
扩散模型:扩散训练配方与排障
扩散模型的论文叙事常聚焦于参数化、采样器和新架构,但真正把模型训稳,往往依赖一整套细碎却关键的工程配方:数据如何清洗、分辨率怎么安排、噪声日程怎么采、条件 dropout 何时打开、EMA 多大、classifier-free guidance 相关条件该如何混入、loss weighting 用哪一版、验证集看什么,以及一旦生成崩坏该如何定位。对实际训练者而言,失效分析的重要性并不低于新方法本身。
这页先回答“扩散训练配方与排障”在「扩散模型」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先知道张量、损失函数和高斯噪声的基本读法;不熟时回基础知识再继续。 必要时先回 扩散模型入口、基础知识 或 术语表。
主线关系:把训练目标、噪声日程、采样器、条件控制和蒸馏看成同一条链:带噪状态如何一步步被推回数据分布。
扩散训练的公式看起来短,但配方很长。数据、噪声时间采样、条件 dropout、EMA、分辨率 curriculum、batch 和验证集都会改变最终观感;训练崩坏时不要只怀疑网络结构。
同样是面粉、鸡蛋和糖,温度、搅拌顺序和烘烤时间不同,蛋糕会完全不同。扩散训练也是这样:很多关键差异藏在论文表格和附录里,而不是主公式里。
扩散页在“世界模型高效训练”主线里负责回答:什么时候值得用更贵的生成目标换更强的多模态建模,什么时候必须通过 latent、patch、少步蒸馏或 action chunk 把成本压回来。它能降低真实数据成本和候选轨迹搜索成本,但如果采样步数、token 数和候选数没有账本,训练成本会被转移到部署和 rollout 上。
扩散训练不是“把数据喂进去就行”
训练目标表面很简单:
但这个式子里每一项都藏着配方选择: 来自什么样的数据分布, 的采样分布是什么, 是否重加权,条件 如何注入、何时 dropout, 用什么架构和参数化,以及优化器与 EMA 如何设置。
拆开读:
| 位置 | 含义 |
|---|---|
| 对干净样本、随机噪声和时间步做平均 | |
| 时间步权重,决定不同噪声区间的 loss 贡献 | |
| 真实加入的噪声 | |
| 模型在带噪样本、时间步和条件下预测的噪声 | |
| 平方误差,预测噪声和真实噪声越接近越小 |
这使得扩散训练像烘焙一样:原料大体相同,但温度、顺序和时间稍有变化,成品就可能完全不同。
数据质量先于模型技巧
扩散模型对数据脏噪特别敏感。图像里常见问题包括低分辨率、强压缩、重复样本、模板化素材、标题-图像不一致、水印、拼图、广告图和内容分布偏斜。若是文档、UI、工业图像或机器人视觉数据,还会多出 OCR 标注错误、版面区域丢失、相机标定变化、任务条件与动作轨迹对不齐等问题。
很多训练崩坏看似是架构问题,实则是数据质量首先失守。
分辨率 curriculum
高分辨率训练昂贵且不稳,很多系统采用分阶段策略:先在较低分辨率上学语义与大构图,再提升到更高分辨率补纹理与细节,必要时用级联或 latent decoder 细化。
