
基础知识:Transformer、Tokenization 与注意力
Transformer 最容易被讲成一张架构图:左边 encoder,右边 decoder,中间有很多箭头。但真正决定模型如何工作的是一条更朴素的链路:
1 | 原始输入 -> token 序列 -> embedding + position -> Q/K/V -> mask 后的 attention -> FFN -> 下一层表示 |
这条链路适用于 LLM,也适用于 VLM、DiT、VLA 和世界模型。文本会被切成 subword token,图片会被切成 patch token,视频会变成时空 token,机器人策略还可能把状态、动作、相机视角和语言指令都塞进同一个序列。Transformer 的核心问题不是“图里有几个模块”,而是:每个 token 在每一层到底能读谁、读多少、读回来以后怎么改写自己。
读完这篇应该能回答四个问题:tokenizer 为什么会影响上下文和成本;Q/K/V 的公式怎样落到 shape;causal mask 与 KV cache 为什么是同一条生成链;为什么现代 Transformer 的改进经常落在位置机制、KV 存储、attention kernel 和 MoE 上。
Tokenization 先决定计算账本
模型不能直接处理“字符串”“图片”或“机器人轨迹”,它先要把输入切成离散或连续的 token。文本里的常见做法是 byte-level BPE、WordPiece 或 Unigram:先从字符、字节或基础子词开始,再用训练语料中的频繁片段合并出更长 token。Hugging Face 的 tokenizer 课程和 OpenAI 的 tiktoken 都在强调同一件事:tokenizer 不是排版工具,它决定模型实际看到的序列长度。
同一句话在不同 tokenizer 里可能有完全不同的 token 数。英文常见词可能被合成一个 token;中文、代码、罕见专名、空格和标点的切分会受词表与训练语料影响。token 数变多并不只是“上下文被占用”,它会直接进入 attention 的 成本、KV cache 显存和 serving batch 调度。
多模态模型里这个问题更明显。图片如果按 14x14 patch 切,224x224 图像就是 256 个视觉 token;4 路相机、16 帧视频就是 个视觉 token,还没加语言、状态和动作。把 patch 做小、帧数做多、动作频率做高,模型会获得更细粒度的证据,但 Transformer 要为每个 token 建立和其他 token 的关系。
进入模型后,token id 会先查 embedding 表:
这里 是第 个 token id, 是词表或 patch projection 给出的内容向量, 是位置相关的信息。注意这个公式的含义很具体:embedding 只告诉模型“这个位置是什么内容”,position 才告诉模型“它在序列里的哪里”。没有位置机制,两个 token 交换顺序后,纯 attention 很难知道谁先谁后。
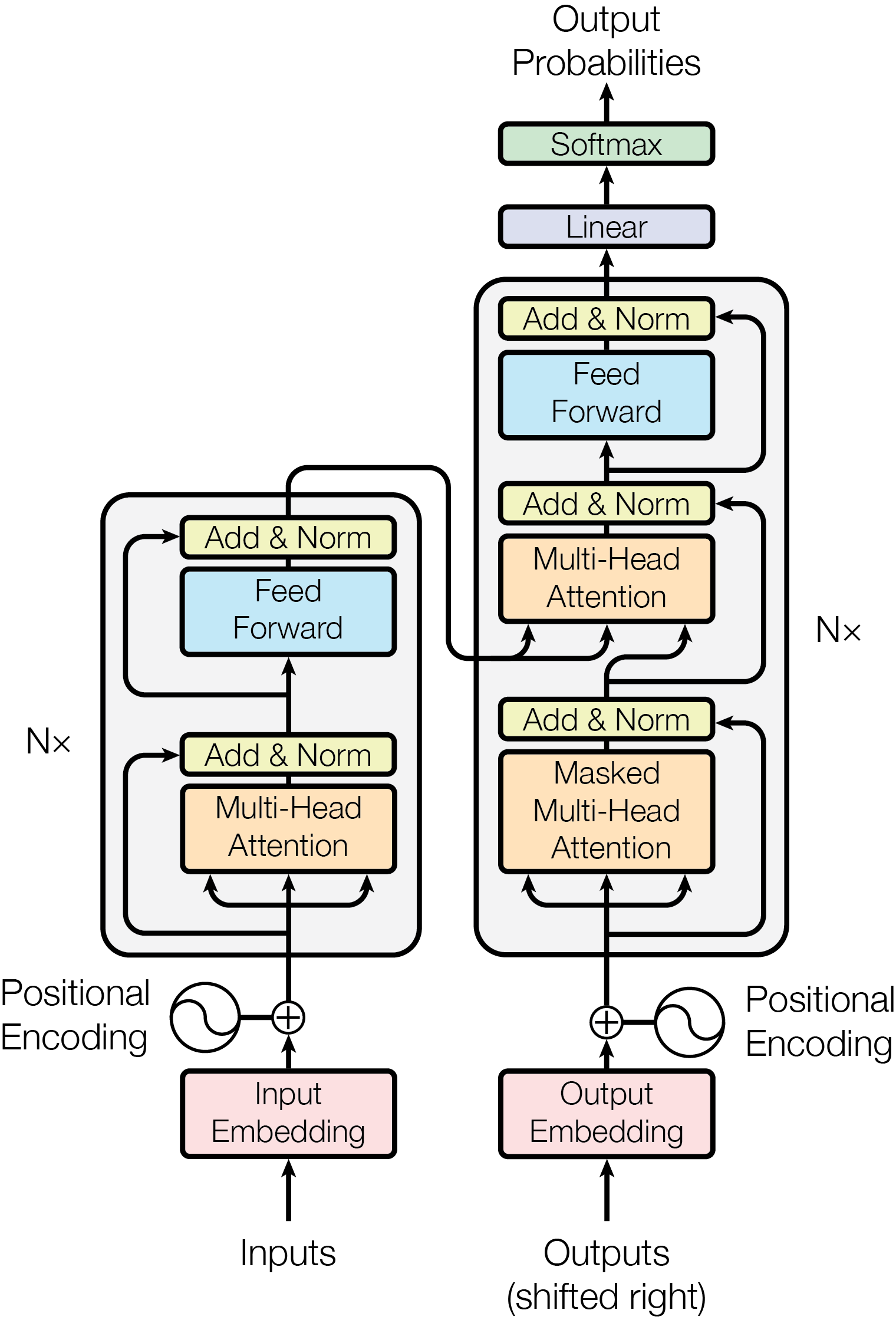 { width=“500” .atlas-figure-tall }
{ width=“500” .atlas-figure-tall }
图源:Attention Is All You Need,Figure 1。原图表达 encoder-decoder Transformer 的基本结构:embedding 与 positional encoding 进入多层 attention、feed-forward、残差和归一化模块。本站使用这张图时,先看输入如何变成 token 表示,再看 attention 如何跨 token 交换信息,最后看 FFN 如何逐 token 改写表示。
原论文图里的 encoder 更像“把输入序列读成一组可被查询的表示”,decoder 更像“在已生成前缀上继续预测下一个 token”。Decoder 里的 masked multi-head attention 是关键:生成第 个位置时,它只能看 到 的前缀,不能偷看未来答案。后面的 encoder-decoder attention 则让 decoder 用当前 query 去读取 encoder 输出的 key/value。
从 [B,L,D] 到 Q/K/V
假设一层 Transformer 收到的 hidden states 是:
是 batch size, 是 token 数, 是每个 token 的隐藏维度。注意这里的 不是原始 token id,而是上一层已经加工过的向量表示。
Attention 的第一步是用三组线性投影把同一个 变成 query、key、value:
如果只看单个 head,常见形状可以写成:
query 是当前位置发出的“我想找什么”,key 是每个位置暴露给别人匹配的“索引”,value 是真正被读走的“内容”。这三个名字不只是符号,读公式时要把它们当成一次信息检索:
会得到一个 的分数矩阵。第 行表示第 个 token 对所有 token 的匹配分数;第 列表示第 个 token 被别人读到的可能性。除以 是为了让点积尺度不要随着维度变大而过尖。 是 mask,可以把“不允许看的位置”加上很大的负数;softmax 后这些位置的权重接近 0。最后乘 ,就是把被允许、且匹配分数高的位置的信息加权读回来。
用一句话说:attention 不是直接判断答案,而是在每一层为每个 token 做一次带权限的加权检索。
