
推理:KV、缓存与投机解码:把贵模型用在值得的位置
这篇回答的问题。 如何理解“KV、缓存与投机解码”背后的核心机制、适用边界和下一步阅读路径。
缓存、路由和投机解码看起来是三类技术:缓存复用历史计算,路由选择请求路径,投机解码让便宜 draft 先猜、昂贵 target 再验证。但它们在服务系统里回答的是同一个问题:有限的 GPU 时间、KV 显存和强模型调用次数,应该花在哪些 token 和哪些请求上。
所以这页不按功能名分散介绍,而按一次请求的生命周期看:
1 | request |
prefill 主要受输入长度和前缀复用影响;decode 主要受输出长度、KV 读取和 target 步数影响;路由决定请求一开始走哪条成本曲线。三者一起看,才不会把某个平均 tokens/s 当成系统已经优化好。
KV cache 是执行状态,不是普通缓存
自回归模型每生成一个 token,都需要历史 token 的 key/value 来做注意力。KV cache 保存的是这些历史 K/V;没有它,每一步都要重算完整历史。有了它,decode 只追加新 token 的 K/V,再读取已有历史。
KV 显存可以粗略写成:
这里 2 表示 K 和 V 两份缓存, 是层数, 是活跃请求数, 是上下文长度, 是 KV head 数, 是每个 head 的维度, 是每个元素的字节数。读这行式子时,重点不是背符号,而是看到服务压力来自乘法关系:并发上去、上下文变长、输出变长、KV 精度更高,显存都会迅速变成主约束。
PagedAttention 的关键,是把每条请求逻辑上连续的 KV 序列切成固定大小 block,用 block table 映射到物理 block。请求继续生成时追加 block,请求结束时释放 block;有共享前缀时,某些 block 还可以复用。
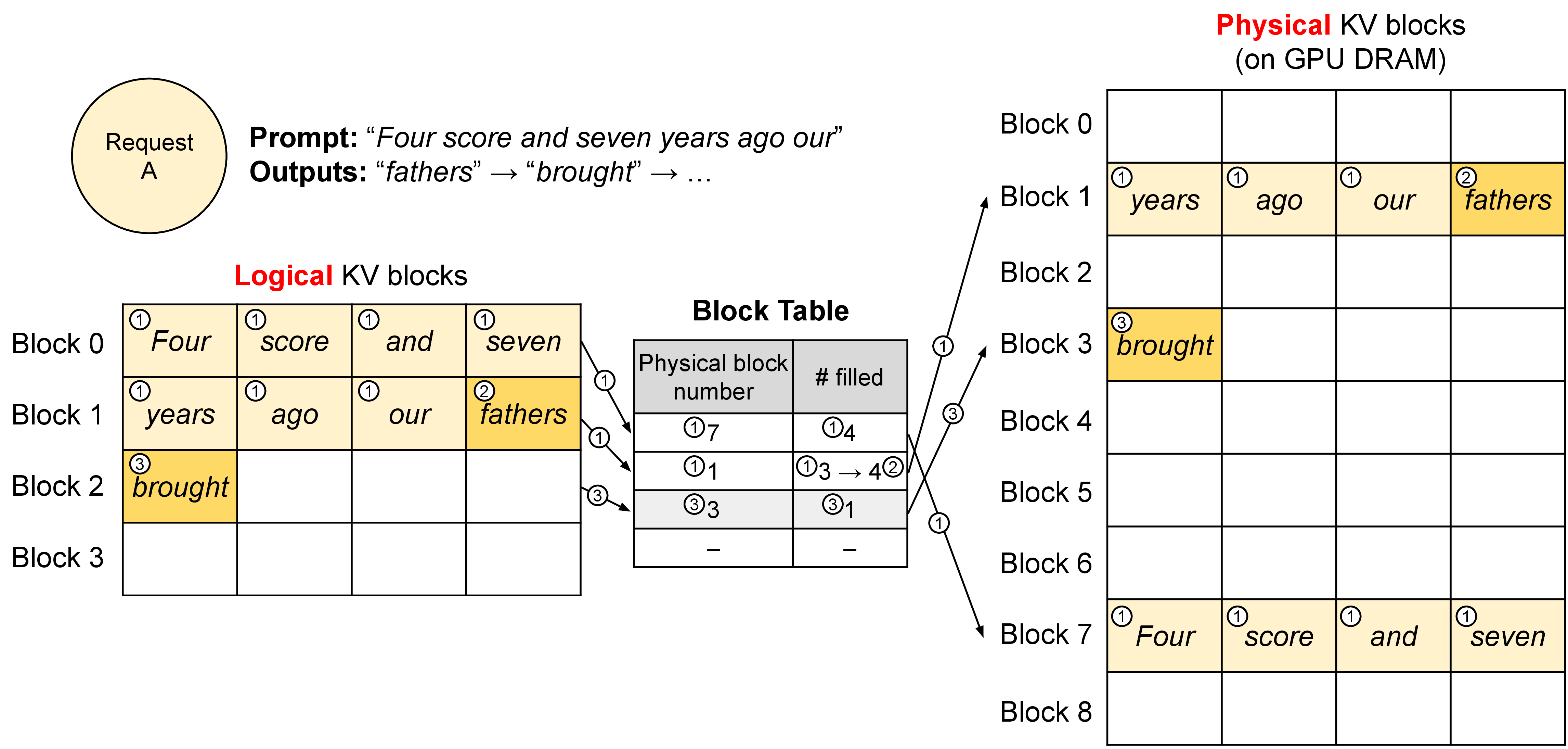
图源:Efficient Memory Management for Large Language Model Serving with PagedAttention,Figure 5。原图表达 logical KV blocks 如何映射到 physical KV blocks。这里用它说明:PagedAttention 主要解决的是动态请求长度导致的 KV 分配、碎片和共享问题,不是改变 attention 数学。
