
基础知识:优化与训练入门
训练是把数据、模型、目标函数和优化器组织成一个闭环。模型不是一次性“学会”,而是在大量 batch 上反复计算 loss、回传梯度、更新参数。
这页先回答“优化与训练入门”在「基础知识」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先看本页要补哪一个最小概念;公式或术语卡住时回到术语表,不需要一次吃完整个数学体系。 必要时先回 基础知识入口 或 术语表。
主线关系:把符号、张量、优化、评测和运行时这些前置打稳,后面的扩散、VLM/VLA、训练与系统页才不会断层。
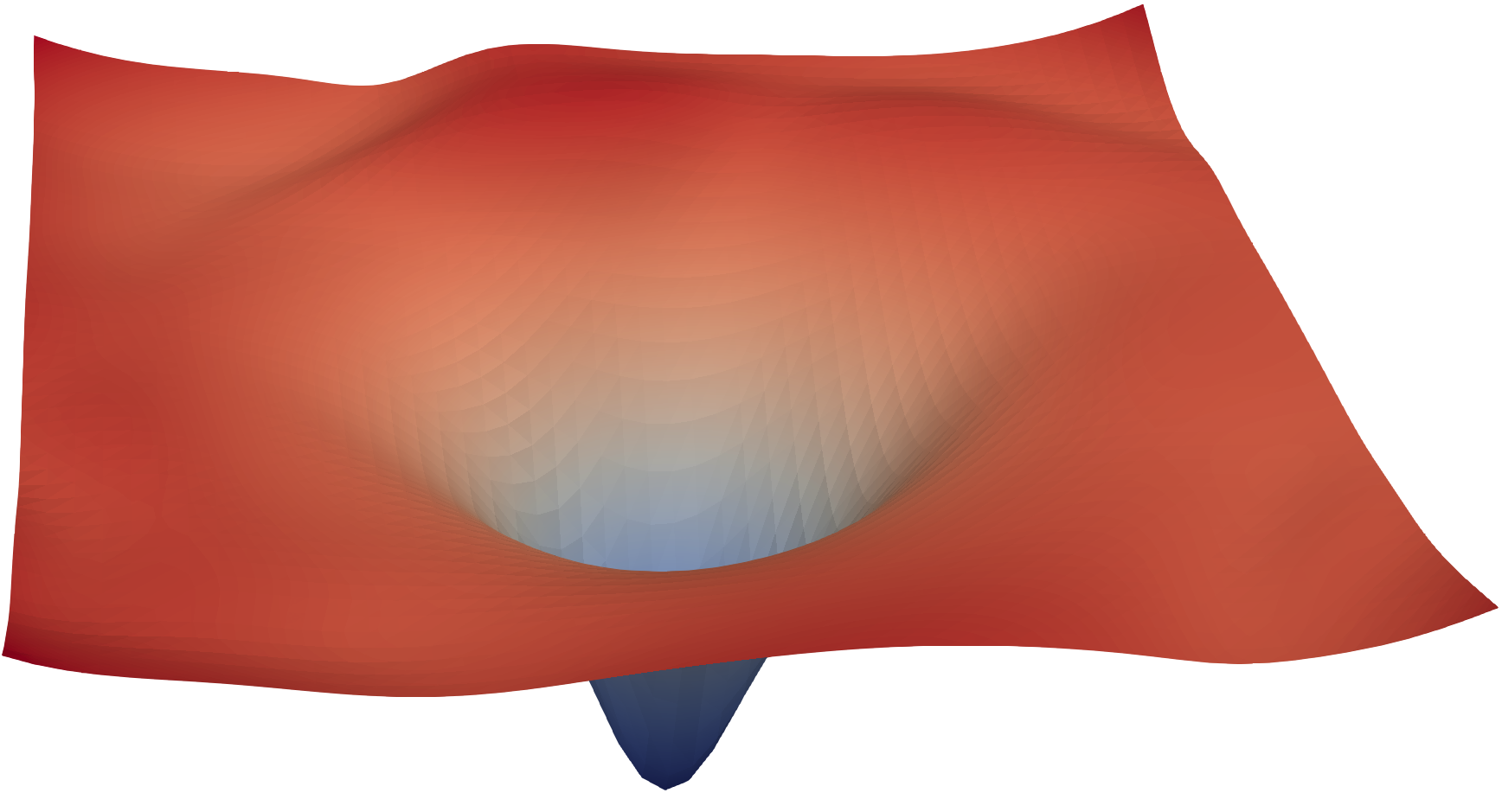
图源:Visualizing the Loss Landscape of Neural Nets,loss landscape visualization。原论文图意:通过 filter normalization 等方法可视化网络周围的 loss surface,帮助比较不同结构或训练配置下优化地形的平滑程度。
这张图把 loss 想象成一片地形:训练不是一次跳到最低点,而是优化器沿着梯度在地形上移动。学习率太大可能越过谷底,太小会走得很慢;batch、归一化、残差、初始化和优化器都会改变这条路是否平滑。训练问题先分层:是能力不够、目标不对、优化没走稳,还是系统数值/恢复出了问题,不要把所有异常都归因于模型结构。
训练循环可以先记成四步:算预测、算 loss、反传 gradient、更新参数。后面所有复杂训练系统,本质上都是在让这四步更稳定、更高效、更可信。看到训练曲线异常时,先区分 loss 设计、学习率、batch、梯度裁剪、数据分布和系统恢复问题。
训练 loss 稳定下降但闭环成功率不涨、长视频 bucket 反复 loss spike、换 optimizer 后短跑更快但最终指标不稳,或者恢复 checkpoint 后曲线悄悄偏离基线时,先回到 loss、gradient、optimizer、scheduler 和评测闭环。本页能帮你判断这是优化路径问题、目标函数问题、数据分布问题,还是系统恢复破坏了训练状态。
优化基础在世界模型高效训练里负责判断“训练到底在朝哪里走”。它能降低无效训练成本:早识别 loss 代理目标和闭环指标错位、learning rate 或 batch 设计不合适、optimizer 让短跑好看但长跑不稳,以及系统恢复让曲线不可比较。
先看标准训练循环
训练可以先记成四步:
1 | output = model(input) # 算预测 |
对应公式是:
| 符号 | 含义 |
|---|---|
| 模型参数 | |
| loss,模型当前错多少 | |
| loss 对参数的梯度 | |
| learning rate,更新步长 |
这行公式的直觉是:沿着让 loss 下降的方向,小步修改参数。
Loss:模型错在哪里
Loss 是训练的方向盘。它定义模型输出和目标之间的差距:
不同任务有不同 loss:
- 分类:交叉熵
- 回归:MSE / L1
- 语言模型:next-token cross entropy
- 扩散模型:噪声、velocity 或 score 预测损失
- 对齐:DPO、RLHF、reward model loss
- 世界模型:观测/latent 重建、dynamics/KL、reward/continue/risk 预测损失
- 具身智能 / VLA:行为克隆动作损失、动作 token 交叉熵、动作扩散去噪损失、RL policy/value loss
Loss 定义不清,训练再久也可能朝错误方向走。
后面读世界模型和具身智能时,可以先把常见 loss 放到这张速查表里。这一节属于进阶查阅,第一遍只要知道“不同任务会定义不同的错误”即可。
