
扩散模型:噪声日程与参数化
上一页讲了扩散训练如何构造带噪样本:
这页先回答“噪声日程与参数化”在「扩散模型」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先知道张量、损失函数和高斯噪声的基本读法;不熟时回基础知识再继续。 必要时先回 扩散模型入口、基础知识 或 术语表。
主线关系:把训练目标、噪声日程、采样器、条件控制和蒸馏看成同一条链:带噪状态如何一步步被推回数据分布。
这条式子把带噪样本拆成两部分: 是保留下来的干净信号, 是混入的噪声。
这页继续问两个更细的问题:
- 噪声日程:不同时间步到底加多少噪声?
- 参数化:模型到底预测噪声、干净图、score,还是 velocity?
这两个问题看似是训练细节,其实会直接影响采样质量、少步生成、guidance 稳定性和视频一致性。
先看图:不同时间步的学习压力不同
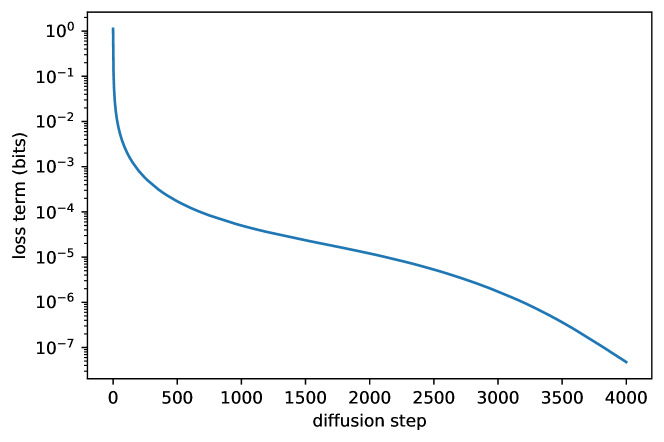
图源:Improved Denoising Diffusion Probabilistic Models,Figure 2。
原论文图意:该图分析 CIFAR-10 训练中 variational lower bound 各 timestep 项的贡献,显示不同 diffusion step 的损失权重和学习压力差异很大。
本教程读法:不要把所有时间步想成一样难。低噪声区间更像补边缘和纹理,中噪声区间更像恢复结构,高噪声区间更像从几乎看不见的信号里猜语义。噪声日程和 loss weighting 会决定模型把精力花在哪里。
噪声日程决定什么
离散扩散里,单步前向过程是:
这行式子在说:第 步把上一时刻图像 缩小一点,再加入强度为 的高斯噪声。
把 拆开读会更清楚:
| 位置 | 在这条公式里 | 含义 |
|---|---|---|
| 第 1 个位置 | 当前带噪样本 | 这个分布要生成或评估的变量 |
| 第 2 个位置 | 均值 | 保留下来的上一时刻信号 |
| 第 3 个位置 | 协方差 | 噪声强度; 表示各维独立同方差 |
符号含义:
| 符号 | 含义 |
|---|---|
| 第 步新增噪声强度 | |
| 第 步保留信号比例 | |
| 单位矩阵,表示独立同方差噪声 | |
| 固定加噪过程 |
一整串 就叫噪声日程。它决定图像从清晰到纯噪声的速度。
通常还会定义:
这行式子在说: 是单步保留信号比例, 是从第 1 步到第 步累计保留的信号比例。
符号含义:
| 符号 | 含义 |
|---|---|
| 单步信号保留比例 | |
| 累计信号保留比例 | |
| 连乘,表示把多个时间步的保留比例乘起来 |
SNR:比 更贴近学习难度
闭式加噪是:
这行式子在说: 控制原图信号还剩多少, 控制噪声占多少。
如果上下文写着 ,这里的 是噪声均值, 是单位协方差;也就是每个维度独立采样标准高斯噪声。和 相比,它省略了“在哪个变量上取值”的第 1 个位置,因为这是在说“ 从这个分布里采样”。
于是可以定义信噪比:
这行式子在说:SNR 衡量当前时间步里“原图信号”相对“噪声”的强弱。
符号含义:
| 符号 | 含义 |
|---|---|
| 第 步的信噪比 | |
| 信号强度部分 | |
| 噪声强度部分 |
直觉上:
- SNR 高:图像还很清楚,模型主要学局部细节修复。
- SNR 中等:图像结构还在,模型学语义和形状。
- SNR 低:几乎都是噪声,模型要靠分布先验猜大结构。
