
基础知识:概率与潜变量模型:生成模型到底在学什么
生成模型不是把训练样本背下来,也不是“随机画一个像样的东西”。它要学的是一个分布:哪些样本可能出现,哪些条件会改变样本,哪些隐藏因素可以解释观测到的数据。VAE、扩散模型、RSSM / Dreamer、JEPA、视频世界模型都会反复使用这套语言。
这页只回答一个核心问题:当论文写 、、、ELBO、score 和 latent state 时,它们分别在训练链条里扮演什么角色?
分布不是标签,而是可能性的形状
如果真实数据来自未知分布,可以写成:
模型要学一个 去接近它。这里 可以是一张图、一段视频、一串 token、一个机器人轨迹,也可以是世界模型里的未来状态。条件生成则多一个条件:
可以是文本、类别、图像、动作、目标状态或历史观测。这个式子的含义不是“模型确定地产生一个 ”,而是“在条件 下,哪些 更可能”。同一个 prompt 可以有多张合理图,同一个当前状态也可能有多种未来,所以生成模型必须处理多种可能性。
训练时常见的 maximum likelihood 是:
直觉很简单:真实样本 在模型分布下概率越高,loss 越小。但很多强生成模型不会直接显式写出完整 ,而是借助 latent variable、denoising objective、score matching 或 autoregressive factorization 来训练。
潜变量:把看不见的因素放进模型
很多观测背后都有隐藏因素。人脸图像背后有身份、姿态、光照、表情;机器人观测背后有速度、接触状态、遮挡物;视频世界模型背后有还没被直接看到的动力学状态。潜变量 就是模型用来表示这些隐藏因素的随机变量。
一个最小 latent-variable generative model 可以写成:
合起来得到边际分布:
这行公式在说:要生成 ,模型先从先验 里抽一个内部原因,再通过 decoder / generative model 生成观测。这里的 通常不是一个普通确定性函数,而是一个由神经网络参数化的概率分布;网络可能输出均值、方差、logits 或其他分布参数。
推断方向:看到 后反推
生成方向是 。训练时我们看到的是 ,经常需要反过来问:这个样本可能由哪些 产生?这叫 posterior inference:
难点正好在分母:
对高维连续 latent 和神经网络 decoder,这个积分通常不可算。VAE 的解决办法不是“硬算后验”,而是训练一个 inference model:
它用简单可采样的分布去近似真实 posterior 。因此,VAE 里的 encoder 更准确地说是 recognition / inference model;decoder 才是生成模型的一部分。
ELBO:把不可算 likelihood 换成可优化下界
从任意近似分布 出发,可以把真实 likelihood 拆成:
因为 KL divergence 非负, 就是 的下界。最大化 ELBO 有两个效果:一边把下界往上推,让模型更能解释数据;一边让 更靠近真实 posterior。
把联合分布 展开,常见 VAE 形式是:
第一项常被叫 reconstruction term,但它不是普通像素 MSE 的同义词;它是在问“从这个 latent 生成真实样本的概率有多高”。第二项把每个样本的 posterior 拉回统一先验 ,否则 encoder 可能给每个训练样本分配一块互不相干的 latent 空间,采样时从 抽出来的点就很难被 decoder 正确使用。
重参数化:让采样也能反向传播
VAE 训练还需要解决一个工程问题:如果 ,采样步骤会挡住对 的梯度。重参数化技巧把随机性搬到一个无参数噪声上。常见高斯 posterior 写成:
这样 仍然是从同一个分布采样,但梯度可以沿着 和 回到 encoder。Auto-Encoding Variational Bayes 的关键价值就在这里:把 latent-variable model 的近似推断和神经网络的随机梯度训练接起来。
KL 项不是装饰:太强太弱都会出问题
ELBO 里的 KL 项常被初学者当作“正则化”,但它实际控制的是 posterior 和 prior 的关系。KL 太弱时,encoder 可能把样本记到分散的 latent 角落,重建很好,但从 prior 采样会生成差。KL 太强时, 被迫过于接近 ,decoder 可能学会忽略 ,这就是常说的 posterior collapse 风险之一。
所以 VAE 不是“autoencoder 加噪声”。它是在三件事之间折中:latent 要解释当前样本,latent 要能从统一先验中采样,decoder 要能把 latent 变成观测分布。
扩散模型:不用显式密度,也能学分布方向
扩散模型也在学习分布,但方式不同。它先定义一个正向加噪过程 ,把真实样本逐步推向噪声;再训练反向模型 ,从噪声一步步回到数据。

图源:Denoising Diffusion Probabilistic Models,Figure 2。原图表达前向过程 逐步加噪,反向过程 逐步去噪。本站读法是把 看成一串受控噪声状态:训练目标不是直接写出 ,而是在每个噪声水平学习回到数据分布的局部方向。
Score 是另一种描述分布的方式:
它表示当前位置往哪个方向移动会让 log density 上升。扩散训练里的噪声预测和 score 有尺度关系;模型看起来在做 MSE 去噪,本质上是在不同噪声水平学习一个概率方向场。
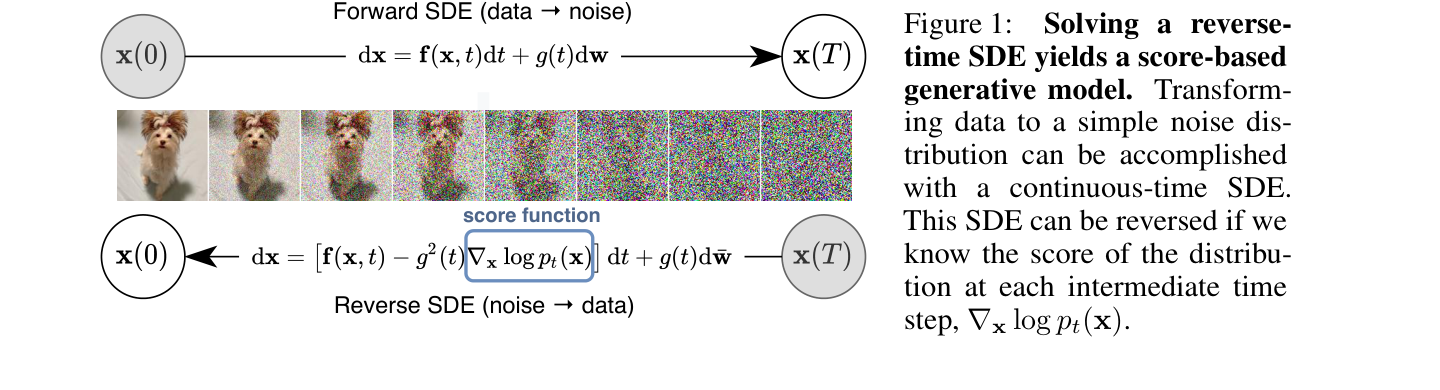
图源:Score-Based Generative Modeling through Stochastic Differential Equations,Figure 1。原图表达正向 SDE 把数据扰动到噪声,反向 SDE 依赖每个中间分布的 score 生成样本。本站读法是把 score 当作“分布地形上的坡度”:生成不是一次性解码,而是沿着学到的方向场积分回数据区域。
世界模型里的 latent:状态要服务预测和决策
在 VAE 中,latent 常常服务重建和采样;在扩散中, 是噪声链上的中间状态;在世界模型里,latent 更接近 agent 的 belief state。它要压缩历史观测和动作,还要保留未来预测、奖励、风险和规划需要的信息。
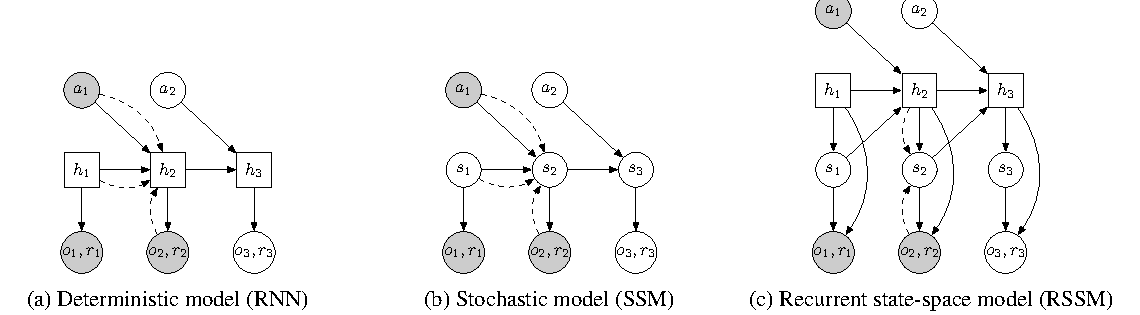
图源:Learning Latent Dynamics for Planning from Pixels,Figure 2。原图比较 RNN、SSM 和 RSSM 三种 latent dynamics 设计。本站读法是看 deterministic memory 和 stochastic state 的分工:前者记历史,后者表达不确定未来,二者合在一起才能服务 planning。
这也是为什么“latent”不能被翻译成一个固定概念就结束。读论文时要追问:这个 latent 来自哪里?它是从 prior 采样、从 posterior 推断、从 denoising chain 递推,还是从历史观测更新?它最后服务的是生成图像、压缩 token、预测未来,还是选择动作?
不确定性会在 rollout 里放大
概率语言对世界模型特别重要,因为决策系统害怕长尾错误。假设 risk head 对“接触即将失败”的单步漏报率是 5%。看单步不大,但 20 步 rollout 中至少漏一次的概率是:
这说明多步预测不能只报最可能未来。若未来分布是多峰的,均值预测可能 loss 低,却把“会滑落”和“能抓稳”平均成不存在的中间状态。对 planner 来说,中间状态不是安全折中,而是错误世界模型给出的虚假可行动作。
读生成模型时先问四个问题
第一,模型定义的随机变量是什么:是 、、、belief state,还是动作序列?第二,训练目标在逼近什么:likelihood、ELBO、score、denoising loss,还是下游 reward?第三,采样或推理时从哪里开始:prior、噪声、posterior state,还是真实历史观测?第四,评测看什么:likelihood、sample quality、prompt alignment、calibration、closed-loop success,还是 planner 的候选排序?
这些问题能避免几个常见误解:likelihood 高不等于样本好看;重建好不等于 latent 可采样;视频预测清晰不等于能规划;score 准也不等于少步采样一定稳定;latent 省 token 不等于保留了行动相关状态。
读完以后怎么判断
概率与潜变量模型的核心不是背公式,而是分清三条链。生成链:,再从 生成观测。推断链:看到 后用 近似不可算 posterior。采样链:从 prior、噪声或 posterior state 出发,用训练好的模型逐步生成样本或未来状态。
VAE 用 ELBO 把不可算的边际似然变成可优化下界;扩散用受控加噪把分布学习变成方向场学习;世界模型用 latent state 把历史、不确定性和动作后果压到可 rollout 的状态空间。把这三条链看清,后面的扩散、Dreamer、V-JEPA、VLA 和视频世界模型公式就不再只是符号。
外部精读
- Auto-Encoding Variational Bayes
- An Introduction to Variational Autoencoders
- Tutorial on Variational Autoencoders
- Variational Inference: A Review for Statisticians
- Deep Generative Modelling: A Comparative Review
- RBC Borealis: Tutorial #5 Variational Auto-Encoders
- Yang Song: Generative Modeling by Estimating Gradients of the Data Distribution
- DDPM
- Score-Based Generative Modeling through SDEs
- TensorFlow Core 中文教程:卷积变分自编码器
- Pyro 中文教程:变分自编码器
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:概率与潜变量模型:生成模型到底在学什么
- Author: Charles
- Created at : 2025-07-01 09:00:00
- Updated at : 2025-07-01 09:00:00
- Link: https://charles2530.github.io/2025/07/01/ai-files-foundations-probability-latent-variables-and-generative-models/
- License: This work is licensed under CC BY-NC-SA 4.0.