这种 curriculum 让模型先学会“画什么”,再学会“画得细”。如果一开始就用极高分辨率和小 batch,往往算力花得很快,但收敛不一定好。
噪声日程与时间采样
即使固定了 beta schedule,不同时间步采样分布也会改变训练重点。直觉上,靠近高噪区的样本更强调全局语义与粗结构,低噪区更强调细节修复。若训练中过度采某一段时间,模型能力会失衡。
很多系统会使用 importance sampling 或 log-SNR 相关重权,使不同噪声区的梯度贡献更均衡。若记信噪比为
则加权常围绕 的函数设计。
这里分子 表示信号能量,分母 表示噪声能量;SNR 越大,样本越接近干净图,SNR 越小,样本越接近纯噪声。
条件 dropout 与 CFG 兼容性
文本到图像里,classifier-free guidance 常需在训练时随机丢弃条件,让模型同时学条件和无条件分支。若 dropout 概率记为 ,则训练数据中一部分样本使用空条件 :
太低,推理时 CFG 不稳定;太高,则条件对齐能力下降。这个比例是最典型的“论文里一句带过、训练里很影响结果”的配方项。
这条分段式的上半行表示“以 的概率把条件替换为空条件”,下半行表示“剩下的概率保留原条件 ”。所以 才是模型实际看到的训练条件。
EMA 为何常常决定最终观感
扩散训练常用 exponential moving average 保存一份平滑权重:
EMA 模型通常比最后一步权重更稳,特别在后期损失抖动时。很多视觉生成系统最终部署的并不是“当前训练权重”,而是 EMA 权重。若 EMA 衰减设得不合适,模型可能看起来一直在进步,但采样质量忽上忽下。
等号右边有两部分: 保留旧的平滑权重, 混入当前训练权重。 越接近 1,EMA 更新越慢、越平滑。
优化器与 batch 设计
AdamW + 混合精度是常见组合。关键不只在于学习率,还在于全局 batch 是否足够大、梯度累积是否引入统计偏差、gradient clipping 是否必要,以及是否存在异常 batch 导致 loss spike。
扩散训练尤其容易在数据混杂、分辨率变化大、caption 质量参差时出现不稳定 batch。
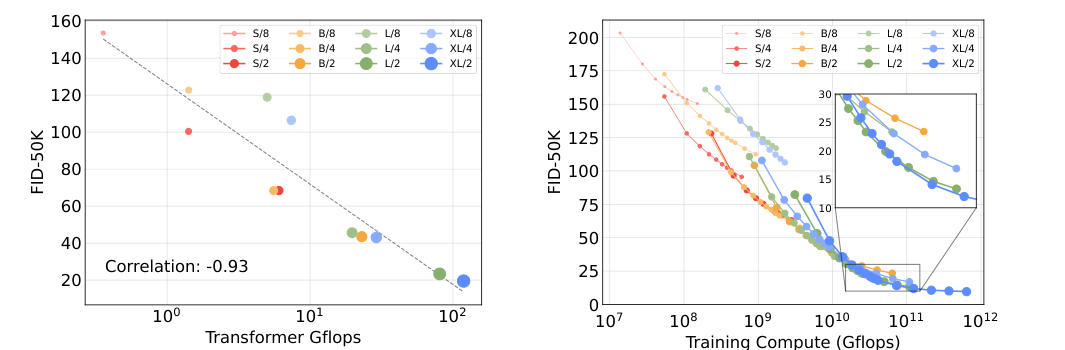
图源:Scalable Diffusion Models with Transformers,Figures 8-9。原论文图意:DiT 用 forward pass GFLOPs 衡量模型计算量,展示更高 GFLOPs 与更低 FID 的强相关,以及更大训练计算预算下模型质量的变化。
这张图支撑一个工程判断:在 latent diffusion / DiT 路线里,提高 token 数、深度或宽度通常会改善生成质量,但也会直接提高每次去噪 forward 的成本。对世界模型和机器人规划来说,这不是单纯训练指标问题,因为推理阶段还要乘以采样步数、候选 action 数和重规划频率。
7.1 算一遍:视频世界模型扩散训练的成本账
