
论文专题讲解:Diffusion Forcing:next-token 与全序列扩散
- 论文:
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion - 链接:arXiv:2407.01392
- 版本:2024-07-01 首次提交,2024-12-10 更新到 v4
- 项目页:Diffusion Forcing
- 代码:GitHub
- 关键词:序列扩散、因果扩散、next-token prediction、full-sequence diffusion、视频预测、扩散规划、Monte Carlo Tree Guidance
这篇论文的核心不是再发明一个采样器,而是改了扩散模型处理序列的训练方式:每个 token 都可以有自己的噪声水平。这样一个因果序列模型既能像 next-token 模型一样逐步向前生成,又能像 full-sequence diffusion 一样对整段未来做 guidance。
如果只用一句话概括:
1 | Teacher Forcing 沿时间轴遮住未来; |
论文位置
扩散模型在图像和视频里通常默认一次建模一个固定大小的样本,例如一张图或一段固定长度视频。放到序列问题里,这会形成两类路线:
| Route | Strength | Main limitation |
|---|---|---|
| Next-token prediction / teacher forcing | variable-length generation, causal rollout, online control | hard to guide a whole future trajectory, continuous signals easily drift in long rollout |
| Full-sequence diffusion | strong continuous generation, can use guidance on a whole sequence | fixed horizon, usually non-causal, cannot naturally reuse online feedback |
| Diffusion Forcing | variable horizon + sequence-level guidance + causal uncertainty | current paper implementation is still small-scale RNN, not internet-scale video generation |
这篇论文值得放进扩散专题,是因为它把扩散从“整段样本一起去噪”的默认形态,推到“序列上每个 token 可以处于不同不确定性”的形态。它和 视频与多模态扩散、采样与推理加速、条件控制与 Guidance 都有直接接口。
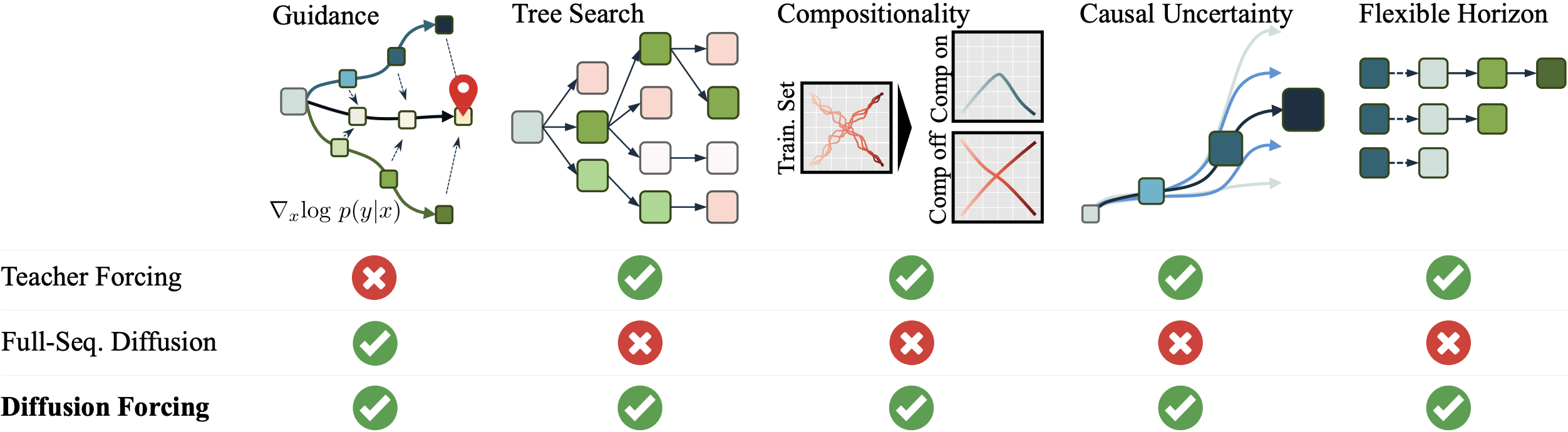
图源:Diffusion Forcing 官方项目页,对应论文 Figure 1。该图用 Guidance、Tree Search、Compositionality、Causal Uncertainty 和 Flexible Horizon 对比 Teacher Forcing、Full-Seq. Diffusion 与 Diffusion Forcing。
这张图最重要的读法不是“DF 什么都赢”,而是看它在能力组合上的定位:full-sequence diffusion 可以做整段 guidance,但不擅长树搜索、组合生成、因果不确定性和可变 horizon;teacher forcing 可以变长生成和在线决策,但缺少扩散式整段引导;DF 试图把二者同时放进一个训练目标里。
这里的关键是把“序列生成”拆成两个轴来看:一个是时间轴,也就是模型怎样从过去走向未来;另一个是噪声轴,也就是模型怎样从不确定状态逐步还原出确定样本。
