
扩散模型:噪声日程与参数化
扩散模型的很多讨论表面上在谈“模型结构”,但真正决定训练稳定性和采样行为的,往往是两个更底层的设计:噪声日程 和 参数化方式。
如果这两项没理解清楚,很多现象都会显得像经验调参;一旦把它们放回统一公式里,很多设计选择就会变得有逻辑。
下面这张 Improved DDPM 原论文图把训练损失拆到不同 diffusion step 上看:不同时间段贡献的学习压力并不均匀。低噪声区间更像“补纹理和边缘”,中噪声区间更像“学物体结构”,高噪声区间更像“从几乎看不见的信号里恢复语义”。
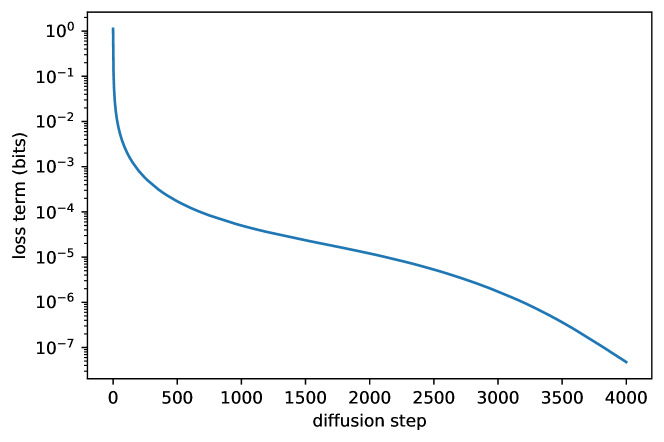
图源:Improved Denoising Diffusion Probabilistic Models,Figure 2。原论文图意:分析 CIFAR-10 训练中 variational lower bound 各 timestep 项的贡献,显示不同 diffusion step 的损失权重和学习压力差异很大。
图里的重点是不同 timestep 对训练目标的贡献并不平均。某些区间如果权重过大,模型会把容量集中到那段噪声水平;某些区间如果监督太弱,少步采样时就容易出现结构不稳、细节糊或语义弱。实际读噪声日程时,不要只看 是不是线性,真正影响训练的是 SNR 分布、loss weighting 和采样时选哪些 timestep。
噪声日程像调一块可控雾化玻璃:低噪声时还能看清边缘,高噪声时只剩大概轮廓。训练材料如果总停在轻雾区,模型会擅长修细节;如果总停在浓雾区,模型会更会猜语义但容易丢纹理。
1. 噪声日程到底在决定什么
在离散扩散里,正向过程通常写成:
其中 的序列就是噪声日程。它决定单步噪声强度、信号衰减速度和梯度可用性:每个 timestep 往样本里加入多少随机扰动,前期是否过快丢掉结构,后期是否还留有可学习的细节,不同噪声区间是否还能给模型提供稳定监督,都由它间接塑形。
若展开到任意时刻 ,有:
因此从训练视角看,噪声日程其实是在塑造:
也就是说,它本质上在决定不同时间点的信噪比分布。
2. 为什么噪声日程会影响训练质量
直觉上,扩散训练就是在不同噪声水平下让模型学会去噪。
如果日程设计不合理,就会出现低噪声阶段样本过多、模型过度关注细节但全局结构差,或高噪声阶段过强、训练信号过于模糊、模型难学语义。
一个直观例子:临摹一张照片
如果老师给你的训练材料里,90% 都是“只被轻微擦花”的图,你会很擅长修局部划痕,却不擅长从几乎全噪声中恢复对象结构。
反过来,如果 90% 都是“几乎纯噪声”的图,你可能学会猜大概轮廓,却补不出细节。
噪声日程就是在平衡这两种学习压力。
3. 常见噪声日程
3.1 线性日程
最直接的做法是让 线性变化。
优点是实现简单、教学和复现方便,DDPM 等经典实现也常从线性日程出发,便于对照基线。缺点是 SNR 分布不总是理想:线性 不等于线性信息难度,某些噪声段可能过密或过稀,压缩采样步数时这种偏差更容易放大成结构或细节问题。
线性日程的最大优点,是它足够直接、足够容易实现,也因此成为很多早期工作和教学材料的起点。它给人一种“每一步都均匀增加一些噪声”的直观感,这对理解正向过程非常友好。
但问题在于,训练真正感受到的不是 本身,而是整个过程中 SNR 如何分布。线性变化的 并不意味着“信息难度线性变化”。在很多实际模型里,它会让某些时间区间过于拥挤,另一些区间又学得不够。
3.2 Cosine 日程
很多后来工作更偏好用 的余弦形式控制噪声衰减。
直觉上,它试图让信号保留得更平滑,避免过早把图像彻底打成白噪声。
这类日程的优点往往体现在训练更平衡和少步采样更稳:SNR 衰减更平滑,模型不容易只偏向某一段噪声水平,稀疏选 timestep 时轨迹也通常不那么极端。