假设一个机器人视频世界模型输入 4 路相机、16 帧、每路 256 x 256,VAE 下采样 8x 后 latent 网格是 32 x 32。如果 DiT 直接按 latent patch 1 x 1 建 token:
四个乘数分别是相机路数、帧数、latent 高度和 latent 宽度。也就是说,每个决策样本不是一张图,而是把所有相机和时间帧的 latent 网格都摊成 token。
如果 patch 改成 2 x 2,每帧每路变成 16 x 16,总 token 变为:
这里后两个 16 来自 2 x 2 patch 后的 latent 网格高宽;相比 32 x 32,空间 token 数从每帧每路 1024 降到 256。
注意力主干的显存和计算会随 token 数显著增长。即使 patch 2 x 2 已经降了 4x token,只要采样还要 50 步,每个候选未来都要 50 次 forward。若在线规划一次比较 8 个候选 action sequence,就是:
50 是每个候选未来的去噪步数,8 是候选动作序列数量,乘积就是做一次决策需要调用世界模型的次数。
若单次 forward 在目标 GPU 上是 90ms,一次决策要 36s,根本进不了闭环。蒸馏到 4 步后变成 32 次 forward,理想延迟约 2.88s;再配合候选预筛到 2 条,是 720ms,才接近低频 replan。一步模型是 8 x 90ms = 720ms,看起来更快,但把“多步修错”的能力压进一次映射,长尾风险通常要用更硬的评测补回来。
所以设计链条不是“扩散好不好”,而是:
1 | 症状:open-loop 视频像,但 planner 太慢或动作不敏感 |
验证集不要只看 FID
FID 重要,但不够。实际训练中还应观察 prompt fidelity、构图稳定性、细节完整性、人脸/手部/文字等敏感区域质量、长尾类别表现、多样性与模式坍缩迹象。
若是文档或控制类扩散,更要看结构与任务一致性,而非只看视觉美感。
8.1 训练曲线怎么读:v-prediction 与 distribution matching
如果训练日志里同时有 v-prediction loss 和 distribution matching loss,不要把它们当成同一种东西看。前者通常是监督回归误差,后者通常是分布级、critic / score 参与的对齐信号;它们的下降速度、噪声形态和可解释性都不同。
v-prediction loss 可以先按普通去噪回归看:
这条曲线下降,通常说明模型越来越会在训练分布的噪声点上预测局部生成方向。它应该相对平滑,尤其在 batch 足够大、time sampling 稳定时。更有用的看法不是只看总 loss,而是拆成高噪声、中噪声、低噪声几个桶:高噪声桶下降慢,常对应全局结构、语义和运动还不稳;低噪声桶下降慢,常对应纹理、边缘、文字和局部细节修不好。
但 v-prediction loss 低不等于生成一定好。它只说明“在训练采到的 上,局部速度回归更准”。如果推理时使用少步 solver、强 CFG,或者 student 自己滚出的中间状态偏离训练分布,验证样例仍可能崩。这时要看真实采样链路,而不是只庆祝回归 loss 下降。