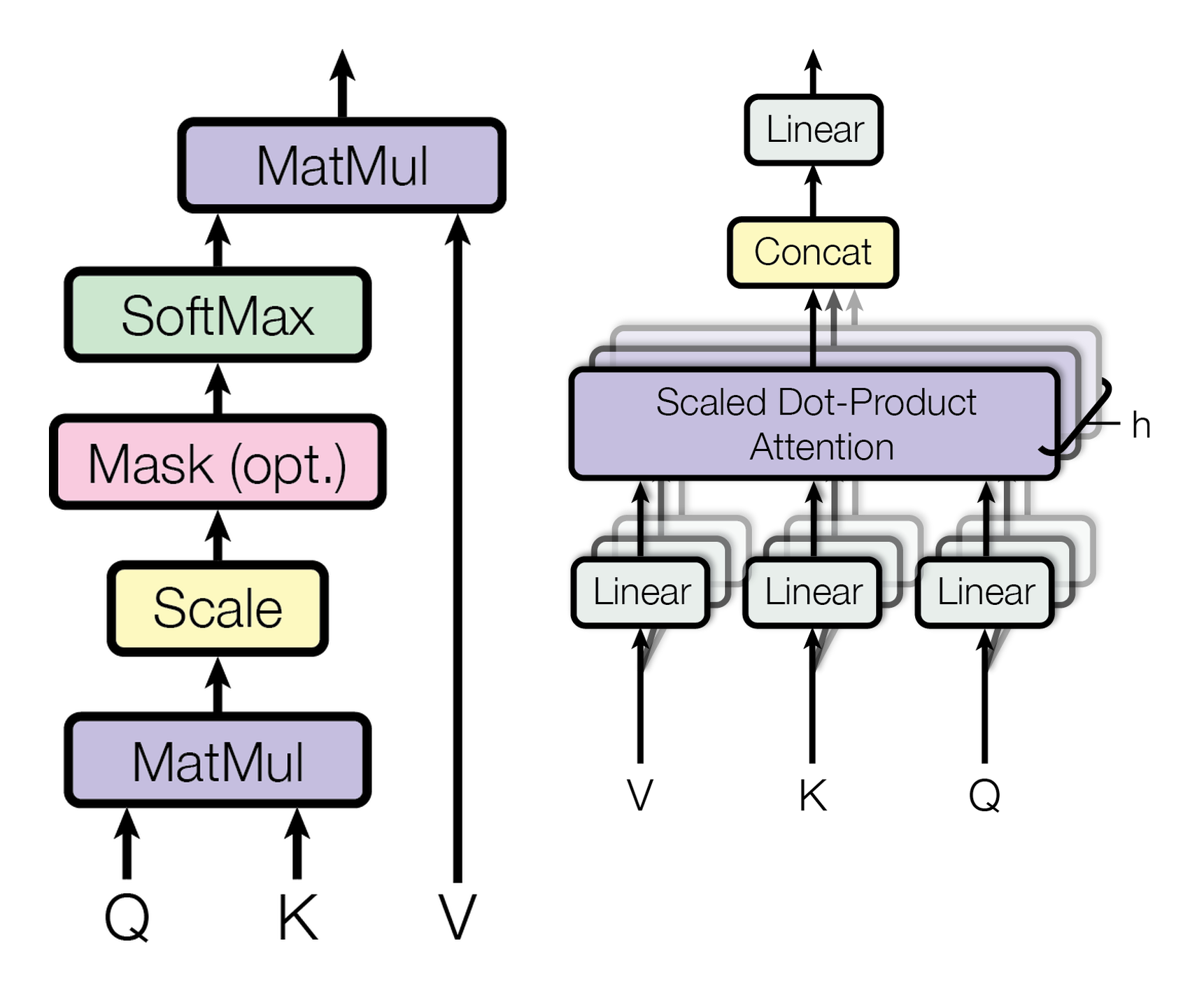
图源:Attention Is All You Need,Figure 2。原图表达 scaled dot-product attention 和 multi-head attention 的组成。本站使用它说明:单个 head 完成一次“匹配、归一化、读取”,multi-head 则并行使用多套投影,让同一批 token 可以从不同关系里读信息。
Multi-head attention 的意义不是“多几个可解释脑区”,而是让模型在同一层里并行学习多种关系。一个 head 可能偏向局部语法,一个 head 可能偏向长距离指代,一个 head 可能在 VLM 中把词语和视觉 patch 对齐。多个 head 的输出会拼接后再过线性层,合并成下一层的 token 表示。
把它放进一个具身任务里会更直观:“把桌边红色杯子拿起来。”语言 token 里的“杯子”需要和视觉 patch 中的杯身、杯沿、桌边建立关系;“拿起来”需要和夹爪状态、动作历史、目标位置建立关系;如果是自回归动作模型,当前动作 token 还只能看过去的视觉和动作,不能看未来动作。每层 attention 都在更新这些关系,而不是一次性给出最终动作。
Self-attention、cross-attention 与 concat tokens
Self-attention 指 都来自同一组 hidden states。LLM 读文本上下文、ViT 读一张图的 patch、视频 Transformer 读一段时空 token,都是这种结构。它的优点是统一:任何 token 都可以在 mask 允许的范围内读其他 token。代价也统一:序列越长,分数矩阵越大。
Cross-attention 指 来自主序列, 来自条件序列。扩散模型里,图像 latent 可以用 query 去读文本 prompt 的 key/value;encoder-decoder 翻译模型里,decoder token 也通过 cross-attention 读取 encoder 输出;Flamingo 这类多模态模型会让语言主干通过 gated cross-attention 读取视觉 token。
还有一种常见设计是 concat tokens:把文本、图像、动作、状态全部拼成一条长序列,再用 self-attention 和 mask 控制谁能看谁。很多 VLA、原生多模态模型、世界模型都会接近这条路。它实现简单,接口统一,但必须付出更高的 token 账本,因此常常需要视觉 resampler、action tokenizer、局部 attention 或 latent bottleneck。
1 | self-attention: |