Cosine 日程之所以常被偏好,不是因为“余弦形式更优雅”,而是因为它更像在直接塑造一个更平滑的信噪比衰减过程。这样模型在中高噪声区间通常能拿到更自然的训练分布,不会太早失去对有效结构的感知。
在很多实践里,Cosine 更适合作为“默认更稳”的起点,尤其当你关心少步采样、latent diffusion 或更复杂的条件控制时。它不一定在所有设置下都绝对更强,但更容易给出一个不那么极端的训练几何。
3.3 连续时间与 EDM 风格日程
在连续时间或 EDM 框架中,更常直接用噪声标准差 参数化训练与采样区间。
这样做的好处是 ODE / SDE 视角更统一,sampler 设计也更直接:用连续噪声尺度描述训练和采样,更容易接到概率流与随机微分方程;沿 区间选步长、排采样点和配 solver 也会更清楚。
一旦采用连续时间或 sigma 参数化,你对训练和采样的理解就会从“离散步编号”变成“在噪声尺度上移动”。这对后续的 solver 设计、少步推理和采样调度都很有帮助,因为系统不再被固定的离散网格束缚。
EDM 风格的重要性还在于,它把很多原本零散的经验重新写回设计空间:该在什么噪声范围训练,如何采样训练时间点,solver 如何沿噪声尺度推进。这样一来,日程、参数化和 sampler 就更容易放在同一张图里比较。
4. 参数化方式:模型到底在预测什么
这是扩散里最容易看似换符号、实则换优化几何的部分。
常见的目标有四类:
4.1 预测噪声
这是最经典、最广泛使用的参数化。
优点是实现简单、训练稳定,并且与 DDPM 主线一致:目标就是回归注入的 ,监督构造直接,目标尺度清晰,许多基础实现和经验也都围绕它建立。
很多基础教材默认从它开始讲,是合理的。
噪声预测的价值,在于它把训练目标直接对准“当前带噪图里混进来了多少噪声”。这让监督信号形式统一、实现简洁,也非常适合作为扩散主线的起点。很多经典 DDPM 与后续文生图系统,都是在这个参数化上建立起来的。
但它也有自己的倾向性。因为目标本身偏向噪声尺度,训练时不同 SNR 区间的梯度结构会受到较大影响。于是它是否好用,往往和日程、loss weighting、solver 以及 guidance 一起决定,而不是单独决定。
4.2 预测原图
它的直觉最强,因为模型直接学“把当前带噪图还原成原图”。
但它对不同噪声区间的尺度变化更敏感,因此并不总是比噪声预测更稳。
x_0 预测最吸引人的地方,是它非常符合人的直觉:既然目标是恢复干净图像,那就直接让模型去猜干净图像本身。这在某些编辑任务、重建导向任务和解释模型行为时都很有帮助。
问题在于,越高噪声的样本离真实 越远,直接回归原图的尺度压力就越大。于是它对时间权重和数据尺度通常更敏感,也更容易把训练难度集中到高噪声区间。
4.3 预测 score
这在 score-based SDE 路线中很自然。
它的意义在于把扩散明确地连到 score matching 和连续时间动力学上。
score 参数化的最大价值,不在于它一定更容易工程落地,而在于它让“扩散为何成立”这件事有了更统一的理论语言。你不再只是把模型看成一个黑盒去噪器,而是把它看成估计当前噪声分布梯度方向的向量场。
一旦这个视角建立起来,很多 solver、连续时间路径和概率流 ODE 的讨论就会自然连起来。也正因此,score 路线常常是理论理解和方法统一的关键桥梁。
4.4 预测 velocity
前面三种参数化都可以从同一条加噪路径推出来。先把前向混合写成更统一的形式:
在 VP / cosine 一类常见设定中,通常有 。这时 velocity 常定义为:
网络学习:
它不是凭空多出来的目标,而是 这组坐标的一个旋转。若模型预测出 ,就能和当前 互相换回 和 :