所以线性 不等于线性学习难度。真正影响训练体验的,是整个 SNR 曲线怎么变化。
常见噪声日程
3.1 线性
最直接的做法是让 从小到大线性增加。
优点:简单、好复现、适合入门理解。
缺点:线性增加噪声强度,不代表信息难度线性变化;某些 SNR 区间可能过密,另一些区间可能过稀。
3.2 Cosine 日程
Improved DDPM 推动了 cosine schedule 的常用化。它更直接地控制 的衰减,让信号保留过程更平滑。
直觉上,cosine 日程不会过早把图像彻底打成噪声,因此中间噪声区间更容易得到稳定训练信号。它常被当作比线性日程更稳的默认选择。
3.3 连续噪声尺度
EDM 等连续时间框架更常直接用噪声标准差 描述状态:
这行式子在说:当前样本是干净图加上标准差为 的噪声。这里不再强调离散编号 ,而是直接用噪声大小 表示“现在有多吵”。
符号含义:
| 符号 | 含义 |
|---|---|
| 当前带噪样本 | |
| 干净样本 | |
| 噪声标准差,越大表示噪声越强 | |
| 标准高斯噪声 |
这种写法更容易和 ODE / SDE 采样器连接,因为采样器可以直接沿着连续噪声尺度安排步长。
参数化:模型到底输出什么
同一个带噪状态 ,模型可以学习不同目标。它们表达的信息可以互相转换,但训练难度和采样稳定性不完全一样。
4.1 预测噪声
这行式子在说:模型输入带噪图 和时间步 ,输出它认为被加入的噪声。
优点:训练目标最直接,因为训练时真实噪声 是我们自己采样出来的。
代价:在不同 SNR 区间,噪声预测的尺度和误差影响不完全均衡,少步采样或强 guidance 时需要和采样器一起调。
4.2 预测干净图
这行式子在说:模型直接从带噪图里猜原始干净图。
优点:直觉清楚,采样器可以直接拿 计算更新。
代价:高噪声时 几乎看不出原图,直接预测 更容易承受尺度和不确定性压力。
4.3 预测 score
这行式子在说:模型估计当前噪声分布 的对数密度梯度,也就是“往哪里走,概率密度会上升最快”。
符号含义:
| 符号 | 含义 |
|---|---|
| 模型估计的 score | |
| 第 个噪声水平下的数据分布 | |
| 当前样本在该分布下的对数概率密度 | |
| 对样本 求梯度 |
score 不是“分数”,而是一个方向向量。它把扩散和 SDE / ODE 理论连起来。
在常见噪声预测参数化下,可以粗略理解为:
这行式子在说:预测噪声和预测 score 不是两件完全无关的事;噪声方向的反方向,经过时间相关缩放后,就是朝数据高概率区域移动的方向。
4.4 预测 velocity
常见的混合路径写成:
这行式子在说: 是干净图和噪声按两个权重混合出来的状态。
velocity 通常定义为:
这行式子在说: 是沿混合路径移动的方向,既包含噪声信息,也包含数据信号信息。
如果模型预测 ,常可以换回:
这两行式子在说:velocity 不是新的神秘信息,而是一个坐标系。第一行把带噪样本 和预测速度 换算成干净图估计 ;第二行把它们换算成噪声估计 。预测 后,采样器仍然能得到需要的 或 。
4.5 预测值怎样真正作用到去噪过程
不管模型预测的是 、、score,还是 ,采样时都要落到同一个问题:给定当前状态 ,怎样得到更低噪声的下一个状态 。
最常见的执行链条是:
1 | model output |
例如确定性 DDIM 可以粗略写成:
这里的关键不是“把噪声直接从图上擦掉一次”,而是:模型先告诉采样器当前样本里哪些部分像数据、哪些部分像噪声;采样器再按照下一个噪声水平 重新组合这两部分。 如果离 很近,就是小步去噪;如果跳得很远,就是少步采样,对模型预测和 solver 都更苛刻。
如果模型直接预测 ,采样器已经拿到了“数据端估计”;如果模型预测 ,就先用反解公式得到 ;如果模型预测 ,就先用上面的坐标变换得到 和 。所以 -prediction 发挥作用的方式通常不是多了一个神秘步骤,而是给采样器一个更稳定的坐标,再由采样器把它兑现成每一步移动。
为什么“等价”又“不等价”
从信息表达看,只要知道 、时间步和其中一种预测目标,很多情况下可以解析换算到其他目标。
但训练不是只看信息能否换算,还要看:
- 损失在不同时间步的尺度是否均衡;
- 高噪声和低噪声区间谁主导梯度;
- guidance 放大后是否容易过冲;
- 少步采样时误差是否累积;
- 模型输出坐标是否适合采样器。
所以 -prediction、-prediction、score prediction 和 -prediction 像是用不同坐标系描述同一个去噪问题。坐标系不同,优化几何也不同。
日程、参数化、采样器要一起看
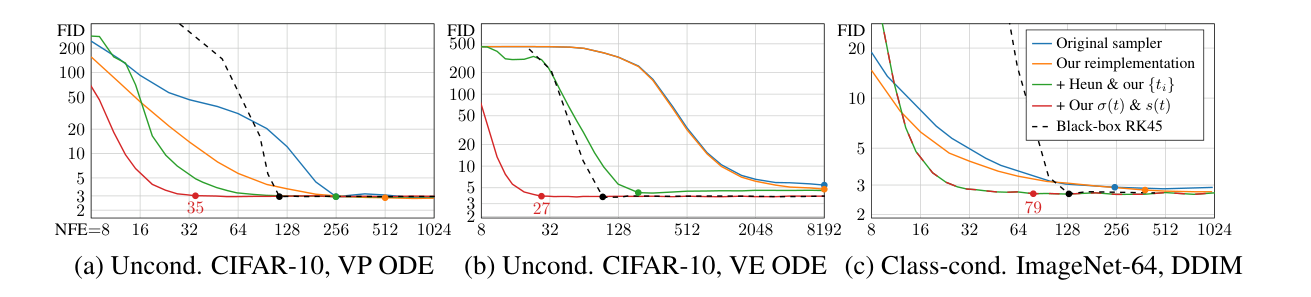
图源:Elucidating the Design Space of Diffusion-Based Generative Models,Figure 2。
原论文图意:在多个预训练模型上比较确定性采样设计,横轴是 NFE,纵轴是 FID;Heun、噪声日程 、scaling 等改动都会影响少步质量。
本教程读法:这张图说明,采样质量不是只由模型权重决定。噪声日程、参数化、时间离散方式和 solver 共同决定少步采样表现。NFE 是模型前向调用次数,越少通常越快,但数值误差更难控制。
一句话:噪声日程决定训练样本落在哪些噪声区间,参数化决定模型用什么坐标理解这些样本,采样器决定推理时如何兑现这些学习成果。
和下一页的关系
这一页解释了噪声水平和预测坐标。下一页 Score Matching 到 SDE 会把“预测噪声”进一步解释成“学习概率分布的梯度方向”,并说明为什么扩散采样可以被看成 SDE / ODE 的数值求解。
在视频扩散和世界模型里,噪声日程还会影响运动是否连续、身份是否漂移、动作条件是否敏感。基础图像扩散先把 SNR 和参数化理解清楚,后面看高低噪声 expert、Flow Matching 或 Phased DMD 会轻松很多。
本页结论
噪声日程控制“训练题目有多难、难题分布在哪里”;参数化控制“模型用哪个坐标系回答题目”。它们不是孤立技巧,而是扩散训练和采样之间最重要的连接层。
- 回到本专题入口:扩散模型,确认这页在整条路线中的位置。
- 按导航顺序继续:Score Matching 到 SDE。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 扩散模型:噪声日程与参数化
- Author: Charles
- Created at : 2025-05-12 09:00:00
- Updated at : 2025-05-12 09:00:00
- Link: https://charles2530.github.io/2025/05/12/ai-files-diffusion-noise-schedules-and-parameterization/
- License: This work is licensed under CC BY-NC-SA 4.0.