这三种接口没有绝对高下。读论文时更应该问:信息在哪里被压缩?哪个模块承担跨模态对齐?mask 是否允许未来泄漏?长视觉或长视频 token 是否会把 serving 成本推爆?
Causal mask 把训练和生成连起来
自回归语言模型的训练目标通常是预测下一个 token:
这个公式说的是:整段序列概率被分解成每一步的条件概率。第 步只能依赖 之前的 token。Transformer 训练时虽然可以并行处理整段序列,但 causal mask 会让第 行的 attention 看不到 到 的位置,因此数学上仍然对应“只用前缀预测下一个 token”。
这也是 decoder-only LLM、动作 token VLA、一些视频 next-token world model 共享同一种骨架的原因。它们都在学一个条件分布:给定过去的文本、图像、状态或动作,预测下一个 token。区别在于 token 的来源、损失函数和输出空间,而不是“有没有 Transformer”。
训练和推理的差异也从这里出现。训练时一整段序列已知,可以一次性算出所有位置的 loss;推理时未来 token 不存在,模型只能一个 token 一个 token 地生成。这个差异会把 KV cache 推到系统中心。
KV cache 是生成链路的内存
生成第 个 token 时,前 个 token 的 已经算过。如果每一步都把完整前缀重新过一遍 Transformer,decode 会浪费大量计算。KV cache 的做法是:prefill 阶段把提示词的 K/V 算好并存起来,decode 阶段每来一个新 token,只计算它自己的 Q/K/V,再用新 Q 去读历史 K/V。
单层、单 batch 的 KV cache 大致可以按下面这项估算:
前面的 2 是 K 和 V 两份缓存, 是历史 token 数, 是 KV head 数, 是每个 head 的维度,bytes 是每个数值占多少字节。真实系统还要乘以层数、batch size,并考虑 allocator、block 管理、prefix 复用和并行切分。
这个公式解释了很多推理系统设计。GQA/MQA 通过减少 KV head 数降低缓存;KV quantization 用更少字节存历史;vLLM 的 PagedAttention 用分页式 block 管理动态增长的 KV cache,减少碎片和浪费;TensorRT-LLM 这类 runtime 会把 KV block pool、reuse、eviction、offload 和 attention window 变成可配置的服务策略。换句话说,KV cache 不是一个小优化,而是自回归 Transformer 能否高吞吐服务的核心数据结构。
为什么长上下文和多模态会贵
