
基础知识:多模态推理入门
现代模型越来越少是“只读文字、直接回答”的形态。真实系统里,用户可能上传图片、视频、语音、PDF、网页截图或工具返回;模型也可能先思考、调用工具、读结果、再继续回答。多模态和 CoT(Chain-of-Thought,思维链)看起来是两个话题,本质上都在回答同一个问题:模型如何把复杂输入组织成可推理的中间状态,再把中间状态转成可靠输出。
如果你还不熟悉 Prompt Engineering、Zero-shot / Few-shot、CoT、RAG 和 ReAct 的基本区别,建议先读 Prompt、CoT 与 RAG 入门。本页会进一步把这些概念放到视觉、音频、视频和工具系统里理解。
多模态不是把图片塞进 prompt,CoT 也不是让模型多写几句。多模态解决“不同来源的信息如何变成统一表示”,CoT 解决“复杂问题如何分解、检查和逐步求解”。二者合在一起,才是多模态 agent、视频理解、工具调用和世界模型的基础。
维修工看到设备照片、听到报警声、读到故障码,不会立刻给结论。他会先确认哪个灯亮、声音从哪里来、故障码对应哪条线路,再决定是否断电、换件或继续测量。多模态模型也类似:先把视觉、音频、文本和历史状态对齐,再进行分步推理。
1. 多模态的第一层:对齐,而不是理解全部世界
最经典的多模态入口是图文对齐。CLIP 的核心是把图片和文字放进同一个 embedding 空间:匹配的图文靠近,不匹配的图文远离。它让模型能回答“这张图更像哪句话”,也为后来的 VLM 提供视觉语义底座。
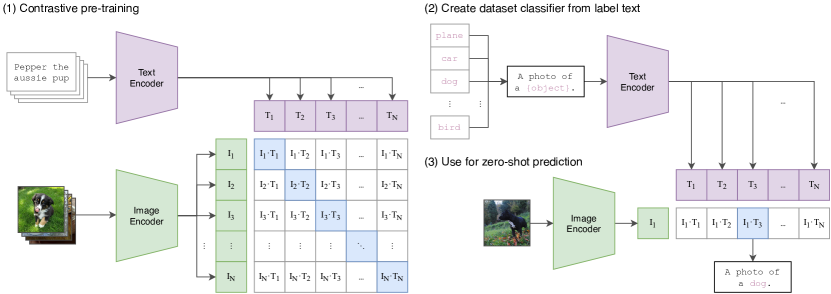
图源:Learning Transferable Visual Models From Natural Language Supervision,Figure 1。原论文图意:CLIP 先用大量 image-text pairs 做对比预训练,再把文本类别转成 prompts,通过图文 embedding 相似度完成 zero-shot prediction。
CLIP 解决的是静态语义对齐:图片 encoder 和文本 encoder 分别输出向量,训练目标让正确图文配对相似度更高。它不是在做长推理,也不知道动作会导致什么未来。读 VLM/VLA/世界模型时,要先分清:CLIP 类方法提供“当前看到了什么”的语义锚点,后面的连接器、LLM、视频记忆、动作接口和世界模型才继续处理“接下来该怎么想、怎么做”。
可以把多模态系统拆成四层:
| 层级 | 解决的问题 | 常见组件 |
|---|---|---|
| 编码 | 每种模态如何变成特征 | vision encoder、audio encoder、video tokenizer、OCR |
| 对齐 | 不同模态如何进入同一语义空间 | CLIP / SigLIP、InfoNCE、image-text matching |