| 场景 | 模型在学什么 | 常见 loss 形态 | 训练信号从哪里来 |
|---|---|---|---|
| 像素 / 视频世界模型 | 预测下一帧、未来视频或被 mask 的观测 | ,或扩散去噪 | 视频帧、图像 patch、未来观测 |
| Latent / JEPA 世界模型 | 预测 encoder latent,而不是逐像素生成 | , | frozen/target encoder 表征、masked latent |
| RSSM / Dreamer | 学可 rollout 的 latent dynamics,并预测 reward/continue | 重建项 + reward loss + continue loss + | 真实交互轨迹:observation、action、reward、done |
| WAM / 动作条件世界模型 | 给定历史和目标,同时建模未来动作与未来世界 | 未来观测/latent loss + 动作一致性 loss + reward/risk/done head | 机器人轨迹、候选动作、执行后观测 |
| VLA 行为克隆 | 从视觉语言观测直接预测专家动作 | ,连续动作常退化成 MSE/L1 | 专家示范、遥操作、机器人数据集 |
| 动作 token / 序列策略 | 把动作离散成 token,像语言一样预测下一步动作 | action-token cross entropy | 离散化动作序列、teacher forcing |
| Diffusion Policy | 生成未来动作块,而不是回归单步均值 | 未来动作 chunk、观测、语言目标 | |
| RL / 闭环微调 | 让策略更偏向高回报、低风险动作 | policy gradient / PPO loss + value loss + entropy 或 KL 正则 | 环境 reward、规则评测、reward model、成功/失败回放 |
世界模型的 loss 通常在问“世界会怎么变”:未来观测像不像、latent 能不能往前 rollout、reward/continue/risk 能不能被读出来。具身智能 / VLA 的 loss 通常在问“该怎么动”:动作是否像专家、动作块是否连贯、采样策略是否带来更高成功率。两者会在 WAM、Dreamer、VLA+WM 系统里合到一起:前者提供可预测的未来,后者把未来变成可执行动作。但最终不能只看训练 loss,必须看闭环 success、failure bucket、risk recall 和真实执行成本。
Backprop:把错误传回参数
反向传播使用链式法则计算每个参数对 loss 的影响:
这里 是学习率。学习率太大容易震荡或发散,太小则训练慢甚至停滞。
梯度爆炸和梯度消失:错误传不回来或传过头
反向传播会把后面层的误差信号一层层传回前面。深层网络或长序列模型里,这个过程会反复乘 Jacobian:
如果这些乘积的尺度长期小于 1,梯度会越来越接近 0,这就是梯度消失;如果尺度长期大于 1,梯度会被放大到非常大,这就是梯度爆炸。RNN 因为沿时间反复使用同一类状态转移,最容易把这个问题暴露出来;很深的前馈网络、Post-Norm Transformer、低精度训练和长序列 world model 也会遇到类似现象。
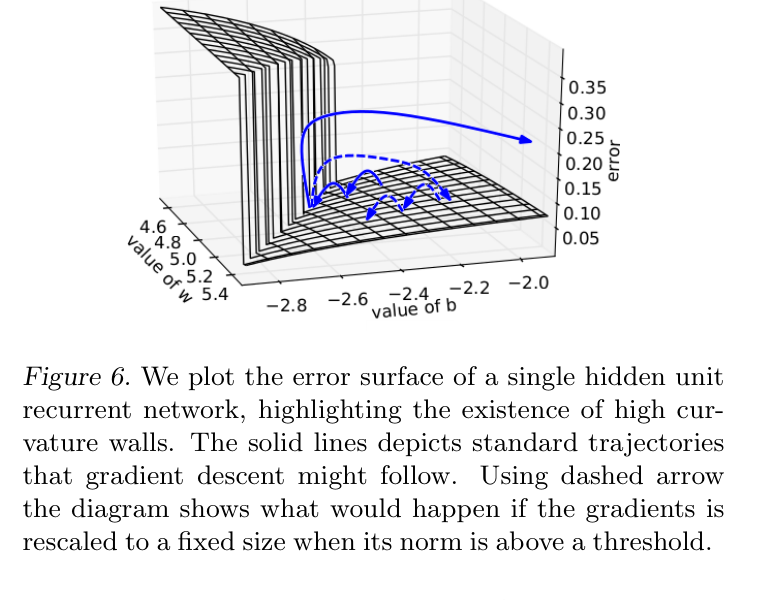
图源:On the difficulty of training recurrent neural networks,Figure 6。原论文图意:单隐藏单元 RNN 的 error surface 中存在高曲率墙;普通梯度下降可能因为梯度过大跳过稳定区域,虚线示意把梯度 norm 裁剪到阈值后更新会更可控。
训练曲线上通常会这样表现:
| 现象 | 训练曲线长什么样 | 监控指标 | 常见例子 | 常见处理 |
|---|---|---|---|---|
| 梯度消失 | train loss 很早进入平台期,下降极慢;长依赖任务学不到,但不一定 NaN | 前面层或早期时间步 grad norm 接近 0;activation 进入 sigmoid/tanh 饱和区 | vanilla RNN 记不住很早的 token;深层 sigmoid 网络前几层几乎不更新 | 残差/skip、LayerNorm/RMSNorm、LSTM/GRU 门控、ReLU/GELU、合适初始化、缩短反传长度 |
| 梯度爆炸 | loss 突然尖刺、震荡或直接变 NaN/Inf;恢复 checkpoint 后也可能马上再次炸 | global grad norm 突增几个数量级;参数范数和 loss scale overflow 同步异常 | 长序列 RNN、学习率过大、warmup 太短、长视频 bucket 或异常 batch 触发 spike | gradient clipping、降低 LR、加 warmup、检查异常样本、提高敏感路径精度 |

图源:On the difficulty of training recurrent neural networks,Figure 7。原论文图意:在 temporal order 任务上,序列长度变长后,不同初始化和训练策略的成功率差异明显;带 clipping 和 regularization 的变体更能维持长序列训练成功率。
假设一个 RNN 或长视频世界模型在短序列 bucket 上 loss 正常下降,但切到长序列后 loss 先尖刺、随后 NaN,同时 global grad norm 从 1e1 跳到 1e5,这更像梯度爆炸,应先看 clipping、LR、warmup、异常样本和低精度 overflow。反过来,如果训练没有 NaN,loss 只是长期卡在高位,模型只会利用最近几步上下文,早期层或早期时间步 grad norm 长期接近 0,这更像梯度消失,应检查残差路径、归一化、激活饱和、初始化和是否需要 gated / attention / SSM 结构。
loss spike 不一定都是梯度爆炸,也可能是坏数据、混合精度 scale、分布式恢复或评测 bucket 变化;loss 平台期也不一定都是梯度消失,可能是模型容量、标签噪声或目标函数不对。最稳的排查方式是把 loss、global grad norm、per-layer grad norm、LR、overflow/NaN、数据 bucket 和 checkpoint 恢复事件放在同一条时间线上看。
Optimizer:怎么走下一步
常见 optimizer:
| Optimizer | 特点 |
|---|---|
| SGD | 简单、稳定,但调参要求高 |
| Adam | 自适应学习率,深度学习常用 |
| AdamW | decoupled weight decay,LLM 训练常见 |
| Muon | 对矩阵权重做 momentum orthogonalization,大规模预训练中用于提升 token / FLOP efficiency |
现代大模型训练通常还会配合:
- learning rate warmup:训练初期逐步升高学习率,避免参数还不稳定时被大步更新冲坏。
- cosine decay:训练后期平滑降低学习率,让优化从快速探索转向细致收敛。
- gradient clipping:限制梯度范数,减少 loss spike 或异常 batch 引发的发散。
- mixed precision:用 FP16/BF16/FP8 等低精度加速计算,同时保留必要的高精度状态。
