
推理:运行时:按请求生命周期选择 vLLM、SGLang 与 TensorRT-LLM
推理运行时不是“把模型权重加载起来”的薄壳。它真正负责的是一条在线生产线:请求进入队列,prompt 做 prefill,随后逐 token decode,KV cache 随输出增长,batch 每一步都在变化,最后结果以 streaming 或一次性响应返回给应用。
同一份权重换一个 serving runtime 后,吞吐、首 token 延迟、尾延迟和显存占用可能完全不同。差异通常不在参数本身,而在 runtime 怎样处理四件事:
- KV cache 的分配、复用、驱逐和释放;
- prefill 与 decode 的调度,以及不同长度请求的 batch 组织;
- prefix、工具调用、JSON 约束、并行采样这类 workload 结构;
- attention backend、量化 kernel、多 GPU 通信和硬件执行路径。
因此,不要先问“vLLM、SGLang、TensorRT-LLM 谁更快”。更好的问题是:你的请求主要卡在 prefill、decode、共享前缀、结构化生成,还是硬件 kernel。
从一条请求开始看 runtime
一条 LLM 请求可以拆成四段:
| 阶段 | Runtime 在做什么 | 常见瓶颈 |
|---|---|---|
| 入队与调度 | 接收请求、检查限流、选择进入 prefill 还是等待 | 排队时间、优先级、SLO |
| prefill | 读完整 prompt,一次性为每层生成首批 KV cache | 长 prompt 的 dense compute、prompt packing |
| decode | 每步生成一个新 token,读取历史 KV 并追加新 KV | KV cache 带宽、batch 动态变化、inter-token latency |
| 返回与清理 | streaming 返回、释放或保留 cache、记录指标 | cache reuse、尾延迟、观测口径 |
prefill 更像大块矩阵计算。prompt 越长,Q/K/V projection、attention 和 MLP 的矩阵规模越大,GPU 更容易被算力吃满。decode 的形态不同:每个请求每步只新算一个 token,但它要反复读取已有 KV cache。输出越长,历史 KV 越长;并发越高,runtime 越需要在显存容量、内存带宽、batch 大小和排队时间之间取舍。
KV cache 的容量可以先用一个成本账估算:
这里 是并发序列数, 是每条序列保留的 token 数, 是 key 和 value 两份缓存, 是层数, 是 KV head 数, 是 head 维度, 是每个元素的字节数。GQA/MQA 会减少 ,FP8/INT8 KV cache 会减少 ,长上下文和长输出会直接增加 。这就是为什么 serving runtime 的中心难题不是“能不能 forward”,而是“不同长度、不同到达时间、不同共享结构的请求能不能一起高效 forward”。
vLLM:把动态请求变成可分页的 KV 工作流
vLLM 的代表性贡献是 PagedAttention。它把 KV cache 拆成 block,并用 block table 把逻辑 token 位置映射到物理 block。这样每个请求不需要预留一整段连续显存,请求变长时追加 block,请求结束时释放 block,某些场景下还可以共享 prompt 对应的 block。
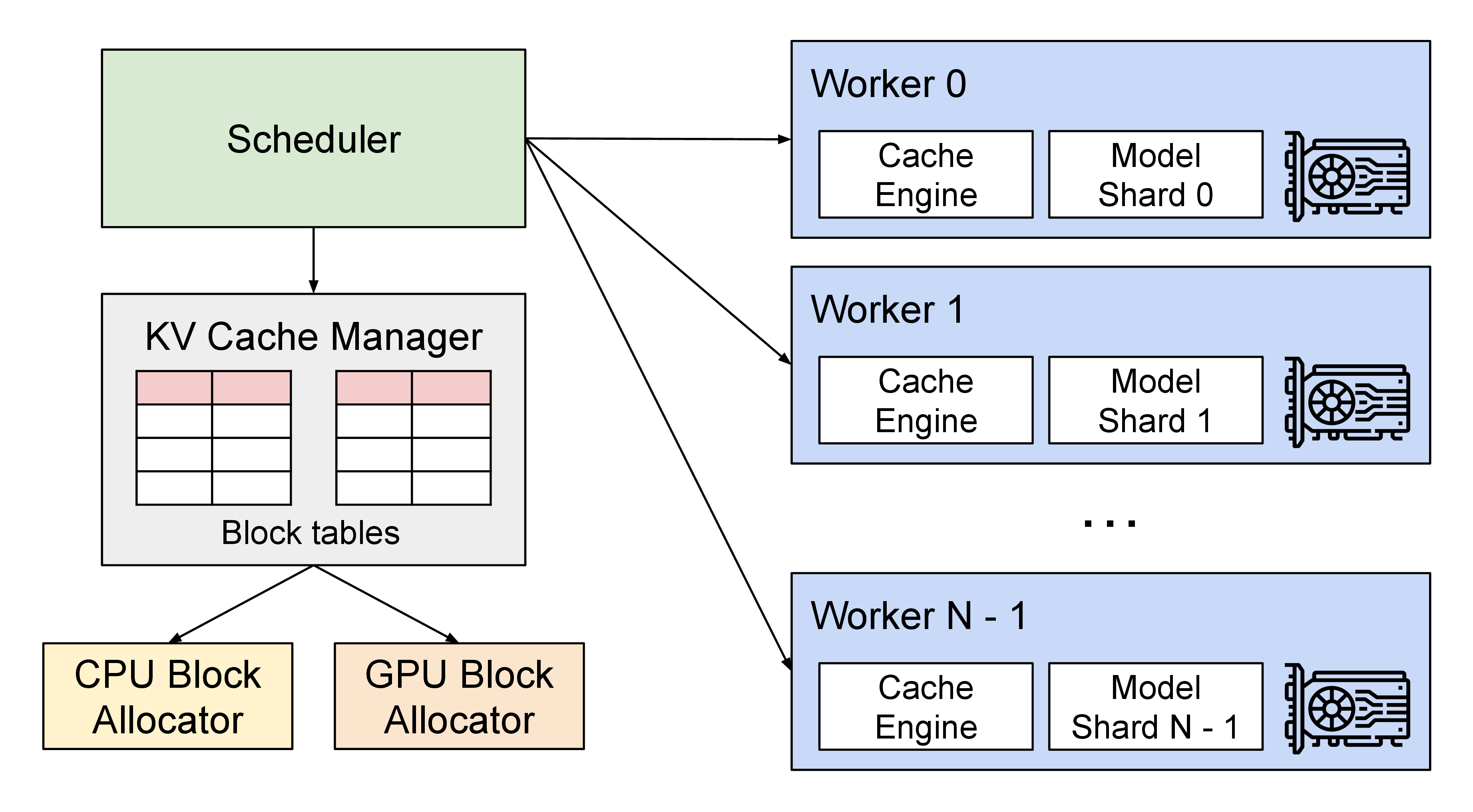
图源:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention。图中把请求调度、KV block 管理和模型执行放在同一个系统里。本站复用仓库已有图片,用它说明 runtime 的核心是请求、缓存和调度的组合。
读 vLLM 时先看两个层面。第一层是 KV 内存管理:PagedAttention 让逻辑上连续的 token 序列可以落到非连续物理 block 中,从而减少碎片和过度预留。第二层是调度:continuous batching 让已完成的请求离开 batch,新请求尽快加入 batch,而不是等一整批请求同时结束。
