
推理:服务系统:快模型为什么上线后仍然慢
离线测一个模型,常见做法是加载权重、喂 prompt、看 tokens/s。真正上线后,用户看到的不是这一个数字,而是一条请求链:排队、鉴权、路由、prefill、KV cache 分配、decode 循环、采样、detokenize、安全检查、工具调用、流式返回、日志追踪。任何一段慢,都会把“模型很快”变成“服务很慢”。
这页只抓一个问题:同一份模型权重,为什么单请求 benchmark 看起来快,线上用户仍然觉得慢。
先把一次请求拆成状态机,而不是一次 generate():
1 | client |
推理服务优化的核心,不是追一个最高 tokens/s,而是让不同类型请求在各自 SLO 内稳定完成。
用户体感慢,先拆成三张账
LLM 服务里最容易混淆的是“模型速度”和“用户等待”。用户通常感受到三种时间:
| 账 | 用户看到什么 | 常见瓶颈 |
|---|---|---|
| TTFT | 第一个 token 迟迟不出来 | queue、prompt 太长、prefill、首轮 decode |
| TPOT | 流式输出一顿一顿 | decode batch、KV 访存、采样、后处理 |
| E2E latency | 整个任务完成慢 | 多轮工具、RAG、路由、fallback、安全检查 |
可以把 TTFT 简化写成:
这里 表示进入 GPU 前的排队时间, 表示处理完整输入上下文的时间, 表示第一次生成新 token 的时间。
稳定输出阶段可以看 TPOT:
这里 表示整个 decode 阶段耗时, 表示输出 token 数。TTFT 好,不代表长回答流畅;TPOT 好,也不代表用户能很快看到首 token。聊天产品常盯 TTFT,代码补全更怕 TPOT 波动,agent 工作流还要看任务完成时间和每成功任务成本。
Prefill 和 Decode 是两种工作
LLM 推理可以先粗分为 prefill 和 decode。
1 | prefill: 读完整 prompt,一次性生成 prompt token 的 KV cache |
prefill 更像大块并行计算。输入越长,attention、MLP 和 KV 写入都变多。长文档问答、RAG、会议纪要、多模态上下文,经常慢在第一个 token 前面。
decode 更像一个持续循环。每次只生成一个 token,却要在每层读取历史 KV,跑 attention 和 MLP,采样下一个 token,再把新 KV 追加回 cache。短 prompt 长输出、代码续写、创作型回答,经常慢在这个循环里。
| 请求类型 | 容易慢在哪里 | 先看什么 |
|---|---|---|
| 短聊天 | queue、batch wait、首步 decode | P95 TTFT、admission、batch window |
| 长文档问答 | prefill、prefix cache、上下文裁剪 | prompt tokens、prefill tokens/s、prefix hit |
| 长输出生成 | decode、KV 生命周期、采样 | TPOT、decode batch、输出长度 |
| Agent / 工具链 | 多轮调用、共享前缀、外部工具 | trace waterfall、tool latency、cache reuse |
这也是为什么 prefill / decode disaggregation 会出现。DistServe 这类系统把 prefill worker 和 decode worker 分开调度,是因为两段资源画像不同:prefill 更吃大块算力,decode 更吃 KV、显存、带宽和循环调度。这个设计适合规模和 SLO 都比较清楚的服务;小规模单机部署可能被 KV 传递、网络和调度复杂度抵消收益。
KV Cache 才是隐藏容量上限
