
具身智能:相机、深度与机器人视觉
这一页补一个很基础但很关键的直觉:机器人看到的“图像”并不天然等于 3D 世界。不同相机给机器人的信息不同,能不能估计距离、能不能恢复物体尺寸、能不能抓取,取决于传感器和标定。
这页先回答“相机、深度与机器人视觉”在「具身智能」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先知道 VLA、世界模型、相机/深度和评测集的基本角色。 必要时先回 具身智能入口、基础知识 或 术语表。
主线关系:把感知、数据、仿真、策略、控制、安全和真实闭环连起来,看机器人系统为什么不能只靠离线指标判断。
先记住一句话:
1 | 单目相机主要给 2D 图像;双目/RGB-D 才更直接给 3D 距离。 |
这不是说单目完全不能估深度,而是说单张单目图像本身没有可靠的绝对尺度。它需要额外假设、运动、多帧、已知物体尺寸或学习到的先验。
硬证据模块:几何页必须能回放标定和失败
机器人视觉页如果只讲相机类型,会缺少工程可信度。对 VLA/world model 来说,几何证据必须能追到 episode:相机时间戳、内参、外参、深度质量、动作坐标系和失败 replay 是否对齐。
| 证据项 | 最小可复算例子 | 失败案例 | 验收指标 |
|---|---|---|---|
| 本页解决哪项成本 | 用标定/深度减少盲目真实试错和失败排查成本 | 数据很多,但相机外参漂移导致抓取点错 | reprojection error、pose error |
| 多相机对齐 | 同一时刻 wrist/front/overhead 的 timestamp skew 和外参版本 | 手臂挡住目标后,全局视角和腕部视角冲突 | max skew、calibration version、view agreement |
| 深度可信度 | RGB-D / stereo / monocular depth 分桶比较 | 透明杯深度错,risk head 低估碰撞 | depth error、contact boundary F1 |
| 动作坐标系 | action chunk 明确写 base/ee/camera frame | 坐标系混用,world model 误学动作后果 | action-frame consistency、controller reject |
| failure replay | 保存原图、深度、点云、标定、动作和结果 | 只有视频,无法判断是感知错还是动作错 | replay completeness、root-cause label |
一个几何 hard case 应能回答:模型选错动作,是因为视觉 tokenizer 丢了目标,深度估计错了距离,外参错了坐标,还是控制器没有执行到位。没有这条证据链,多相机数据越多,越可能只是把噪声喂给世界模型。
相机在机器人上大概长什么样
机器人上常见相机不是一种形态,而是几类安装方式:

图源:A Simple Robotic Eye-In-Hand Camera Positioning and Alignment Control Method Based on Parallelogram Features,Figure 3。图中相机安装在机械臂末端附近,典型对应 eye-in-hand / wrist camera;外部固定相机则通常放在工作站上方或侧面,用来提供全局视角。
| 安装方式 | 长什么样 | 适合做什么 | 局限 |
|---|---|---|---|
| 固定外部相机 / eye-to-hand | 一台相机固定在桌面上方、侧面或工作站支架上 | 看全局桌面、记录轨迹、做俯视定位 | 被手臂或物体遮挡后看不到局部接触 |
| 腕部相机 / eye-in-hand | 小相机装在夹爪或手腕附近,跟着机械臂一起动 | 近距离对准、插入、抓取前校正 | 视野小,运动时画面变化大 |
| 移动机器人前置相机 | 机身前面一排镜头,常是双目或 RGB-D | 导航、避障、找物、房间级感知 | 看不到背后,近距离抓取还要配合腕部或外部相机 |
实际设备外观上,你可以先这样识别:
单目 RGB:一个镜头,像普通 USB 摄像头或手机单摄。双目 stereo:两个左右分开的镜头,像两只眼睛,中间距离叫 baseline。RGB-D / depth camera:通常有 RGB 镜头、红外发射器、红外接收器,正面会看到多个圆形窗口。多相机 rig:多个相机固定在不同位置,不一定每个都能测深度,但如果都标定好,可以联合定位。
单目为什么不能直接成立体
单目相机只有一个视角。它把 3D 世界投影到 2D 图像上,投影时会丢掉深度。

网页图源:Wikimedia Commons: Pinhole camera model technical version - no annotation.svg。针孔模型的关键直觉是:3D 点经过相机光心投影到 2D 成像平面,深度在投影过程中被压缩到尺度变化里,所以单张单目图像天然存在绝对尺度歧义。
同一张图里,一个物体看起来大,可能有两种原因:
- 它真的很大;
- 它其实不大,只是离相机很近。
从一张单目图像本身,无法严格区分这两种情况。数学上可以理解为:3D 点沿着相机射线投影到同一个像素,深度 不同,但像素坐标可能一样。
这就是为什么单目有“尺度歧义”:
1 | near small object -> image looks big |
单目仍然很有用,但它通常适合回答:
- 这是什么物体?