| 连接 | 视觉/音频特征如何喂给 LLM | projector、Q-Former、cross-attention、adapter |
| 推理与行动 | 如何结合语言、工具、历史和目标做决策 | LLM、CoT、tool use、planner、world model |
这四层缺一不可。只有编码,没有对齐,模型看不懂语义;只有对齐,没有连接,LLM 消费不了视觉信息;只有连接,没有推理,模型可能会描述图像,却不会解决复杂任务;只有推理,没有可靠感知,模型又会在错误观察上自信推断。
2. 多模态输入如何进 Transformer
多模态模型最终通常要把不同输入变成 token 或 embedding 序列。文本是 subword token,图像可以是 patch token,视频可以是 frame/tubelet token,音频可以是压缩后的 acoustic token,动作可以是连续向量或离散 action token。
一个简化流程是:
1 | image / video / audio / text |
这里最重要的不是“都变成 token”这句话,而是 token 的密度差异。文本一句话可能几十个 token,一张高分辨率图可能几百到几千个视觉 token,一段视频或长音频会迅速吃掉上下文。因此多模态基础里必须同时关心语义对齐和上下文预算。
Qwen3.5-Omni 的架构图很适合说明这一点:它不是简单把 ASR、LLM、TTS 串起来,而是把 text、image、video、audio 都纳入 Thinker,再由 Talker 生成流式语音。
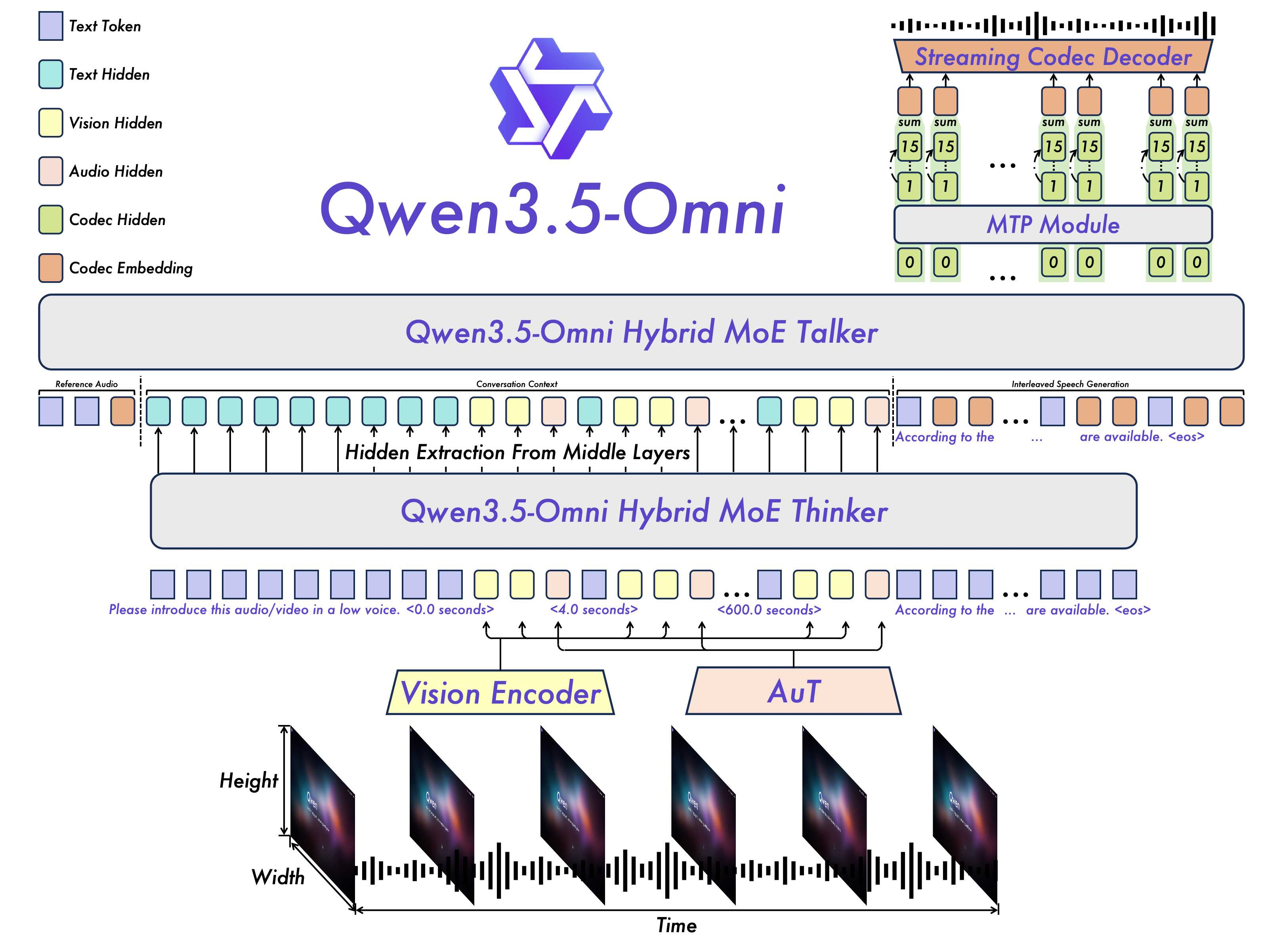
图源:Qwen3.5-Omni Technical Report,Figure 2。原论文图意:Thinker 处理文本、图像、视频和音频输入;Talker 接收 Thinker 表示并通过 RVQ tokens、MTP 和 Code2Wav 生成流式语音。
多模态模型常见误解是“先语音转文字,再把文字给 LLM,最后接 TTS”。这种流水线能工作,但会丢失语气、节奏、环境声、说话人状态和音视频同步线索。Thinker-Talker 这类结构把更多中间表示留在模型内部,让语音输出能跟随多模态上下文。代价是训练、对齐、延迟和上下文管理都更复杂。
2.1 为什么音频和视频特别吃上下文
音频原始帧率很高,视频还多了空间维度和时间维度。如果每 10ms 一个音频帧、每帧视频又切成大量 patch,序列会爆炸。工程上通常会做:
- 音频降采样,例如把连续声学特征压成低频 audio tokens;
- 视频抽帧、动态帧率或 tubelet tokenization;
- 图像 token 压缩或只保留关键区域;
- 显式时间戳,让模型用文本式 timecode 理解长音视频;
