
基础知识:数值、显存与运行时
模型能不能真正部署,不只取决于算法,还取决于数值格式、显存、带宽、kernel 和 runtime 是否匹配。
这页先回答“数值、显存与运行时”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先看本页要补哪一个最小概念;公式或术语卡住时回到术语表,不需要一次吃完整个数学体系。 必要时先回 基础知识入口 或 术语表。
主线关系:把符号、张量、优化、评测和运行时这些前置打稳,后面的扩散、VLM/VLA、训练与系统页才不会断层。
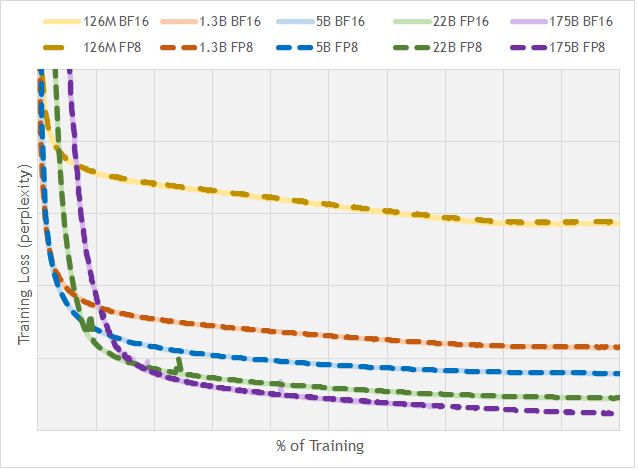
图源:FP8 Formats for Deep Learning,Figure 1。原论文图意:比较不同规模 GPT 模型在 BF16 与 FP8 训练下的 loss/perplexity 曲线,展示 FP8 在合适 scaling 与训练配置下可以接近 BF16 收敛行为。
这张图的重点不是“FP8 一定安全”,而是说明低精度能否用于训练,要看 loss 曲线是否稳定跟随高精度基线。FP8 节省显存和带宽,但必须配合合适的 scaling、累加精度、kernel 和异常值处理。低精度格式能保存不等于能高效执行;模型文件变小也不等于线上更快。必须同时看数据在哪里、怎么搬、用什么 kernel 算。
大模型系统里,“算得动”和“跑得快”不是一回事。真正速度常由 dtype、显存、带宽、kernel、runtime 和请求形态共同决定。看到“模型更小但没有更快”“FLOPs 低但延迟高”“量化后 P99 变差”时,不要只看参数量。
KV INT8 省了显存但 token/s 没升,FP8 loss 曲线短期对齐但长跑漂移,或者某个 runtime 宣称支持低比特却在 trace 里频繁 dequant 回 FP16 时,回看本页。本页能帮你判断收益是否被带宽、workspace、kernel fallback、scale 读取或数值保护抵消。
最小字节账:先把数字换成显存
数值格式首先决定每个数字占多少 bytes。
| 格式 | 粗略 bytes / value | 直觉 |
|---|---|---|
| FP32 | 4 | 准但贵 |
| FP16 / BF16 | 2 | 大模型训练和推理常用 |
| FP8 / INT8 | 1 | 更省,但依赖 scale 和 kernel |
| INT4 / FP4 | 0.5 | 压缩强,硬件和 runtime 支持更关键 |
一个 hidden tensor 的最小显存可以先估:
这不是完整显存,只是把 shape 换成 bytes 的第一步。训练还要加激活、梯度和 optimizer state;推理还要加 KV cache 和 workspace。
数值格式:精度和范围的取舍
常见格式:
| 格式 | 常见用途 | 直观理解 |
|---|---|---|
| FP32 | 高精度训练、参考路径 | 准但贵 |
| FP16 | 混合精度训练和推理 | 省显存但范围较窄 |
| BF16 | 大模型训练常用 | 范围接近 FP32,精度更低 |
| FP8 | 新硬件上的训练/推理加速 | 更省,但更依赖 scaling |
| INT8 / INT4 | 量化推理 | 压缩强,kernel 支持很关键 |
低精度的本质是牺牲部分表示能力,换取更低显存、更低带宽和更高吞吐。
显存主要被谁占用
不同阶段显存构成不同:
| 阶段 | 主要显存 |
|---|---|
| 训练 | 权重、梯度、optimizer state、activation |
| 推理 | 权重、KV cache、临时 workspace |
