
论文专题讲解:CausVid:流式自回归视频扩散
- 论文:
From Slow Bidirectional to Fast Autoregressive Video Diffusion Models - 系统:
CausVid - 链接:arXiv:2412.07772
- 版本:2024-12-10 首次提交,2025-09-23 更新到 v4
- 会议:CVPR 2025
- 项目页:CausVid
- 代码:GitHub
- 关键词:视频扩散、DiT、因果注意力、KV cache、DMD、few-step distillation、streaming generation
这篇论文的核心价值在于给出了一条很清楚的工程路线:不要从零训练一个自回归视频模型,而是把已有高质量双向视频 DiT 改造成因果学生模型,再用双向教师做非对称 DMD 蒸馏,把 50 步视频扩散压成 4 步流式生成器。
如果说 Diffusion Forcing 重点回答“序列扩散应该怎样表达不同时间 token 的不确定性”,CausVid 更进一步回答:“怎样把这种因果序列扩散真正做成低延迟视频生成系统”。
它的效率贡献是什么
| 维度 | 贡献 |
|---|---|
| 节省的成本 | 把多步双向视频扩散压成少步 causal streaming 生成,主要节省 rollout 推理延迟和长视频生成成本 |
| 核心机制 | 双向 teacher 提供视频质量,causal student 满足流式依赖,KV cache 降低自回归 rollout 成本,DMD 蒸馏减少采样步数 |
| 对世界模型主线的意义 | 交互式世界模型不能等完整视频离线生成;CausVid 展示了视频扩散如何被改造成可流式、可缓存、低延迟的 rollout 模块 |
| 主要风险 | causal student 会面对误差累积和 chunk discontinuity;若缺少动作条件和闭环评测,它仍可能只是流式视频生成器,不一定是可决策世界模型 |
| 应接到本站哪里 | 世界模型高效训练技术路线图、动作条件视频世界模型端到端训练案例、推理成本建模 |
论文位置
当前强视频扩散模型大多是 bidirectional video diffusion:模型在生成当前帧时会看整段视频 token,包括未来帧。这对离线生成很好,因为全局注意力能提高一致性;但对交互式应用很糟,因为用户必须等整段视频生成完,不能边生成边看,也不能在中途改变输入。
CausVid 的目标不是单纯提高 VBench 分数,而是改变视频扩散的系统形态:
| Dimension | Bidirectional video diffusion | CausVid |
|---|---|---|
| Attention dependency | current chunk can attend to future chunks | current chunk only attends to previous chunks and itself |
| Generation mode | fixed clip, wait for full video | streaming chunks, watch as generated |
| Latency | entire video must finish first | first chunk after about 1.3s |
| Sampling steps | many-step teacher, 50 steps in paper description | few-step causal student, 4 steps |
| Long video | expensive full-sequence or sliding windows | autoregressive rollout with KV cache |
| Main risk | high latency, fixed horizon | error accumulation and chunk discontinuity |
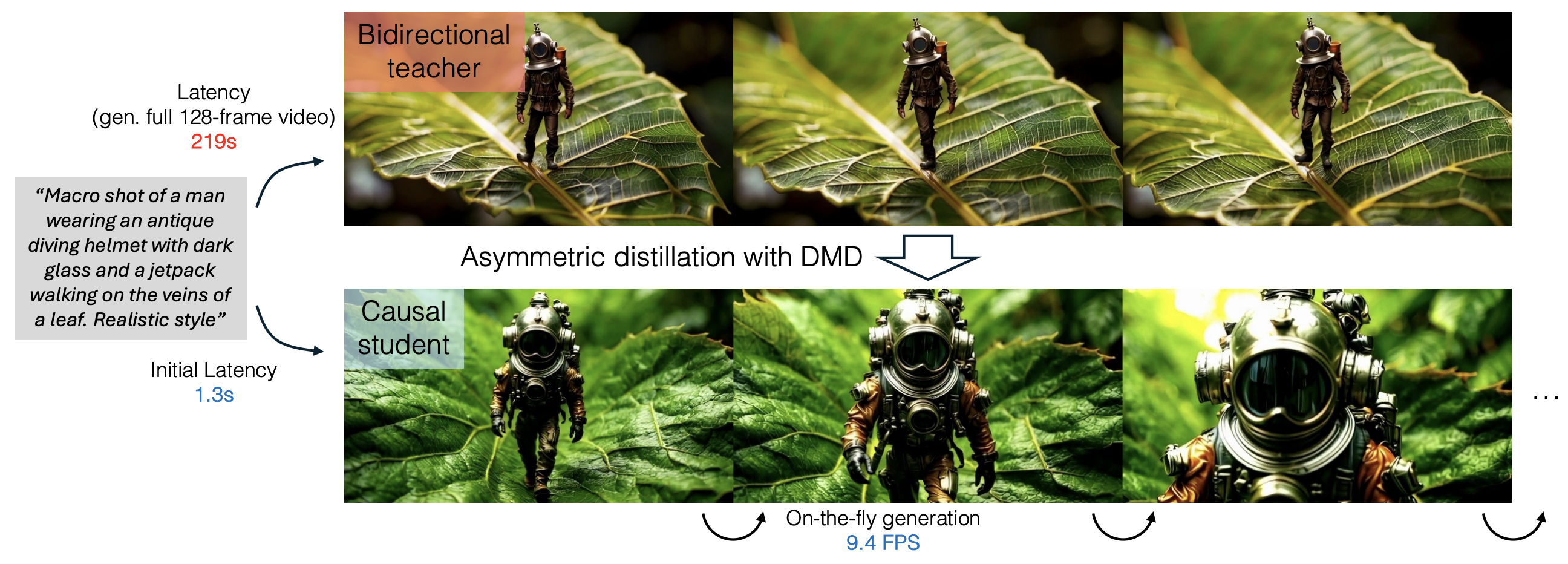
图源:CausVid 官方项目页,对应论文 Figure 1。原图对比传统 bidirectional diffusion 生成完整 128-frame 视频需要 219s,而 CausVid 通过 asymmetric distillation with DMD 得到 causal student,初始延迟 1.3s,随后约 9.4 FPS 流式生成。