- 物体大概在图像左边还是右边?
- 是否有文字、颜色、类别、语义关系?
- 根据经验估计相对远近。
它不适合单独回答:
- 这个杯口直径是不是 4cm?
- 夹爪离物体还有 2cm 还是 8cm?
- 物体精确 6D pose 是多少?
单目深度网络可以从大量数据中学到“地面、桌面、物体大小、透视关系”等先验,所以能估一个看起来合理的深度图。但它不是几何测量:换一个新场景、新相机、新尺度物体时,绝对深度可能偏。机器人抓取和插入任务通常不能只依赖单目估计。
Depth Anything 和 Depth Anything V2 这类模型的价值在于把单目相对深度的开放域鲁棒性和细节显著拉高,尤其对复杂场景、薄结构、透明/反光物体更有帮助。但基础模型仍输出相对深度,不等价于厘米级测距;需要绝对尺度时,还要接 metric fine-tuning、标定、多视角或 RGB-D。
双目为什么能估计深度
双目相机有两个相机,左右之间有固定距离 ,这个距离叫 baseline。两个相机从不同位置看同一个点,这个点在左右图像里的像素位置会不同,差值叫 disparity。
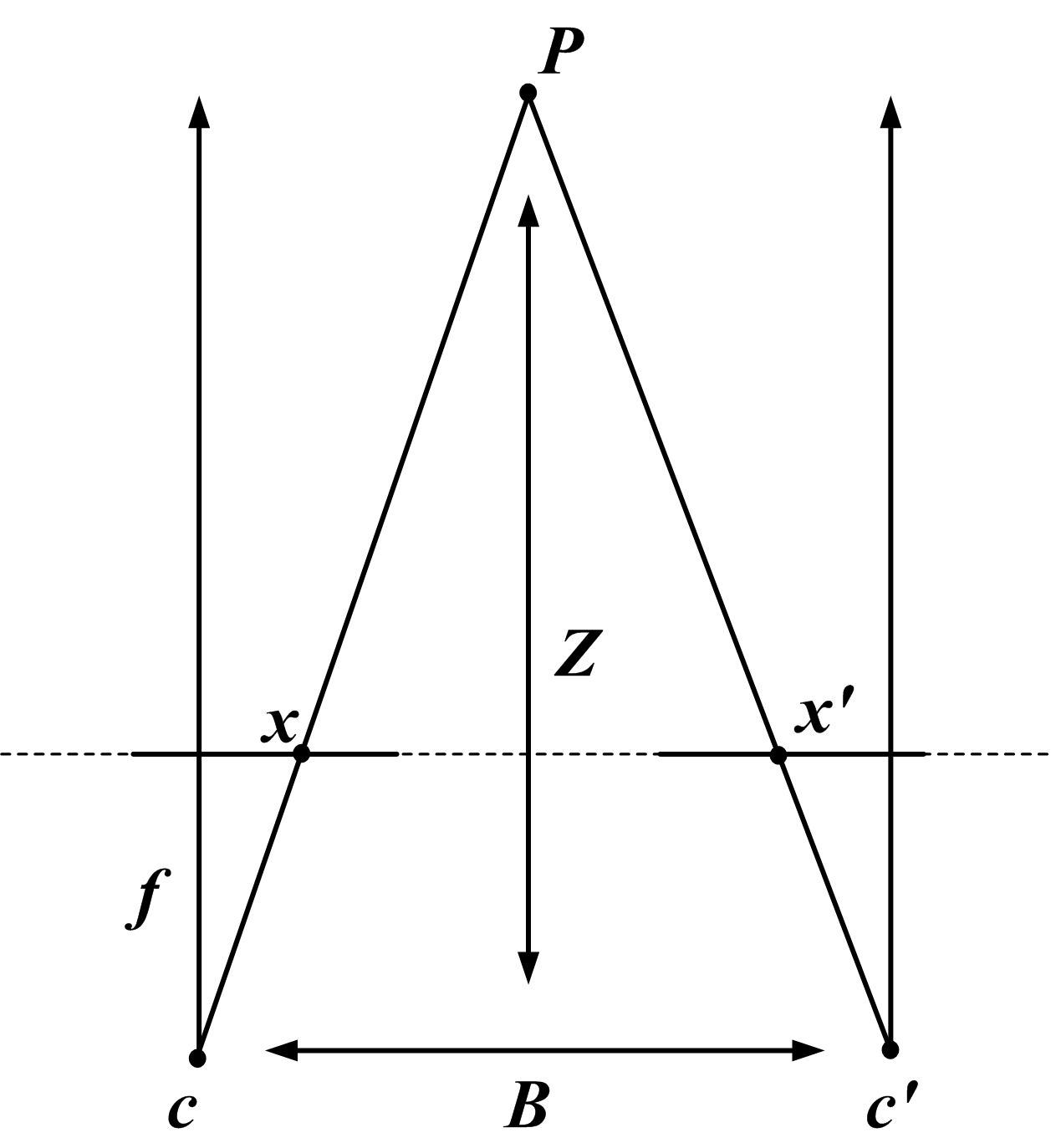
网页图源:Wikimedia Commons: Stereo-camera-model.jpg。双目相机的深度来自两个相机之间的 baseline 和左右图像的 disparity;同一个 3D 点在左右图上的像素偏移越大,通常表示它离相机越近。
双目深度的直觉公式是:
其中:
- :点到相机的深度;
- :相机焦距;
- :左右相机距离,也就是 baseline;
- :左右图像中同一个点的像素位移,也叫 disparity。
直觉上:
- 物体越近,左右眼看到的位置差越大, 大, 小;
- 物体越远,左右眼看到的位置差越小, 小, 大。
所以双目能成立体,是因为它有两个视角,可以用三角测量恢复深度。
但双目也不是万能的:
| 问题 | 为什么 |
|---|---|
| 低纹理表面难 | 左右图找不到稳定匹配点,比如纯白墙、纯色杯子 |
| 透明/反光物体难 | 玻璃和金属会让左右图对应关系混乱 |
| 远距离误差大 | 远处 disparity 很小,几个像素误差就会放大成很大深度误差 |
| 需要标定 | 两个相机的相对位置、焦距、畸变必须知道 |
RGB-D 相机为什么能直接给深度
RGB-D 相机输出两张对齐图:
1 | RGB image: 每个像素是什么颜色 |

网页图源:Wikimedia Commons: Intel Realsense depth camera D435.jpg。RealSense D435 这类 RGB-D / depth camera 会同时提供彩色图像和深度相关传感数据;在机器人里,它常用来把像素反投影成点云,再接抓取、避障和 6D pose 估计。
常见 RGB-D 相机有两类主动深度原理:
| 类型 | 直觉 | 典型特点 |
|---|---|---|
| Structured light | 投射红外花纹,看花纹变形来算深度 | 近距离室内常见,强光或反光可能影响 |
| Time-of-flight / ToF | 发出红外光,测光返回时间或相位 | 结构紧凑,深度噪声和多径反射需要处理 |
也有一些 RGB-D 设备内部其实用的是主动双目:既有左右红外相机,也有红外投射器,用来给低纹理表面增加可匹配纹理。
RGB-D 对机器人很有用,因为它能把像素变成 3D 点。给定像素 、深度 、相机内参 ,可以反投影成相机坐标系下的 3D 点:
这就是点云的来源。点云不是另一种神秘数据,本质上就是“每个深度像素反投影出来的 3D 点集合”。
深度图、点云和 6D pose 的关系
| 名词 | 是什么 | 机器人怎么用 |
|---|---|---|
| RGB 图 | 每个像素的颜色 | 识别类别、纹理、文字、语义 |
| 深度图 | 每个像素的距离 | 判断物体远近、避障、抓取前校正 |
| 点云 | 深度图反投影后的 3D 点集合 | 估计物体形状、桌面平面、碰撞体 |
| 6D pose | 物体的 3D 位置 + 3D 朝向 | 生成抓取点、放置点、规划轨迹 |
机器人抓取时常见链路是:
1 | RGB/RGB-D image |
如果只有 RGB,没有深度,也可以用模型估计 6D pose,但通常更依赖训练数据和物体 CAD 模型。对尺寸任务、插入任务、精细抓取来说,真实深度或多视角几何会稳很多。
内参、外参和标定:把像素接回真实空间
相机能不能用于机器人,关键不只是有没有图,还要知道图和真实世界怎么对应。入门时可以先理解世界坐标系、相机坐标系、图像坐标系、像素坐标系,再理解内参和外参。这里把这条线补成具身智能里更实用的版本。

网页图源:Wikimedia Commons: Chessboard calibration setup.png。标定的核心是用已知尺寸的棋盘格、Charuco 或 AprilTag 等几何目标,把真实 3D 点和图像 2D 点配对;OpenCV 的 camera calibration 文档也把内参、外参和畸变放在同一套投影模型里解释。
棋盘格角点提供已知 3D 几何,图像中的角点提供 2D 像素坐标。标定就是让 投影出来的像素尽量对齐真实角点。内参 说明相机自己怎么成像,外参 说明相机相对世界或机器人 base 在哪里。
6.1 四个坐标系:先分清点在哪里
| 坐标系 | 原点在哪里 | 单位 | 在机器人里对应什么 |
|---|---|---|---|
| 世界坐标系 / world frame | 任务场景或机器人基座定义的参考点 | 米 | 桌面、工件、机器人 base、地图原点 |
| 相机坐标系 / camera frame | 相机光心 | 米 | 相机自己看到的 3D 空间,通常 指向前方 |
| 图像坐标系 / image plane | 成像平面中心或光轴交点附近 | 毫米或归一化坐标 | 透视投影后的连续 2D 坐标 |
| 像素坐标系 / pixel frame | 图像左上角 | 像素 | 图像数组里的 ,检测框和 mask 都在这里 |
具身系统里最常见的 bug,就是把这四个坐标系混在一起:检测模型输出的是像素坐标,深度反投影得到的是相机坐标,planner 需要的是机器人 base 或 world 坐标,success checker 可能又在仿真 world frame 里判断。
6.2 内参 K:相机自己怎么成像
内参描述的是相机自身的成像几何,和相机摆在哪里无关。最常见的 pinhole camera 内参矩阵是:
其中:
| 参数 | 含义 | 直觉 |
|---|---|---|
| 以像素为单位的焦距 | 焦距越大,同样大小的物体在图像里越大 | |
| 主点 / principal point | 光轴落在图像上的位置,通常接近图像中心 | |
| skew / 轴倾斜 | 大多数现代相机近似为 0 | |
| distortion | 畸变系数 | 镜头让直线弯曲,常见径向畸变和切向畸变 |
一个容易漏掉的细节:如果图像被 resize, 要按同样比例缩放;畸变系数通常不随分辨率直接缩放。这个细节在 VLA 数据预处理里很重要,否则同一台相机在不同分辨率下会变成两套不一致的几何。