这两条换算很实用。训练时模型可以回归 ,推理时 sampler 或 guidance 仍然可以按需要取 、 或 score 形式。很多代码里看起来“模型输出 velocity,但采样器又在用 epsilon 或 x0”,本质就是在做这组坐标变换。
velocity 这个名字也有严格来源。若把路径写成角度形式:
那么对 求导:
所以 真的是“沿着信号到噪声混合路径移动的速度”。它不是物理世界里物体运动速度,也不是视频中的 optical flow,而是 latent / data 空间中从干净样本到噪声样本这条路径的切向量。
这类参数化在 latent diffusion、少步采样和 guided 场景下经常更稳,因为它在不同 SNR 区间里平衡了 和 两种信息。
v 参数化的受欢迎,很大程度上来自它不像纯 那样过分偏向噪声,也不像纯 那样过分承受尺度变化。它更像在学习“当前状态沿着去噪轨迹应该怎么运动”,因此经常和少步 solver、latent 空间和 guidance 路线配合得更舒服。
这也是为什么很多近年的实践更愿意把它视为一个默认更平衡的坐标系,而不是只把它当成符号替换。
两者都可以被直观理解成“预测速度”,但层级不同。v-prediction 通常是在 DDPM / DDIM / latent diffusion 框架里换一个监督坐标,模型仍围绕给定噪声日程学习去噪目标。Flow Matching 则更直接:先指定一条从噪声分布到数据分布的连续路径,再让模型回归这条路径上的速度场,并在采样时积分一个 ODE。
因此可以说:在某些三角路径或扩散路径下,-prediction 是 Flow Matching 视角下的一个特例或近邻表达;但不能简单把所有 -prediction 都等同于完整的 Flow Matching 训练框架。
5. 这些参数化为什么本质上是等价又不等价
从信息论上看,只要你知道 、 并预测了其中一种量,往往可以解析恢复另外几种。
例如已知 时:
所以它们在“可表示的信息”上接近等价。
但它们在优化过程中并不等价,因为损失尺度、梯度权重、guidance 适配和少步 solver 适配都会改变。同一预测误差换到不同目标坐标后,数值大小和敏感区间会变;不同 timestep 对参数更新的贡献也会随参数化改变。
也就是说,它们像是在不同坐标系里优化同一个问题。
6. 为什么 velocity 参数化近年更常见
因为它在高 SNR 和低 SNR 两端都相对平衡。纯噪声预测在某些区间会让优化更偏向噪声分量,纯 预测则更容易受尺度影响;而 参数化在很多实践中表现为少步采样兼容性更好、guided generation 更稳、latent space 里更舒服。
更细一点看,velocity 的收益来自四个层面。
第一,它把高噪声和低噪声两端的目标尺度压得更接近。高噪声时,直接预测 要从几乎纯噪声里猜干净样本,误差容易很大;低噪声时,预测 又可能把训练压力放在很小的残差上。 混合了两者,使模型在整条路径上的回归目标更均衡。
第二,它和 cosine / 角度式日程天然搭配。若用 表示噪声角度,模型预测的就是 。这让很多 ODE solver 更容易把模型输出理解成沿路径前进的方向,而不是在每一步先换回噪声再间接更新。
第三,它对强 guidance 更友好。Classifier-free guidance 本质上会放大条件和无条件输出的差值。如果输出坐标本身在不同噪声段尺度差异很大,放大后更容易过冲,出现高对比、颜色偏移、纹理炸裂或视频闪烁。velocity 坐标通常能让 guidance 的尺度更平滑,但这不是免调参的保证,guidance scale、time schedule 和 solver 仍然要一起看。