Self-attention 的分数矩阵是 。当 从 4k 到 32k,再到多相机视频的十几万 token,问题不是“多一点显存”这么简单,而是计算、内存访问、调度、cache 管理、通信都会一起变难。
继续看前面的机器人视频例子:4 路相机、16 帧、每帧 256 个视觉 token,会产生 16,384 个视觉 token。单个 head 的 attention score 元素数是:
如果把完整 score matrix 用 BF16 物化,只是这个中间矩阵就约 512 MiB;16 个 heads 就接近 8 GiB,还没算 Q/K/V、dropout、反向传播保存、FFN 激活、多层堆叠和 optimizer states。很多读者第一次看到长视频或机器人世界模型的 token 账本,会意识到“多模态大模型”不是把图片和文字拼起来这么简单。
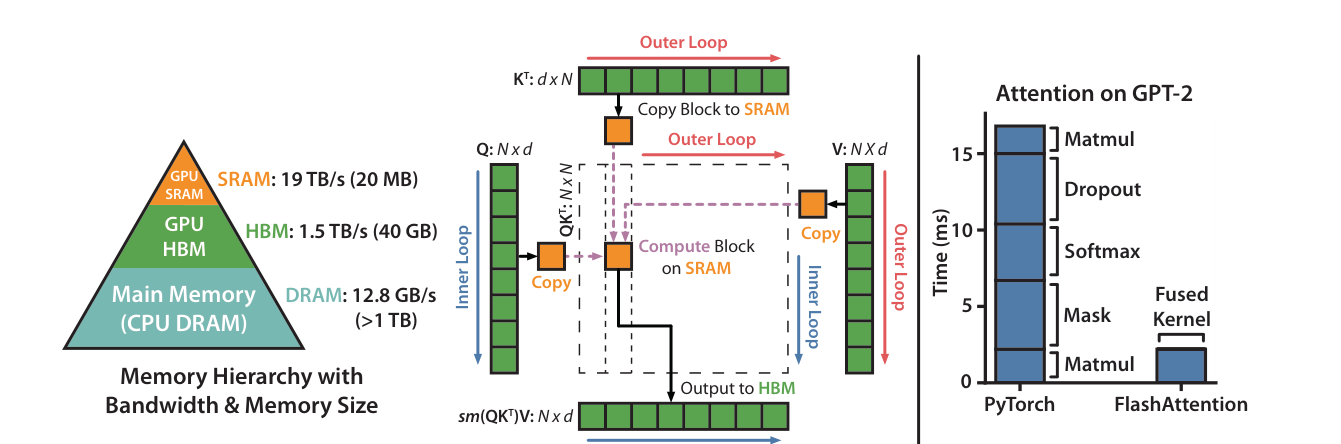
图源:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,Figure 1。原图表达朴素 attention 会反复在 HBM 中读写中间矩阵,而 FlashAttention 通过 tiling 与 online softmax 避免物化完整 attention matrix。本站使用它说明:同一个 attention 公式,在不同内存访问路径下会有完全不同的吞吐和显存占用。
FlashAttention 的关键不是把 attention 数学上变成线性,而是把原本巨大、低效的中间读写变成更接近硬件友好的分块计算。它仍然在算精确 attention,仍然要面对 token 增长带来的总体计算压力;但它减少了 HBM 往返和中间结果物化,所以训练和推理都能大幅受益。
这也解释了为什么长上下文论文、VLM/VLA 架构和推理 runtime 经常同时出现这些词:sliding window、local attention、block-sparse attention、resampler、KV eviction、prefix cache、PagedAttention、GQA/MQA、MLA。它们不只是“模型技巧”,而是在不同位置压缩同一张 token 账本。
现代 Transformer 改在哪里
原始 Transformer 的大结构很稳定:attention 做跨 token 信息路由,FFN 做逐 token 非线性变换,残差和归一化保证深层训练。但现代模型的关键变化往往不在课堂图的外壳上,而在四个位置。
第一,位置机制。绝对位置编码、RoPE、ALiBi、YaRN 等方法改变模型如何感知顺序、距离和长上下文外推。位置不是附属项,因为 attention 本身对顺序并不敏感。
