
具身智能:一个任务跑通具身闭环
这一页用一个具体任务把具身智能串起来。前面的页面讲了系统地图、资产、轨迹、VLA、WAM 和世界模型,但真正理解它们,最好从一条任务链路开始。
我们用两个任务作为主例子:
按从小到大的顺序从左向右排序将圆柱体放入罐口尺寸接近的罐子
这两个任务很好,因为它们不只是普通 pick-and-place,还会考察尺寸感知、相对比较、空间规划、抓取、放置、任务判定和失败恢复。

图源:π0.5,Figure 2。原论文图意:展示机器人在未见过的新厨房中执行多个清理子任务,例如关柜门、把物品放入抽屉、擦拭液体和把餐具放入水槽。
这张图里的每个小任务都可以拆成“看见、选择、抓取、移动、放置、判定”。长任务失败通常不是最后一步才发生,而是在任务绑定、对象选择、抓取姿态、轨迹规划或执行反馈中的某一环开始偏离。用具体任务走读时,要把每一阶段的输入、输出和 checker 都写清楚。
1. 同一个任务要被拆成六个问题
以“把圆柱体放入罐口尺寸接近的罐子”为例,系统必须连续回答:
| 问题 | 系统要知道什么 | 常见模块 |
|---|---|---|
| 看见什么 | 圆柱在哪里,几个罐子在哪里,罐口尺寸是多少 | RGB/RGB-D、多视角、检测、分割、pose estimation |
| 选哪个 | 哪个罐口和圆柱尺寸最匹配 | VLM/VLA、高层 planner、规则脚本 |
| 怎么抓 | 从哪里接近圆柱,夹爪朝向如何 | grasp annotation、grasp sampler、affordance |
| 怎么走 | 机械臂如何从当前位置移动到抓取点和放置点 | IK、cuRobo、STOMP、motion planner |
| 怎么执行 | 每个控制周期下发什么动作,碰撞和力是否安全 | controller、MPC、safety filter |
| 成功没有 | 圆柱是否在正确罐子里,夹爪是否打开,物体是否稳定 | success checker、termination script、task progress |
具身智能难,不是因为某个问题单独不可解,而是这些问题必须在一个闭环里连续成立。
2. 先定义任务状态,而不是先选模型
在写模型或轨迹生成前,先把任务状态定义清楚。一个最小状态可以写成:
1 | { |
这里有几个重点:
pose_w表示物体在 world frame 下的位置和朝向。size_m和opening_diameter_m是尺寸任务的关键状态。target_container可以先为空,由高层模块根据尺寸匹配算出来。grasp_candidates来自手动标注、自动抓取生成或离线筛选。
如果状态定义不清,后面用 VLA、WAM、planner 都会混乱。模型输出错了也很难判断错在哪里。
3. 离线数据生成怎么跑
离线生成专家轨迹时,比较稳的流程是:
1 | sample task |
在工具链上,这通常可以理解成:RoboTwin 风格代码负责 sample task / reset scene / success checker,Isaac Sim 或其他仿真器负责 simulate trajectory / render cameras / query states,cuRobo 或 STOMP 负责 run planner。更详细的分工见 Isaac Sim 与 RoboTwin 仿真数据链。
对应到代码结构可以是:
1 | def generate_episode(task, asset_pool, planner, simulator): |
这段逻辑说明一件事:专家轨迹不是直接“生成动作文件”就结束,而是必须经过仿真验证和成功判定。否则错误轨迹会进入训练集,后面模型会学到错误行为。
4. 在线执行怎么跑
在线执行时,系统不是一次性把完整任务做完,而是循环:
1 | observe |
可以写成:
1 | while not done: |
这和离线轨迹生成不同。离线可以用完整状态和 planner 慢慢算;在线必须处理传感器噪声、执行误差、物体滑动、人类干扰和实时延迟。
5. 三种路线会怎样解决同一个任务
经典 pipeline
1 | 检测圆柱和罐子 |
它的优点是可解释、容易 debug。缺点是每个接口都要手工定义,遇到开放语言和新物体时扩展比较慢。
π0.5 式 VLA
1 | 多视角图像 + 机器人状态 + 语言任务 |
π0.5 式路线会把任务分解和动作生成放进模型里。它更适合开放环境,但仍然需要 success checker、低层控制和安全过滤。否则模型动作看起来合理,也可能撞到物体或放错容器。
DreamZero 式 WAM
1 | 当前视觉上下文 + 语言 + 机器人状态 |
DreamZero 式路线会让动作和未来画面绑定。它的优势是模型被迫学习“动作会导致什么视觉变化”。风险是,如果未来视频预测错,动作也可能很一致地跟着错。所以它更需要风险检测、真实观测回写和安全层。
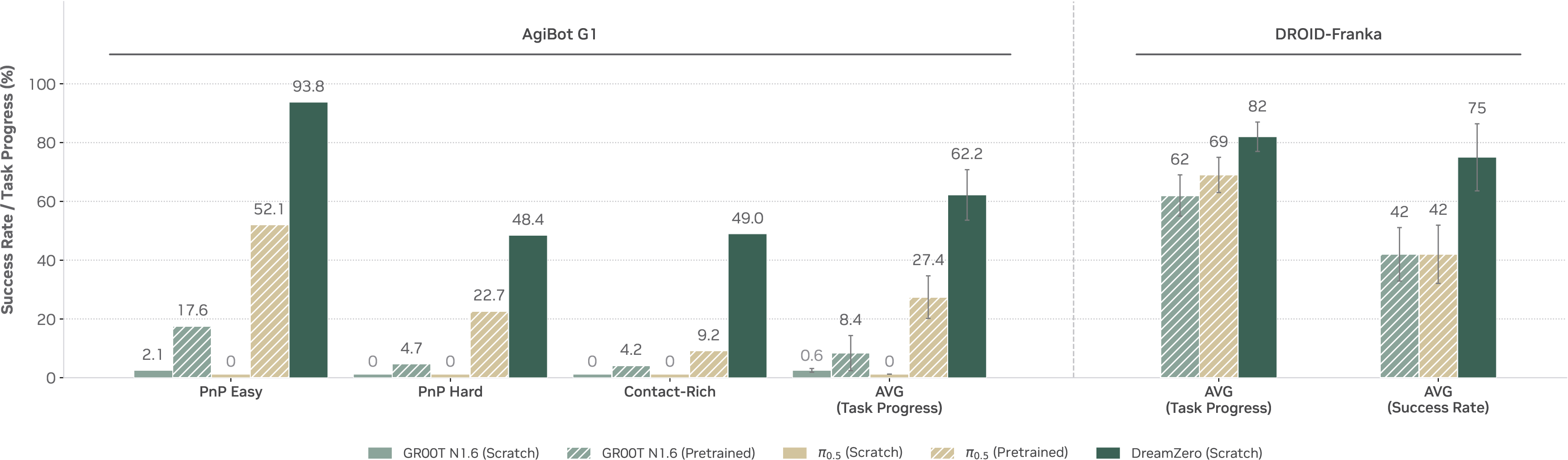
图源:DreamZero,Figure 8。原论文图意:展示 World-Action Model 在机器人任务上的执行与评测样例,用来观察未来视觉和动作输出是否能转化为真实任务进展。
WAM 的图不能只看“未来画面像不像”,还要看预测动作执行后真实观测是否朝同一方向变化。实际排查时,把模型预测的未来、下发动作、真实新观测和 success checker 结果并排看,最容易定位失败来自视频预测、动作接口还是执行控制。
6. 失败时应该先查哪一层
具身任务失败后,不要先说“模型不行”。更好的做法是按责任层排查:
| 失败现象 | 先查什么 | 可能原因 |
|---|---|---|
| 目标物体识别错 | 感知和数据 | 纹理太相似、遮挡、单目深度错误、标签/OCR 错 |
| 尺寸比较错 | 状态估计和任务绑定 | scale 错、深度错、尺寸字段缺失、规则阈值不合理 |
| 抓取点很奇怪 | grasp annotation | 抓取轴随机、候选没有任务语义、物体 origin 错 |
| 轨迹规划失败 | planner 和 collision mesh | IK 无解、障碍物太近、碰撞网格过粗或过碎 |
| 仿真执行掉落 | 物理属性和控制 | 摩擦/质量不合理、夹爪力不够、接触模型不稳 |
| 最后状态看似成功但判失败 | success checker | 阈值太严、坐标系不一致、夹爪状态读取错 |
| VLA 会做短动作但长任务崩 | 高层子任务和记忆 | 没有 task progress、没有状态跟踪、没有失败恢复 |
| WAM 生成视频合理但执行失败 | video-action alignment 和安全层 | 视觉未来缺少物理可执行性,动作没有被控制层约束 |
这张表是具身 debug 的核心。真实系统里大多数问题不是单一模型替换能解决的,而是某个接口没有定义或验证清楚。
7. success checker 应该比模型更早写
很多项目会先生成资产和轨迹,最后才写任务判定。这个顺序容易返工。更稳的顺序是先写 success checker 的草案,因为它定义了“什么叫成功”。
以“按从小到大排序”为例,success checker 至少要判断:
- 所有目标物体都在指定区域内;
- 按 方向从左到右排序;
- 尺寸顺序和空间顺序一致;
- 物体间距在目标范围内;
- 夹爪已打开;
- 物体稳定,没有继续滑动。
伪代码可以写成:
1 | def check_size_sort_success(objects, gripper_open, eps_order=0.01): |
