
扩散模型:Score Matching 到 SDE:扩散模型到底在学哪一个方向
扩散模型表面上是在预测噪声,采样时又像在逐步去噪。更统一的读法是:模型在每个噪声水平上学习一个方向场,告诉当前样本应该往哪里移动,才能从噪声分布回到数据分布。这个方向场的核心对象叫 score。
这页只回答一个问题:为什么 DDPM 的噪声预测、Score SDE 的反向过程、Probability Flow ODE 和 DPM-Solver 这些名字,其实都围绕同一件事:学一个可积分的生成方向。
score 是概率密度的坡度
对一个连续分布 ,score 定义为:
这里 是样本, 是样本密度, 是对数密度, 表示对样本坐标求梯度。白话说,score 指向“让当前点的概率密度上升最快”的方向。
如果把数据分布想成地形,高概率区域像山脊,低概率区域像山脚。score 就是你脚下的坡度箭头。生成模型从噪声出发,需要知道每一步应该往哪个方向走,才能更像真实数据。
问题是,真实图像分布 没有解析公式。我们只有样本,没有办法直接算:
这就是 score matching 要解决的入口:既然不知道密度本身,能不能直接学它的梯度方向。
扩散不是一个分布,而是一串分布
扩散模型不会只在干净数据分布上学 score。它人为定义一串加噪分布:
1 | p_0(x): 干净数据分布 |
所以扩散里的 score 是时间相关的:
这里 是噪声水平 下的样本,既不是完全干净的 ,也不是纯噪声。这个 score 告诉模型:在当前噪声水平下,这个样本往哪里移动,会更接近该时刻的高概率区域。
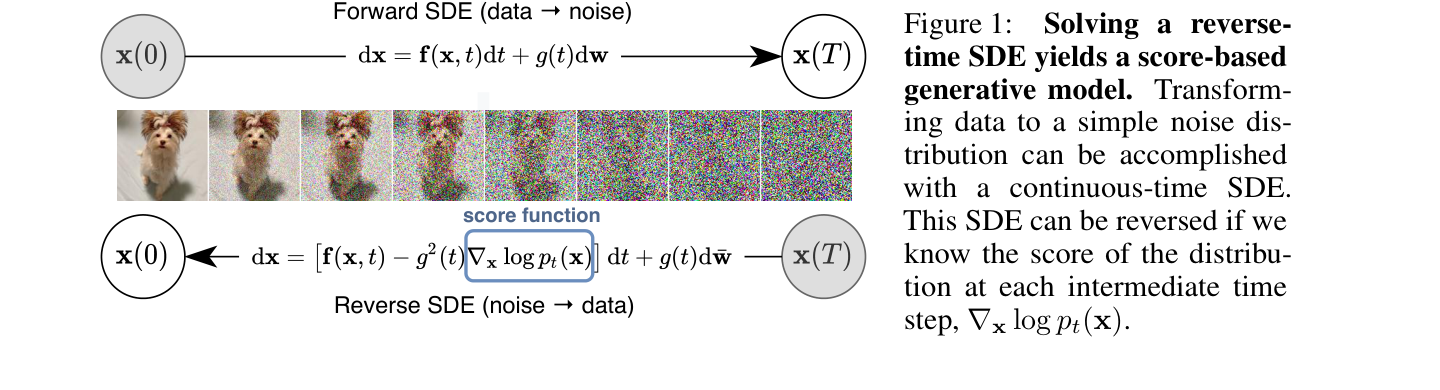
图源:Score-Based Generative Modeling through Stochastic Differential Equations,Figure 1。原图表达正向过程把数据逐渐扰动成噪声,反向过程依赖每个中间分布的 score 从噪声生成数据。本文用它说明:扩散采样不是凭空“去噪”,而是在一串噪声分布上沿概率方向移动。
读这张图时先看时间方向。左到右是正向加噪:数据越来越像高斯。右到左是生成:先采一个高斯噪声,再用模型估计每个时刻的 score,把样本推回数据区域。模型难的不是“最后一步修图”,而是在所有噪声水平上都给出可用方向。
噪声预测为什么能变成 score
DDPM 常见的加噪形式可以写成:
这里 是干净样本, 是标准高斯噪声, 控制保留多少信号, 控制加入多少噪声。时间越靠后, 越大, 越像噪声。
在给定 的条件高斯分布里,score 可以直接算:
这行式子拆开读: 正是加进去的噪声部分,等于 ;高斯 log density 对 求梯度后会指向均值 ,也就是“把噪声往回拉”的方向;最后得到 。
所以模型预测噪声 时,也在学一个可转成 score 的方向:
这里的负号很重要。预测出的噪声方向表示“污染来自哪里”;去噪方向要反过来,往数据高概率区域移动。尺度 表示不同噪声水平下,方向大小要按噪声强度校准。
训练目标不是玄学,是条件 score matching
理想目标是:
但边缘分布 是所有数据点加噪后的混合分布,真实 score 仍然不可直接算。扩散训练绕过这个困难的方法是:我们知道每个训练样本 和自己采样的噪声 ,因此可以训练模型预测条件高斯里的修正方向。
常见 DDPM loss 是:
这里期望里的 来自数据集, 是我们主动采样的高斯噪声, 是噪声水平。模型看到 noisy sample ,学习把当初加进去的噪声 预测出来。
这就是很多中文资料强调的“条件得分匹配”:训练时目标来自 这条可计算的条件分布,而不是直接拿不可知的 来监督。经过对 的期望,它会成为学习边缘 score 的可行训练方式。
SDE 把离散加噪变成连续时间
DDPM 使用有限个离散时间步。Score SDE 把步数推到连续时间,用随机微分方程描述正向加噪:
这里 是确定性漂移, 是随机噪声注入, 是 Wiener process。直觉上,样本一边按规则漂移,一边不断被随机噪声扰动。