6.3 外参 [R|t]:相机在哪里看
外参描述的是世界坐标系和相机坐标系之间的刚体变换:
齐次坐标写法是:
这里要特别小心两个方向:
| 名称 | 作用 | 机器人里常见叫法 |
|---|---|---|
w2c / world-to-camera |
把世界点变到相机坐标 | OpenCV 的很多投影公式使用这个方向 |
c2w / camera-to-world |
把相机点变到世界坐标 | 常被叫作 camera pose,也就是相机在世界里的位姿 |
两者互为逆矩阵。很多 3D 重建、NeRF、仿真器和机器人库对 pose 的方向约定不同,所以看到 camera_pose、extrinsic、T_wc、T_cw 时,第一件事不是写代码,而是确认它到底是 world -> camera 还是 camera -> world。
6.4 从世界点到像素点:一条公式串起来
OpenCV 文档里的 pinhole camera model 可以写成:
拆开看就是:
1 | world point Pw |
反过来,如果你有 RGB-D 图像,就可以用像素和深度反投影:
再用 c2w 或 T_base_camera 把点变到 world / robot base frame。机器人抓取、避障、焊缝观察和尺寸比较,本质上都在反复做这件事。
6.5 标定到底在求什么
相机标定就是用已知几何的标定物,把“真实 3D 点”和“图像 2D 点”对应起来,估计内参、畸变和每张图里的外参。常见流程是:
- 准备棋盘格或 AprilTag / Charuco 这类已知尺寸的标定板;
- 从不同位置、角度、距离拍多张图;
- 检测角点或 tag 角点,得到 2D image points;
- 根据格子尺寸生成对应的 3D object points;
- 用
calibrateCamera估计 、畸变和每张图的 ; - 用重投影误差检查标定质量;
- 对真实机器人,再做手眼标定,把 camera frame 接到 gripper / robot base frame。
OpenCV 的 calibrateCamera 会从多个标定板视角估计内外参;如果内参已知,只想求某个物体或标定板相对相机的位姿,通常用 solvePnP。这两个函数在具身系统里非常常用:前者回答“这台相机怎么成像”,后者回答“这个已知几何物体现在相对相机在哪里”。
6.6 到底需要几个外参
先给一个最容易记的答案:
1 | 内参:通常每台相机一套 K。 |
更精确地说,外参不是“越多越高级”,而是看你要把哪些坐标系接起来。如果只有一台固定相机,想把相机点变到机器人 base,就需要一条 。如果有 台相机想融合到同一个 world / base frame,通常需要 个相机到同一参考系的外参。任意两台相机之间的相对外参可以由这两个外参相减出来。
| 场景 | 需要的外参数量 | 能做什么 | 不能自动做什么 |
|---|---|---|---|
| 单目 RGB,只有内参 | 0 或 1 个相机到 world/base 的外参 | 把已知深度的点投影/反投影;如果有外参,可把相机观测放进机器人坐标系 | 单张 RGB 本身仍没有绝对深度 |
| 单台 RGB-D 固定相机 | 1 个 | 把 depth 反投影成相机点云,再变到机器人 base,用于抓取、避障、测距 | 看不到遮挡背面;深度噪声仍要处理 |