vLLM 尤其适合从“高并发通用 serving”入门:OpenAI-compatible API、batch 调度、PagedAttention、prefix caching、speculative decoding、量化和分布式部署都已经形成文档入口。它的优势在 KV cache 动态管理和通用部署生态;它的风险是 benchmark 很容易被 workload 设定误读。长 prompt + 短输出主要看 prefill 与 TTFT,短 prompt + 长输出主要看 decode 与 KV 带宽,共享系统提示词多时要单独看 prefix cache 命中。
所以,vLLM 不是“永远最快”的代名词。它更像一个默认强基线:当你还不知道生产流量会长成什么样,先用 vLLM 把请求生命周期、显存账和 tail latency 量出来,通常比直接手写 serving 更稳。
SGLang:让 runtime 看见生成程序结构
SGLang 的出发点是复杂 LLM 应用本身就是程序。一个 agent 请求可能包含系统提示词、工具说明、检索片段、并行候选、函数调用、JSON 约束、失败 retry 和多轮状态。把这些内容都压成一条普通字符串,runtime 就看不见其中的共享前缀、分支和约束。
SGLang 论文把系统分成 frontend language 和 runtime。Frontend 让开发者表达 generation、parallelism 和控制流;runtime 用 RadixAttention 做 KV cache reuse,并用压缩状态机加速结构化输出解码。这里的关键不是多一个 API 语法,而是 runtime 能把“生成程序的结构”变成调度和缓存信号。
这种视角对几类流量很有价值:
| 流量形态 | SGLang 能利用的结构 |
|---|---|
| 多轮 agent | 系统 prompt、工具说明和历史状态有共享前缀 |
| few-shot / RAG | 模板、示例和检索片段常出现重复或局部重复 |
| 并行候选 / self-consistency | 分叉前的 prompt KV 可以复用,分叉后分别 decode |
| JSON / grammar 输出 | 约束解码可以放到 runtime 里统一处理 |
| 多阶段任务 | 生成、校验、调用工具和继续生成形成程序流 |
如果你的服务主要是一次性短问答,SGLang 的程序化接口未必是第一优先级。如果你的服务有大量共享 prompt、工具调用、结构化输出、多分支采样或 agent workflow,SGLang 的优势会更容易显出来。评价它时不要只看 tokens/s,要看 prefix hit rate、分支复用、约束解码开销和失败 retry 成本。
TensorRT-LLM:把模型图和 cache 系统压到 NVIDIA 执行路径
TensorRT-LLM 更靠近 NVIDIA GPU 上的 engine、kernel 和部署优化。它关心的不只是“请求怎么排队”,还包括 fused kernel、attention backend、in-flight batching、paged attention、chunked prefill、FP8/INT8/INT4、multi-GPU parallelism、CUDA graph、benchmark 工具和在线服务入口。
这里的“快”通常来自一组硬件友好的共同设计。低比特权重如果没有合适 kernel,可能省显存但不省延迟;FP8 KV cache 可以降低 cache bytes,但要看模型精度、scale、GQA/MQA、attention window 和硬件支持;in-flight batching 可以提高 decode 阶段的 GPU 利用率,但会改变首 token 延迟和 P99。
TensorRT-LLM 的 KV cache 文档尤其值得读,因为它把 cache 写成一个系统:block pool 按需分配,radix tree 支持跨请求复用,eviction/offload 管理显存压力,retention policy 调整不同 token 范围的保留优先级,GQA/MQA 和 attention window 会改变 cache 成本。这个文档提醒我们:生产 serving 不是一个 kernel benchmark,而是一套 cache policy、scheduler、dtype、硬件和观测指标的组合。