第二,KV 存储。GQA、MQA、MLA、KV quantization 和 paged cache 都在减少历史 K/V 的显存和读写成本。只看参数量很容易低估推理瓶颈。
第三,attention kernel。FlashAttention、Triton attention backend、persistent kernels、context parallel 都在处理同一个现实:矩阵公式能不能高效落到 GPU 内存层级和通信拓扑上。
第四,FFN 与 MoE。很多大模型把 dense FFN 换成 routed experts,让每个 token 只激活一部分专家。这样能扩大总参数量,但也引入 router、负载均衡、专家并行和通信问题。
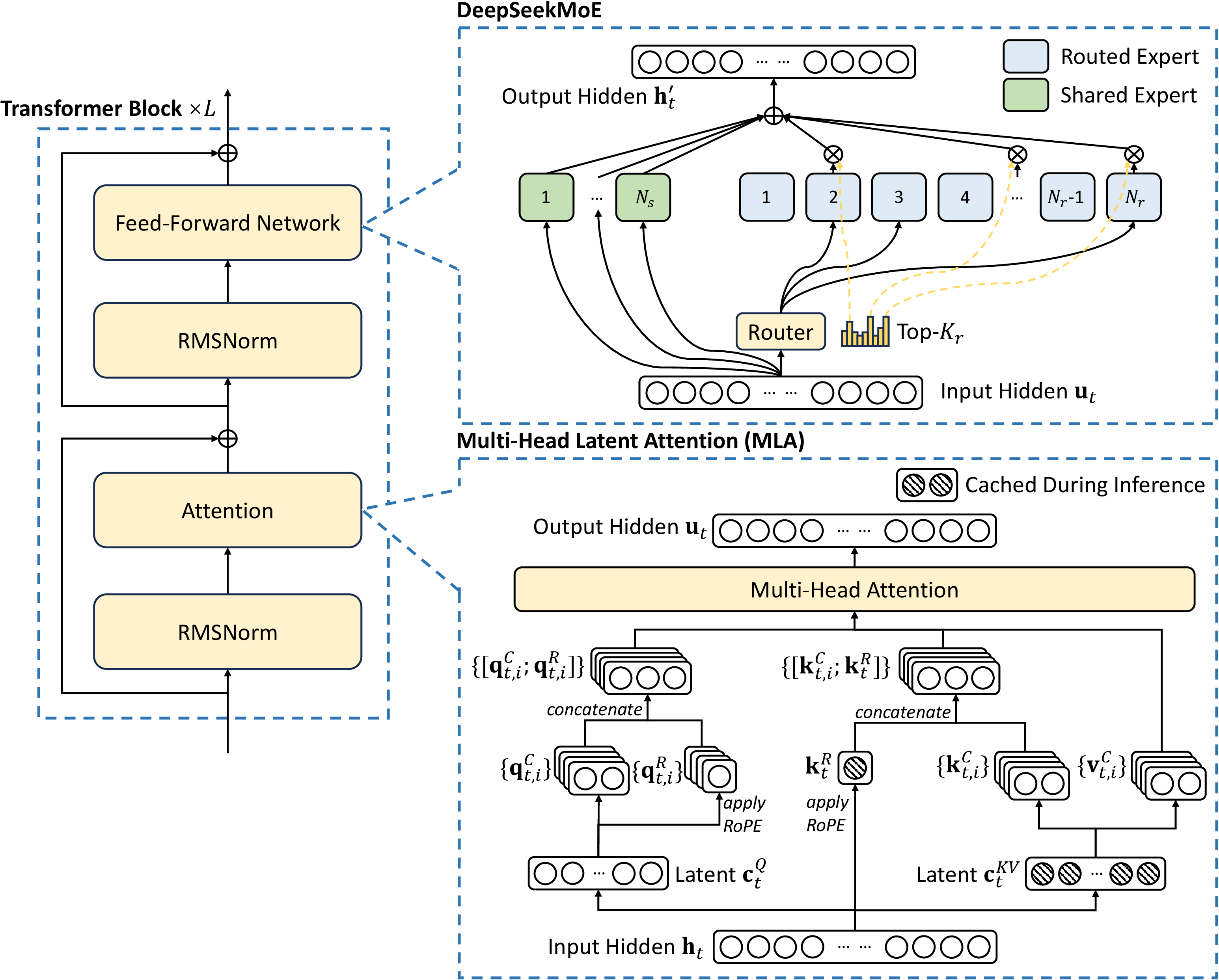
图源:DeepSeek-V3 Technical Report,Figure 2。原图表达 DeepSeek-V3 block 使用 MLA 压缩 KV cache,并用 shared experts 与 routed experts 构成 DeepSeekMoE。本站使用它说明:现代 Transformer 的改进常常同时发生在 attention 的历史存储与 FFN 的稀疏激活上。
读这种技术报告图时,不要只看“参数多少、上下文多长”。更有效的读法是跟着 token 走:它被切成什么粒度,位置怎么编码,它能 attend 到谁,历史 K/V 怎么保存,每层实际激活多少专家,专家之间的通信是否吃掉了稀疏计算的收益。
容易误读的地方
误解一:attention 权重就是解释。
Attention 权重只是某一层、某个 head 的信息路由。最终表示还会经过残差、归一化、FFN 和后续层改写。它可以提供线索,但不能直接等同于“模型为什么这么想”。
误解二:tokenizer 只是预处理。
Tokenizer 决定 ,而 同时进入 attention 计算、上下文窗口、KV cache 和 serving 调度。多语言、代码、长视频、机器人动作频率,都会通过 token 数改变系统成本。
误解三:FlashAttention 解决了长上下文。
FlashAttention 解决的是中间矩阵物化和内存 IO,不能取消长序列本身的计算。长上下文还需要位置外推、cache 管理、batch 调度、稀疏或分块机制。
误解四:多模态只是把图像 token 接到 LLM。
关键问题是视觉信息在哪里被压缩、语言 token 如何读取视觉证据、动作或状态如何进入序列、mask 是否符合因果关系、输出 token 能否被真实系统执行。
读完以后怎么判断