它的收益通常出现在高并发、长度分布很散、请求持续进出的 workload 上。它不能减少模型权重,不能消除长上下文 KV 读取,也不能自动修好所有 P99。如果瓶颈来自 prefill 算子、工具调用、低 acceptance 投机解码或网络通信,KV 分页只能解决其中一部分。
Prefix cache 要靠稳定前缀赚钱
Prefix cache 复用的是请求开头相同的一段 token:系统 prompt、工具 schema、固定模板、共享政策文本、同一 RAG 文档前缀。它省的是重复 prefill。
一个简单成本账是:
是命中率, 是可复用前缀长度, 是请求数。这行式子提醒你:命中率高但前缀很短,收益仍然有限;前缀很长但模板里混进时间戳、随机 ID、用户私有字段,命中率会被切碎。
Prefix cache 不是 runtime 私活,它也要求 prompt 组织配合。公共系统 prompt、工具 schema、共享文档应该尽量放在请求前部,并避免把用户私有内容插入公共前缀中间。多租户场景还要把权限边界写进 cache key,不能因为复用前缀把一个用户的上下文暴露给另一个用户。
路由是在选成本曲线
路由不是“小模型先答,大模型兜底”这么简单。它是在质量、成本、延迟和风险之间为每个请求选路径。
这行式子说的是:候选路径 可以是不同模型、服务池、上下文策略或工具链;请求 不同,质量和风险也不同。路由器要用业务权重 做取舍。低成本、低延迟、高质量、低风险不可能总是同时最大化。
常见路由维度包括长度、任务、风险、置信度、租户和 SLA。长文档请求不该挤占短问答池;高风险请求可能要强模型、工具校验和审计;低置信请求要升级或重试;高价值租户可能需要独立容量。路由上线的验收不是“小模型占比提高”,而是每个请求桶的质量、延迟、成本、升级率和回退率都可解释。
RouteLLM 这类工作适合用来理解路由问题的边界:路由器要在 cheaper model 和 stronger model 之间判断哪些请求值得升级。真正上线时,还要把缓存命中、SLO、工具链和安全风险纳入同一张决策表。
投机解码是 draft 提议,target 裁决
普通 decode 是目标模型逐步生成。投机解码增加一条便宜路径:
1 | draft 猜多个 token -> target 并行验证 -> 接受连续通过的前缀 -> target 修正第一个失败点 |