TensorRT-LLM 的适用场景通常更明确:NVIDIA 生产部署、固定硬件、明确 SLO、需要低比特或多 GPU 优化,并且团队愿意处理 engine 构建、版本矩阵和调参成本。它不一定是研究试验最快上手的选择,但在硬件路径明确时,它给了更多贴近底层的控制面。
不按框架名选,按瓶颈选
下面这张表比“谁更快”的排行榜更实用:
| 你观察到的现象 | 先检查 | 更可能优先看的 runtime |
|---|---|---|
| 并发稍高就 OOM,短请求也占很多显存 | KV block、碎片、max model len、prefix cache | vLLM |
| 首 token 很慢,输出很短 | prefill tokens/s、chunked prefill、prompt packing | vLLM、TensorRT-LLM |
| 输出很长,单步 token 延迟抖动 | decode batch、KV bandwidth、block usage、attention window | vLLM、TensorRT-LLM |
| 大量请求共享系统 prompt 或工具说明 | prefix hit rate、cache key、模板一致性 | SGLang、vLLM、TensorRT-LLM |
| agent、工具调用、JSON 约束很多 | 分支复用、constraint overhead、retry 成本 | SGLang |
| 硬件固定在 NVIDIA,目标是压低 P95/P99 | engine build、kernel、量化、multi-GPU、benchmark | TensorRT-LLM |
| 团队要快速验证模型和产品形态 | API 兼容性、部署复杂度、观测指标 | vLLM、SGLang |
很多生产系统也不是单选。一个团队可能用 vLLM 服务通用 chat,用 SGLang 服务复杂 agent workflow,用 TensorRT-LLM 服务固定模型的高性能生产路径。真正影响成本的是每条链路的瓶颈是否被正确定位,而不是 runtime 名字是否统一。
Benchmark 要写成请求生命周期报告
推理 benchmark 至少要写清这些条件:模型大小、GPU 型号、prompt 长度分布、输出长度分布、并发数、batch 策略、是否 streaming、是否 prefix cache、是否 speculative decoding、是否量化、是否多 GPU、SLO 是平均延迟还是 P95/P99。
更好的报告方式是按生命周期拆指标:
| 场景 | 主要风险 | 应该一起报告的指标 |
|---|---|---|
| 长 prompt + 短输出 | prefill 变成首 token 瓶颈 | TTFT、prefill tokens/s、prompt length bucket |
| 短 prompt + 长输出 | decode 和 KV 带宽吃紧 | inter-token latency、decode tokens/s、KV block usage |
| 高并发在线服务 | 平均值掩盖排队和尾延迟 | queue wait、P95/P99、SLO violation |
| 共享前缀很多 | benchmark 命中率高但线上模板不一致 | prefix hit rate、cache key miss reason、TTFT 降幅 |
| 结构化输出和工具调用 | 约束解码或 retry 抵消吞吐收益 | constraint overhead、failure retry、end-to-end success latency |
| 低比特和多 GPU | kernel 或通信把理论收益吃掉 | quality regression、kernel fallback、GPU utilization、communication time |