KV cache 保存每层 attention 的 key 和 value。没有 KV cache,decode 每生成一个 token 都要重算全部历史;用了 KV cache,历史不用重算,但显存会随着并发、上下文长度和输出长度增长。
KV cache 的数量级可以这样估算:
这里 表示 key 和 value 两份缓存, 表示层数, 表示活跃请求数, 表示每个请求当前缓存 token 数, 表示 KV head 数, 表示 head 维度, 表示每个元素的字节数。
例如 32 层、batch 4、context 32k、8 个 KV heads、head dim 128、BF16:
这行式子表示:仅 KV cache 就可能占掉十几 GiB。若 KV heads 从 8 变 32,显存大约再乘 4;若 context 从 32k 变 128k,也大约再乘 4。很多“支持 128k 上下文”的模型,上线后会被 batch、KV 精度、GQA/MQA、prefix cache、eviction 和 SLO 重新限制。
PagedAttention 把 KV 管成块表
vLLM 的 PagedAttention 把 KV cache 切成 block,用 block table 把逻辑 token 位置映射到物理 block,思路接近操作系统里的分页内存。它解决的不是“模型算子本身变快”,而是动态请求长度下 KV 预留、碎片和共享的问题。
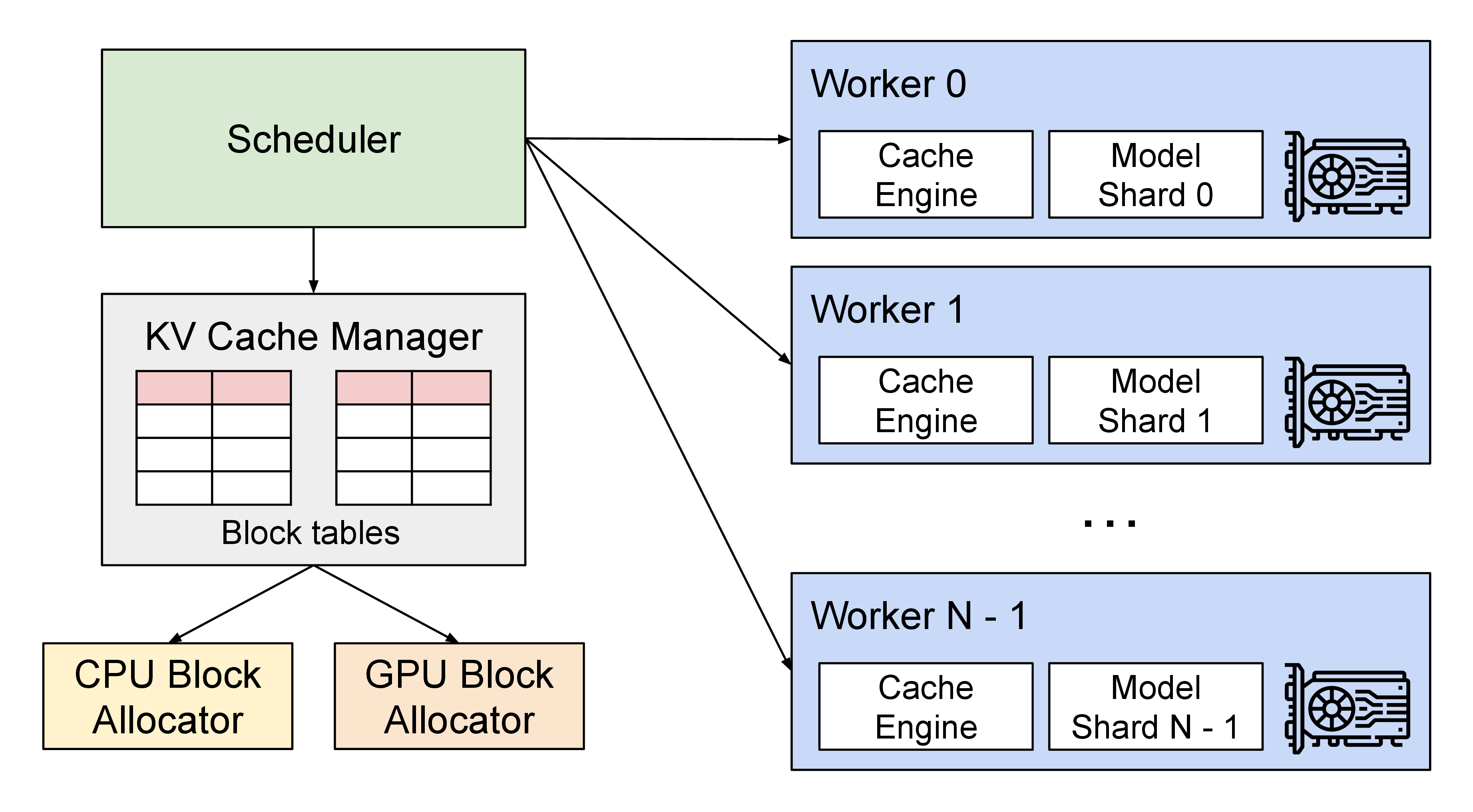
图源:vLLM PagedAttention blog。本站用这张图说明 scheduler、KV cache manager、CPU/GPU block allocator 和 worker 的关系;没有用 image2 或其他生成式工具作图。
读这张图时,先看三件事。第一,请求不是直接进入模型 worker,而是先被 scheduler 管理。第二,KV cache manager 和 block allocator 决定 GPU 显存怎样被分配、复用和释放。第三,worker 的吞吐和尾延迟取决于调度、KV 分配和 batch 形态,而不只取决于模型权重。
传统做法如果按最大上下文给每个请求预留 KV,短请求会浪费显存;如果临时扩容,又容易碎片化或搬移。PagedAttention 让请求需要多长就追加多少 block,请求结束就释放 block,共享前缀时还可以复用 block。这样 continuous batching 才有空间发挥:完成的请求可以从 batch 移走,新请求可以加入,GPU 不必等所有序列同长。
但 PagedAttention 不是万能按钮。长 prompt 短输出主要痛在 prefill;短 prompt 长输出更容易痛在 decode 和 KV 带宽;agent 请求可能痛在共享前缀、分支、工具链和多轮 trace。读 vLLM benchmark 时,必须看 prompt/output 长度分布,而不是只看平均 tokens/s。
Continuous Batching 是吞吐和尾延迟的交换
静态 batch 要等一批请求凑齐再跑。continuous batching 允许 decode 每一步动态加入和移除请求:
这里 表示当前 decode batch, 表示这一轮已经完成的请求, 表示新加入的请求。这个公式想表达 iteration-level scheduling:生成式模型的 batch 在每个 decode step 都可能变化。
它的好处是 GPU 不容易空转,整体吞吐上升。代价是调度更复杂,batch window、优先级、输入长度和输出长度会互相影响。一个常见故障是:把 batch window 拉大后,tokens/s 提升,短问答 TTFT P95 反而变差。原因不是模型变慢了,而是短请求为了合批在 queue 里等得更久。