这段代码不是最终实现,而是告诉你:任务定义要落到可查询状态和阈值上。否则模型、planner、数据集之间没有共同标准。
8. 训练数据应该保存哪些字段
一条 episode 至少建议保存:
| 字段 | 用途 |
|---|---|
instruction |
训练语言到动作或语言到子任务 |
camera_frames |
训练 VLA、WAM、视觉感知 |
depth_or_pose |
debug 感知和 planner,也可作为 privileged state |
robot_state |
关节角、夹爪、底盘、本体状态 |
actions |
行为克隆、WAM action latent、policy training |
subtasks |
π0.5 式 high-level supervision |
object_states |
success checker、状态估计、错误分析 |
success / task_progress |
过滤数据、训练 reward/judge、评测 |
failure_reason |
后续回流和 hard case mining |
asset_metadata |
追踪 scale、质量、材质、碰撞网格、抓取标注版本 |
如果未来想接 DreamZero 这类 WAM,尤其要保证视频、动作和机器人状态严格时间同步。WAM 学的是 video-action 对齐,时间戳漂移会直接破坏监督信号。
9. clean 到 random 的升级顺序
不要一开始就上复杂随机场景。更稳的升级顺序:
| 阶段 | 场景设置 | 目标 |
|---|---|---|
| clean-0 | 单物体、无干扰、固定相机 | 验证资产、scale、抓取、planner 和 success checker |
| clean-1 | 单物体、多初始位姿 | 验证 grasp 和 planner 是否泛化 |
| clean-2 | 同类多尺寸物体 | 验证尺寸比较和任务绑定 |
| random-1 | 加少量非目标干扰物 | 验证检测、避障和任务筛选 |
| random-2 | 加纹理、光照、位置随机化 | 验证视觉鲁棒性 |
| random-3 | 加失败复位、重试和 hard cases | 生成更接近训练/评测需要的数据 |
这样做可以保证每一步失败都能定位。如果一开始就 random,很容易出现“看起来哪里都错,但不知道先修什么”。
10. 和论文路线的关系
| 论文路线 | 这个 walkthrough 对应的位置 |
|---|---|
| π0.5 | 把高层子任务和低层 action chunk 串进在线闭环 |
| DreamZero | 把 episode 里的视频、动作和状态变成 WAM 训练信号 |
| LingBot-World | 把动作条件未来观测用于交互模拟和反事实数据 |
| Dreamer | 把状态、奖励和 continue 信号用于 latent imagination |
| RoboTwin | 提供任务组织、资产标注和仿真数据生成的参考 |
最终你应该能把任何具身论文放回这条链路:它到底在改感知、子任务、动作、世界预测、规划控制、数据生成,还是评测回流。
- Title: 具身智能:一个任务跑通具身闭环
- Author: Charles
- Created at : 2025-05-31 09:00:00
- Updated at : 2025-05-31 09:00:00
- Link: https://charles2530.github.io/2025/05/31/ai-files-embodied-ai-closed-loop-task-walkthrough/
- License: This work is licensed under CC BY-NC-SA 4.0.