
扩散模型:一步生成、蒸馏与整流:把多步纠错压成少数大跳
扩散采样慢,不只是因为循环次数多。多步采样的每一步都在做小修正:先定大结构,再补关系、材质、边缘和高频纹理。把 30 步、50 步压到 4 步甚至 1 步,等于要求学生模型一次跨过教师原来很多个噪声区间。
采样器不再有几十次纠错机会时,少步模型要同时保住分布、细节、多样性和条件控制。
少步生成把线上推理成本转移到离线训练里。Progressive Distillation 压缩教师轨迹,Consistency / LCM 学同一轨迹终点一致,DMD / DMD2 直接匹配最终分布,Rectified Flow / Rectified Diffusion 重新设计生成路径。它们都在换取更少 NFE,但付出的训练成本和失败模式完全不同。
少步学生少了什么
一个多步教师从噪声到图像通常走一串状态:
这里 是初始噪声, 是最终干净样本,中间的 是采样器逐步修正后的状态。如果学生只保留 个时间点:
是学生保留的粗时间点, 表示学生步数远少于教师。难点在于:学生的每一步不再是微小去噪,而是大跳。大跳会放大四类错误。
| 错误 | 少步时为什么更严重 | 表现 |
|---|---|---|
| 轨迹误差 | 中间修正机会少,早期偏差无法慢慢纠正 | 构图漂、对象位置错 |
| 分布误差 | 学生最终样本不像 teacher / data 分布 | 模式坍塌、风格单调 |
| 高频误差 | 低噪声细节没有足够步数慢慢补 | 文字糊、边缘软、纹理假 |
| 条件误差 | CFG、ControlNet、参考图等条件被粗步长放大 | prompt 丢对象、结构控制漂 |
所以少步训练最重要的不是“让 loss 下降”,而是让真实 1/2/4/8 步推理时,上面四类错误不要一起爆出来。
四条路线先分清
| 路线 | 学什么 | 适合步数 | 主要风险 |
|---|---|---|---|
| Progressive Distillation | 学教师多步复合后的结果 | 4-8 步常见 | 压到极低步数后误差累积 |
| Consistency / LCM | 同一 PF-ODE 轨迹的不同噪声点映射到同一终点 | 1-4 步 | 细节和强条件控制可能变弱 |
| DMD / DMD2 | 学生最终分布接近 teacher / real 分布 | 1-4 步 | fake score / critic 跟不上会不稳 |
| Rectified Flow / Diffusion | 让生成路径更适合粗步积分 | 少步 ODE | 路径、时间采样和条件控制要重训 |
这个表比年份顺序更重要。读论文时先问它在补哪种错误:是在压缩轨迹,还是在对齐终点,还是在匹配分布,还是在重画路径。
轨迹蒸馏:把教师两步合成学生一步
Progressive Distillation 的核心可以写成:
这里 是教师采样器或教师模型的一步更新, 是学生,右边 表示教师连续两步后的复合结果。学生学会“教师两步做完的事”之后,再继续把步数减半:32 到 16,16 到 8,8 到 4。
这条路线的优点是直觉清楚。学生不是凭空学一个一步生成器,而是在教师已经验证过的轨迹上逐级压缩。它很适合把慢模型压到几步到十几步,也适合做稳定的工程加速。
局限也很清楚:越往 1-2 步压,学生每一步要承载的教师复合越长,细节、条件和多样性越容易被均值化。Progressive Distillation 像把老师的很多小笔画合并成少数大笔画;合并到 4 笔还可能保住轮廓,硬压成 1 笔就很难同时画出结构和纹理。
