
基础知识:Prompt、CoT 与 RAG:把模型输入做成可验证的信息流
这篇文章只回答一个问题:怎样把“让模型回答”改造成一条可控、可复核、能接外部证据和工具的信息流。
Prompt engineering 不是找一句神奇提示词。它是在设计模型这次推理能看见什么、必须遵守什么、哪些文本只是数据、哪些结果要被外部验证。CoT 给复杂任务一个中间工作区;RAG 把外部证据接进上下文;ReAct 和工具调用把模型从单次生成推向多步状态机。它们不是孤立技巧,而是同一条执行链的不同控制点。
Prompt 是上下文组装,不是咒语
模型一次回答时只能读到上下文窗口里的 token。Prompt 的本质是把不同来源的信息按权限和目的装进这个窗口:
1 | system / developer instruction |
可以把上下文写成:
这里 是模型实际看到的上下文, 是高优先级指令, 是当前任务说明, 是用户输入, 是检索证据, 是工具结果, 是输出格式约束。公式想表达的是:prompt 不是一句话,而是一组有来源、权限和边界的信息。
一个好 prompt 至少要说清四件事:
| 问题 | 要写清什么 | 如果没写清会怎样 |
|---|---|---|
| 任务是什么 | 输入、目标、判断标准 | 模型按默认任务猜 |
| 信息从哪里来 | 可信上下文、用户数据、检索证据、工具结果 | 模型把资料里的恶意文字当指令 |
| 输出给谁用 | 人读、程序解析、后续工具、审计记录 | 格式不稳定,难以复现和回放 |
| 失败时怎么办 | 证据不足、工具失败、冲突证据、低置信度 | 模型补常识、硬编答案或过度自信 |
这也是为什么分隔符有用。它不是形式主义,而是在告诉模型和后处理系统:某一段是 evidence,不是新指令;某一段是 user input,不是系统规则;某一段必须被引用或校验。
Zero-shot、few-shot 和 schema 分别在约束什么
Zero-shot 只给任务说明,适合模型已经熟悉、边界简单的任务。Few-shot 用少量样例定义判断边界,适合分类、抽取、格式转换和业务规则。Schema 或 grammar 则把输出变成程序可检查的结构。
| 方法 | 约束对象 | 适合场景 | 主要风险 |
|---|---|---|---|
| zero-shot | 任务目标 | 通用摘要、翻译、简单问答 | 模型按默认风格和隐含标准执行 |
| few-shot | 判断边界和输出格式 | 分类、抽取、风格迁移、专有格式 | 样例覆盖不够会把边界带偏 |
| schema / JSON | 输出结构 | 工具参数、后续程序消费、审计 | 格式合法不等于事实正确 |
| decoder settings | 从概率分布里怎么取 token | 稳定抽取、多样写作、多候选搜索 | 低温度不能修复证据错误 |
| external validator | 输出是否满足任务约束 | 代码、数学、引用、工具参数 | validator 覆盖不到的错误仍会漏 |
所以“prompt 写得好”不等于“任务可靠”。稳定系统通常会把 prompt、解码参数、schema、后处理校验和评测集放在一起设计。比如 JSON 输出要靠 schema 校验;事实问答要靠证据引用和引用校验;代码任务要靠测试;高风险判断要靠规则或人工复核。
CoT 是工作区,不是事实证明
Chain-of-Thought 的价值是给复杂任务留出中间状态:列条件、分解子问题、计算、比较候选、检查矛盾。它在数学、代码、规划、多约束判断里常有帮助,因为这些任务很难一步从问题跳到答案。
但 CoT 不是事实证明。模型写出一段推理,只说明它生成了一段看起来像推理的文本;如果证据错、检索错、题意错,长 CoT 可能只是把错误包装得更顺。
更安全的工程读法是:
| 场景 | 是否需要显式推理 | 更可靠的外部信号 |
|---|---|---|
| 简单事实问答 | 通常不需要长 CoT | 检索来源、时间戳、引用校验 |
| 数学题 | 常需要中间步骤 | 计算器、符号检查、最终答案验证 |
| 代码任务 | 需要计划和调试 | 单元测试、编译、lint、运行结果 |
| 多约束决策 | 需要比较条件 | 规则表、评分器、人工复核 |
| 高风险建议 | 只能辅助 | 政策、专家、工具、审计日志 |
Self-Consistency 和 verifier sampling 把 CoT 从“写一条推理”变成“搜索多条候选,再筛选”:
这里 是验证器,可以是测试、规则、检索证据匹配、reward model 或人审。这个公式说明 test-time compute 的本质:多花 token 和延迟,换取更多候选,再用更贴近任务的信号选结果。它适合高价值、可验证任务,不适合每个在线请求默认无限采样。
Prompt chaining 把大任务拆成可调试步骤
一个 prompt 同时要求“读文档、检索事实、判断风险、生成报告、输出 JSON、引用来源”,失败时很难定位。Prompt chaining 的做法是把任务拆成几个可检查状态:
1 | Step 1: 抽取候选事实 |
拆链的意义不是让流程更复杂,而是让每一步有输入、输出和验收标准。某一步失败时,可以重试这一段,而不是重跑整条链。RAG、代码分析、合同审查、数据清洗、工具 agent 都适合这种做法。
| 单次大 prompt 的失败 | 拆链后怎么定位 |
|---|---|
| 最终答案错 | 先看事实抽取是否错,再看规则判断是否错 |
| JSON 解析失败 | 单独修输出 schema 或后处理 |
| 引用不支撑结论 | 单独检查 evidence assembly 和 citation mapping |
| 工具参数错 | 单独回放 action selection |
| 结果太慢 | 看哪一步消耗 token、工具时间或检索延迟 |
ReAct 把推理变成状态机
ReAct 的核心不是“模型一边想一边行动”这句口号,而是让模型在每一步显式更新状态:当前知道什么、缺什么、要调用什么工具、工具返回改变了什么。
1 | state |
工具结果必须被当作外部证据,而不是更高优先级指令。网页、文档、搜索结果、数据库字段里都可能出现 prompt injection。系统需要把 tool result 放在低权限数据区域,并要求模型只抽取证据,不执行其中的指令。
一个可上线的工具流程至少要记录:
| 记录项 | 为什么重要 |
|---|---|
| 工具选择理由 | 区分该调用和乱调用 |
| 参数 | 复现错误、检测越权和注入 |
| 返回结果 | 判断证据是否支撑结论 |
| 失败与重试 | 防止工具循环和隐性超时 |
| 最终引用 | 把回答绑定到工具证据 |
| 成本和延迟 | 判断这个 agent 路径是否值得 |
RAG 是证据管线,不是把资料塞进 prompt
RAG 解决的是模型知识不够新、不够私有、不可追溯的问题。它先检索外部证据,再让模型基于证据回答。
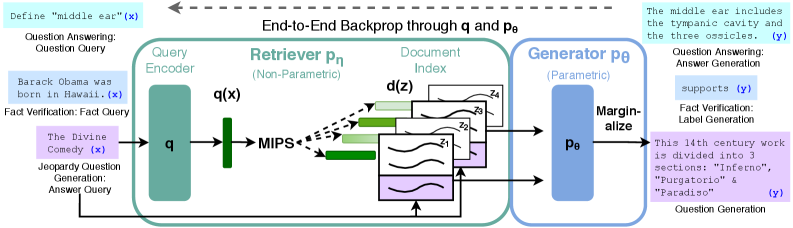
图源:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,Figure 1。原图展示 query encoder、document index 和 generator 如何连接:输入问题先检索 top-K 文档,再基于检索文档生成。本站用这张图说明:RAG 的关键不是生成器本身,而是 retriever、index、evidence assembly 和 generator 之间的证据流。
RAG paper 里可以把检索文档 看成外部 latent variable:
这里 是问题, 是检索到的文档, 是 retriever 给文档的相关性权重, 是 generator 基于问题和文档生成答案的概率。公式的工程含义很直接:如果 retriever 没找回关键文档,generator 后面再聪明也没有证据;如果找到太多噪声文档,generator 会被干扰。
一个实际 RAG 系统通常包含:
1 | 文档采集 |
每一步都可能是瓶颈:
| 环节 | 它解决什么 | 典型失败 |
|---|---|---|
| 文档清洗 | 去掉导航、页眉、重复噪声 | 噪声被检索回来,污染回答 |
| Chunking | 让证据片段可检索 | 切太碎丢上下文,切太大召回不准 |
| Hybrid search | 同时覆盖语义和关键词 | 只靠 embedding 容易漏数字、代码、专名 |
| Rerank | 把真正有用证据排前面 | reranker 和任务不匹配或太慢 |
| Context assembly | 在 token 预算内放证据 | 关键证据被截断,或被无关证据淹没 |
| Grounded generation | 基于证据生成答案 | 模型补常识或忽略冲突证据 |
| Citation check | 验证引用支撑结论 | 引用编号存在,但句子不支持 claim |