Transformer 的核心不是“某个模型架构名”,而是一种把世界切成 token、再让 token 互相读取信息的计算方式。tokenization 决定模型看到多少证据;位置机制告诉模型顺序和距离;attention 决定每个 token 能从哪里读信息;causal mask 把并行训练变成前缀预测;KV cache 把自回归生成变成可服务的系统;kernel、resampler、GQA/MQA/MLA、MoE 和 paged cache 则是在现实硬件上压缩这条链路的成本。
所以读任何 Transformer 系论文或报告时,可以先问六个具体问题:输入被切成什么 token;序列长度大概是多少;每类 token 能看谁;位置和时间如何编码;历史 K/V 如何保存和复用;哪些信息在 connector、resampler、latent bottleneck 或 expert routing 里被压缩了。问完这六件事,论文里的大部分结构图就不再只是模块堆叠。
外部精读
- The Illustrated Transformer:用可视化数据流建立 Transformer 第一层直觉,适合在看公式前阅读。
- The Annotated Transformer:把原论文公式和 PyTorch 实现逐段对应,适合检查自己是否真的理解了 shape。
- Attention Is All You Need:原论文仍然是 Figure 1、Figure 2、scaled dot-product attention 与 mask 机制的第一来源。
- Hugging Face NLP Course: Byte-Pair Encoding:清楚解释 BPE merge 如何从语料统计生成 subword token。
- OpenAI tiktoken:理解现代 byte-pair tokenizer 的工程接口,也可配合 token 计数工具看真实上下文成本。
- FlashAttention:理解 attention 为什么是内存系统问题,而不只是一个矩阵公式。
- vLLM PagedAttention blog:把 KV cache、分页管理和动态 serving batch 放到真实推理系统里看。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:Transformer、Tokenization 与注意力
- Author: Charles
- Created at : 2025-07-07 09:00:00
- Updated at : 2025-07-07 09:00:00
- Link: https://charles2530.github.io/2025/07/07/ai-files-foundations-transformer-attention-and-tokenization/
- License: This work is licensed under CC BY-NC-SA 4.0.