这张图的关键不是“更快”这个单点,而是两个约束同时成立。第一,模型必须 causal:生成当前 chunk 时不能依赖未来 chunk,否则无法流式交互。第二,模型必须 few-step:即使结构上已经 causal,如果每个 chunk 还要几十步扩散采样,也达不到交互帧率。CausVid 的路线是用双向 teacher 保留视频先验,用 causal student 和 KV cache 满足部署形态,再用 DMD 把采样步数压下来。
核心问题
视频扩散模型通常在 latent video 上训练一个 denoiser:
如果视频 latent 被组织成多个 chunk:
双向 DiT 的 self-attention 默认允许任意 chunk 互相看见。于是生成第 个 chunk 时,模型实际依赖:
交互式视频生成需要的却是:
也就是说,当前 chunk 不能依赖未来 chunk。CausVid 要解决的核心矛盾是:
- 双向视频 DiT 质量高,但不是流式;
- 自回归视频模型可以流式,但容易误差累积;
- 多步扩散质量好,但推理太慢;
- 少步学生快,但直接训练因果学生会不稳定。
论文的答案是三件事一起做:
1 | pretrained bidirectional video DiT |
方法总览
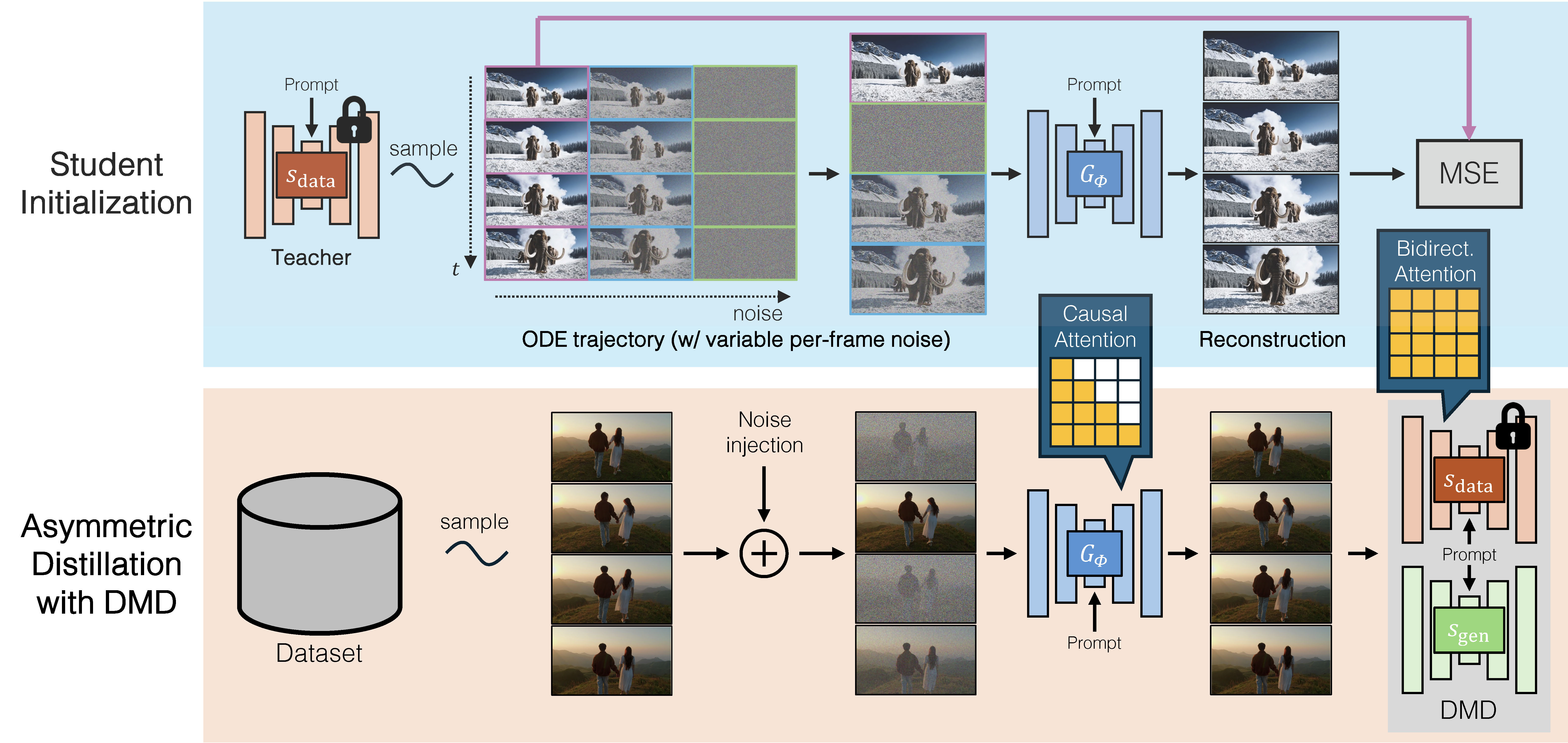
图源:CausVid 官方项目页,对应论文 Figure 5。该图展示两阶段训练:先用 bidirectional teacher 的 ODE solution pairs 初始化 causal student,再用 bidirectional teacher 对 causal student 做 asymmetric DMD distillation。
图里的关键是“先初始化,再分布匹配”,而不是直接把双向模型改成 causal 后开训。第一阶段的 ODE initialization 用 bidirectional teacher 生成的轨迹点训练 causal student,让它先学会在 causal attention 约束下走一条合理的去噪路径。这个阶段更像把学生放到一个不会崩的初始区域。
第二阶段才是 asymmetric DMD:student 是 causal 的,但 teacher score 来自 bidirectional teacher。这个不对称很重要,因为 causal teacher 自己会有未来信息缺失和误差累积问题,如果再拿它蒸馏 causal student,会把弱点传下去。CausVid 的图实际表达的是一个工程判断:部署形态必须 causal,但监督信号可以继续利用 bidirectional teacher 的强视频先验。
方法可以拆成四层。
| Layer | Design | Why it matters |
|---|---|---|
| Latent video representation | 3D VAE encodes video chunks into latent chunks | avoid raw-pixel video diffusion cost |
| Causal DiT | block-wise causal attention across chunks, bidirectional attention within chunk | preserve local temporal consistency while enforcing streaming causality |
| ODE initialization | fit student on teacher-generated ODE solution pairs | stabilize few-step causal student before DMD |
| Asymmetric DMD | causal student is supervised by bidirectional teacher | keep teacher quality while making student causal and fast |
这篇论文最值得学的点在第三、四层。直接把 bidirectional DiT 加上 causal mask 后微调,会明显掉质量;直接用 DMD 训 causal student 又容易不稳。作者因此先用 teacher ODE trajectory 做初始化,再用强的 bidirectional teacher 做分布匹配蒸馏。
因果架构
CausVid 使用 3D VAE 压缩视频。论文的实现中,3D VAE 把 16 个视频帧编码成一个包含 5 个 latent frames 的 latent chunk。DiT 在 latent space 上生成 chunk。