- 分层记忆,把短期细节和长期摘要分开。
所以,多模态长上下文不是“上下文长度越大越好”。更准确的说法是:模型必须把有限 token 预算分给视觉细节、音频节奏、文本证据、历史对话和工具结果。
3. CoT:模型的中间草稿
CoT 可以先理解成模型解决复杂问题时的“中间草稿”。它把一步到位的回答拆成若干可检查的小步骤,例如列条件、做计算、比较方案、回头检查错误。
形式上,普通直接回答像:
1 | question -> answer |
CoT 式回答更像:
1 | question -> intermediate reasoning -> answer |
但这不意味着 CoT 是魔法。它更像给模型留出工作台:简单题不一定需要,复杂题、数学、代码、规划、多工具任务才更明显受益。工作台太小,模型没空间展开;工作台太大,又会增加延迟、成本,并可能产生看似有理但实际错误的长解释。
模型写出一段推理,不代表推理一定真实可靠。它可能先给出错误观察,再围绕错误观察组织一段流畅解释;也可能最终答案对了,但中间理由不严谨。工程上应把 CoT 看成一种推理过程信号和训练接口,而不是自动可信的证明。
4. Thinking Mode、Thinking Budget 与训练
近年的技术报告把 CoT 从 prompting 技巧推进到了模型训练和产品接口。Qwen3 的 thinking budget 图很适合建立直觉:思考 token 数变成一种可调资源,复杂任务可以多想,简单任务可以少想或不想。
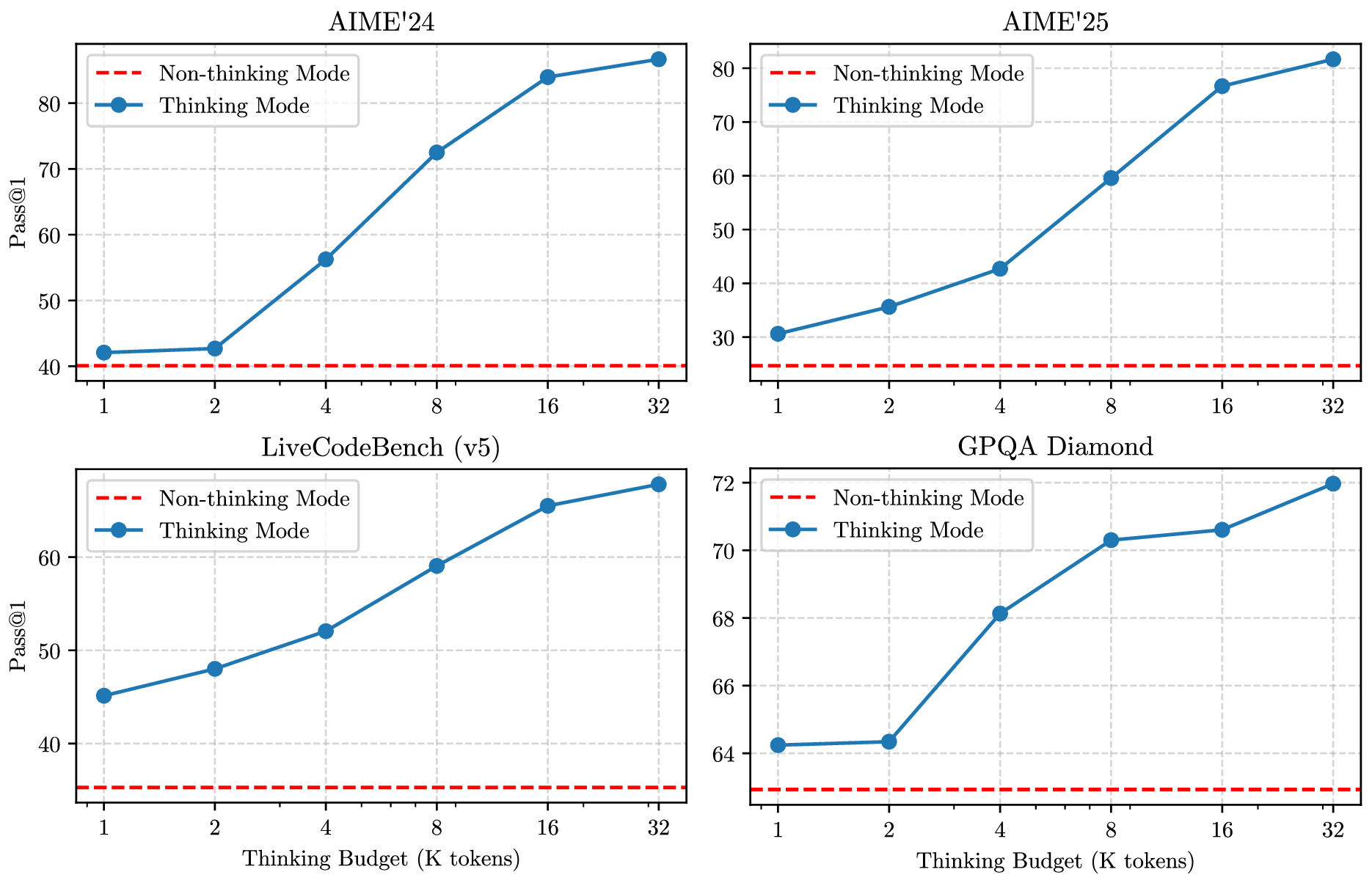
图源:Qwen3 Technical Report,Figure 2。原论文图意:Qwen3-235B-A22B 在数学、代码和 STEM 相关 benchmark 上,随着 thinking budget 增加,性能平滑提升。
Thinking budget 把“模型想多久”变成接口变量。它不是让模型永远长篇推理,而是允许系统按任务难度和延迟预算分配推理 token:普通问答直接答,复杂数学/代码给更多 thinking,工具任务则把部分预算留给调用和读取结果。
CoT 相关训练大致有四类信号:
| 信号 | 学到什么 | 典型用法 |
|---|---|---|
| Long-CoT SFT | 模仿高质量推理格式和步骤 | cold start、格式稳定 |
| RLVR / GRPO | 用可验证奖励筛选更有效推理轨迹 | 数学、代码、选择题、工具任务 |
| Rejection Sampling | 多采样后保留正确、清楚、稳定的样本 | 构造 SFT 或蒸馏数据 |
| Distillation | 把强模型推理能力压到小模型 | strong-to-weak、小模型部署 |
这解释了为什么 CoT 不只是 prompt 工程。模型需要在训练中见过可读推理、可验证任务、错误修正和预算控制,才能在推理时稳定使用这类行为。