| 长上下文 | KV cache 可能成为主瓶颈 |
| 多模态 | 图像/视频 token 和中间特征会显著增加内存 |
这解释了为什么同一个模型“能推理”不代表“能训练”,也不代表“能高并发服务”。
FLOPs、MACs、带宽和延迟
常见指标:
FLOPs:算了多少浮点操作。MACs:multiply-accumulate 次数,也就是一次乘法加一次累加。memory bandwidth:数据搬运速度。latency:单次请求耗时。throughput:单位时间处理多少请求或 token。
MACs 和 FLOPs 经常被混用,但最好先立一个约定:一个 MAC 包含一次 multiply 和一次 add,所以在很多硬件/论文的 FLOPs 口径里,1 MAC ≈ 2 FLOPs。但有些模型统计工具会把 fused multiply-add 当成 1 次操作。读报告或 profile 时,先确认工具到底在数 MACs、FLOPs,还是只数矩阵乘里的乘加主项。
一个 Linear 层 最适合建立直觉:
如果一次处理 个 batch、每个 batch 有 个 token,那么 Linear 主体 MACs 约为:
这也是为什么 Params 和 MACs 有时看起来很接近:对单个 token 来说,一个被用到的权重通常贡献一次乘加。但它们不是同一个概念。Params 是模型静态存了多少权重;MACs 是某个输入 shape、某个推理/训练阶段实际做了多少乘加。MoE、长上下文 attention、batch、prefill/decode 都会让两者分开。
一个算子可能不是算不动,而是数据搬不动。比如低算术强度算子经常受带宽限制,而不是算力限制。
Kernel 和 Runtime
Kernel 是实际在 GPU 或加速器上执行的底层计算程序。Runtime 负责把模型图、请求、batch、缓存和 kernel 组织起来。
例如:
- GEMM kernel 负责高性能 dense 矩阵-矩阵乘路径。
- Attention kernel 负责注意力计算。
- Fused kernel 把多个操作合并,减少中间读写。
- vLLM、SGLang、ONNX Runtime、TensorRT-LLM 负责更高层的执行调度。
为什么“格式支持”不等于“性能收益”
一个 INT4 模型文件很小,但如果 runtime 没有 INT4 高效 kernel,可能会发生:
- 先反量化成 FP16。
- 再用普通 FP16 GEMM 计算。
- 文件变小了,但计算没变快,甚至因为反量化更慢。
因此量化上线前必须确认:
- 目标 runtime 支持该格式;
- 目标硬件支持该低精度指令;
- 热点算子有对应 kernel;
- 端到端 TTFT、TPOT、吞吐和质量都改善。
一张部署成本流图
flowchart LR
A["模型参数"] --> B["权重显存"]
C["输入 token / 图像 / 视频"] --> D["激活与临时 workspace"]
E["长上下文 / 多轮对话"] --> F["KV cache"]
B --> G["HBM 读写"]
D --> G
F --> G
G --> H["Kernel 执行"]
H --> I["Runtime 调度"]
I --> J["TTFT / TPOT / 吞吐 / P99"]
K["dtype / quant scale"] --> H
L["batch / shape bucket"] --> I
这张图提醒你:低精度格式只是进入系统成本的一条边。真正上线时,权重、activation、KV cache、workspace、kernel、runtime 和 shape bucket 都会共同决定延迟。一个方案若只减少权重显存,却没有减少 decode 时的 KV 读取或没有命中低比特 kernel,端到端收益就会很小。