注意力 mask 是 block-wise causal:
其中 是 frame 或 latent token 的时间索引, 是 chunk size。
这意味着:
- 同一个 chunk 内部可以双向注意力,保证局部视频连续;
- 当前 chunk 可以看过去 chunk;
- 当前 chunk 不能看未来 chunk;
- 推理时按 chunk 生成,过去 chunk 的 key/value 可以缓存。
这个设计比逐帧完全 causal 更现实,因为 VAE 解码本身也需要一个 latent block 才能输出像素。换句话说,系统的真实最低延迟不是单帧,而是一个 VAE chunk。
非对称 DMD 蒸馏
CausVid 用的是 DMD / DMD2 路线:不要求学生逐步模仿 teacher 的每一步轨迹,而是用 score difference 近似 reverse KL,让学生输出分布贴近数据分布。
普通 DMD 有两个 score:
| Score | Role |
|---|---|
| frozen teacher score, approximates data distribution | |
| trainable score on student-generated distribution |
生成器更新方向来自二者差异。直觉上,如果 student 输出落在低数据密度区域, 会把它往真实视频分布推; 用来校正 generator 自己分布的梯度。
CausVid 的关键改动是 asymmetric:
| Component | Attention | Function |
|---|---|---|
| Teacher | bidirectional | provide strong video prior and distribution-level supervision |
| Student | causal | generate chunks autoregressively |
| Fake score | trained on student outputs | approximate generator distribution score |
为什么不能用 causal teacher?论文的消融显示 causal teacher 本身更容易误差累积,蒸馏给学生会把这个缺陷传下去。用 bidirectional teacher 则保留了强模型的全局视频先验,让 causal student 学到更好的局部质量和长期稳定性。
学生初始化
直接用 DMD loss 训练 causal student 会不稳定,主要因为 teacher 和 student 的架构、依赖关系都不同。CausVid 先做 ODE initialization。
初始化流程:
1 | sample Gaussian noise sequence |
训练损失可以理解为:
这一步不是最终目标,只是把 causal student 放到一个“会沿 teacher ODE 轨迹还原视频”的初始区域。后续 DMD 才负责分布级对齐。
推理:KV cache 和流式 chunk
推理时,CausVid 按 chunk 自回归生成:
1 | initialize KV cache |
KV cache 的意义和 LLM 类似:过去 chunk 已经计算过的 key/value 不必重复计算。论文还指出,因为推理时有 KV cache,训练里的 block-wise causal attention mask 不再需要以同样形式执行,可以使用更快的 bidirectional attention implementation 来处理当前 chunk。
这解释了为什么它能从 bidirectional teacher 的 219.2s 降到 1.3s initial latency 和 9.4 FPS throughput。不是只靠少步采样,也不是只靠 causal mask,而是:
1 | 4-step DMD student + causal chunking + KV cache + latent video representation |
四者叠加。
训练细节
论文训练细节很值得单独记,因为它说明 CausVid 不是“随便把 mask 换成 causal”。
| Item | Detail |
|---|---|
| Teacher | bidirectional DiT, architecture similar to CogVideoX |