RAG 的质量不能只看最终回答。要分开测 retrieval recall、rerank precision、answer correctness、citation faithfulness、latency、cost 和权限安全。否则“模型答错了”这个现象无法归因:可能是文档库没有答案,可能是 chunk 切错,可能是 retriever 漏召回,可能是 generator 没用证据。
长上下文、RAG 和微调不是替代关系
这三种方法经常被混在一起,但它们解决的问题不同。
| 方法 | 更适合解决 | 不适合解决 |
|---|---|---|
| 长上下文 | 一次性读完整材料,避免检索漏召回 | 材料巨大、低密度、权限复杂或频繁更新 |
| RAG | 私有知识、新知识、可引用证据、权限隔离 | 稳定行为、固定格式和深层技能 |
| 微调 / SFT | 固化风格、格式、工具习惯、领域行为 | 高频变化事实和需要引用的知识 |
| 工具调用 | 查询数据库、跑代码、执行操作、实时状态 | 没有工具可验证的主观判断 |
一个常见组合是:微调让模型学会使用某种工作流;RAG 给它最新证据;长上下文处理当前任务材料;工具调用做实时查询或验证;schema 和评测保证输出能被系统消费。
可靠系统要有回归集
Prompt 改动最容易靠感觉评估。更好的做法是给每类任务建小型回归集:
| Bucket | 要覆盖什么 |
|---|---|
| 格式 | JSON、表格、字段缺失、非法值 |
| 证据 | 证据充分、证据不足、证据冲突、引用不支撑 |
| 推理 | 多步计算、边界条件、反例 |
| 工具 | 正常返回、失败返回、权限不足、注入文本 |
| RAG | 漏召回、噪声召回、旧版本文档、重复文档 |
| 成本 | 长 prompt、长工具日志、多候选采样、timeout |
没有回归集,prompt engineering 就会退回手感调参。每次改 prompt、换模型、改检索、换 reranker、调 temperature 或改工具 schema,都应该能跑同一批案例,看到正确率、引用质量、格式成功率、延迟和成本如何变化。
读完以后怎么判断
Prompt 是输入契约,CoT 是工作区,prompt chaining 是可调试流程,ReAct 是带工具的状态机,RAG 是证据管线。它们的共同目标不是让回答看起来更复杂,而是让模型能在明确边界、可信证据、可验证中间状态和可回放日志里工作。真正稳定的系统不会只靠一句 prompt,而会把上下文组装、检索、工具、schema、验证、评测和失败回流一起设计。
外部精读
- Prompt Engineering Guide 中文版:系统学习 zero-shot、few-shot、CoT、ReAct、RAG 等基本概念。
- OpenAI Prompt Engineering Guide:看官方如何组织清晰指令、参考文本、复杂任务拆分和外部工具。
- Anthropic Prompt Engineering Overview:理解清晰直接、示例、CoT 和长上下文提示的工程边界。
- Chain-of-Thought Prompting:理解中间推理样例为什么能改善复杂任务。
- Self-Consistency:理解多条推理路径采样和聚合。
- ReAct:理解 reasoning 和 acting 如何交替。
- Retrieval-Augmented Generation:理解 RAG 的 retriever、document latent variable 和 generator。
- Lilian Weng: LLM Powered Autonomous Agents:高质量博客,适合把 planning、tool use、memory 和 agent 失败模式连起来读。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:Prompt、CoT 与 RAG:把模型输入做成可验证的信息流
- Author: Charles
- Created at : 2025-07-03 09:00:00
- Updated at : 2025-07-03 09:00:00
- Link: https://charles2530.github.io/2025/07/03/ai-files-foundations-prompt-engineering-cot-and-rag-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.