distribution matching loss 则更像在问:“当前 generator 产出的整体分布,是否越来越像 teacher / real distribution?”在 DMD / DMD2 里,它依赖 real score、fake score 或 discriminator 一类动态信号,所以曲线通常不会像 MSE 那样单调好看。
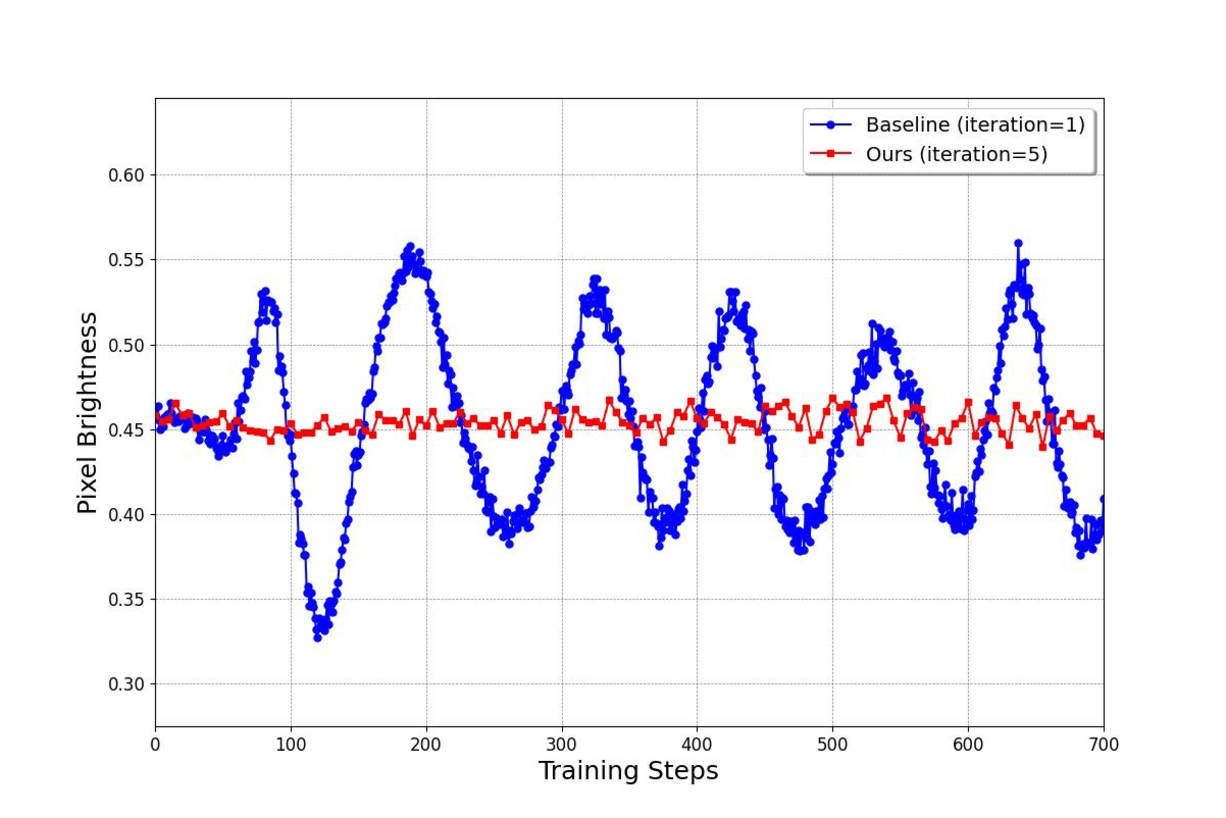
图源:Improved Distribution Matching Distillation for Fast Image Synthesis,Appendix Figure 7。原论文图意:去掉 regression loss 后,如果 fake critic 只做 1 次更新,ImageNet 生成样本的平均亮度会明显振荡;增加 fake critic 更新次数后更稳定。
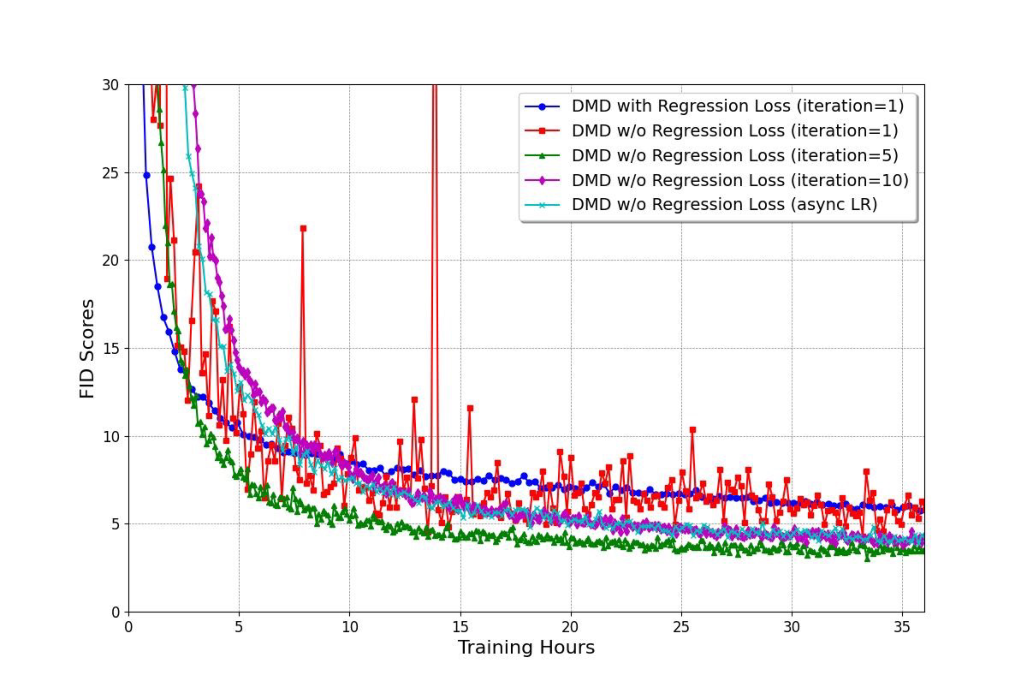
图源:Improved Distribution Matching Distillation for Fast Image Synthesis,Appendix Figure 8。原论文图意:比较不同 fake critic update ratio 和原始 DMD 设置下的收敛表现。
本教程读法:这两张图正好说明 distribution matching 曲线背后有一个动态系统。generator 在动,fake critic 也在追;如果 critic 跟不上,分布梯度会带偏 generator,外在表现可能不是 loss 单调变坏,而是亮度、颜色、清晰度或 FID 周期性晃动。
| 曲线现象 | 常见含义 | 下一步检查 |
|---|---|---|
| 稳定下降,样例也变好 | 局部速度场和采样器配合正常 | 继续看分桶 loss、验证 prompt 和少步采样 |
| 下降,但样例构图或 prompt 变差 | 训练点回归变准,但推理轨迹或条件使用不稳 | 回放真实 sampler,检查 CFG、time grid、条件 dropout |
| distribution matching loss 大幅震荡 | fake critic / score estimator 可能跟不上 generator | 看 critic update ratio、学习率、EMA、生成统计量 |
| distribution matching loss 下降,但多样性变差 | 可能出现 mode dropping 或过度追求高密度模式 | 看不同 seed、LPIPS / DINO 多样性、长尾 prompt |
| 两个 loss 都下降,但验证不进步 | loss 对任务目标不敏感,或 train-inference mismatch | 固定 seed 做 K 步推理回放,按失败类型分桶 |