Orca 的 iteration-level scheduling、vLLM 的 continuous batching、TensorRT-LLM 的 in-flight batching,本质上都在处理同一个事实:生成式请求不是一次固定 batch 的矩阵乘,而是一条每一步都在变化的流。
路由、缓存和投机解码不要混成一个优化词
生产系统通常不该让所有请求走同一条路。闲聊、长文档、代码补全、多模态、工具 agent、高风险任务,对质量、延迟和成本的要求不同。
路由可以抽象成:
这里 表示选中的模型或服务链路, 表示候选集合, 表示请求特征, 表示成本、延迟和质量的权重。这个公式不是让线上一定用线性打分,而是提醒:路由必须同时考虑任务类型、输入长度、输出长度、风险、缓存命中和 SLO。
缓存也要分层看。Prompt cache / prefix cache 主要省重复输入的 prefill;KV block reuse 主要省显存分配和重复前缀;工具缓存主要省外部调用;RAG 缓存可能省检索,也可能伤新鲜度。把这些都叫 cache,会让排障变得很钝。
Speculative decoding 又是另一张账。它让 draft model 先猜多个 token,再由 target model 验证,命中时减少 target decode step。它适合 target decode 是瓶颈、draft 足够便宜且接受率高的场景。长 prompt 的 prefill 不会因为 draft 变快;结构化输出、低温采样、代码、工具调用和长上下文也会改变接受率。读 EAGLE、SpecInfer 或 vLLM speculative decoding 文档时,要看 draft 开销、接受率、target 验证开销和端到端 SLO。
最小观测闭环:不要只看平均 tokens/s
推理优化最怕“平均值看起来不错”。最小观测集应该按请求生命周期记录。
| 类别 | 必看指标 |
|---|---|
| 请求形态 | 输入长度、输出长度、任务类型、模型路由 |
| 队列 | queue time、admission reject、priority、batch wait |
| prefill | prefill time、prefill tokens/s、prefix hit rate |
| decode | TPOT、decode batch、tokens/s、sampling config |
| KV | KV GiB、block usage、eviction、fragmentation、prefix reuse |
| 尾延迟 | P50/P95/P99 TTFT、TPOT、end-to-end latency |
| 质量 | 任务成功率、引用正确率、格式错误、fallback |
| 成本 | 每请求成本、每 token 成本、每成功任务成本 |
如果没有这些 trace,优化动作会互相打架:batch window 提升吞吐但伤 TTFT;压上下文省 prefill 但伤回答质量;低比特 KV 省显存但引入长上下文退化;路由省钱但让困难任务失败;投机解码提高 tokens/s 但对端到端 agent 任务没有收益。
排查慢请求时按这组问题走
第一,慢的是 TTFT、TPOT 还是 E2E?不要先说“模型慢”。
第二,请求桶是什么?短聊天、长文档、长输出、代码、agent、多模态、高风险任务,不该混在一个平均数里。
第三,队列里等了多久?如果 queue time 高,先看 admission、batch window、优先级和容量,而不是先换 kernel。
第四,prefill 是否占主导?如果是,先看上下文长度、prefix hit、chunked prefill、上下文裁剪和 prefill 池。
第五,decode 是否占主导?如果是,先看 KV cache、decode batch、attention backend、采样配置、投机解码和输出长度策略。