Full-sequence diffusion 很擅长在噪声轴上工作。它把整段未来轨迹、整段视频或整段 token 序列一起加噪,然后一起去噪。这样做的好处是,模型在采样时可以看见“整段候选未来”的当前状态,所以很适合做 sequence-level guidance:例如希望整段轨迹最终到达目标、整段视频满足某个约束、整段动作序列降低某个代价。它的问题是时间结构通常不够因果:整段长度常常要预先固定,模型一次处理完整 horizon,不天然支持“先生成一小段、根据环境反馈再继续”的在线过程。树搜索也类似,树搜索需要在不同未来分支之间反复展开、回滚、比较,而传统 full-sequence diffusion 更像一次性优化一个固定长度样本,不像 next-token 模型那样自然地按节点扩展。
Teacher forcing / next-token prediction 正好相反。它很擅长沿时间轴工作:给定过去 ,预测下一个 ,再把预测结果接回上下文继续往前滚。这样天然支持 variable horizon,因为想生成多长就循环多少步;也天然适合在线决策,因为每一步都能把新观测、新动作或环境反馈放回上下文。但它缺少扩散模型那种“整段未来一起被优化”的机制。next-token 模型通常只看局部下一步损失,长程目标、全局约束、轨迹级 guidance 很难直接作用到整段未来上,尤其在连续状态、视频帧或动作序列里,长期 rollout 容易漂移。
Diffusion Forcing 的尝试是把两者的优点放进同一个训练目标:时间上仍然保持因果,可以像 teacher forcing 一样从左到右 rollout;噪声上又允许每个 token 有独立噪声水平,可以像 diffusion 一样对未来的不同部分施加不确定性和 guidance。直观地说,过去 token 可以是干净观测,当前 token 可以是低噪声状态,远期未来可以是高噪声候选;模型被训练去处理这种“有的时间点确定、有的时间点半确定、有的时间点完全不确定”的混合序列。因此 DF 才能同时连接 variable-horizon generation、causal uncertainty、trajectory guidance 和 tree-search-style planning。
核心问题
设序列为:
其中上标 表示干净 token。token 可以是视频帧、状态、动作、奖励、时间序列向量,或者它们的组合。
普通 full-sequence diffusion 往往给整段序列同一个噪声水平 :
这等价于“整段一起模糊,再整段一起还原”。它适合固定长度视频或轨迹,但不自然支持“前面已经确定、后面还不确定”的在线生成。
Diffusion Forcing 改成给每个 token 采样独立噪声水平:
于是同一条序列里可以同时出现:
- :这个 token 是干净观测,相当于已知上下文;
- :这个 token 部分可见,表示中等不确定性;
- :这个 token 接近纯噪声,相当于被完全遮住。
论文把这个解释成 noise as partial masking:噪声不是只能服务图像生成,它也可以作为连续版 mask。这个视角很关键,因为它把扩散模型和 teacher forcing、masked modeling 放到同一个坐标系里。
方法总览
Diffusion Forcing 的训练可以理解成一条链:
1 | sample sequence x_1:T |
论文在序列生成中使用的是 Causal Diffusion Forcing,简称 CDF。它要求模型在时间上因果,只能依赖过去和当前 token 的 noisy observation,而不能偷看未来干净 token。
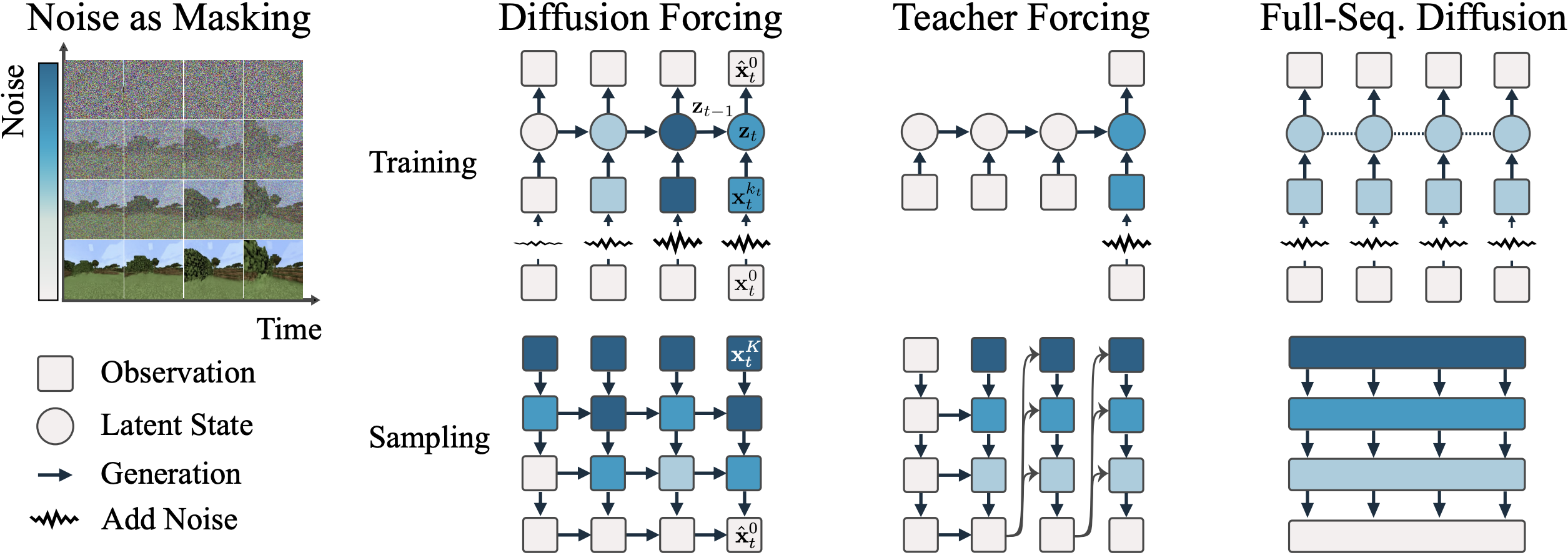
图源:Diffusion Forcing 官方项目页,对应论文 Figure 2。原图展示 noise as masking、Diffusion Forcing、Teacher Forcing 和 Full-Seq. Diffusion 的训练与采样差异。
图里有两个轴:横轴是时间,决定 token 之间的因果关系;纵轴是噪声,决定每个 token 当前还有多少信息。Teacher forcing 基本只沿时间轴工作:过去是真值,预测下一个 token。Full-sequence diffusion 基本只沿噪声轴工作:整段序列共享一个噪声水平。Diffusion Forcing 则允许二维网格上每个位置有自己的噪声水平,训练模型学会从任意“部分确定、部分不确定”的序列中恢复干净 token。
训练目标
