
扩散模型:扩散训练:从加噪到去噪方向场
扩散模型训练的核心不是“从噪声里变出图片”。更准确地说,它训练一个模型:在任意噪声强度下,看着一份被污染的样本,判断它应该往哪个方向移动,才更像真实数据。采样时再把这些局部方向串起来,从纯噪声走回图像、视频、音频或动作轨迹。
这篇只回答一个问题:为什么主动把好样本加噪,反而能得到一个强生成模型。
先用一张猫图想象。低噪声时,猫还清楚,模型主要学修边缘、毛发和颜色;中噪声时,主体轮廓开始模糊,模型要判断“这团灰影大概率是什么结构”;高噪声时,图像几乎像随机点,模型学的是从无结构噪声往数据分布移动的粗方向。扩散训练的知识含量就在这里:它把一次很难的生成问题,拆成很多不同噪声尺度下的局部修正问题。
前向加噪是人为造出来的监督任务
DDPM 的前向过程从干净样本 出发,逐步加入高斯噪声。常见闭式写法是:
这行公式的意思是:给定干净样本 ,第 个噪声水平的样本 服从一个高斯分布。均值是被缩小的干净样本 ,方差是 。当 接近 1,样本还很干净;当 接近 0,样本接近纯噪声。
训练时更常用显式采样形式:
这行式子非常关键。我们知道 ,也知道自己采样了哪份噪声 ,还知道时间步 。所以训练数据可以无限构造:随机选一张真图,随机选一个噪声强度,随机采一份噪声,把它们混成 ,然后让模型从 里判断这份污染怎么修。
这就是扩散训练稳定的原因之一。真实数据分布 很复杂,直接学它的密度很难;但“我刚加进去的噪声是什么”是一个明确的监督信号。模型学会这个监督任务后,采样时就能把预测噪声转成往数据分布走的方向。

图源:Denoising Diffusion Probabilistic Models,Figure 2。原图表达前向过程逐步加噪,反向过程逐步去噪。本站使用这张图说明:训练时前向加噪由我们控制,采样时只保留学到的反向去噪模型。
看这张图时,左到右是固定的 noising chain,右到左是要学习的 denoising chain。扩散模型的巧妙之处不是“噪声很神奇”,而是前向过程让每个时间步都变成可监督的去噪学习问题。
预测噪声不是唯一目标
DDPM 常见训练目标是预测噪声:
白话说:模型输入 和 ,输出它认为被加进去的噪声 。如果猜得接近真实噪声 ,loss 就小。这个目标看起来像普通 MSE,但它的作用不只是“去掉噪点”。在高斯加噪设定下,噪声方向和 score 方向可以互相换算,模型预测噪声其实也在学习当前噪声分布的概率梯度方向。
如果模型能预测噪声,就能反推出干净样本估计:
这说明 -prediction 和 -prediction 不是完全不同的世界,而是同一个加噪公式的不同坐标。模型也可以预测 score:
score 表示在当前噪声水平下,往哪个方向移动会让样本更接近高概率区域。还可以预测 velocity ,它常被理解为在 之间换一个更适合训练和采样的坐标。现代视频模型、DiT 和 flow/rectified flow 路线经常讨论 velocity,就是因为少步采样和强 guidance 下,输出坐标会影响优化几何和数值稳定性。
所以不要把“预测噪声”背成唯一答案。更重要的问题是:这个参数化是否让不同 SNR 区间的训练信号平衡,是否适合采样器,是否在 guidance 或视频长时一致性下稳定。
Noise schedule 决定模型在哪些难度上练习
Noise schedule 决定 或噪声标准差 随时间如何变化。它不是装饰超参,而是在决定训练任务的难度分布。
低噪声区接近细节修复:边缘、颜色、局部纹理还在,模型需要做精修。高噪声区接近语义重建:局部证据很少,模型要从条件和数据先验里猜全局结构。中间噪声区连接两者,是很多结构和语义开始形成的地方。
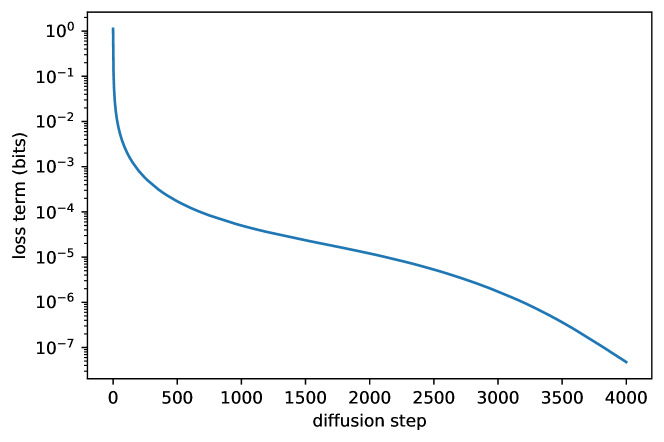
图源:Improved Denoising Diffusion Probabilistic Models,Figure 2。原图表达不同时间步对 variational lower bound 的贡献差异。本站使用它说明:不同噪声区间的训练信号强弱不同,noise schedule 和 loss weighting 会改变模型把容量花在哪里。