经典 speculative decoding 的关键不是让小模型替代大模型,而是让 target model 仍然决定最终分布。只要接受/拒绝规则按目标模型分布设计,输出可以保持 target 原分布;速度来自一次 target forward 并行验证多个候选,而不是放弃 target。
一个粗略速度账是:
是平均每轮接受 token 数。它越大,一次 target 验证换来的 token 越多;如果 acceptance 低,系统会额外付 draft、tree mask、verify、分支 KV 和回滚成本,P99 甚至可能变差。
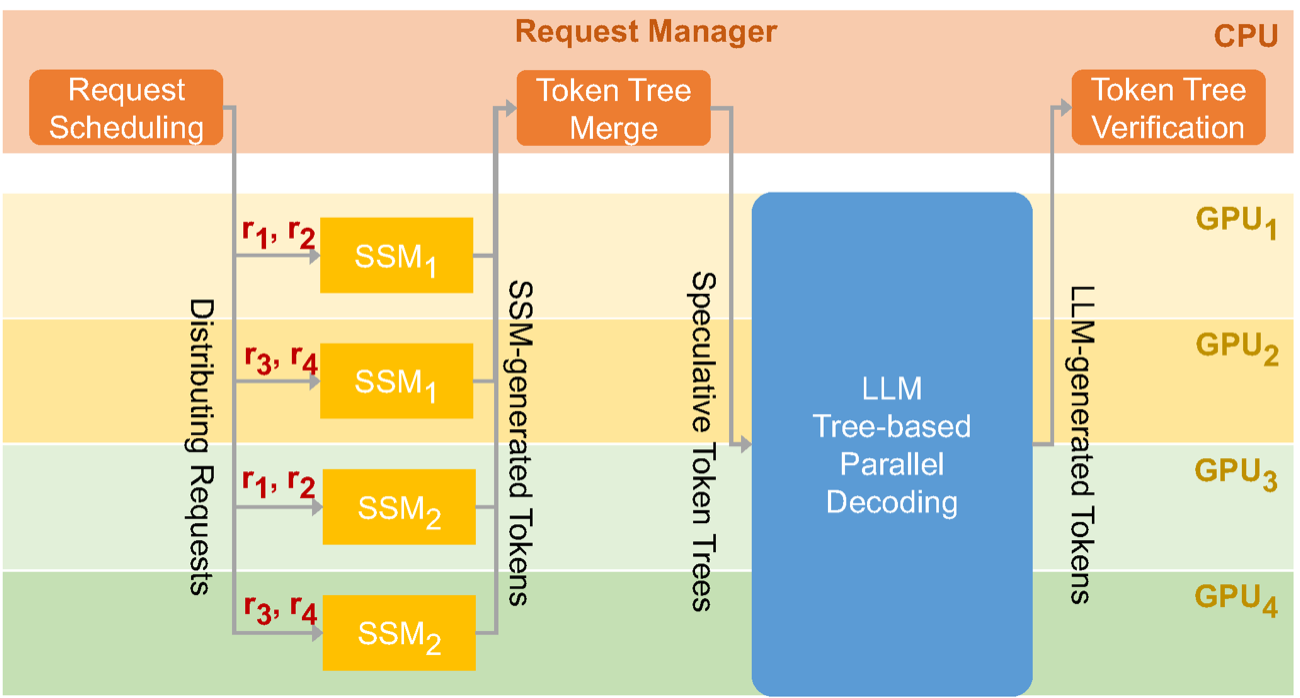
图源:SpecInfer,Figure 1。原图展示 draft 模型生成 token tree,target LLM 用 tree verification 并行验证候选。这里用它说明:投机解码真正省时间的是被 target 连续接受的前缀,不是 draft 生成越多越好。
上线投机解码时,不能用全局开关。低温短回答、格式化输出、代码补全可能 acceptance 高;高温创意写作、多工具 agent、长链推理或频繁改写上下文时 acceptance 可能低。每个请求桶都要看 accepted length、reject rate、verify time、rollback、P95/P99 和质量回归。
EAGLE 的启发:draft 预算要给更可能被接受的位置
EAGLE 系列把投机解码的重点从“找一个更小的 draft LLM”推进到“怎样产生更容易被 target 接受的候选”。EAGLE 用 target feature 做 draft;EAGLE-2 按 confidence 动态扩展 draft tree;EAGLE-3 处理训练时和测试时递归 draft 分布不一致的问题。
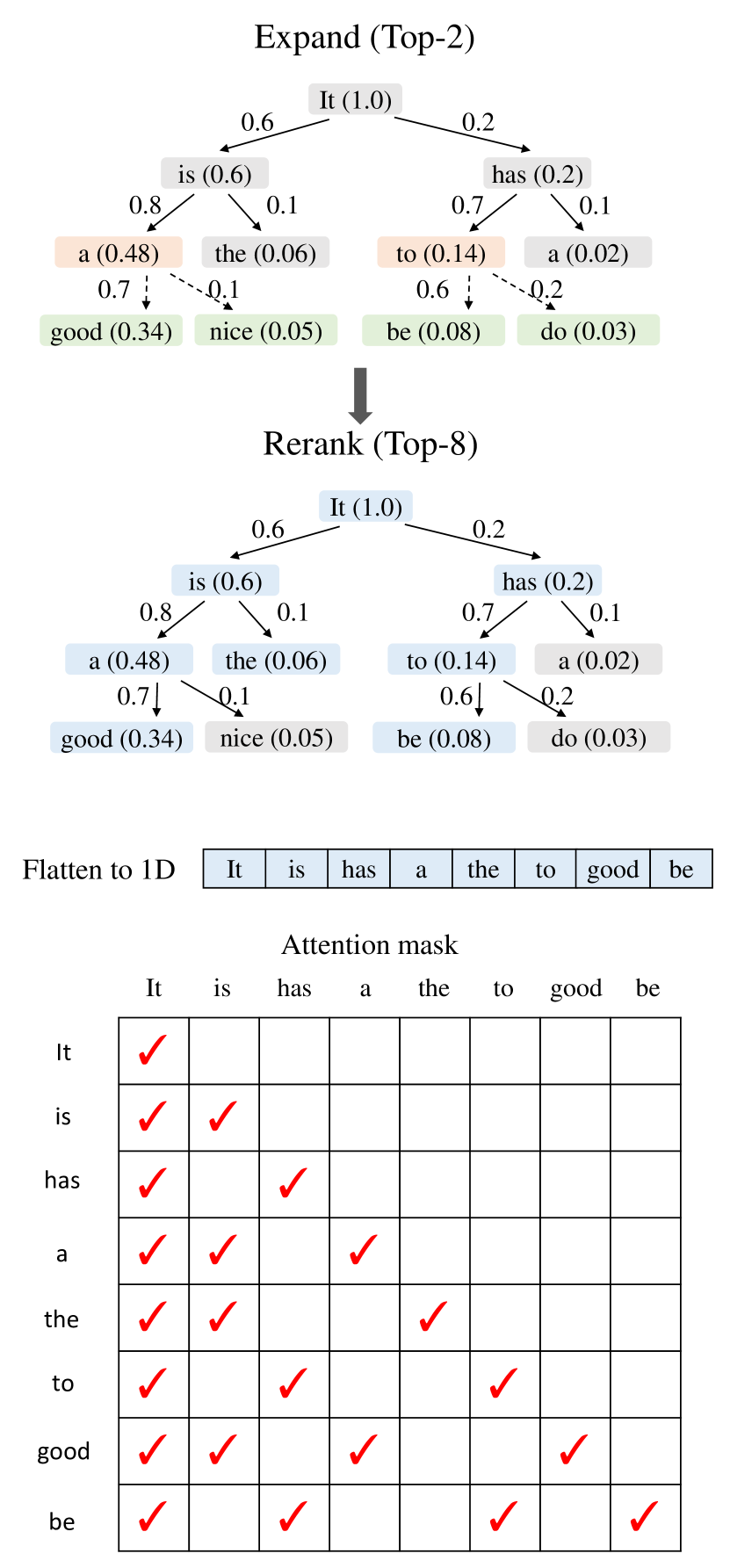
图源:EAGLE-2,Figure 7。原图表达根据 confidence 和节点 value 动态扩展 draft tree,再用 tree attention mask 验证候选。这里用它说明:投机预算应该给更可能被接受的位置,而不是平均撒给所有分支。