这个写法的价值不是把事情变难,而是统一:
| 离散/连续视角 | 它在说什么 |
|---|---|
| DDPM | 固定时间表上的逐步加噪和反向去噪 |
| SMLD / VE-SDE | 噪声方差逐渐变大,数据被扩散到很宽的噪声分布 |
| VP-SDE | 保持总体方差结构,DDPM 可以看成它的离散化 |
| sub-VP-SDE | 为 likelihood 和采样稳定性改写噪声结构 |
一旦写成 SDE,很多采样器就不再是孤立 trick,而是不同的数值求解方式。
反向 SDE:回来时必须知道 score
Score SDE 的关键公式是反向时间过程:
这里 是反向时间里的 Wiener process。括号里的第一项 来自正向 SDE 的漂移;第二项 使用 score 修正方向;最后的 保留随机性。
真实 score 不知道,所以用网络替代:
这两行式子合起来表达:只要模型在每个噪声水平都能估出足够好的 score,就可以从简单噪声分布反向积分回数据分布。反向 SDE 的随机项会带来采样多样性,但也意味着采样路径不是确定的。
Probability Flow ODE:同一边缘分布的确定路径
同一个 score-based model 还对应一条确定性的 probability flow ODE:
这条 ODE 没有随机 Wiener 项,score 项前的系数也变成 。它的关键性质是:它和反向 SDE 拥有相同的边缘分布 ,但每个初始噪声点对应一条确定轨迹。

图源:Score SDE,Figure 3。原图表达 probability flow ODE 可以把数据确定性编码到 latent,也可以从 latent 确定性解码回数据。本文用它说明:ODE 视角让 likelihood、latent encoding 和高阶数值求解器进入扩散采样讨论。
ODE 视角解释了 DDIM、Euler、Heun、DPM-Solver 这些采样器为什么能接在扩散模型后面。模型提供方向场,采样器负责用有限步数积分这条路径。步数少时,主要风险不再是“模型不会去噪”,而是数值积分误差和方向场误差被放大。
sampler 是怎样使用这个方向场的
有了 、 或 ,采样器要做的是把连续方向变成离散更新。最粗略的一阶更新可以写成:
这里 是由 score、noise prediction 或 data prediction 转换出的当前速度方向, 是时间步长。Euler 是最直接的一阶近似;Heun 会先预测再校正;DPM-Solver 利用 diffusion ODE 的特殊结构做高阶更新。
这就是为什么同一个 checkpoint 换 sampler 会有不同质量和速度。模型学的是方向场,采样器决定如何走这条方向场。少步采样不是简单“跳过几步”,而是在更粗的时间网格上近似同一条或相近的生成轨迹。
和 Flow Matching / Rectified Flow 的关系
Score SDE 路线的核心是学 score,再由 SDE/ODE 定义反向路径。Flow Matching / Rectified Flow 则更直接:给定一条从噪声到数据的路径,训练模型预测这条路径上的速度场。
可以这样区分:
| 路线 | 模型主要学什么 | 采样时怎么走 |
|---|---|---|
| DDPM / score-based diffusion | 噪声、score 或 data prediction | 沿反向 SDE/ODE 逐步积分 |
| DDIM / ODE samplers | 同一个去噪模型的确定轨迹 | 用更稀疏时间网格跳步 |
| DPM-Solver / DPM-Solver++ | diffusion ODE 的高阶积分 | 在少 NFE 下减小数值误差 |
| Flow Matching / Rectified Flow | 路径上的 velocity field | 直接沿速度场从噪声流向数据 |
