
扩散模型:Score Matching 到 SDE
前两页已经讲了:扩散训练常让模型预测噪声 、干净图 或 velocity 。这一页换一个更统一的视角:这些预测目标背后,都可以理解成模型在学习一个“往数据分布高概率区域走”的方向场。
这页先回答“Score Matching 到 SDE”在「扩散模型」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先知道张量、损失函数和高斯噪声的基本读法;不熟时回基础知识再继续。 必要时先回 扩散模型入口、基础知识 或 术语表。
主线关系:把训练目标、噪声日程、采样器、条件控制和蒸馏看成同一条链:带噪状态如何一步步被推回数据分布。
这个方向场叫 score。它是理解 DDPM、DDIM、SDE、ODE、DPM-Solver 和 Rectified Flow 的共同语言。
先看图:从数据到噪声,再从噪声回来
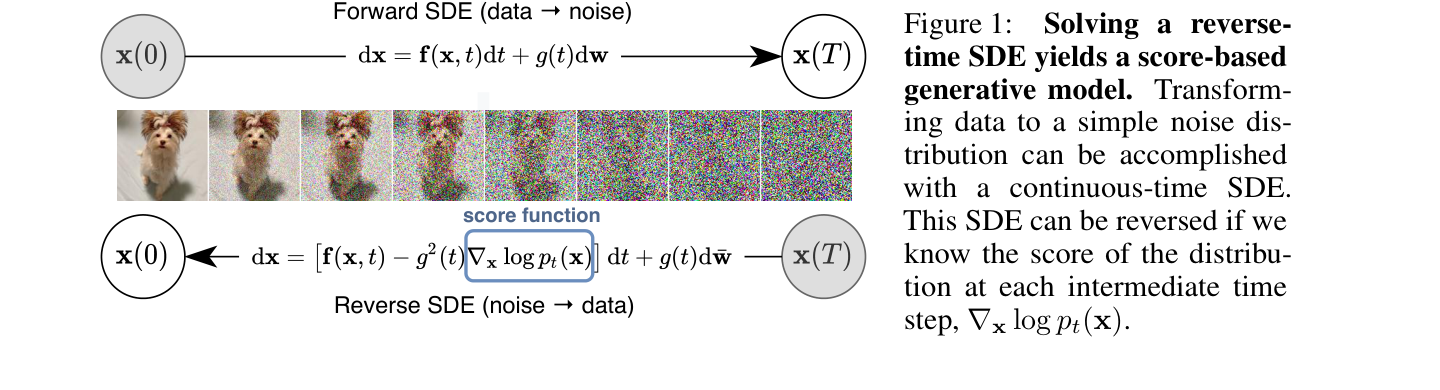
图源:Score-Based Generative Modeling through Stochastic Differential Equations,Figure 1。
原论文图意:正向 SDE 将数据逐步扰动成简单噪声分布;如果知道每个中间分布的 score ,就可以构造反向 SDE,从噪声生成数据。
本教程读法:上半部分是“数据 -> 噪声”,下半部分是“噪声 -> 数据”。中间被框出的 score function 是关键:它告诉反向过程在每个噪声水平下应该往哪里移动。
score 是什么
对一个概率分布 ,score 定义为:
这行式子在说:score 是对 关于 的梯度。它指向让概率密度上升最快的方向。
符号含义:
| 符号 | 含义 |
|---|---|
| 样本 所属的概率分布 | |
| 对数概率密度 | |
| 对 求梯度 | |
| score,指向更高概率区域的方向向量 |
如果把数据分布想成一片地形,概率高的地方像山峰,概率低的地方像山脚。score 就像当前位置的坡度箭头,告诉你往哪里走更接近高概率区域。
扩散里为什么要写成
扩散不是只有一个分布,而是每个噪声时间步都有一个分布:
- :干净数据分布;
- :加到第 个噪声水平后的分布;
- :接近标准高斯噪声的简单分布。
所以扩散里的 score 写成:
这行式子在说:在时间步 的噪声分布里,当前样本 应该往哪个方向移动,才会更像该噪声水平下的真实数据。
符号含义:
| 符号 | 含义 |
|---|---|
| 第 个噪声水平下的样本分布 | |
| 当前带噪样本 | |
| 该时间步下的 score |
注意:score 不是最终干净图本身,而是当前位置的方向信息。
噪声预测和 score 的关系
前向加噪可以写成:
这行式子在说:当前带噪样本 是干净图 和高斯噪声 的混合。
其中 采用采样写法:括号里的 是噪声均值, 是单位协方差。它不是说噪声只有一个标量,而是说和 同形状的每个维度都采独立标准高斯噪声。
在常见高斯扰动设定下,预测噪声和预测 score 可以互相对应。一个常见直觉关系是:
这行式子在说:模型预测出的噪声方向 ,取反并按噪声尺度 缩放后,就对应“往数据高概率区域走”的 score 方向。
符号含义:
| 符号 | 含义 |
|---|---|
| 模型估计的 score | |
| 模型预测的噪声 | |
| 当前噪声标准差 | |
| 噪声的反方向,也就是去噪方向 |
这就是为什么很多看起来只是“回归噪声”的训练,其实也可以理解成在学习 score field。
Score Matching:直接学这个方向场
score matching 的目标是让模型输出的方向接近真实 score:
这行式子在说:模型 要学会在每个噪声水平下估计真实分布的概率梯度方向。
难点是:真实图像分布 很复杂,我们通常不知道它的解析形式,也就不能直接算 。扩散训练的妙处在于,通过人为加高斯噪声,可以把这个难题转成可监督的噪声预测问题。
所以可以这样记:
1 | 预测噪声:更容易训练 |
连续时间 SDE:把很多小步写成一条方程
如果把离散时间步变得非常密,就可以用随机微分方程 SDE 描述前向加噪:
这行式子在说:样本 随时间变化,一部分来自确定性漂移 ,另一部分来自随机噪声 。
符号含义:
| 符号 | 含义 |
|---|---|
| 样本状态的微小变化 | |
| 确定性漂移项 | |
| 很小的时间增量 | |
| 噪声强度函数 | |