论文把 CDF 写成一个因果状态空间模型。可以用下面这个近似形式理解:
训练损失仍然是标准扩散里的 noise prediction MSE,只是噪声水平从全序列共享改成逐 token 独立:
这点很重要:DF 没有抛弃扩散模型的基本训练范式。它仍然是加噪、预测噪声、MSE 训练。真正变化的是 训练 batch 里同一条序列的每个 token 噪声水平不同,并且模型结构保持因果。
论文给出的理论结果可以直观理解为:这种训练不只是一个 heuristic,它对应所有 noisy subsequence likelihood 的某种重加权 ELBO 下界。换句话说,模型被迫同时学习:
- 给定完整过去,生成未来;
- 给定部分过去,补全缺失 token;
- 给定部分 noisy future,对更早 token 做 guidance;
- 给定任意长度上下文,维持因果状态。
采样:二维噪声日程
普通 diffusion 的采样日程是一维的:
1 | K -> K-1 -> ... -> 0 |
Diffusion Forcing 的采样日程是二维矩阵。列是时间 token,行是采样阶段,每个格子指定某个 token 当前要处于哪个噪声水平:
1 | time: 1 2 3 4 5 |
这个矩阵只是示意,真实 schedule 可以按任务设计。关键是:近处未来可以更干净,远处未来可以保持更 noisy。这样模型在做规划或视频 rollout 时,不必假装所有未来同样确定。

图源:Diffusion Forcing 官方项目页。该图概览稳定自回归 rollout、带因果不确定性的去噪、整段轨迹 guidance 和 corrupted observation conditioning 等用法。
这张图不是在列四个互不相关的应用,而是在说明同一个模型可以通过噪声日程变化服务不同任务。历史 token 可以保持低噪声来稳定 autoregressive rollout;远期未来可以保持高噪声来表达 causal uncertainty;目标或 reward 可以对整段未来施加 guidance;被污染的 observation 可以被当作带噪条件继续去噪。关键是 DF 把“时间上因果”和“噪声上可控”同时保留下来,所以采样阶段可以按任务重排噪声水平。
这个采样自由度带来四个能力:
| Capability | Why DF can do it |
|---|---|
| Stable autoregressive rollout | past tokens can be treated as slightly noisy rather than perfectly fixed, reducing error accumulation |
| Causal uncertainty | near future can be low-noise while far future remains high-noise |
| Long-horizon guidance | future reward gradients can guide earlier decisions without making the whole future clean |
| Flexible horizon | padding or unused future tokens can be represented as pure noise |
为什么长视频 rollout 更稳
连续视频上的 next-frame 模型有一个常见问题:每一步预测都有一点误差,下一步又把上一步误差当真值输入,长 rollout 很快漂移。full-sequence diffusion 可以生成短段高质量视频,但固定窗口和非因果结构不适合无限向前生成。
DF 的稳定性来自一个很细但很关键的设计:在自回归 rollout 时,它可以让历史 token 保持一个很小的噪声水平,而不是把模型自己生成的帧当成绝对干净的观测。这让 recurrent latent state 不会过度相信已经有误差的生成帧,更像 Bayes filtering 里的“带不确定性的观测更新”。
论文在 DMLab 和 Minecraft 上用同一类卷积 RNN 架构比较三类方法:
- next-frame diffusion baseline,按 teacher forcing 训练;
- causal full-sequence diffusion baseline;
- Causal Diffusion Forcing。
实验结论是:DF 在训练 horizon 外仍能保持更稳定的视频结构,而 teacher forcing 和 causal full-sequence diffusion 更容易出现漂移或帧间跳变。

图源:Diffusion Forcing 官方项目页。DMLab 结果展示 DF 的视频预测样例,红框是 conditioning frames。

图源:Diffusion Forcing 官方项目页。Minecraft 结果展示 DF 在 128x128 Minecraft 视频上的自回归预测样例。
红框是 conditioning frames,后面的帧是模型自回归预测。读这类结果时不要只看第一两帧是否清晰,而要沿时间往后看:场景布局是否突然跳变,物体身份是否变形,视角运动是否连续,纹理是否逐渐糊成平均样子。DF 想解决的是 teacher forcing 长 rollout 的误差积累,所以 DMLab 和 Minecraft 图的重点是训练 horizon 外还能不能保持结构,而不是单帧视觉质量是否最锐。
扩散规划:为什么 MCTG 有用
论文把 DF 用到离线强化学习和规划时,每个 token 不是单纯的视频帧,而是动作和后续观测的组合:
这样做的好处是:模型不只是生成一个未来状态序列,还生成“动作会导致什么观测”的因果结构。每执行一步动作,环境返回新观测,模型就可以用这个观测更新 latent state,再重新规划下一段。
传统 Diffuser 类 full-sequence diffusion planner 可以对整段轨迹做 guidance,但它的动作和状态不一定因果一致。论文特别指出,Diffuser 的常用实现依赖手工 PD controller 从生成状态反推出动作,而不是直接执行扩散模型生成的动作。DF 的目标则是让生成动作本身和未来观测一致。
Monte Carlo Tree Guidance
MCTG 的直觉是:选择当前动作时,不只看一条未来样本,而是从当前 token 往后采样多条可能未来,用它们的期望 reward gradient 来指导当前去噪。
1 | current token denoising |
这只有在 DF 这种“当前更确定、远方仍不确定”的 schedule 下才自然。full-sequence diffusion 如果把整段轨迹都放在同一个噪声水平,就很难表达“当前动作要清楚,但远处结果还应保留多种可能”。
Table 1: Diffusion Forcing for Planning
下面按论文 Table 1 的英文格式重绘。数值是 D4RL Maze2D / Multi2D 环境上的 reward,Diffuser* 表示使用 hand-crafted PD controller 的 Diffuser 设置。
| Environment | MPPI | CQL | IQL | Diffuser* | Diffuser w/ diffused action | Ours w/o MCTG | Ours |
|---|---|---|---|---|---|---|---|
| Maze2D U-Maze | 33.2 | 5.7 | 47.4 | 113.9 ± 3.1 | 6.3 ± 2.1 | 110.1 ± 3.9 | 116.7 ± 2.0 |
| Maze2D Medium | 10.2 | 5.0 | 34.9 | 121.5 ± 2.7 | 13.5 ± 2.3 | 136.1 ± 10.2 | 149.4 ± 7.5 |
| Maze2D Large | 5.1 | 12.5 | 58.6 | 123.0 ± 6.4 | 6.3 ± 2.1 | 142.8 ± 5.6 | 159.0 ± 2.7 |
| Single-task Average | 16.2 | 7.7 | 47.0 | 119.5 | 8.7 | 129.67 | 141.7 |
| Multi2D U-Maze | 41.2 | - | 24.8 | 128.9 ± 1.8 | 32.8 ± 1.7 | 107.7 ± 4.9 | 119.1 ± 4.0 |