| Student | same DiT backbone but with causal attention across chunks |
| VAE | 3D VAE, encodes 16 video frames into 5 latent frames |
| Chunk | each chunk contains 5 latent frames |
| Training video length | 10 seconds |
| Training FPS | 12 FPS |
| Training resolution | 352 x 640 |
| Student inference steps | 4 denoising steps |
| Student timesteps | [999, 748, 502, 247] |
| Efficient attention | FlexAttention during training |
| Data | mixed image and video datasets following CogVideoX |
| Internal videos | around 400K single-shot videos with full copyright |
| Filtering | safety and aesthetic score filtering |
| ODE initialization data | 1000 ODE pairs |
| ODE init optimization | 3000 iterations, AdamW, learning rate 5e-6 |
| DMD optimization | 6000 iterations, AdamW, learning rate 2e-6 |
| Guidance scale | 3.5 |
| TTUR ratio | 5, following DMD2 |
| Compute | about 2 days on 64 H100 GPUs |
这组配置里有几个实践信号:
- 训练分辨率是
352 x 640,不是靠低分辨率玩具视频证明速度; - student 与 teacher 主体结构相同,只改 causal attention,这降低了从预训练 teacher 迁移的难度;
- ODE init 只用 1000 pairs 和 3000 iterations,说明它是稳定器,不是主训练阶段;
- DMD 只训 6000 iterations,但算力很大,说明数据和 teacher 质量仍然是核心前提;
- 推理用 4 steps,论文摘要表述为把 50-step diffusion model 蒸馏成 4-step generator。
开源代码需要和论文实验区分开看。论文主实验使用内部约 400K single-shot videos;当前 GitHub 是工作中代码库,README 说明实现 largely based on Wan model suite,并提供 MixKit 6K videos 作为 toy distillation dataset。也就是说,repo 对理解流程很有用,但不能把 toy dataset 训练效果等同于论文主结果。
实验结果
Table 1: Evaluation of text-to-short-video generation
论文用 VBench 评估 10 秒附近的短视频生成。表格保留英文格式。
| Method | Length (s) | Temporal Quality | Frame Quality | Text Alignment |
|---|---|---|---|---|
| CogVideoX-5B | 6 | 89.9 | 59.8 | 29.1 |
| OpenSORA | 8 | 88.4 | 52.0 | 28.4 |
| Pyramid Flow | 10 | 89.6 | 55.9 | 27.1 |
| MovieGen | 10 | 91.5 | 61.1 | 28.8 |
| CausVid (Ours) | 10 | 94.7 | 64.4 | 30.1 |
表源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,Table 1。原论文表格要点:该表在 text-to-short-video 生成上比较 CogVideoX、OpenSORA、Pyramid Flow、MovieGen 和 CausVid;CausVid 在 temporal quality、frame quality 和 text alignment 上都取得最高分,说明因果少步学生没有牺牲短视频质量。