共同点是:生成都变成了沿某个方向场移动。区别在于方向场的定义、训练目标、时间参数化和路径形状。现代视频扩散和 rectified-flow 模型常喜欢 velocity 目标,是因为它更直接贴近 ODE 采样和少步化。
容易误读的地方
| 误解 | 更准确的说法 |
|---|---|
| score 就是模型输出的噪声 | 噪声预测可以转换成 score,但有负号和噪声尺度。 |
| DDPM loss 直接监督真实 score | 常见训练目标更像条件 score matching;真实边缘 score 不直接可见。 |
| SDE 只是把公式写复杂 | 连续时间框架统一 DDPM、SMLD、ODE sampler、likelihood 和求解器。 |
| ODE 采样一定比 SDE 好 | ODE 可确定、可用高阶 solver,但质量取决于模型、路径、步数和 guidance。 |
| 少步采样只是少算几次模型 | 少步会放大方向场误差和数值积分误差,常需要 solver、蒸馏或重训目标。 |
读完以后怎么判断
Score matching 到 SDE 这条线的核心知识不是记公式,而是抓住一个转换:扩散模型把“直接建模复杂数据分布”改写成“在每个噪声水平学习往数据分布走的方向”。DDPM 的噪声预测、Score SDE 的反向过程、Probability Flow ODE 和 DPM-Solver 都是在使用这个方向,只是训练参数化和采样求解方式不同。
读扩散论文时可以先问三件事:模型输出的是噪声、score、 还是 velocity;采样走的是随机 SDE、确定 ODE 还是 flow path;少步时靠 solver、蒸馏、consistency,还是重新训练目标。问清这三件事,DDPM、DDIM、Score SDE、DPM-Solver 和 Rectified Flow 就不再是一堆名字,而是一条生成轨迹的不同写法。
外部精读
- Yang Song: Generative Modeling by Estimating Gradients of the Data Distribution:作者博客,适合先建立 score、Langevin dynamics 和多噪声扰动的直觉。
- Lil’Log: What are Diffusion Models?:把 DDPM、score、SDE、sampling 和 guidance 放在一条解释链里。
- Score-Based Generative Modeling through SDEs:SDE / ODE 统一视角的核心论文。
- DDPM:理解离散前向加噪、反向去噪和噪声预测目标。
- DDIM:理解确定性采样、跳步和 probability-flow 直觉。
- DPM-Solver++:看高阶 ODE solver 如何服务少步 guided diffusion。
- 科学空间:得分匹配 = 条件得分匹配:中文长文,适合补“为什么 DDPM 常见目标更准确地说是条件得分匹配”。
相关阅读与下一步
- 外部材料:Lil’Log:What are Diffusion Models?。
- 外部材料:DDPM 论文。
- 外部材料:Score SDE 论文。
- 站内下一步:扩散模型专题。
- 站内下一步:扩散方法对比表。
- 站内下一步:Score Matching、SDE 与 Probability Flow。
- Title: 扩散模型:Score Matching 到 SDE:扩散模型到底在学哪一个方向
- Author: Charles
- Created at : 2025-05-15 09:00:00
- Updated at : 2025-05-15 09:00:00
- Link: https://charles2530.github.io/2025/05/15/ai-files-diffusion-score-matching-sde-and-probability-flow/
- License: This work is licensed under CC BY-NC-SA 4.0.