| Multi2D Medium | 15.4 | - | 12.1 | 127.2 ± 3.4 | 22.0 ± 2.7 | 145.6 ± 6.5 | 152.3 ± 9.9 |
| Multi2D Large | 8.0 | - | 13.9 | 132.1 ± 5.8 | 6.9 ± 1.7 | 129.8 ± 1.5 | 167.1 ± 2.7 |
| Multi-task Average | 21.5 | - | 16.9 | 129.4 | 20.57 | 127.7 | 146.17 |
表源:Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion,Table 1。原论文表格要点:该表在 D4RL Maze2D / Multi2D 上比较 MPPI、CQL、IQL、Diffuser 和 Diffusion Forcing;Ours 的平均 reward 最高,且 Ours w/o MCTG 与 Ours 的差距显示 Monte Carlo Tree Guidance 对规划有额外收益。
这张表支持的结论有三层:
Ours在平均 reward 上最高,说明 DF 的 causal uncertainty 和 MCTG 对规划有实际收益;Ours w/o MCTG仍然较强,但低于Ours,说明多未来样本的 guidance 不是装饰项;Diffuser w/ diffused action很低,说明直接执行生成动作时,full-sequence diffusion 的动作和状态一致性会成为问题。
机器人 imitation learning
论文还把 DF 用在真实 Franka 机器人长时模仿学习上。任务是把苹果和橙子通过第三个空槽交换位置。这个任务的难点是非 Markov:只看当前画面,有时无法判断下一步应该移动哪个水果,必须记住初始配置。

图源:Diffusion Forcing 官方项目页,对应论文 Figure 4。图中展示有记忆依赖的水果交换任务、生成视频预测和双相机观测。
这张图不要只看成机器人演示截图。水果交换任务要求模型记住初始摆放和中间操作历史,因为当前画面可能不足以判断下一步该移动哪个水果。DF 的优势在于它可以把过去观测作为较干净条件,把未来动作和观测作为带噪候选来生成;双相机输入提供不同视角,动作 token 则把视频预测和控制决策绑在一起。也就是说,这里测试的是“能不能在部分可观测、长时依赖任务里保持因果状态”,不是普通单步视觉分类。
论文和附录给出的训练设置要点:
| Item | Detail |
|---|---|
| Robot | Franka robot |
| Data collection | VR teleoperation with impedance control |
| Demonstrations | 150 expert demonstrations |
| Cameras | two views, hand camera and front camera |
| Action | 6-DoF robot hand actions |
| Sequence preprocessing | each demonstration has about 500-600 frames/actions, padded and downsampled to 40 frames |
| Action bundling | each frame is bundled with 15 actions |
从方法上看,机器人部分不是单独训练一个“看图出动作”的 policy,而是联合扩散 action-observation sequence。模型既生成动作,也能在同一框架下生成未来观测。因此它天然带一个 latent memory,用来保存初始水果位置这类只在早期画面中可见的信息。
论文报告 DF 在该记忆依赖任务上达到 80% success rate,而 Diffusion Policy 因为缺少长时记忆失败。加入视觉干扰或摄像头遮挡时,DF 可以把异常观测标记成 noisy observation,让 prior model 更多接管动作预测,成功率只下降 4% 到 76%;next-frame diffusion baseline 为 48%。