第四,它非常适合视频和 latent 模型。视频 latent 里同时有空间结构、时间运动和压缩器带来的尺度变化;如果目标坐标在某些噪声段过于偏向 或 ,模型容易把容量浪费在局部噪声或静态纹理上。velocity 让模型更像在学习“这个 noisy video latent 接下来应该往哪里流动”,因此和 Flow Matching、Rectified Flow、Wan / Sora 类视频 DiT 的训练语言更接近。
实践上可以这样判断:
| 场景 | 为什么更常选 velocity |
|---|---|
| latent diffusion | latent 尺度不等同于像素尺度, 对 SNR 两端更平衡 |
| 少步采样 | 轨迹更新更像直接沿路径走,低步数下更不容易极端偏向某一端 |
| 强 CFG | 条件差值放大后更需要稳定输出坐标 |
| 视频生成 | 时空 latent 的误差会跨帧累积,目标尺度平衡更重要 |
| Flow / Rectified 路线 | 训练语言接近“拟合速度场”,便于和 ODE 采样衔接 |
一个直观比喻
如果说噪声预测像只盯“照片里加了多少脏东西”,原图预测像只盯“干净照片应该长什么样”,那么 velocity 更像同时考虑“信号和噪声之间的混合运动方向”。
7. 损失重加权为什么重要
即便选定参数化方式,训练时仍常需要对不同时间点重加权。
可写作:
其中 决定低噪声细节权重和高噪声语义权重:前者更强调边缘、纹理和局部保真,后者更强调从弱信号中恢复主体结构和全局语义。
这其实又回到了前面说的 SNR 平衡问题。
很多训练现象如果只看“总 loss”,会显得很玄学;一旦意识到不同时间点的损失其实在争夺模型容量,问题就会清楚得多。重加权不是装饰项,而是在明确告诉模型:你希望它把更多容量花在什么噪声区间、什么难度段上。
这也是为什么某些模型训练 loss 很漂亮,但采样质量并不理想。因为它可能只是把更容易优化的区间学得更好了,而不是把最终最影响视觉质量或少步稳定性的区间学得更好了。
8. 日程与参数化不是独立设计
这是最值得强调的一点。
很多实现把它们写成两个可选开关,但从效果上看,它们高度耦合:
- 某种噪声日程在 -prediction 下很稳,换成 -prediction 未必
- 某种参数化在长链采样下好用,在少步 solver 下未必最好
因此合理做法不是“分别调最优”,而是把噪声日程、参数化、loss weighting 和 sampler 放在同一框架下考虑:日程决定训练样本落在哪些噪声区间和 SNR 如何变化,参数化决定模型用 、、score 还是 这样的坐标来学习,loss weighting 决定不同噪声区间的误差在优化里有多重要,sampler 决定推理时如何把学到的向量场离散成有限步更新。
更直白地说,日程决定“样本在哪些噪声段被看到得更多”,参数化决定“模型用什么坐标系理解这些噪声段”,reweighting 决定“哪些段更值得认真学”,而 sampler 决定“这些训练成果最终如何被兑现”。它们像同一条链上的四个齿轮,只要有一个齿轮啮合不顺,整条链都会表现怪异。
9. 三个实践场景
9.1 高质量图像生成
这里关注训练稳定、高频细节和文本对齐:loss、梯度和样本质量不要在某些噪声段突然崩掉,纹理、边缘、小物体和局部清晰度要能保住,生成内容也需要贴合 prompt。对应地,噪声日程要让语义、结构和细节区间都有足够学习压力,参数化也要和 guidance 兼容,避免强条件引导时颜色过冲、结构断裂或局部发散。
这类场景最在意的是全局语义、局部细节和条件贴合能否同时成立。噪声日程若过于偏某一段,模型就可能要么大结构好但细节虚,要么细节锐但整体构图不稳。参数化若和 guidance 不兼容,则常在高提示强度时暴露颜色过饱和、局部断裂或文本对齐抖动。