如果 schedule 太快把样本推到高噪声,模型可能缺少学习中间结构的机会;如果太慢,训练和采样步数会很长。Improved DDPM 推动 cosine schedule,是因为它让信号衰减更平滑。EDM 进一步把噪声尺度、preconditioning、采样器和 NFE 放进同一个设计空间里看。
图源:Elucidating the Design Space of Diffusion-Based Generative Models,Figure 2。原图表达噪声水平、采样轨迹和 denoising network 之间的设计空间。本站使用它说明:扩散训练和采样不是两个孤立模块,噪声参数化会直接影响采样器如何走。
对图像、视频和动作扩散来说,schedule 的意义也不同。图像生成要平衡全局语义和高频纹理;视频生成还要让时间一致性跨噪声区间保持;动作扩散要避免把多峰可行动作平均成不可执行轨迹。噪声日程和 loss weighting 实际是在分配模型容量。
条件不是后处理,训练时就要进入去噪器
无条件扩散只学 。条件扩散学的是 ,条件 可以是类别、文本、图像、mask、深度、姿态、动作或历史状态。训练时 denoiser 通常写成:
这表示模型预测噪声时不仅看带噪样本和时间步,还要读取条件。文本到图像里的 cross-attention、ControlNet 里的结构条件、视频模型里的首帧或轨迹条件、动作扩散里的观测状态,都是在回答同一个问题:去噪时模型到底能用什么证据。
Classifier-free guidance 也要从训练说起。训练时模型有一部分样本会把条件丢掉,使用空条件 。这样同一个网络同时学到条件预测和无条件预测:
采样时再把条件带来的方向差放大。也就是说,guidance 不是纯后处理魔法,它依赖训练时模型见过“有条件”和“无条件”两种输入。若条件 dropout、文本质量、条件编码器或跨模态接口本身不好,采样时再把 guidance scale 拉高,只会放大一个不可靠方向。
采样把局部方向串成生成轨迹
训练学到的是局部方向:给定 ,模型告诉你当前应该怎么修。采样时从 开始,按照某个时间网格反复调用模型,把局部方向串成从噪声到数据的轨迹。

图源:DDPM,Figure 14。原图表达从噪声到图像的逐步生成过程。本站使用它说明:采样不是一次性解码,而是在不同噪声尺度上逐步建立大结构、局部形状和细节。
DDPM 采样保留随机反向链,通常步数多;DDIM 改变采样路径,可以跳步;Score/SDE 和 probability flow ODE 把采样看成连续时间轨迹;DPM-Solver、Euler、Heun 等方法则是在有限 NFE 下更好地积分这条方向场。
这也解释少步采样为什么难。1000 步时,每一步只做小修正;10 步或 4 步时,每一步要跨越更大的分布距离。模型在训练时如果只学过细小步长的局部修正,少步采样就容易走偏。Consistency model、LCM、DMD、DMD2、Rectified Flow 等方法要重新设计训练目标或蒸馏目标,本质上是在训练一个更适合跨大步的学生模型或更直的生成路径。
表示空间决定扩散在哪儿发生
早期扩散可以直接跑在像素空间,但高分辨率图像和视频会很贵。Latent diffusion 的关键是先用 VAE 把图像压到 latent,再在 latent 上扩散。这样空间尺寸更小,训练和采样更便宜;代价是 VAE 的压缩会限制细节,解码器也会成为质量上限的一部分。
DiT 把 denoiser 从 U-Net 换成 Transformer。图像 latent 被切成 patch token,时间步和文本条件进入 Transformer block。这里扩散目标和 Transformer 架构分工很清楚:扩散定义训练任务和采样轨迹,Transformer 负责建模 token 间关系。
读视频扩散或世界模型时,表示问题更尖锐。视频 latent 不只要像素好看,还要保持物体身份、运动、遮挡和长时一致性。若加入动作条件,模型还必须学到“不同动作会导致不同未来”。一个生成漂亮短视频的模型,不等于能作为世界模型给 planner 使用;它还需要动作敏感性、状态接口和闭环评测。
训练日志应该看什么