| 两个 loss 同时突然 spike | 可能是坏 batch、学习率过高、数值溢出或 timestep 分布异常 | 查数据批次、梯度范数、混合精度、噪声时间采样 |
更实用的日志面板应至少同时放这些曲线:v loss by timestep/SNR bucket、distribution matching loss、fake critic denoising loss、GAN/discriminator loss、sample FID or CLIP score、固定 prompt 样例、多 seed 多样性,以及真实步数下的延迟和失败桶。单条 loss 曲线不够,因为扩散训练的成功发生在“局部方向准、分布不塌、采样链路稳”三件事同时成立时。
常见失效模式一:生成很糊
可能原因包括低噪区训练不足、分辨率提升过快、decoder 或 latent 压缩过强、学习率太高导致细节不稳定,以及数据本身低质占比过高。
一个实用排查方法是固定 prompt,分别看不同采样步数和不同噪声区起点生成结果,判断问题更像“全程没学会”还是“后段细化不足”。
常见失效模式二:构图混乱或主体丢失
这常与高噪区建模和文本条件对齐相关。若模型对全局语义理解不稳,即使细节不错,也会出现“画得精致但画错了主角”的情况。原因可能是 caption 过短或噪声大、条件注入能力弱、噪声日程采样偏低噪,或 guidance 设置与训练不匹配。
常见失效模式三:文字、手部、局部结构错误
这是视觉生成中的顽固难题。原因往往不是“模型总体不会画”,而是数据中此类结构稀少、像素级细节要求高、局部一致性难以靠全局语义自动保证。
针对这些问题,通常需要更专门的数据、局部控制条件或后处理模块,而不只是延长训练。
常见失效模式四:prompt adherence 差
用户写“红色雨衣”,生成却经常变成黄色;写“两只猫”,结果总出一只。这说明条件信号没被充分绑定到生成过程。排查时要看文本编码器是否足够强、条件 dropout 是否过高、训练 caption 是否过于模板化,以及 CFG 推理范围是否超出训练支撑。
常见失效模式五:模式坍缩或风格单一
虽然扩散比 GAN 更不易塌缩,但若数据分布狭窄、训练过度聚焦主模态,生成仍可能显得“都一个味”。这常发生在垂直领域数据集,如特定商品图、固定 UI 或单一艺术风格集上。
例子:文档版面扩散
如果训练的是文档页面生成或版面增强模型,最常见的失效不是“图片不好看”,而是字段位置错乱、表格线条断裂、小字体不可读和 OCR 语义不一致。
此时训练配方应优先保证结构保真,而不是视觉风格多样性。
例子:机器人动作扩散
如果扩散用于动作轨迹生成,失效模式会变成轨迹平滑但不可执行、长时动作后段漂移、条件目标被部分满足但最终失败,以及多样性很好但稳定性差。
因此验证集要看成功率、碰撞率和恢复能力,而不是只看轨迹相似度。
15.1 真实排查:轨迹更平滑,成功率反而下降