这张表说明 CausVid 不只是快:在短视频 VBench 口径下,它的 temporal quality、frame quality 和 text alignment 都很强。尤其是 temporal quality,因果模型没有因为自回归而明显掉一致性。
Table 2: Evaluation of text-to-long-video generation
长视频更能检验 error accumulation。
| Method | Temporal Quality | Frame Quality | Text Alignment |
|---|---|---|---|
| Gen-L-Video | 86.7 | 52.3 | 28.7 |
| FreeNoise | 86.2 | 54.8 | 28.7 |
| StreamingT2V | 89.2 | 46.1 | 27.2 |
| FIFO-Diffusion | 93.1 | 57.9 | 29.9 |
| Pyramid Flow | 89.0 | 48.3 | 24.4 |
| CausVid (Ours) | 94.9 | 63.4 | 28.9 |
表源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,Table 2。原论文表格要点:该表比较长视频生成方法的 VBench 指标;CausVid 在 temporal quality 和 frame quality 上最高,说明 asymmetric DMD 与 causal rollout 能缓解长视频生成中的误差累积和画质衰减。
这里 CausVid 的 frame quality 优势很明显。它说明 bidirectional teacher 的蒸馏确实缓解了普通 autoregressive model 的质量衰减问题。
Table 3: Latency and throughput
| Method | Latency (s) | Throughput (FPS) |
|---|---|---|
| CogVideoX-5B | 208.6 | 0.6 |
| Pyramid Flow | 6.7 | 2.5 |
| Bidirectional Teacher | 219.2 | 0.6 |
| CausVid (Ours) | 1.3 | 9.4 |
表源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,Table 3。原论文表格要点:该表报告 10-second、120-frame、640 x 352 视频生成的 initial latency 和 throughput;CausVid 相比 bidirectional teacher 把首段延迟从约 219s 降到 1.3s,吞吐提升到 9.4 FPS。
论文测的是生成 10-second、120-frame、640 x 352 视频,总时间包含 text encoder、diffusion model 和 VAE decoder。这个表最重要:CausVid 相对类似规模 CogVideoX 有约 160x latency reduction 和 16x throughput improvement。
Table 4: Ablation studies
| Many-step models | Causal Generator? | # Fwd Pass | Temporal Quality | Frame Quality | Text Alignment |
|---|---|---|---|---|---|
| Bidirectional | ✗ | 100 | 94.6 | 62.7 | 29.6 |
| Causal | ✓ | 100 | 92.4 | 60.1 | 28.5 |
| Few-step models | ODE Init. | Teacher | Causal Generator? | # Fwd Pass | Temporal Quality | Frame Quality | Text Alignment |
|---|---|---|---|---|---|---|---|
| ✗ | Bidirectional | ✓ | 4 | 93.4 | 60.6 | 29.4 | |
| ✓ | None | ✓ | 4 | 92.9 | 48.1 | 25.3 | |
| ✓ | Causal | ✓ | 4 | 91.9 | 61.7 | 28.2 | |
