
基础知识:线性层到 GEMM
如果把现代大模型拆到最底层,会发现大量计算都在做矩阵乘。但这里要先分清三层概念:Linear 是模型层,MatMul 是数学/框架里的矩阵乘操作,GEMM 是底层线性代数库和 GPU kernel 常用的 dense matrix-matrix multiplication 形式。它们相关,但不是同一个词。
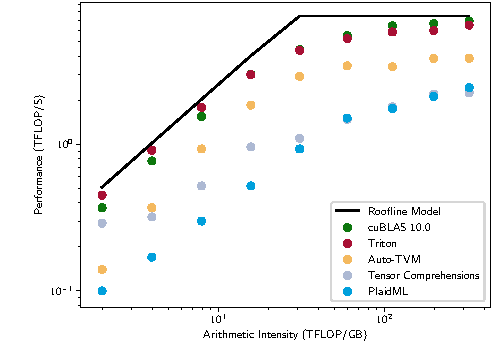
图源:Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations,Figure 1。原论文图意:在 矩阵乘上比较 cuBLAS、Triton、Auto-TVM、Tensor Comprehensions 和 PlaidML 相对 roofline model 的性能位置。
这张图选择矩阵乘作为性能比较对象,正好说明本页要分清的层级:Linear / MLP 是模型结构,MatMul 是数学或框架 API 里的矩阵乘操作,GEMM 是库和 kernel 层常见的高性能 dense matrix-matrix multiplication。Transformer 的 QKV 投影、attention 输出投影、MLP 升维和降维,数学上常写成 MatMul;工程上通常会 reshape 成二维矩阵并派发到 GEMM、batched GEMM 或 fused GEMM family。Triton 这类 DSL 的价值,就是让自定义矩阵类 kernel 在 tile、layout 和 memory access 上接近成熟库的性能区间。
Linear 层就是把一组数字重新加权组合成另一组数字。MLP 则是在“重新组合 -> 非线性变形 -> 再压回去”之间给每个 token 一个独立的变换空间。看到量化或 kernel 优化论文时,重点判断它优化的是权重矩阵、激活矩阵、layout、epilogue 还是底层矩阵乘 kernel。
0. 先分清 MatMul 和 GEMM
MatMul 更像数学操作或框架算子名:给定两个张量,按最后两个维度做矩阵乘,可能带 batch 维、broadcast、transpose 或不同 backend lowering。
GEMM 是 BLAS 语境里的 General Matrix-Matrix Multiplication,标准形式更接近:
其中 、、 是二维 dense matrices,、 是标量。深度学习里的 bias、activation、dequant、requant、residual 等,通常属于 GEMM kernel 的 epilogue fusion 或周边融合,不是 GEMM 这个数学定义本身。
二者关系可以这样记:
| 概念 | 所在层级 | 典型含义 |
|---|---|---|
Linear |
模型层 | ,把 hidden 表示投影到新维度 |
MatMul |
数学/API 层 | 两个矩阵或 batched tensors 相乘 |
GEMM |
库/kernel 层 | 高性能 dense 矩阵-矩阵乘,常见形式是 |
BMM / batched GEMM |
库/kernel 层 | 一批小矩阵乘,常见于 attention 的 QK/PV 路径 |
| fused GEMM | 工程实现层 | GEMM 主计算后融合 bias、activation、scale、quant/dequant 等 epilogue |
因此,不是所有 MatMul 都是 GEMM:向量乘、稀疏乘法、带复杂 broadcast 的高维张量乘、attention 的 fused kernel、某些 tiny shape 的专用 kernel,都可能不走普通 GEMM 路径。反过来,很多 Linear 层虽然代码里写的是 matmul,运行时会被 reshape、pack、dispatch 到 GEMM 或 fused GEMM kernel。
1. Linear 层在做什么
线性层最常见的形式是:
如果输入是:
权重是:
输出就是:
直觉上,Linear 层是在问:当前每个 token 的 维表示,应该被重新组合成什么新的 维表示。
上面的公式用的是教学里常见的 写法,所以 写成 。PyTorch 的 nn.Linear(in_features, out_features) 通常把权重存成 [out_features, in_features],前向等价于 。这只是存储布局和 API 约定不同,不改变 Linear、MatMul、GEMM 的层级关系。
2. 为什么 Transformer 到处都是 Linear
一个 Transformer block 里常见的 Linear 包括:
| 位置 | 作用 | 典型维度变化 |
|---|---|---|
| Q 投影 | 生成 query | |
| K 投影 | 生成 key | |
| V 投影 | 生成 value | |
| Attention 输出投影 | 合并多头结果 | |
| MLP 升维 | 扩张中间表达 | 或更大 |
| MLP 降维 | 压回 hidden size |
所以当你听到“优化 Transformer 性能”时,很多时候其实是在优化这些 Linear 对应的 MatMul/GEMM 执行路径,而不是在改 Linear 的数学定义。
3. MLP 为什么通常先升维再降维
Transformer 里的 MLP 常写成:
其中 把维度升高,激活函数 引入非线性, 再把维度压回去。
这像一个“临时扩展工作台”:
- 先把表示展开到更大的中间空间;
- 在中间空间里做非线性组合;
- 再把结果压回模型主干维度。
如果没有 MLP,Transformer 只有 attention 的信息混合能力,逐 token 的非线性变换会弱很多。
4. Linear 如何落到 GEMM
以一个 Linear 为例:
框架常把前两维合并:
再执行:
最后 reshape 回:
这个二维 dense matrix multiplication 很适合落到 GEMM。若 很小,例如 decode 阶段每次只来少量 token,它仍然可能走 GEMM family,但性能画像会变成小 、skinny GEMM、batched GEMM 或专用 kernel 问题。
5. GEMM 为什么是硬件热路径
GPU、TPU、NPU 等加速器都非常擅长规则 dense 矩阵-矩阵乘。大模型性能优化里,很多问题最终会变成:
- 矩阵形状是否适合硬件 tile;
- 数据是否连续;
- dtype 是否命中 Tensor Core 或专用低精度路径;
- 是否能把小矩阵合并成更大的 batch GEMM;
- 量化后是否仍有对应 INT4/FP8/FP4 kernel。
这也是为什么 算子与编译器 章节会反复讨论 GEMM、layout、tile 和 kernel。
6. 一个最小伪代码
1 | function Linear(x, W, b): |
7. 和量化有什么关系
权重量化最常压的就是 Linear 层权重,因为它们占参数量大头。常见形式包括:
W8A16:权重 INT8,激活 FP16/BF16。W4A16:权重 INT4,激活 FP16/BF16。W8A8:权重和激活都 INT8。FP8 W8A8:权重和激活走 FP8 或近似 FP8 路径。
如果量化格式没有高效 GEMM / batched GEMM / fused dequant MatMul kernel,模型文件虽然变小,推理可能并不会更快。这个问题会在 量化路线图 和 数值、显存与运行时 里继续展开。
小结
Linear 是表示投影,MLP 是逐 token 非线性变换,MatMul 是数学/API 操作,GEMM 是常见的底层 dense 矩阵-矩阵执行核心。理解这几层的边界,能帮助你把 Transformer、量化、算子优化和推理性能连成一条线。
- Title: 基础知识:线性层到 GEMM
- Author: Charles
- Created at : 2025-06-29 09:00:00
- Updated at : 2025-06-29 09:00:00
- Link: https://charles2530.github.io/2025/06/29/ai-files-foundations-linear-layers-mlp-and-gemm/
- License: This work is licensed under CC BY-NC-SA 4.0.