一致性路线:同一轨迹应回到同一终点
Consistency Models 和 LCM 的核心不是严格复刻教师每一步,而是让同一生成轨迹上的不同噪声点映射到一致结果:
这里 和 位于同一条 PF-ODE 或教师轨迹上的不同时间, 是一致性模型。这个式子表达的是:无论你从这条轨迹上哪个噪声层级出发,模型都应该把你带回相近的干净样本。
一致性路线的吸引力在于,它天然支持一步或少步推理。LCM 把这个想法接到 latent diffusion 上,使 Stable Diffusion 这类模型可以用少量步数做快速预览或交互。
它的边界也要写清楚。终点一致不等于所有细节都保住。强 prompt、复杂空间关系、ControlNet、局部编辑、文字和高频纹理都可能因为“快速映射到终点”而变弱。读 LCM/Consistency 时,不要只看平均视觉指标,要看条件控制桶。
DMD:不逐步模仿,直接管最终分布
DMD 把问题从“学生是否复刻教师轨迹”转成“学生最终样本分布是否接近目标分布”。可以粗略写成:
这里 是学生生成分布, 是真实数据或教师诱导的目标分布, 表示分布差异。这个式子不要求学生的中间状态像教师,只要求最终落点的整体分布对。
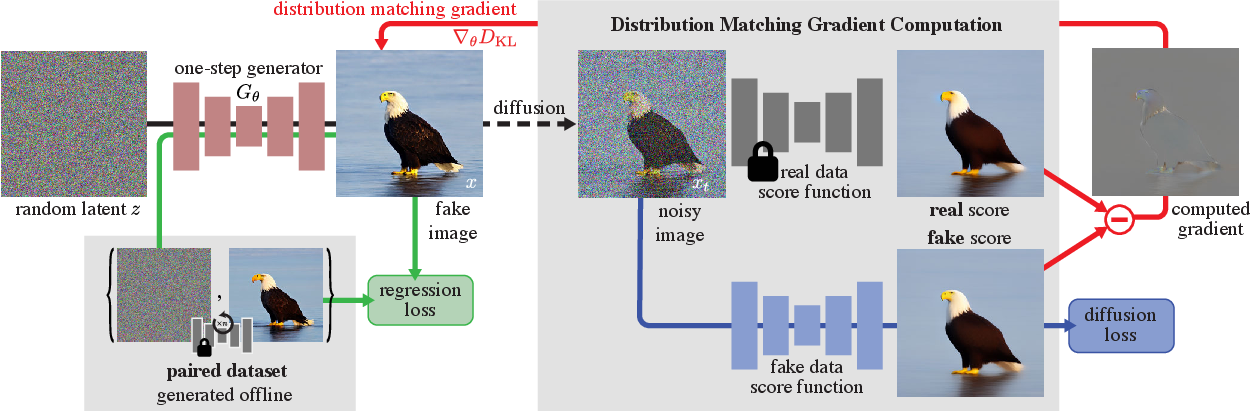
图源:One-step Diffusion with Distribution Matching Distillation,Figure 2。原图展示一步生成器 从噪声生成样本,一条支路用 teacher 生成的 noise-image pair 做回归,另一条支路用 real / fake score 差异形成 distribution matching gradient。读图重点:DMD 的关键不是少跑几步,而是用分布信号约束学生最终落到哪里。
DMD 的重要性在于,它给一步生成一个更合适的目标。一步学生很难逐点模仿教师轨迹,因为它几乎没有轨迹;用最终分布约束更自然。但分布约束也更危险:如果只往 real score 的高密度方向走,学生可能收缩到少数安全模式;如果 fake score 估计不准,梯度方向会偏。
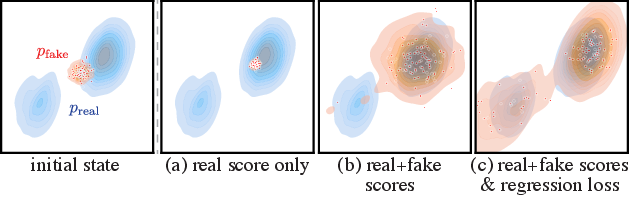
图源:DMD,Figure 3。原图用二维 toy 分布比较只用 real score、加入 distribution matching、再加入 regression anchor 的效果。读图重点:分布匹配不能只看 loss 数字,关键是模式覆盖和样本多样性是否保住。
所以 DMD 类方法的验收要同时看分布质量和模式覆盖。只看单张样例锐不锐,很容易漏掉学生是否坍缩到少数风格。
DMD2:训练端加复杂度,推理端少走路
DMD2 继续走分布匹配路线,但它把 DMD 的几个不稳定点拆开处理:fake score function 要更快跟上当前 generator 分布,GAN loss 负责补视觉锐度,训练时还要模拟推理时学生自己产生的中间状态,减少 train-inference mismatch。

图源:Improved Distribution Matching Distillation for Fast Image Synthesis,Figure 3。原图展示 generator、fake score function 和 GAN discriminator 交替训练。读图重点:DMD2 的少步速度不是白来的;部署端少跑几十步,训练端增加了动态 critic、GAN 分支和推理链路模拟。