| ✓ | Bidirectional | ✓ | 4 | 94.7 | 64.4 | 30.1 |
表源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,Table 4。原论文表格要点:该表对 many-step causalization、ODE initialization 和 teacher 类型做消融;最终 ODE Init. + Bidirectional Teacher + causal generator + 4 fwd pass 的组合最好,说明初始化和非对称 teacher 都不可省。
这张表在回答一个很具体的问题:CausVid 的提升到底来自 causal architecture、ODE init,还是 DMD teacher?上半部分说明,只把 many-step bidirectional model 改成 causal 会掉质量,尤其 temporal quality 和 text alignment 都下降,说明 causal mask 本身不是免费午餐。
下半部分更关键。没有 ODE init 时,4-step causal student 还能跑,但质量不稳;只有 ODE init、没有 DMD teacher 时,frame quality 掉到 48.1,说明初始化不能替代分布匹配蒸馏;用 causal teacher 又不如 bidirectional teacher,说明强 teacher 的全局视频先验仍然必要。最终最佳组合是 causal student + ODE init + bidirectional teacher DMD。这个表支撑了论文的“asymmetric distillation”主张。
这张消融把论文主张支撑得很扎实:
- 直接把 bidirectional 模型改成 causal many-step,会掉质量;
- 只做 ODE init、没有 teacher DMD,frame quality 很差;
- 用 causal teacher 蒸馏不如 bidirectional teacher;
- 最终方案必须是
ODE Init. + Bidirectional Teacher + causal student + 4 fwd pass。
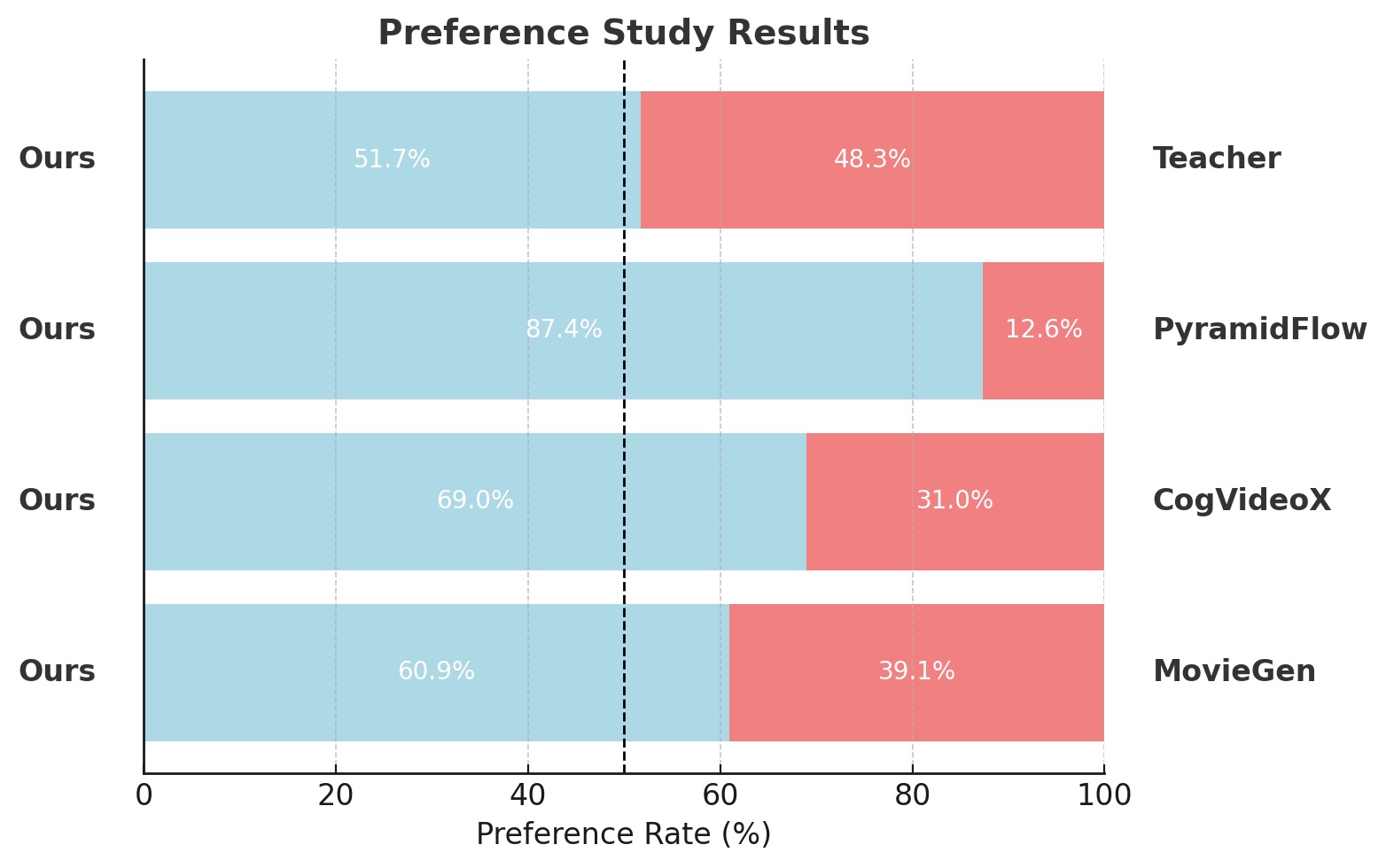
图源:CausVid 官方项目页,对应论文的人类偏好实验可视化。CausVid 在偏好研究中相对 PyramidFlow、CogVideoX、MovieGen 取得明显优势,并与 bidirectional teacher 接近。
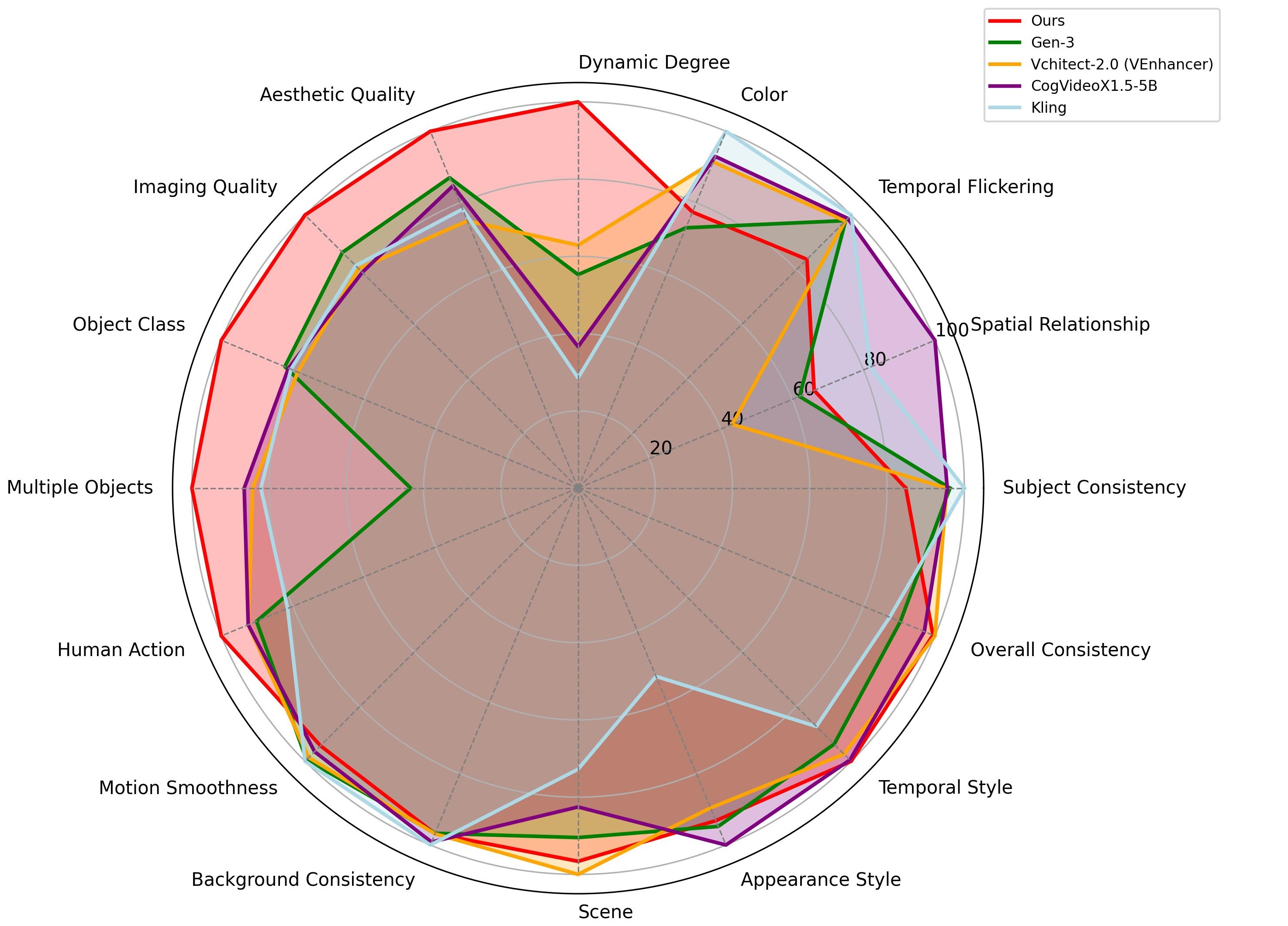
图源:CausVid 官方项目页。Radar plot 展示 CausVid 在 VBench 多项指标上的表现,项目页报告其 VBench 总分为 84.27。
Preference 图回答“人在两两比较时更喜欢谁”,更接近真实观感和交互体验;radar 图回答“VBench 多个自动维度上哪里强、哪里弱”,更适合定位能力结构。CausVid 要证明的不是单项指标最高,而是 causal streaming 约束下仍接近 bidirectional teacher:人评接近 teacher 说明质量没有因流式化严重崩掉,radar 图则检查 temporal quality、frame quality、alignment 等维度是否均衡。
Table 5: Evaluation of streaming video-to-video translation
| Method | Temporal Quality | Frame Quality | Text Alignment |
|---|---|---|---|
| StreamV2V | 92.5 | 59.3 | 26.9 |
| CausVid (Ours) | 93.2 | 61.7 | 27.7 |
表源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,Table 5。原论文表格要点:该表比较 streaming video-to-video translation;CausVid 在 temporal quality、frame quality 和 text alignment 上均高于 StreamV2V,说明视频扩散先验比逐帧 image diffusion 更适合流式视频编辑。