| 双目相机 | 左右相机各自内参 + 左右相机相对外参,常写作 | 用 baseline 和 disparity 三角测量深度 | 如果没有接到 robot base,只知道相机内部深度,不知道机器人该往哪动 |
| 双目 / RGB-D 装在机器人上 | stereo/RGB-D 内部标定 + 1 个 或 | 既能算深度,又能把 3D 点转到机器人可执行坐标系 | 还需要时间同步和手眼标定质量 |
| 多个固定相机 | 个相机到同一 world/base 的外参 | 多视角融合、减少遮挡、轨迹记录、重建场景 | 每台相机时间不同步或标定漂移会导致点云重影 |
| 移动相机视频 / SLAM | 每一帧一个 camera pose,或关键帧 pose | 用多帧做 SfM/SLAM、重建轨迹和地图 | 单目视频如果没有尺度来源,metric scale 可能仍漂 |
| 腕部相机 eye-in-hand | 固定的 ,再乘每时刻机器人 forward kinematics | 末端动到哪里,相机 pose 就能算到哪里,适合视觉伺服和近距离校正 | 只标定一次不代表永远准确,碰撞、松动会让外参变 |
这几个例子可以压缩成三条判断:
- 只做投影到图像:通常要 和
w2c,把世界点画到像素上。 - 从像素回到 3D:要 加深度;如果还要给机器人执行,再要
c2w/ 。 - 多视角融合:每个视角都要知道自己到同一参考系的 pose,否则点云会各在各的坐标系里,拼不起来。
固定 RGB-D 相机看到杯子中心在像素 ,depth 是 0.62m。用内参 可以把它反投影成相机坐标 。但机械臂不能直接执行“到相机坐标前方 0.62m”,它需要 base 坐标。因此还要 ,把 变成 。这就是为什么只知道内参不够,外参把“相机看见了”变成“机器人知道怎么动”。
6.7 Eye-to-hand、eye-in-hand 和手眼标定
机器人里外参还要分安装方式:
| 安装方式 | 要求的关键变换 | 用来做什么 |
|---|---|---|
| eye-to-hand 固定外部相机 | 或 | 把相机看到的物体位置变到机器人 base frame |
| eye-in-hand 腕部相机 | 末端移动时,相机跟着末端一起动,用于近距离对准 | |
| 多相机 rig | 每台相机到 rig / world / base 的外参 | 多视角融合、遮挡补全、轨迹记录 |
如果是腕部相机,只知道相机内参还不够。你还要知道相机相对夹爪的固定变换,否则相机看到目标在前方 5cm,夹爪并不知道该怎么把这 5cm 转成自己的运动。
6.8 具身数据里建议保存哪些字段
| 字段 | 建议含义 | 为什么要存 |
|---|---|---|
camera_intrinsic / K |
内参矩阵 | 深度反投影、3D 重建、投影可视化 |
distortion_coeffs |
径向/切向畸变参数 | 去畸变、真实相机迁移 |
T_world_camera 或 T_camera_world |
明确方向的相机位姿 | 多视图融合、从像素回到世界 |
T_base_camera |
相机到机器人 base 的变换 | 抓取和轨迹规划 |
T_gripper_camera |
腕部相机到夹爪的变换 | eye-in-hand 视觉伺服 |
timestamp |
图像、深度、关节状态的时间戳 | 移动中不同步会造成空间错位 |
image_size |
图像宽高 | resize 后检查内参是否同步缩放 |
命名上建议避免只写 extrinsic。更好的名字是 T_world_camera、T_camera_world、T_base_camera 这种带方向的名字;如果必须用 extrinsic,就在 schema 里明确它是 w2c 还是 c2w。