一个可复算的显存小账
假设一个 7B 模型使用 BF16 权重,权重显存约为:
但如果服务长上下文,KV cache 可能同样大。以 32 层、hidden size 4096、batch 8、上下文 16k、BF16 KV 为例:
这里前面的 2 表示 K 和 V。把这行拆开看会更直观:在单层里,单独一个 K cache 的大小是 ,约 1GiB;再乘 V 就是 2GiB / layer;32 层合起来就是约 64GiB。这还只是 KV 本体,没有算 page metadata、碎片、runtime workspace、临时 buffer 和其它并发请求。
这类小账要注意公式里的 更准确地说是 KV 宽度。标准 MHA 里它通常接近 hidden size;如果用了 GQA/MQA,KV head 数少于 query head 数,KV 宽度会按比例下降;如果用了 MLA,则缓存的可能是压缩 latent,而不是完整 K/V。因此判断一个模型“长上下文贵不贵”时,不能只看参数量,还要看 layers、context、batch、KV heads、head dim 和 dtype。
| 变量变化 | KV 显存怎么变 | 直觉 |
|---|---|---|
context 从 16k 到 32k |
约 2x |
历史 token 多一倍,每层都要多存一倍 K/V |
batch 从 8 到 16 |
约 2x |
并发上下文一起常驻显存 |
| BF16 KV 改 INT8 KV | 约 1/2 |
bytes 从 2 降到 1,但要考虑 scale/dequant 和质量回归 |
MHA 改 GQA,KV heads 降到 1/4 |
KV 宽度约 1/4 |
主要省 KV cache 和 decode 读带宽,不等于 prefill 计算免费 |
这个例子说明:小模型不一定轻,长上下文下 KV cache 会成为主角。量化权重能让模型放得下,但 KV 量化、prefix cache、paged attention 和上下文裁剪才可能让高并发跑得稳。
| 优化动作 | 主要省什么 | 可能不省什么 |
|---|---|---|
| 权重量化 | 参数显存、部分权重带宽 | KV cache、视觉 token、runtime overhead |
| KV 量化 | 长上下文并发显存、decode 读写 | prefill FLOPs、scale/dequant 开销 |
| Activation checkpointing | 训练激活显存 | 反向重算时间 |
| FlashAttention | attention 中间写回 | decode KV 生命周期 |
| Shape bucketing | kernel 命中率、padding 浪费 | 长尾请求和工具延迟 |
进阶案例:DeepSeek-V3 的 Params 和 MACs 怎么手算
下面用 DeepSeek-V3 做一个可复算例子。它适合这个主题,因为它是 MoE:Total Params 很大,但每个 token 只激活一小部分 routed experts。
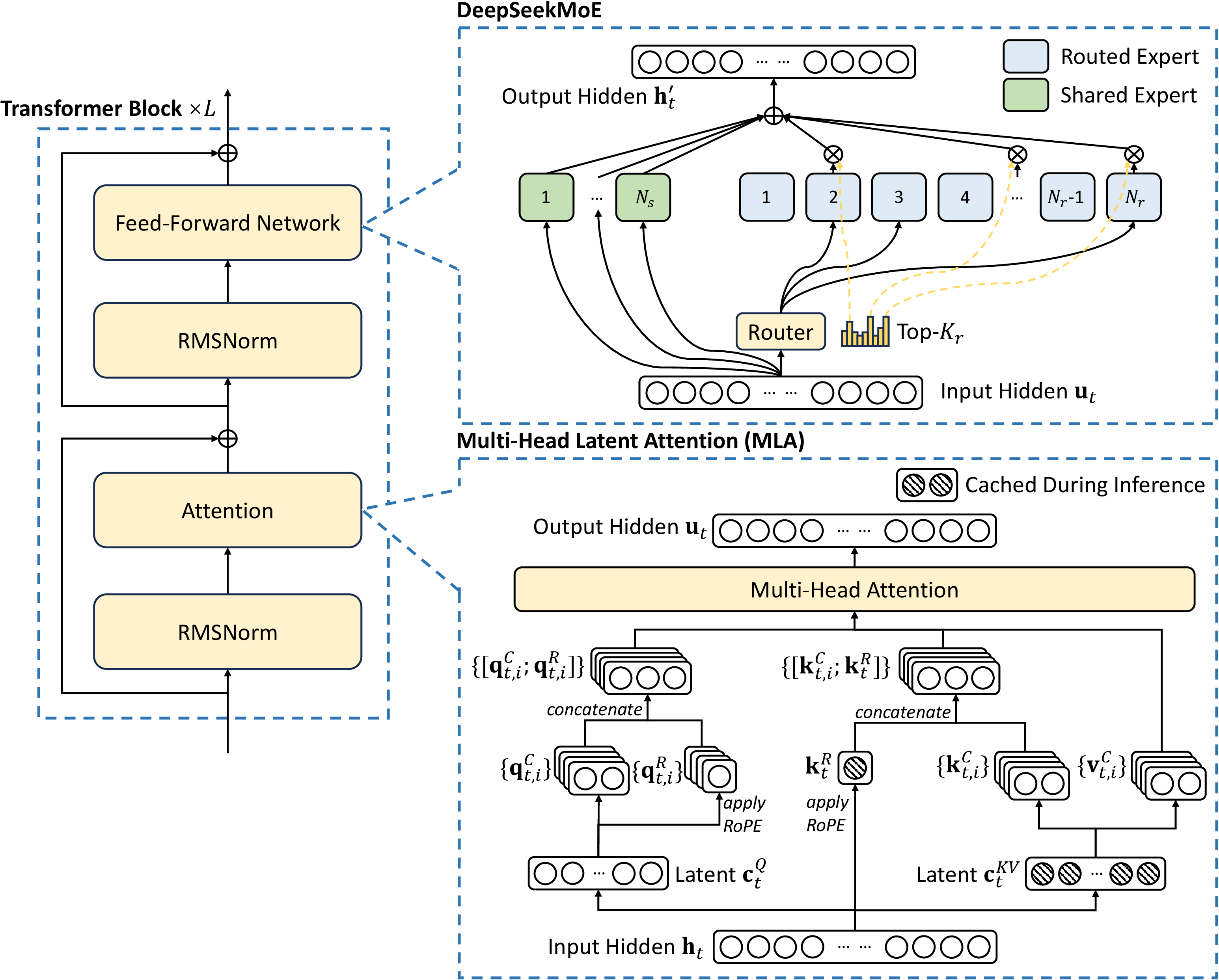
图源:DeepSeek-V3 Technical Report,Figure 2。原论文图意:DeepSeek-V3 的 Transformer block 采用 MLA 和 DeepSeekMoE;MLA 缓存压缩 latent 与 RoPE key,MoE 由 shared experts 和 routed experts 共同组成。