这对工程配置很重要。draft 很便宜但总猜错,不如稍贵但 acceptance 更高;固定 draft 长度可能在简单请求上浪费,也可能在难请求上放大回滚。投机解码的核心指标是“target 每次验证平均接受多少有用 token”,不是 draft 自己每秒能吐多少 token。
三者会互相影响
缓存、路由和投机解码都在改变请求生命周期,因此不能分别报平均收益。
| 组合 | 可能收益 | 可能代价 |
|---|---|---|
| routing + prefix cache | 相似请求进同池,公共前缀更稳定 | 路由太碎会造成资源碎片 |
| KV cache + speculative | 长输出且高 acceptance 时 TPOT 降低 | draft 分支增加临时 KV 和回滚复杂度 |
| routing + speculative | 只给高 acceptance 桶开投机 | acceptance 预测错会放大 P99 |
| cache + RAG | 重复检索和共享文档前缀更便宜 | 证据过期或权限污染 |
| KV eviction + routing | 长任务放专门池,保护短任务 | 淘汰错误会让多轮任务失忆 |
一个常见事故是:上线投机解码后平均 TPOT 下降,但 P99 变差。普通问答 acceptance 高,拉低平均值;创意写作和多工具 agent acceptance 低,承担了 draft、verify、回滚和更长 KV 生命周期。正确修复通常不是全局关闭投机,而是按任务、温度、输出长度和工具状态预测 acceptance,低 acceptance 桶降级或关闭。
验收按请求桶拆
| 机制 | 至少记录 |
|---|---|
| Prefix cache | hit rate、saved prefill tokens、miss penalty、tenant boundary |
| KV cache | KV GiB、page usage、fragmentation、eviction、branch count |
| Routing | route distribution、upgrade rate、fallback rate、per-route quality |
| Speculative decoding | accepted length、rejected tokens、verify time、rollback |