5. CoT、工具调用和 ReAct 的关系
复杂任务经常不能只靠内部推理完成。模型可能需要查数据库、运行代码、访问网页、调用计算器或读取传感器结果。这时 CoT 负责“想清楚下一步”,工具负责“拿到外部证据或执行动作”。
一个典型工具任务流程是:
1 | 用户问题 |
这类流程常被称为 reason + act。它和普通 CoT 的区别是:中间步骤不只是在文字里想,还会改变外部状态或读取外部证据。工具调用场景里最重要的不是“推理写得长”,而是:
- 工具是否该调用;
- 参数是否正确;
- 返回结果是否被正确解释;
- 失败后是否能恢复;
- 最终回答是否保留证据链。
产品系统通常更适合暴露简洁解释、证据来源、关键步骤和可复核结果,而不是把完整内部草稿全部展示给用户。完整思考轨迹可以用于训练、调试或审计;面向用户时,更重要的是回答可靠、引用清楚、计算可复核、工具动作可追踪。
6. 多模态 CoT:先看清,再想清
多模态 CoT 的难点是:推理链的第一步常常不是数学推导,而是感知和定位。例如一张仪表盘照片里,模型要先识别指针位置、单位、警告灯,再判断设备状态;一段视频里,模型要先判断动作顺序、对象关系、时间点,再回答因果问题。
可以把多模态 CoT 拆成五步:
| 步骤 | 问题 | 常见失败 |
|---|---|---|
| 观察 | 图像/音频/视频里有什么 | 漏看小物体、OCR 错、听错词 |
| 定位 | 关键信息在哪里、何时出现 | 空间关系错、时间戳错 |
| 对齐 | 它和文本问题或历史上下文如何对应 | 把问题问的对象和图中对象混淆 |
| 推理 | 根据观察和背景知识推出结论 | 用常识补过头,忽略证据 |
| 回答 | 给出结论、证据或下一步动作 | 结论对但证据不清,或回答过度自信 |
一个简单例子:用户上传一张工厂面板照片,问“这台机器现在能不能启动”。模型不能只回答“可以/不可以”。更可靠的流程是:先读出急停按钮状态、压力表数值、报警灯、屏幕提示,再结合启动条件给结论。如果 OCR 或视觉识别错了,后面的 CoT 再漂亮也没用。
这也是多模态评测为什么不能只看最终答案。应同时检查:
- 模型是否看到了关键视觉/音频证据;
- 证据是否和问题对上;
- 推理是否依赖真实证据,而不是常识猜测;
- 不确定时是否会请求更多信息或工具验证。
7. 和世界模型、VLA 的接口
多模态和 CoT 再往前走,就会接到 VLA、agent 和世界模型。
| 方向 | 多模态提供什么 | CoT/Thinking 提供什么 |
|---|---|---|
| VLM | 图像、视频、文本对齐后的理解能力 | 复杂视觉问答和证据组织 |
| VLA | 视觉状态、语言目标、动作上下文 | 分解任务、选择动作、检查失败 |
| Agent | 工具返回、网页状态、文件内容 | 计划、调用工具、读取结果、恢复 |