可以用一个总目标直觉理解:
负责分布匹配, 负责视觉真实感和锐度, 是可选的回归或稳定项, 系数控制各项在总目标里的权重。这个式子不是 DMD2 的完整实现,而是帮读者抓住一件事:一步/少步生成通常需要多个训练信号互相制衡。
DMD2 的经验提醒是:少步模型的训练曲线不能按单一 loss 读。局部回归变好,不代表最终分布变好;GAN 分支变强,不代表 prompt fidelity 变强;fake critic 收敛,不代表真实 1/2/4 步推理没有错配。必须用真实步数回放。
Phased DMD:少步仍然需要阶段分工
一步生成很诱人,但视频和复杂图像里,少步不等于所有事情都应该一跳完成。高噪声阶段更负责大结构、镜头和运动,低噪声阶段更负责纹理、边缘和细节。Phased DMD 的直觉就是:固定少步目标下,把 SNR 路径切成 phase,让不同子区间分别学习。
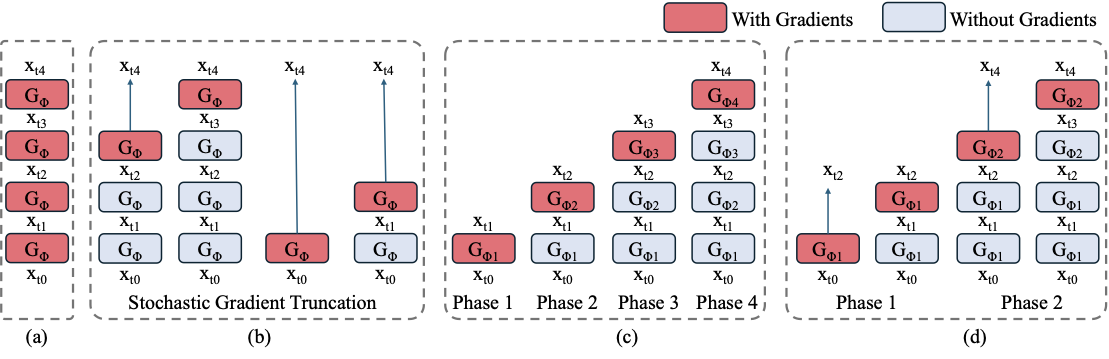
图源:Phased DMD,Figure 1。原图对比 vanilla few-step DMD、DMD2/SGTS、4-phase Phased DMD 和结合 SGTS 的 2-phase 版本;红色表示记录梯度的 generator step,蓝色表示只前向的 step。读图重点:少步训练仍要保留阶段职责,不能把每次训练都退化成“从噪声直接到最终画面”。
如果把少步蒸馏总压成一跳,模型为了稳定可能倾向保守:视频动作变慢、镜头运动变弱、不同 seed 更像。Phased DMD 把任务拆开:低 SNR 子区间负责大结构和运动,高 SNR 子区间负责细节。它和 DMD2 的关系不是谁替代谁,而是进一步处理“大模型、视频、少步”下的阶段退化问题。
整流路线:把路改得更适合少步走
Rectified Flow / Rectified Diffusion 不一定从 teacher-student 蒸馏出发,而是重新设计从噪声到数据的路径。最简形式是学习速度场:
这里 是当前样本状态, 是连续时间, 是模型预测的速度。采样时沿速度场积分,如果路径足够平滑、弯曲少、时间采样合理,少数 Euler / Heun 步也可能得到好结果。
Rectified Flow 的经典目标强调让噪声分布到数据分布的运输路径更直、更容易粗步积分。Rectified Diffusion 进一步提醒:真正需要的不只是几何意义上的“直”,还包括路径是否适合扩散数据几何、条件控制和少步采样。路径太直但条件弱,仍然会失败。
这条路线和 DMD 的差别是:DMD 更像在最终分布上纠偏,Rectified / Flow Matching 更像重画生成路径。二者都追求少步,但训练信号和失败模式不同。
评测要按步数桶和条件桶拆开
少步蒸馏最容易被漂亮样例误导。一个可用报告至少要拆四类桶。
| 桶 | 要看什么 | 为什么 |
|---|---|---|
| 步数桶 | 1、2、4、8 步分别报告 | 不同步数的失败模式不同 |
| 条件桶 | 文本、ControlNet、参考图、局部编辑、强 CFG | 少步会放大条件误差 |
| 视觉桶 | 文字、边缘、脸手、材质、细小物体 | 高频细节最先被牺牲 |