下面按 DeepSeek-V3 官方 671B 主模型配置手算,不把额外的 MTP module 算进主模型参数。为了让初学者能复算,计算只抓主要权重矩阵,RMSNorm、router bias 等小项会说明但不作为直觉重点。MACs 也只先数矩阵乘主项;softmax、SiLU、RMSNorm、top-k、dispatch/combine、通信和 kernel padding 都会影响真实延迟。
关键数字来自 DeepSeek-V3 技术报告和官方 config_671B.json:
| 符号 | 含义 | DeepSeek-V3 值 |
|---|---|---|
| vocabulary size | 129,280 | |
| hidden dimension | 7,168 | |
| Transformer layers | 61 | |
| 前置 dense FFN 层数 | 3 | |
| MoE 层数 | 58 | |
| dense MLP intermediate dim | 18,432 | |
| 单个 expert intermediate dim | 2,048 | |
| routed experts per MoE layer | 256 | |
| activated routed experts per token | 8 | |
| shared experts per MoE layer | 1 | |
| attention heads | 128 | |
| query compression rank | 1,536 | |
| KV compression rank | 512 | |
| non-RoPE Q/K head dim | 128 | |
| RoPE Q/K head dim | 64 | |
| value head dim | 128 |
9.1 先算 embedding 和输出头
输入 embedding 和输出 LM head 都是 :
如果输入 embedding 和输出头不共享权重,仅这两块合计约:
注意:embedding lookup 本身主要是查表读权重,不是大矩阵乘;输出 head 计算 logits 时才是 的 MACs。
9.2 再算每层 MLA 参数
DeepSeek-V3 的 attention 不是普通 Q/K/V/O 四个 投影,而是 MLA。按官方实现,可以把主要权重拆成:
代入数字:
61 层 MLA 合计约:
9.3 Dense MLP 和单个 expert
DeepSeek-V3 的 MLP/Expert 都是 SwiGLU 形态,核心有三块矩阵:w1、w3 升维,w2 降维。因此 dense MLP 每层参数是:
前 3 层是 dense FFN,所以:
单个 expert 的宽度是 ,所以单个 expert 参数是:
9.4 MoE 层的 total params
每个 MoE 层有 256 个 routed experts 和 1 个 shared expert。router gate 还要给每个 expert 打分,主要权重约为 :
58 个 MoE 层合计:
把 embedding、输出头、MLA、前 3 层 dense MLP、58 层 MoE 加起来:
这就对上了 DeepSeek-V3 报告里的 671B total params。关键点是:大头来自所有 routed experts 的总仓库,而不是每个 token 都会跑完这 671B。
9.5 MoE 层的 activated params
每个 token 在 MoE 层不会用 256 个 routed experts,只会用 Top-8 routed experts,再加 shared expert:
这个数很有意思:,而 ,正好接近 dense MLP 的 。所以单 token 的 FFN 乘加量接近一个 宽度的 dense SwiGLU MLP,但模型总容量因为 256 个 routed experts 被放大很多。
把单 token 会用到的矩阵权重加起来:
如果把输入 embedding 查表也放进“activated params”口径里,则约为:
这就是报告里 37B activated params per token 的来源直觉。它不是精确 latency,也不是每步只有 37B 次所有操作,而是说明稀疏 MoE 下每个 token 实际触达的权重规模远小于 671B total params。
9.6 从 activated params 到 MACs
对单个 decode token,如果只看被用到的矩阵乘主项,MACs 约等于 MAC-producing active weights:
如果换成常见 FLOPs 口径:
但真实 LLM 推理还有 attention score/value 聚合。这个部分不随参数量固定,而随上下文长度变。用 MLA 的 absorb 实现做一个粗略估计,decode 一个新 token、历史长度为 时,每层 score/value 聚合主项可写成:
当 :
61 层约:
所以在 4K 历史长度下,一个 decode token 的粗略矩阵乘账可以写成:
如果是 prefill 一个 4K prompt,weight MACs 会乘上 4096:
attention pairwise 部分按 causal triangle 粗算约:
所以 4K prefill 的主项大约是:
这只是手算主项。真实服务还会受 FP8/BF16 kernel、MoE dispatch/combine、expert batch size、all-to-all、KV cache layout、logits 是否全量计算、batching、prefix cache、padding、采样和 runtime 调度影响。Params 帮你看存储和容量,MACs 帮你看乘加规模,最终线上速度仍要用 profiler 和端到端压测确认。
和后续专题的关系
- 量化路线图:理解低精度格式和部署收益。
- 推理系统:理解延迟、吞吐、KV cache 和服务调度。
- 算子与编译器:理解 kernel、GEMM、attention 和 profiling。
- 训练稳定性:理解混合精度和数值异常。
- 线性层、MLP 与 GEMM:理解为什么矩阵乘是低精度和算子优化的主战场。
本页结论
数值格式决定误差和存储,显存与带宽决定瓶颈,kernel 和 runtime 决定收益能否兑现。理解这一层,才能把“模型方法”真正落到“能跑、跑快、跑稳”。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:Prompt、CoT 与 RAG 入门。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:数值、显存与运行时
- Author: Charles
- Created at : 2025-06-30 09:00:00
- Updated at : 2025-06-30 09:00:00
- Link: https://charles2530.github.io/2025/06/30/ai-files-foundations-numerics-memory-and-runtime-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.