仿真里相机参数可以完美知道,但如果你未来要迁移到真实机器人,就要尽量让仿真相机的焦距、视角、分辨率、安装位置和真实设备接近。否则模型可能在仿真里学会了错误的视觉几何。更实际一点:仿真数据里也要保存 K、外参方向、分辨率和相机 frame,否则训练 VLA / 世界模型时很难复现观测。
第一,把 w2c 当成 c2w 用,投影结果会整体飞掉。第二,resize 图像后忘了缩放 ,点云会变形。第三,只看平均重投影误差,不检查边缘、远近距离和机器人工作区内的误差,部署时抓取会偏。
6.9 一个 DA3 多视角 demo 怎么接到几何管线
Depth Anything 3 的 GitHub demo 可以作为这一节的实操例子。比如:
1 | da3 auto assets/examples/SOH \ |
这里 assets/examples/SOH/000.png 和 assets/examples/SOH/010.png 会被当作同一个场景的两个 view,而不是两张互不相关的 batch 图片。DA3 会输出每个 view 的深度、置信度、内参和外参,并把它们融合成一个可查看的 3D 场景:
| 输出 | 在具身管线里的意义 |
|---|---|
scene.glb |
点云和相机的可视化结果,用来肉眼检查几何是否拼对 |
depth_vis/*.jpg |
深度可视化,用来快速看近远关系、边缘、遮挡和低置信区域 |
exports/mini_npz/results.npz |
真正给程序读取的数值结果,包含 depth、conf、extrinsics、intrinsics |
这个例子尤其适合帮助你把几个概念连起来:depth 可以反投影成相机坐标点,intrinsics 决定像素怎么回到相机射线,extrinsics 决定多个 view 怎么放进同一个 world frame,conf 则可以在融合点云时过滤不可靠像素。
但工程上要特别注意两件事。第一,这次导出的 extrinsics 是 world-to-camera,如果下游要的是 camera-to-world 或 ,就要先确认方向并求逆。第二,原图是 1208x680,推理处理后是 336x196,所以 intrinsics 对应的是处理后图像;如果你拿原图像素去反投影,必须同步处理坐标和内参。
对具身智能来说,这类 demo 的价值不是直接得到动作,而是把 RGB 观测转成可检查的几何中间层。后面可以接点云融合、可见性检查、抓取候选生成、世界模型数据质检,或者把真实采集轨迹变成仿真里更容易复现的几何资产。
不同相机在具身任务里的选择
| 任务 | 更常用的传感器 | 原因 |
|---|---|---|
| 桌面抓取 | RGB-D、双目、固定俯视相机 + 腕部相机 | 需要物体位置、深度、抓取前近距离校正 |
| 尺寸比较 | RGB-D、标定双目、多视角 | 需要可靠尺度,单目容易有尺度歧义 |
| 移动导航 | 前置双目、RGB-D、LiDAR、鱼眼相机 | 需要避障和房间级空间感知 |
| 精细插入 | 腕部相机、力觉、近距离 RGB-D | 末端附近微小误差很关键 |
| 数据采集 / 轨迹记录 | 多固定相机 + wrist camera | 方便回放、重建、标注失败原因 |
早期做仿真任务时,可以先从固定 RGB-D 或多视角相机开始,因为它更容易 debug。等任务跑通后,再减少 privileged state 或改成更接近真实部署的相机配置。
单目、双目、RGB-D 在数据管线里怎么对应