| 世界模型 | 历史观测、动作、未来状态 token | 比较反事实、规划候选、解释风险 |
对于世界模型来说,多模态回答“当前世界是什么样”,CoT 回答“我应该如何分解目标、比较动作、解释风险”。但真正的世界模型还要更进一步:它必须能预测动作后的未来,而不只是解释当前画面。
8. 常见误区
8.1 把多模态等同于图片问答
图片问答只是入口。真实多模态还包括视频、音频、时间戳、传感器、工具结果、地图、代码执行输出和历史状态。越接近 agent 和具身系统,多模态越像状态融合问题,而不是单张图说明问题。
8.2 把 CoT 等同于“回答越长越聪明”
长 CoT 可能提升复杂任务,也可能只是增加废话和错误机会。更好的标准是:推理是否分解了关键约束,是否使用了证据,是否检查了错误,是否在预算内得到更可靠结果。
8.3 忽略 token 预算
多模态 token、thinking token、工具返回和历史对话共享同一个上下文窗口。一个系统若让视频帧、完整工具日志和长 CoT 同时无限增长,很快会遇到上下文成本、延迟和注意力稀释问题。
8.4 把可解释摘要当成完整内部状态
模型给出的解释是输出的一部分,不等同于模型内部真实计算过程。做严肃评测时,应结合任务结果、证据定位、工具轨迹、反事实测试和人审,而不是只看解释是否流畅。
9. 读相关论文时的检查清单
遇到多模态或 CoT 论文,可以按下面顺序读:
- 输入模态是什么,分别如何编码;
- 是否有统一 token 序列,还是 cross-attention / connector 接入;
- 训练目标是对齐、生成、分类、偏好、RL,还是多目标混合;
- CoT 是 prompt 诱导、SFT 学来、RL 激发,还是 teacher 蒸馏;
- 是否区分 thinking / non-thinking、是否有预算控制;
- 多模态证据是否可定位、可验证;
- 工具调用和外部证据是否进入训练和评测;
- 延迟、上下文长度和 token 成本是否被报告;
- 失败案例是否区分“看错了”和“想错了”。
一个总判断是:多模态先让模型看见更多世界,CoT 让模型有机会组织复杂问题,但二者都不是可靠性的替代品。真正可靠的系统还需要证据、工具、验证器、分桶评测、回放和失败回流。
- Title: 基础知识:多模态推理入门
- Author: Charles
- Created at : 2025-07-03 09:00:00
- Updated at : 2025-07-03 09:00:00
- Link: https://charles2530.github.io/2025/07/03/ai-files-foundations-multimodal-cot-and-reasoning-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.