
基础知识:数据划分与评测指标
模型训练不是只看 loss,模型能力也不是只看一个 benchmark 分数。要判断一个模型是否真的更好,必须把数据划分、指标选择、分桶评测和错误分析放在一起。
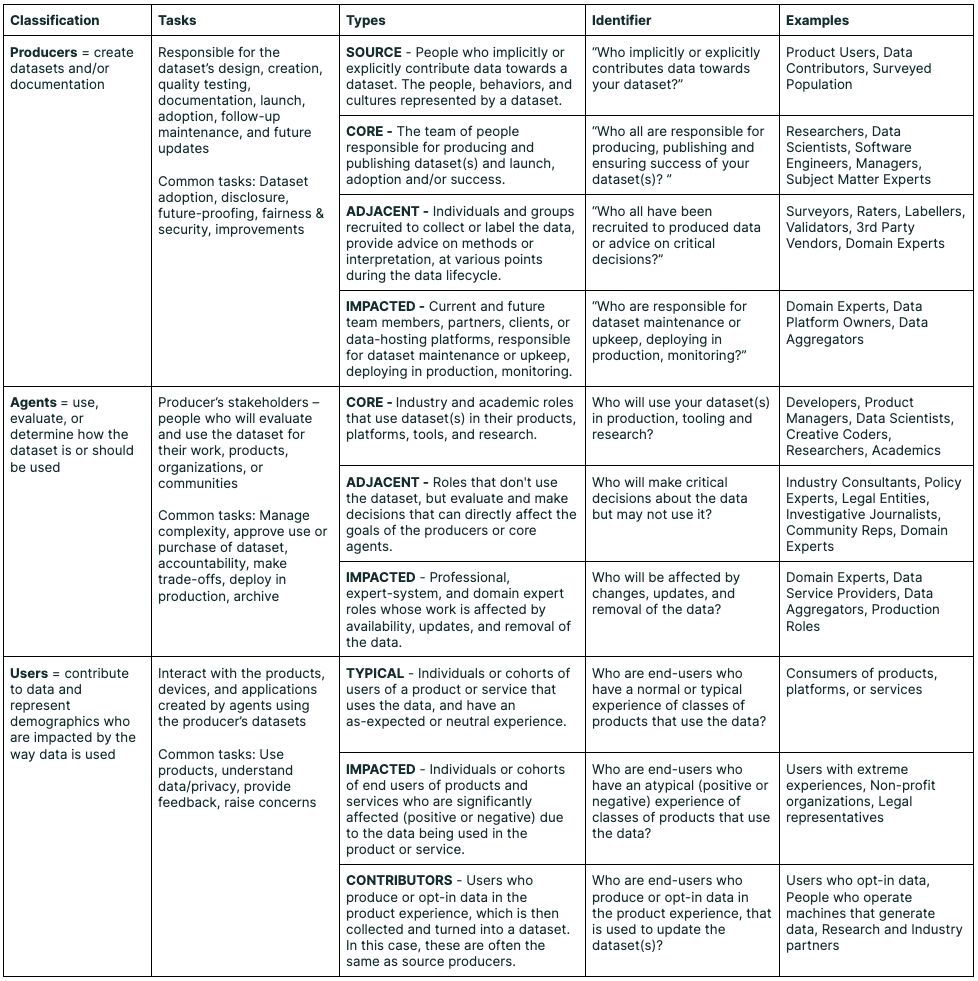
图源:Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI,Typology table。原论文图意:把 dataset 文档相关角色分为 producers、agents 和 users,并说明不同角色在数据创建、使用、评估和影响中的责任与问题。
这张表提醒你:数据和评测结论会被不同角色使用,也会影响不同人群。Train/validation/test 只是第一层划分;真正可信的评测还要说明数据由谁产生、谁会使用、谁会被影响、哪些样本代表真实风险。benchmark 是入口,不是结论。能支撑迭代的是固定样本、分桶指标、失败案例、上线回放和清楚的数据责任边界。
评测不是给模型打一个总分,而是判断模型在哪些场景可靠、在哪些场景危险。平均分只能说明整体趋势,分桶和失败样本才能指导下一步怎么改。看到 benchmark 提升时,先追问数据划分是否干净、提升集中在哪些桶、失败样本是否可回放。
1. Train / Validation / Test
最基本的数据划分是:
| 数据集 | 用途 | 不能做什么 |
|---|---|---|
| Train | 更新模型参数 | 不能用来证明泛化 |
| Validation | 调超参和选 checkpoint | 不能反复过拟合 |
| Test | 最终报告结果 | 不应参与调参 |
如果用 test 集反复调参,test 集就会被污染,分数会越来越像“适配测试集”,而不是代表真实泛化。
Validation set 本来用于调参,但反复围着同一批样本改 prompt、改数据、改超参,也会慢慢过拟合开发过程。更稳的做法是保留 holdout 或 shadow eval:平时少看它,只在关键节点检查改动是否真的泛化。
2. 指标必须匹配任务
不同任务需要不同指标:
| 任务 | 常见指标 | 注意点 |
|---|---|---|
| 分类 | accuracy、F1 | 类别不均衡时 accuracy 可能误导 |
| 检索 | Recall@K、nDCG、MRR | 要看召回池和排序阶段 |
| 生成 | BLEU、ROUGE、human eval | 自动指标很容易漏掉事实性 |
| VLM | OCR 准确率、定位、问答正确率 | 图表、文档、屏幕应分桶 |