资产生成流程:
1 | RGB 图像 -> 背景消除 -> 文字消除 -> 多视角生成 -> 图生 3D |
这是离线资产生产。这里的多视角更多是为了让 3D 生成模型补全形状和纹理,不等价于真实双目测距。
仿真/轨迹生成流程:
1 | 导入资产 -> 场景布置 -> 相机渲染 -> 估计状态或直接读取状态 |
这里的相机可以分两种使用方式:
| 用法 | 数据来源 | 用途 |
|---|---|---|
| privileged state | 仿真直接读取物体 pose、尺寸、速度 | 生成 GT、写 success checker、debug |
| visual observation | 从仿真相机渲染 RGB/RGB-D | 训练 VLA/WAM,让模型从图像推断状态 |
早期建议两者都保存。训练时可以只给模型图像和机器人状态;debug 和判定时用 privileged state。这样模型学的是视觉到动作,工程上仍能解释失败原因。
常见误区
| 误区 | 更准确的说法 |
|---|---|
| 单目完全不能估深度 | 单目可以用先验估相对深度,但单张图没有可靠绝对尺度 |
| 双目一定比 RGB-D 好 | 双目依赖纹理和匹配,RGB-D 依赖主动深度,各有失败场景 |
| 多视图生成就是双目 | 多视图生成是资产生产或补视角,不是已标定双相机的几何测量 |
| 点云比图像高级 | 点云只是另一种表示,语义弱;图像语义强但几何弱 |
| 有深度就能抓 | 还需要分割、pose、抓取候选、碰撞检测、控制和 success checker |
| 仿真里相机随便放 | 相机位置会强烈影响模型学到的策略和真实迁移能力 |
参考资料
- OpenCV: Camera Calibration and 3D Reconstruction:pinhole camera model、内参矩阵、外参矩阵、畸变和标定函数说明。
- OpenCV: Camera Calibration:径向/切向畸变、棋盘格标定、去畸变的入门教程。
- CSDN:相机标定–内参、外参:四个坐标系、内参/外参、棋盘格标定和重投影误差的中文入门脉络。
和其他具身页面的连接
| 继续读 | 你会补上什么 |
|---|---|
| 资产到轨迹:感知、抓取与数据管线 | 相机输出如何进入资产、状态估计、抓取和轨迹生成 |
| 一个任务跑通具身闭环 | 深度和 pose 如何支撑尺寸排序、容器匹配和 success checker |
| 规划、控制与安全 | 感知到的 3D 状态如何变成可执行轨迹和安全约束 |
| VLA、WAM 与世界模型地图 | 相机观测如何进入 VLA、WAM 和世界模型路线 |
- 回到本专题入口:具身智能,确认这页在整条路线中的位置。
- 按导航顺序继续:Isaac Sim / RoboTwin。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 具身智能:相机、深度与机器人视觉
- Author: Charles
- Created at : 2025-05-25 09:00:00
- Updated at : 2025-05-25 09:00:00
- Link: https://charles2530.github.io/2025/05/25/ai-files-embodied-ai-cameras-depth-and-robot-vision/
- License: This work is licensed under CC BY-NC-SA 4.0.