这也是为什么单个 tokens/s 数字经常误导。吞吐上去了,用户可能因为排队更久而感觉更慢;平均延迟好看,P99 可能被少数长 prompt 拖死;prefix cache 在 benchmark 里命中率很高,真实流量里可能因为模板空格、工具顺序或租户隔离而失效。
实战判断
选 runtime 时可以按这个顺序做:
- 先画请求分布:prompt 长度、输出长度、并发、共享前缀、结构化输出比例、工具调用比例。
- 再做成本账:权重显存、KV cache 显存、prefill compute、decode bandwidth、通信和临时 buffer。
- 然后选基线:通用 serving 先用 vLLM,复杂生成程序先看 SGLang,NVIDIA 硬件生产压榨先看 TensorRT-LLM。
- 最后做线上观测:TTFT、inter-token latency、queue wait、prefix hit rate、KV block usage、P95/P99 和质量回归要放在同一张表里。
把 vLLM、SGLang 和 TensorRT-LLM 放到一起看,区别可以压缩成一句话:vLLM 先把动态 KV cache 管成可分页工作流,SGLang 让 runtime 看见复杂生成程序,TensorRT-LLM 把模型图、cache policy 和 kernel 压到 NVIDIA 硬件友好的执行路径。读懂推理运行时,就是读懂这三条路分别省了哪张账,又把成本转移到了哪里。
外部精读
- vLLM PagedAttention blog:理解 KV block、block table、内存碎片、continuous batching 和 parallel sampling cache sharing。
- PagedAttention paper:核对 vLLM 的论文表述、系统目标和 benchmark 边界。
- vLLM documentation:核对当前 serving、prefix caching、structured outputs、speculative decoding、量化和部署入口。
- SGLang paper:理解 structured language model programs、RadixAttention 和压缩状态机。
- SGLang documentation:核对生产 serving、OpenAI-compatible API、prefix caching、多硬件和部署入口。
- TensorRT-LLM documentation:理解 NVIDIA 上的 engine、online serving、feature matrix、量化、parallelism 和 benchmark 工具。
- TensorRT-LLM KV Cache System:理解 block pool、reuse、eviction、offload、retention policy、GQA/MQA 和 cache salting。
- Hugging Face Text Generation Inference:对照另一个成熟 serving 栈,也注意官方文档对维护状态和下游 runtime 的说明。
- Orca:理解 iteration-level scheduling 为什么是大模型 serving 的系统背景。
相关阅读与下一步
- 外部材料:vLLM PagedAttention 博客。
- 外部材料:TensorRT-LLM KV Cache System。
- 外部材料:SGLang 文档。
- 站内下一步:推理系统专题。
- 站内下一步:推理运行时。
- 站内下一步:缓存、路由与投机解码。
- Title: 推理:运行时:按请求生命周期选择 vLLM、SGLang 与 TensorRT-LLM
- Author: Charles
- Created at : 2025-07-24 09:00:00
- Updated at : 2025-07-24 09:00:00
- Link: https://charles2530.github.io/2025/07/24/ai-files-inference-serving-runtimes-vllm-sglang-and-tensorrt-llm/
- License: This work is licensed under CC BY-NC-SA 4.0.