hessian-based Quantization Compensation
采用基于 Hessian 的量化补偿技术,通过迭代量化权重来提高量化精度。
- 我们采用了一种逐层量化框架 GPTQ ,它倡导一种精确高效的基于 Hessian 的量化补偿技术
新型 W4A8 GEMM
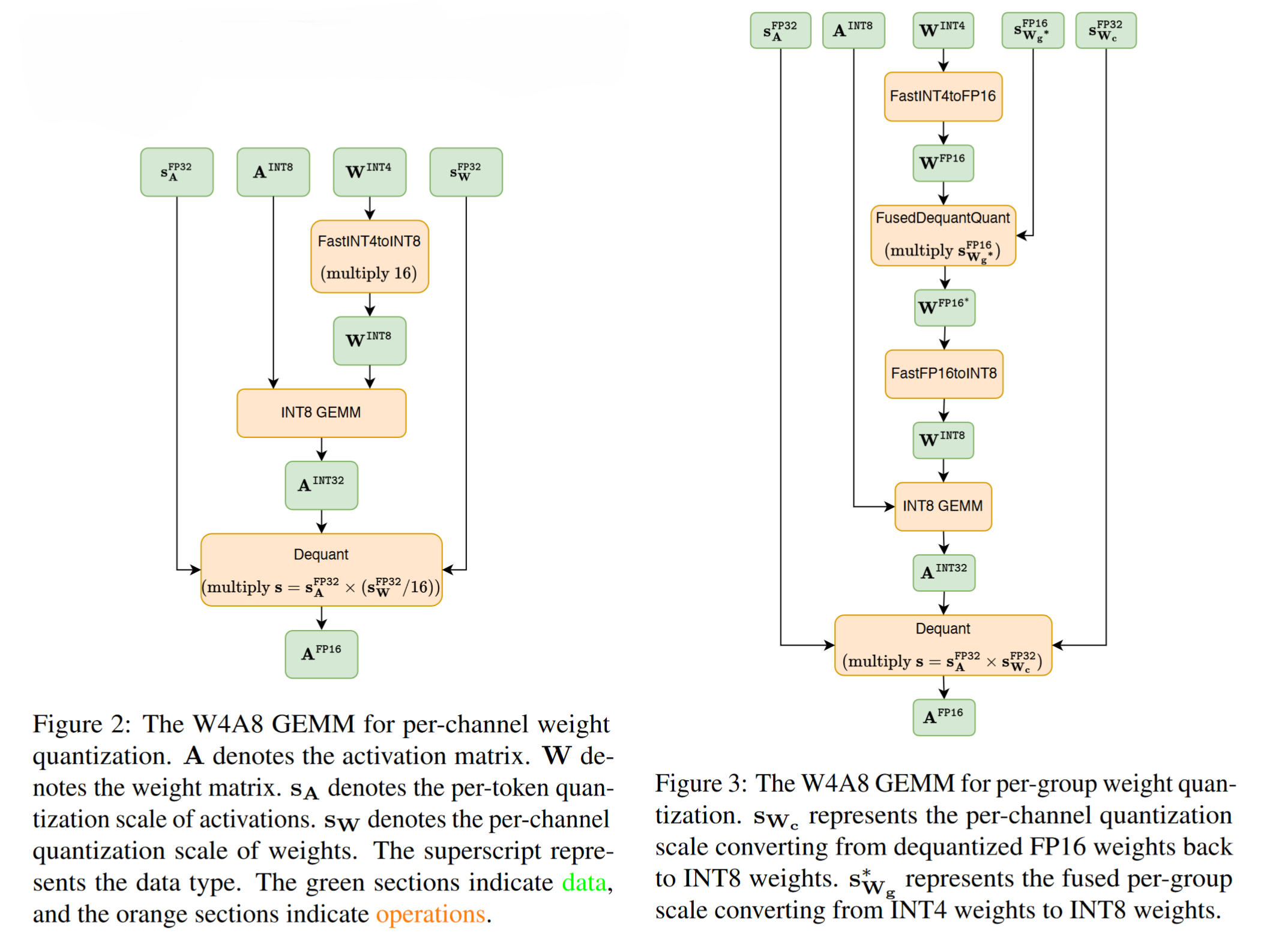
开发了创新的 W4A8 GEMM 内核,优化了推理速度。设计考虑了对称量化的优势,并集成了类型转换和去量化过程。
- 我们的设计完全支持对称量化,因为它比非对称量化具有更高的硬件效率
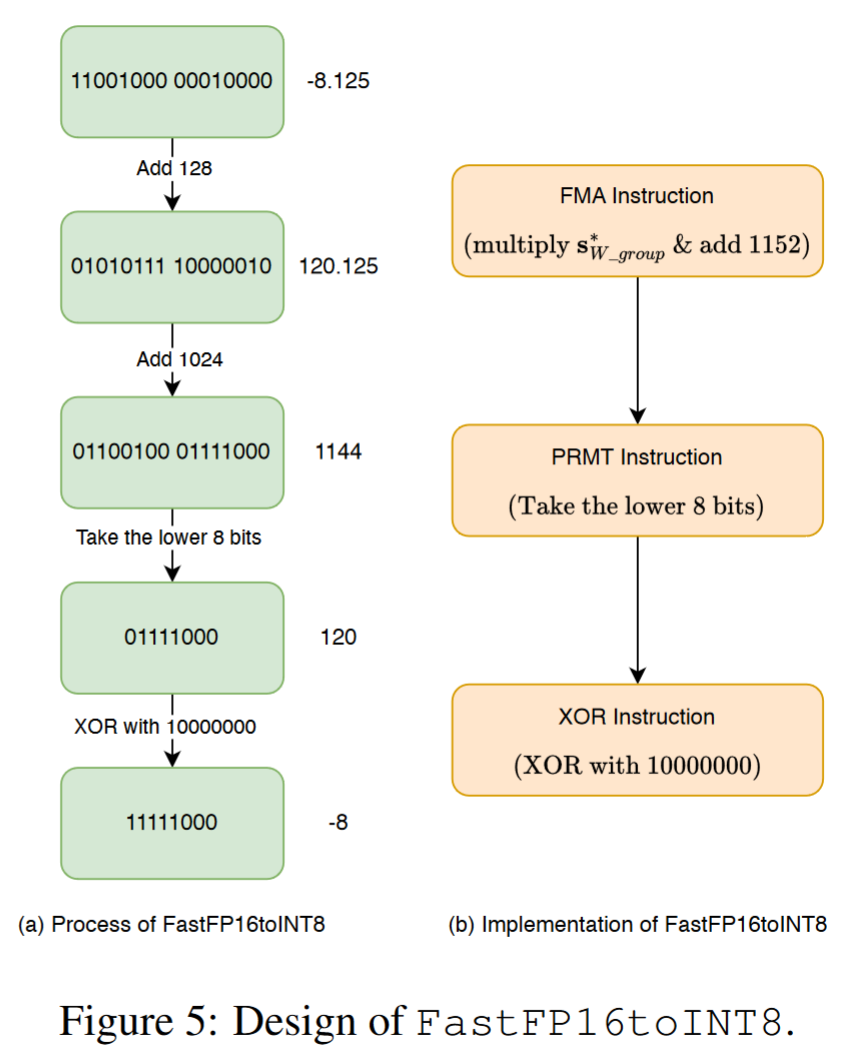
- 为了保证高效的类型转换,我们使用了 FastINT4toINT8 技术

实验工作
- 模型和数据集:使用 LLaMA 系列模型,评估语言建模和零样本任务的性能。
- 算法:QQQ 专注于每 token 激活的量化,并支持每通道和每组权重的量化。
- 推理系统:基于 vLLM 和 Marlin 内核实现的推理系统,支持 QQQ 方法。
- Title: ML-paper-QQQ
- Author: Charles
- Created at : 2024-07-28 08:34:18
- Updated at : 2024-07-29 14:38:06
- Link: https://charles2530.github.io/2024/07/28/ml-paper-qqq/
- License: This work is licensed under CC BY-NC-SA 4.0.
recommend_articles



recommend_articles
Comments