streaming V2V 的设置是:对每个输入视频 chunk 注入噪声,再根据文本条件一步去噪。这很像 SDEdit 的流式版本。CausVid 胜过 StreamV2V 的核心原因是它有视频先验,而不是只靠 image diffusion 逐帧编辑。
Table 6: Evaluation of image-to-video generation
| Method | Temporal Quality | Frame Quality | Text Alignment |
|---|---|---|---|
| CogVideoX-5B | 87.0 | 64.9 | 28.9 |
| Pyramid Flow | 88.4 | 60.3 | 27.6 |
| CausVid (Ours) | 92.0 | 65.0 | 28.9 |
表源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,Table 6。原论文表格要点:该表评估 zero-shot image-to-video;CausVid 只训练 text-to-video,但通过把输入图像作为初始 chunk 仍能在 temporal quality 和 frame quality 上取得强结果。
这一项更有意思:CausVid 只训练 text-to-video,却可以 zero-shot image-to-video。做法很简单:把输入图像复制成第一段 frames,作为初始 chunk,后续由模型自回归扩展。这说明因果视频生成器天然适合把“已知起始观测”当成上下文。
和 Diffusion Forcing 的关系
CausVid 明确和 Diffusion Forcing 属于同一大方向,但解决层级不同。
| Dimension | Diffusion Forcing | CausVid |
|---|---|---|
| Core idea | independent noise level per token | causal video DiT distilled from bidirectional teacher |
| Main object | generic sequence tokens | latent video chunks |
| Training objective | denoising objective over variable token noise | ODE init + asymmetric DMD |
| Architecture in paper | small causal RNN / sequence model | DiT with block-wise causal attention |
| Primary outcome | stable sequence rollout and planning | high-quality low-latency streaming video |
| Speed focus | not the main contribution | central contribution, 4-step generator + KV cache |
可以把 Diffusion Forcing 看成“序列扩散的训练范式”,CausVid 看成“视频生成系统里的落地版本之一”。CausVid 也使用了每个 chunk 独立噪声 timestep 的思想,但它的关键突破是非对称蒸馏:用强 bidirectional teacher 训练 causal student,而不是让 causal teacher 自己教自己。
和 LingBot-World 的关系
LingBot-World 想把视频生成模型变成可交互世界模拟器,CausVid 则提供了非常关键的生成器侧技术:
| Requirement for interactive world model | CausVid contribution |
|---|---|
| low initial latency | first output after about 1.3s |
| streaming rollout | causal chunks with KV cache |
| long horizon | autoregressive sliding-window generation |
| few-step generation | DMD distillation to 4 steps |
| dynamic user input | dynamic prompting and streaming V2V |