扩散训练不能只看一条平均 MSE。更实用的日志至少要按时间步或 SNR 分桶:
1 | loss by timestep / SNR bucket |
如果低噪声 loss 很好但高噪声区差,样本可能纹理漂亮但主体乱;如果高噪声区正常而低噪声区差,构图可能对但细节糊、边缘脏。若训练 loss 正常但强 guidance 下崩,问题可能不在 denoiser 单步回归,而在条件方向、采样器和少步轨迹的组合。
视频和动作扩散还要加额外桶:身份一致性、运动连续性、遮挡再出现、动作条件敏感性、轨迹平滑度、闭环成功率。对世界模型而言,平均视觉指标很容易掩盖“动作后果不对”。
容易误读的地方
误解一:扩散模型就是不断去噪。
去噪只是表层动作。真正决定效果的是前向噪声过程、预测目标、noise schedule、条件接口、采样器和表示空间。
误解二:预测噪声是唯一正确目标。
、、score、velocity 都是描述同一去噪问题的不同坐标。它们会影响训练权重、采样稳定性和少步蒸馏。
误解三:少步采样只是少跑几步。
步数少意味着每一步跨越更大的分布距离。没有合适 solver、distillation 或路径重构,少步会牺牲质量和稳定性。
误解四:视频扩散自然就是世界模型。
没有动作条件、状态接口和闭环评测时,视频扩散更像生成器。世界模型还要证明未来预测能支持决策。
读完以后怎么判断
扩散训练的核心是把生成建模转成可监督的方向场学习。前向加噪由我们控制,所以模型可以在每个噪声水平学习“如何往数据分布修正”;预测 、、score 或 是不同坐标选择;noise schedule 决定不同难度区间的训练权重;条件接口决定去噪时能使用什么证据;采样器和蒸馏决定这些局部方向如何变成实际生成轨迹。
读扩散论文时,先问五件事:数据在哪个表示空间里加噪;模型预测什么目标;时间步或噪声尺度如何采样;条件如何进入 denoiser;推理时用什么 sampler 和多少 NFE。问完这五件事,DDPM、latent diffusion、DiT、视频扩散和动作扩散就会落到同一条主线上。
外部精读
- Lil’Log: What are Diffusion Models?:把 DDPM、score、SDE、采样和 guidance 放在同一条解释链里。
- The Annotated Diffusion Model:用 PyTorch 代码把 forward process、noise schedule、loss 和采样过程对上。
- DDPM:理解前向加噪、反向去噪和基本训练目标。
- Improved DDPM:理解 cosine schedule、learned variance 和 VLB 贡献。
- Score-Based Generative Modeling through SDEs:理解 score field、reverse SDE 和 probability flow ODE。
- EDM:把噪声尺度、preconditioning、sampler 和 NFE 放进同一个设计空间。
- Latent Diffusion Models:理解为什么现代高分辨率生成常在 latent space 里训练。
- DiT:理解扩散目标如何和 Transformer denoiser 结合。
相关阅读与下一步
- 外部材料:Lil’Log:What are Diffusion Models?。
- 外部材料:DDPM 论文。
- 外部材料:Score SDE 论文。
- 站内下一步:扩散模型专题。
- 站内下一步:扩散方法对比表。
- 站内下一步:Score Matching、SDE 与 Probability Flow。
- Title: 扩散模型:扩散训练:从加噪到去噪方向场
- Author: Charles
- Created at : 2025-05-16 09:00:00
- Updated at : 2025-05-16 09:00:00
- Link: https://charles2530.github.io/2025/05/16/ai-files-diffusion-training/
- License: This work is licensed under CC BY-NC-SA 4.0.