- distributed optimizer:把参数、梯度或优化器状态分散到多卡,降低单卡显存压力。
Muon 这类优化器说明了一个容易被忽略的点:优化器不只是“步子大不大”,还决定参数更新的几何。AdamW 是当前最稳的默认起点;Muon 更适合放在大规模预训练、矩阵权重占主导、基础设施能支持矩阵正交化的场景里看。更完整的论文解析和 AdamW 对比见 Muon:LLM 预训练优化器。
一个完整训练循环
1 | for step, batch in enumerate(dataloader): |
这段伪代码看起来简单,但真实训练里每一行都可能扩展成复杂系统:数据加载、混合精度、并行通信、checkpoint、评测和恢复语义。
如果你关心 loss.backward() 背后为什么要保存中间激活、为什么 activation checkpointing 能省显存,可以继续看 自动微分与激活显存。
为什么 loss 下降不等于模型可用
Loss 是训练信号,但最终还要看任务指标。常见误判包括:
- 训练 loss 下降,但评测集不提升。
- 平均指标提升,但长尾任务下降。
- 格式更像人类回答,但事实性变差。
- 短上下文变好,长上下文变差。
- 离线 benchmark 提升,线上延迟或成本不可接受。
因此训练系统必须绑定评测和回放,而不是只看 loss 曲线。
7.1 真实场景:平均 loss 下降,关键桶变差
假设一个 action-conditioned video world model 新 recipe 的训练 loss 从 0.214 降到 0.198,团队很容易认为它更好。但分桶后发现:
| Bucket | Token Share | Baseline Loss | New Loss | Closed-loop |
|---|---|---|---|---|
| easy static scene | 72% |
0.180 |
0.158 |
+0.3% |
| moving object | 18% |
0.246 |
0.241 |
+0.1% |
| contact / occlusion | 10% |
0.310 |
0.337 |
-6.8% |
平均 loss 下降,是因为 72% 的 easy bucket 变好;真正影响机器人成败的 contact/occlusion bucket 变差。优化器没有“犯错”,它只是忠实优化了被数据占比加权后的目标。
排查链应是:
1 | 症状:loss 更低,但闭环成功率或风险召回下降 |
和后续专题的关系
- 大模型训练路线图:进入完整训练生产线。
- 训练评测与消融设计:判断训练改动是否可信。
- 训练稳定性:排查 loss spike、NaN、梯度异常。
- 量化训练:理解低精度训练为什么更难。
- 数据划分与评测指标:理解为什么训练结论必须绑定分桶评测。
本页结论
训练不是“跑一个 loss”而是一个闭环系统:loss 决定方向,梯度推动参数,optimizer 控制步伐,评测决定结论是否可信。
- 回到本专题入口:基础知识,确认这页在整条路线中的位置。
- 按导航顺序继续:自动微分与激活显存。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 基础知识:优化与训练入门
- Author: Charles
- Created at : 2025-07-02 09:00:00
- Updated at : 2025-07-02 09:00:00
- Link: https://charles2530.github.io/2025/07/02/ai-files-foundations-optimization-and-training-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.