| Wiener process 的微小随机扰动,可先理解成连续时间里的高斯噪声 | |
| SDE | Stochastic Differential Equation,随机微分方程 |
初学时不必害怕这行式子。它只是把“每一步加一点噪声”的离散过程,写成连续时间版本。
反向 SDE:知道 score 才能从噪声回来
Score SDE 论文给出的反向过程可以写成:
这行式子在说:反向生成不仅需要原来的漂移项和随机项,还需要 score 。score 告诉系统如何从噪声分布往数据分布走。
符号含义:
| 符号 | 含义 |
|---|---|
| 当前噪声水平下的真实 score | |
| 由 score 决定的反向修正方向 | |
| 反向时间里的随机噪声项 | |
| reverse-time SDE | 从噪声回到数据的随机微分方程 |
现实中真实 score 不知道,所以用模型 替代它:
这行式子在说:只要模型学到了足够好的 score,反向 SDE 就能被近似求解。
Probability Flow ODE:去掉随机项的确定路径
同一个 SDE 还对应一条确定性的 probability flow ODE:
这行式子在说:如果不再额外注入随机噪声,样本可以沿一条确定性轨迹从噪声流向数据。给定同一个初始噪声,ODE 轨迹是可重复的。
符号含义:
| 符号 | 含义 |
|---|---|
| ODE | Ordinary Differential Equation,常微分方程 |
| 样本随时间变化的速度 | |
| 由 score 导出的确定性去噪方向 |
DDIM、Euler、Heun、DPM-Solver 等很多采样器,都可以放进“如何数值求解这条 ODE / SDE”的框架里理解。
DDPM、DDIM 在这条线上的位置
DDPM
DDPM 更接近离散反向马尔可夫链,每一步通常保留随机性。它理论自然、生成质量好,但原始设置下采样步数多。
DDIM
DDIM 改变采样路径,在不重新训练模型的前提下使用更确定的、可跳步的生成过程。它可以理解成从随机链走向 ODE 视角的重要桥梁。
高阶求解器
如果采样是数值求解 ODE / SDE,那么 Euler、Heun、DPM-Solver 的区别就在于:同样调用模型若干次,谁能更准确地沿着 score field 移动。
一个直观比喻
想象你在浓雾里找城市中心:
- 噪声样本像你在雾里的随机位置;
- score 像一个局部指南针,告诉你哪个方向更像城市中心;
- SDE 像你走路时还会被随机风吹;
- ODE 像你只按指南针指向稳定前进;
- 采样器像你的走路策略:小步慢走、跳步快走、先预测再校正,都会影响是否走偏。
和下一页的关系
这一页解释了“模型输出为什么可以看成方向场”。下一页 条件控制与 Guidance 会继续问:如果用户给了文本、类别或参考图条件,这个方向场如何被条件改变?Guidance scale 为什么会让图像更贴 prompt,也可能让采样变不稳定?
DPM-Solver、Consistency Models、Rectified Flow 和 Flow Matching 都在不同程度上利用了“生成是沿向量场积分”这个视角。初学时先把 score、SDE、ODE 的角色分清,再去看少步蒸馏和路径整流会顺很多。
本页结论
score 是扩散模型的数学骨架:它把“预测噪声”解释成“学习概率分布的梯度方向”。SDE / ODE 视角则把反向生成解释成沿这个方向场做数值求解。理解这一页,就能看懂为什么采样器不是玄学名字,而是在解一条由模型定义的生成轨迹。
- 回到本专题入口:扩散模型,确认这页在整条路线中的位置。
- 按导航顺序继续:条件控制与 Guidance。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 扩散模型:Score Matching 到 SDE
- Author: Charles
- Created at : 2025-05-16 09:00:00
- Updated at : 2025-05-16 09:00:00
- Link: https://charles2530.github.io/2025/05/16/ai-files-diffusion-score-matching-sde-and-probability-flow/
- License: This work is licensed under CC BY-NC-SA 4.0.