一个常见场景是:action diffusion 的验证 MSE 从 0.084 降到 0.071,动作 jerk 也下降,但真实机械臂成功率从 78% 掉到 61%。输入日志看起来像这样:
1 | bucket=reflective_cup mse=0.068 jerk=0.31 success=52% collision=18% |
判断过程应从平均误差转向动作后果:反光杯和遮挡抓取都属于多模态动作分布,同一个目标可能有左夹、右夹、先推再夹等几种策略。MSE 会奖励“平均动作”,而平均动作可能正好碰到杯沿或错过抓取点。扩散模型看起来输出更平滑,是因为去噪过程把多峰轨迹压成了中间轨迹;这在离线曲线上好看,在闭环里却会失败。
修复不应只是继续训练。更有效的链条是:按物体材质、遮挡、接触阶段和失败后恢复分桶;增加 action-conditioned counterfactual 检查,确认换动作时预测未来真的变化;在推理时只执行 action chunk 前半段并 receding-horizon 重规划;对高风险桶加入碰撞、接触成功和恢复窗口指标。反例也要写清:如果任务几乎是单峰、低自由度、低频执行,普通行为克隆或小型 transformer policy 可能比 action diffusion 更省。
设计建议
先把数据质量和条件对齐搞清,再谈 fancy sampler。训练监控至少同时看 loss、样例、prompt adherence 和长尾错误;EMA、条件 dropout、时间采样分布必须显式记录;失效分析应按“全局语义 / 局部细节 / 条件绑定 / 结构一致性”分桶。不同任务的“好生成”定义不同,验证指标要贴近任务,而不是照搬图像生成标准。
本页结论
扩散模型的训练成功,很少来自某个单一魔法技巧,而更常来自一套彼此匹配的配方:干净数据、合适噪声采样、稳定优化、正确条件注入、持续样例检查和有条理的失效分析。把这些工作做扎实,往往比再追一篇新方法更能决定最终质量。
工程收束
扩散训练配方不是技巧清单,而是目标、数据制度、噪声采样、EMA、条件注入、验证集和部署约束的共同设计。更稳的验收应同时看基础生成、控制、系统和任务四层;落地时先做目标和数据判断,再定推理预算,再看控制接口,最后才决定是否引入更激进的新方法。
- 回到本专题入口:扩散模型,确认这页在整条路线中的位置。
- 按导航顺序继续:扩散方法对照表。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 扩散模型:扩散训练配方与排障
- Author: Charles
- Created at : 2025-05-14 09:00:00
- Updated at : 2025-05-14 09:00:00
- Link: https://charles2530.github.io/2025/05/14/ai-files-diffusion-practical-training-recipes-and-failure-analysis/
- License: This work is licensed under CC BY-NC-SA 4.0.