| End-to-end | TTFT、TPOT、P95/P99、cost/request、quality regression |
短问答、长文档、长输出、agent、多模态、高温采样、结构化输出,应该分别看。缓存、路由和投机解码的成熟形态,是按 workload 分桶打开和关闭,而不是作为全站统一开关。
外部精读
- vLLM / PagedAttention:理解 KV cache 为什么需要分页式管理。
- PagedAttention paper:用论文证据理解 block table、KV memory waste 和 serving throughput。
- Fast Inference from Transformers via Speculative Decoding:理解 draft-verify 如何保持 target distribution。
- SpecInfer:理解 token tree verification。
- vLLM speculative decoding blog:学习按 draft、acceptance、QPS 和 workload 组织工程评测。
- EAGLE、EAGLE-2 与 EAGLE-3:理解 feature-level draft、dynamic draft tree 和 training-time test。
- RouteLLM:理解模型路由如何在成本和质量之间做请求级选择。
相关阅读与下一步
- 外部材料:vLLM PagedAttention 博客。
- 外部材料:TensorRT-LLM KV Cache System。
- 外部材料:SGLang 文档。
- 站内下一步:推理系统专题。
- 站内下一步:推理运行时。
- 站内下一步:缓存、路由与投机解码。
- Title: 推理:KV、缓存与投机解码:把贵模型用在值得的位置
- Author: Charles
- Created at : 2025-07-08 09:00:00
- Updated at : 2025-07-08 09:00:00
- Link: https://charles2530.github.io/2025/07/08/ai-files-inference-caching-routing-and-speculative/
- License: This work is licensed under CC BY-NC-SA 4.0.