| 分布桶 | 多 seed、多 prompt、长尾风格、模式覆盖 | 防止学生坍缩到少数安全样式 |
视频模型还要加 motion bucket:镜头运动、主体速度、长时一致性、动作幅度、帧间闪烁。少步模型可能平均画质不错,但把运动压慢了,这对视频和世界模型 rollout 都是实质退化。
端到端延迟也要真实测。NFE 下降不一定等于服务成本线性下降,因为还有 VAE、文本编码器、ControlNet、后处理、批处理、显存峰值和并发调度。
什么时候选哪条
如果只是想让现有模型快一点,先试 DDIM、Euler、Heun、DPM-Solver++ 和更合适的 timestep schedule。能不重训就不要先上蒸馏。
如果目标是 4-8 步交互式预览,优先看 Progressive Distillation、LCM/Consistency 或少步 Rectified 路线。它们通常比一步分布匹配更稳,生态兼容也更容易。
如果目标是 1-2 步高质量生成,再看 DMD、DMD2、Phased DMD 这类分布匹配路线。它们更激进,训练也更复杂,必须配更硬的长尾评测。
如果目标是视频、世界模型或机器人 rollout,不能只看画面质量。少步学生要证明运动强度、动作条件、长时状态和 risk/event 相关变量没有被压掉。
读完以后怎么判断
一步生成、蒸馏与整流可以按四句话记:
- 少步生成不是删采样步,而是把多次小纠错压成少数大跳。
- 轨迹蒸馏学教师复合,一致性学终点一致,DMD 学最终分布,Rectified 路线改生成路径。
- DMD2 和 Phased DMD 的复杂性说明:推理端少走路,训练端就要补更强的分布信号和阶段约束。
- 真正验收要按步数、条件、视觉细节、分布覆盖、视频运动和端到端延迟拆开。
继续读相邻内容时,可以接 采样与推理加速、一致性模型与 Rectified Flow、视频与多模态扩散 和 DMD2 论文精读。
外部材料
- Progressive Distillation:理解把教师两步压成学生一步的逐级路线。
- Consistency Models:理解为什么同一轨迹不同噪声点可以映射到一致终点。
- Latent Consistency Models:看一致性目标如何接到 latent diffusion 和少步文生图。
- DMD:理解一步生成为什么需要 distribution matching。
- DMD2:看 fake score、GAN loss 和训练-推理错配如何影响少步质量。
- Rectified Flow 与 Rectified Diffusion:理解“重画生成路径”与“蒸馏学生模型”的区别。
- Lil’Log: What are Diffusion Models?:适合复习 DDPM、score、guidance 和采样直觉。
- Title: 扩散模型:一步生成、蒸馏与整流:把多步纠错压成少数大跳
- Author: Charles
- Created at : 2025-05-04 09:00:00
- Updated at : 2025-05-04 09:00:00
- Link: https://charles2530.github.io/2025/05/04/ai-files-diffusion-distillation/
- License: This work is licensed under CC BY-NC-SA 4.0.