9.2 少步采样或实时场景
这里关注与 solver 的匹配和极少步下的误差放大:训练坐标和采样更新公式要配合,否则低步数会暴露偏差;4 步、8 步甚至一步时,单次预测错误会被直接放大到成图质量里。
这时参数化方式的影响会更明显,尤其在 latent 模型中。
因为步数一压缩,原来分布在多步里的误差会集中到少量更新中,训练坐标系是否合适就会被迅速放大。很多在长链采样里差异不大的设计,一到 4 步、8 步甚至一步附近,就会表现出完全不同的稳定性和细节保真度。
9.3 视频或长时序扩散
这里关注多帧一致性、时间噪声分配和条件控制稳定性:身份、纹理和动作轨迹在时间上不能跳变,噪声不仅要沿生成步分配,还要考虑帧间结构是否同步,文本、轨迹、首帧或参考图条件也需要跨帧保持影响。
此时日程设计常不再只是“图像单帧问题”,而要兼顾时序结构。
视频里最难的地方,是每一帧的去噪问题和跨帧一致性问题会相互干扰。某种日程或参数化在单帧上很好,不代表它在长时序上仍能稳住身份、动作和局部纹理。时间维一旦拉长,噪声如何在帧间分配、条件如何跨帧保留,都会让“单帧最优”失去意义。
10. 常见误区
误区 1:参数化方式只是换个符号
实际上它会显著改变优化几何与采样行为。
如果真只是符号变化,就不会在少步采样、latent diffusion 和高 guidance 下出现如此稳定的经验差异。参数化改变的是模型如何看待信号与噪声混合状态,也因此改变了不同时间点上的学习难度。
误区 2:噪声日程只是细枝末节
很多训练稳定性和少步采样表现都深受其影响。
日程一旦设得不合适,模型等于被迫在一个偏斜的课程表里学习去噪。它可能不是第一眼最显眼的开关,但常常是最深层地决定训练行为的开关之一。
误区 3:单看 loss 就能判断哪种设计更好
有时训练 loss 更低,但真实采样质量、文本对齐或少步表现反而更差。
这是因为总 loss 把很多不同噪声区间、不同难度段和不同下游目标全部揉在一起了。没有结合采样表现、条件遵守、少步稳定性和任务质量去看,loss 很容易给出一个过于乐观的信号。
11. 推荐跳转
- 看训练主线:扩散训练与表示
- 看采样器与求解器:采样与推理加速
- 看少步/一步路线:一步生成、蒸馏与整流
12. 一个总判断
扩散模型里的噪声日程和参数化,作用有点像数值求解中的坐标系与步长安排。
单看某一项都像“局部技巧”,但一旦和 sampler、guidance、蒸馏路线合起来看,它们其实处在整条扩散工程链的最底层。
快速代码示例
1 | import torch |
这段代码给出一个常见的 SNR reweighting 训练写法:先由 alpha_t 计算每个时间步的权重,再对 MSE 做重加权。它的目的通常是平衡不同噪声区间的学习难度,避免训练被少数区间主导。
工程收束
噪声日程、参数化选择、loss reweighting 和数据尺度要一起看。它们共同决定模型在哪些噪声区间学得更充分,也决定采样器能否兑现训练收益;验收时应同时看训练 loss 分桶、采样稳定性、条件遵从、显存和步数预算。
- Title: 扩散模型:噪声日程与参数化
- Author: Charles
- Created at : 2025-05-14 09:00:00
- Updated at : 2025-05-14 09:00:00
- Link: https://charles2530.github.io/2025/05/14/ai-files-diffusion-noise-schedules-and-parameterization/
- License: This work is licensed under CC BY-NC-SA 4.0.