但 CausVid 本身还不是完整世界模型。它主要解决“视频生成如何低延迟流式化”,不是解决“动作如何改变世界状态”。要变成 LingBot-World 那样的交互模拟器,还需要动作条件数据、控制接口、闭环评测和长期记忆机制。
最值得复用的设计经验
1. 不要用弱 causal teacher 蒸馏 causal student
直觉上,student 是 causal,teacher 也 causal 好像更一致。但论文实验反而显示,causal teacher 会把自己的误差累积问题传给 student。更好的方案是用强 bidirectional teacher 提供质量,再让 student 承担 causal 约束。
2. 先初始化,再 DMD
DMD 是分布级目标,直接上可能不稳定。CausVid 用少量 ODE solution pairs 让 student 先学会 teacher 的粗去噪映射,再进入 DMD。这个顺序很适合迁移到其他 few-step / causal distillation 项目。
3. 延迟是模型、VAE、cache 的系统问题
只说“4 steps”不足以解释 9.4 FPS。CausVid 的速度来自四处:
- 少步 DMD;
- latent diffusion;
- chunk-wise causal generation;
- KV cache。
实际部署时,VAE chunk 大小甚至会成为最低延迟下限。
4. 训练短视频,推理长视频,需要正视 memory truncation
CausVid 可以生成 30 秒高质量视频,但极长视频仍会退化。论文讨论指出 sliding window 会丢弃 10 秒以外的上下文,远处物体或场景重现时可能不一致。这对世界模型尤其重要:流式生成不等于长期记忆。
局限与风险
- 极长视频仍会退化:论文承认超过 30 秒或更长时仍存在质量下降和 error accumulation。
- chunk 边界可能不连续:连续视频 segment 之间会有 discontinuities,可能需要 VAE 或 generator 的跨块设计改进。
- VAE 限制最低延迟:当前 VAE 需要生成 5 个 latent frames 才能输出像素,frame-wise VAE 才可能进一步降延迟。
- DMD 可能降低多样性:reverse KL / distribution matching 常见问题是样本多样性略降。
- 动作条件不足:CausVid 支持动态 prompt 和 streaming V2V,但不是动作条件世界模型。
- 论文主训练数据不可完全复现:主结果使用内部 400K single-shot videos;开源 repo 当前给出 Wan-based 工作中实现和 toy MixKit distillation 流程。
读完应该记住什么
CausVid 的关键贡献是证明:高质量视频扩散不一定只能双向、离线、慢速生成。 通过 block-wise causal DiT、ODE initialization、bidirectional-teacher asymmetric DMD 和 KV cache,可以把强双向视频扩散模型转成 few-step 流式生成器。
从工程角度看,这篇论文最值得带走的不是某个单独 trick,而是一条组合路线:
1 | strong bidirectional teacher |
这条路线很适合接在 Diffusion Forcing、视频世界模型和少步蒸馏之后读。它把“因果视频扩散”从概念推进到了一个可测延迟、可跑 benchmark、能支持 streaming UI 的系统形态。
参考资料
- Yin et al. From Slow Bidirectional to Fast Autoregressive Video Diffusion Models. arXiv:2412.07772.
- 官方项目页:CausVid.
- 官方代码:tianweiy/CausVid.
- 论文 HTML 版本:ar5iv:2412.07772v4.
- Title: 论文专题讲解:CausVid:流式自回归视频扩散
- Author: Charles
- Created at : 2025-10-08 09:00:00
- Updated at : 2025-10-08 09:00:00
- Link: https://charles2530.github.io/2025/10/08/ai-files-paper-deep-dives-diffusion-causvid/
- License: This work is licensed under CC BY-NC-SA 4.0.