第六,端到端慢是否来自模型外部?RAG、工具、格式修复、安全检查、网络和客户端 streaming 都可能让 GPU 指标看起来很好、用户体验仍然很差。
最后判断
推理服务系统的核心不是“哪个 runtime 最快”,而是一次请求在队列、prefill、KV cache、decode、采样、后处理和工具链中怎样流动。prefill 决定首 token 前的成本,decode 决定流式生成节奏,KV cache 决定并发和长上下文上限,batching 决定吞吐和尾延迟的取舍,路由决定不同任务是否走对链路。
真正能落地的优化,通常不是一个开关,而是一张账单:这次改动省了 queue、prefill、KV、decode、工具链还是人工成本?又把成本转移到了质量、尾延迟、显存、工程复杂度还是可观测性上?把这张账拆清楚,推理服务才从黑箱变成可以改的系统。
外部精读
- vLLM PagedAttention blog:理解 KV cache 分页、block table 和 continuous batching。
- vLLM paper:理解 PagedAttention 在论文里的内存管理和吞吐证据。
- Orca OSDI paper:理解 iteration-level scheduling 为什么适合生成式模型。
- DistServe paper:理解 prefill / decode disaggregation 和 goodput-oriented serving。
- Hugging Face: Assisted Generation:理解 speculative decoding 的 draft / verify / acceptance 直觉。
- Hugging Face Text Generation Inference:看成熟 LLM serving 栈的部署入口和功能边界。
- SGLang documentation:理解复杂生成程序、prefix reuse 和 RadixAttention。
- TensorRT-LLM KV Cache System:看 block pool、reuse、offload、eviction 与 GQA/MQA 等生产 KV 机制。
- NVIDIA Dynamo documentation:理解现代推理服务里 disaggregated serving、routing 和 KV-aware 调度的系统方向。
- NVIDIA Inference Optimization blog:补充 batching、quantization、KV cache 和 speculative decoding 的工程视角。
- 智源转载:全栈 Transformer 推理优化:学习中文长文如何按模型、算子、显存、调度和工程分层讲推理优化。
- 中国信通院:大模型推理优化关键技术与应用实践研究报告(2026):看产业报告如何组织模型压缩、PD 分离、KV 多级存储和服务调度。
相关阅读与下一步
- 外部材料:vLLM PagedAttention 博客。
- 外部材料:TensorRT-LLM KV Cache System。
- 外部材料:SGLang 文档。
- 站内下一步:推理系统专题。
- 站内下一步:推理运行时。
- 站内下一步:缓存、路由与投机解码。
- Title: 推理:服务系统:快模型为什么上线后仍然慢
- Author: Charles
- Created at : 2025-07-25 09:00:00
- Updated at : 2025-07-25 09:00:00
- Link: https://charles2530.github.io/2025/07/25/ai-files-inference-serving-systems/
- License: This work is licensed under CC BY-NC-SA 4.0.