| 推理系统 | TTFT、TPOT、QPS、P99 | 平均延迟不代表线上体验 |
指标不是越多越好,而是要能回答当前问题。
3. 为什么要分桶
平均分会掩盖局部失败。比如一个 VLM 在普通图片问答上很强,但在发票、表格和小字体 OCR 上很弱。如果只看总分,问题可能完全被盖住。
常见分桶方式:
- 按任务类型:问答、检索、代码、数学、OCR。
- 按输入长度:短文本、长文本、超长上下文。
- 按风险等级:普通样本、高价值样本、安全敏感样本。
- 按模态:文本、图像、视频、动作。
- 按失败类型:幻觉、格式错、召回漏、拒答错。
4. 错误分析比排行榜更重要
如果一个模型分数下降,只知道“下降了 2 分”没有太大价值。更重要的是知道:
- 哪些样本错了;
- 错误集中在哪些桶;
- 是数据问题、模型问题、提示问题还是系统问题;
- 能不能通过回放稳定复现;
- 下一轮该补数据、改目标还是改系统。
5. 一个评测闭环伪代码
1 | for checkpoint in candidate_checkpoints: |
这段伪代码强调:评测不只是打分,而是要能决定 checkpoint 是否进入下一阶段,并驱动数据和训练策略调整。
6. 和 benchmark 的关系
公开 benchmark 很有用,但不能替代自己的任务评测。
公开 benchmark 适合:
- 横向比较模型大致能力;
- 找到领域常用指标;
- 复现论文和系统能力边界;
- 发现明显短板。
自建评测更适合:
- 业务真实样本;
- 高价值长尾;
- 线上失败回放;
- 特定格式和工具协议;
- 安全与合规边界。
7. 和后续专题的关系
- 训练评测与消融:如何判断训练改动是否可信。
- 推理在线评测:如何把离线评测接到线上观测。
- 强化学习总览:reward、闭环评测和世界模型任务指标如何影响训练结论。
- 量化评测与部署清单:量化掉点如何验收。
小结
评测的核心不是“拿一个分数”,而是建立可复现、可分桶、可回放、能驱动下一步行动的证据链。没有这条证据链,模型改动很难长期可信。
- Title: 基础知识:数据划分与评测指标
- Author: Charles
- Created at : 2025-06-26 09:00:00
- Updated at : 2025-06-26 09:00:00
- Link: https://charles2530.github.io/2025/06/26/ai-files-foundations-data-splits-metrics-and-evaluation-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.