训练细节
这一节把论文和官方 GitHub paper 分支中的训练配置合在一起读。需要注意:GitHub 主分支后来改成了带 temporal attention 的 v1.5 代码,复现论文原始 RNN 结果时,README 明确建议切到 paper 分支。
1. 模型结构
论文的 CDF 实现是一个 convolutional RNN,而不是大规模 DiT。
| Component | Implementation detail |
|---|---|
| Token | image frame, state-action token, or time-series vector |
| Latent state | recurrent hidden state summarizing past noisy observations |
| Transition model | diffusion U-Net processes noisy observation, then GRU updates latent |
| Observation model | ResNet-style head followed by conv layer predicts denoising target |
| Causality | future tokens depend on past latent state, not future clean tokens |
| Possible extension | masked transformer or DiT can replace RNN, but paper experiments use small RNN |
RNN 的好处是在线控制友好:每次新观测到来,只要更新 latent state,不需要重新处理整段历史。缺点也明显:高分辨率视频和复杂分布很可能需要 transformer / DiT 与 latent diffusion 才能扩展。
2. Video prediction 配置
官方 paper 分支给出的 video 配置如下。
| Item | DMLab | Minecraft |
|---|---|---|
n_frames |
36 | 72 |
resolution |
64 | 128 |
context_length |
4 | 8 |
frame_stack |
4 | 8 |
z_shape channels |
16 | 32 |
network_size |
48 | 64 |
objective |
pred_v |
pred_v |
sampling_timesteps |
100 | 100 |
ddim_sampling_eta |
0.0 | 0.0 |
beta_schedule |
cosine | sigmoid |
cum_snr_decay |
0.8 | 0.96 |
clip_noise |
6 | 6 |
这些细节说明几个工程判断:
- 论文没有在像素上硬撑高分辨率,而是选择 DMLab 64x64 和 Minecraft 128x128 来验证长 rollout 机制;
pred_v、SNR weighting、cumulative SNR decay 和 noise clipping 都是为了让扩散训练更稳;- 100-step DDIM 采样说明论文重点不是“少步出视频”,而是先验证独立噪声 token 训练是否能稳定长序列;
- DMLab 和 Minecraft 的 schedule 不同,说明 noise schedule 不是无关紧要的常数,需要按数据集调。
3. Planning 配置
官方 paper 分支中的 planning 配置更轻量,输入不是图像,而是 Maze2D 的状态、动作和目标信息。
| Item | Detail |
|---|---|
z_shape |
[128] |
frame_stack |
10 |
chunk_size |
${dataset.episode_len} |
network_size |
16 for medium/umaze, 32 for large |
num_mlp_layers |
4 |
sampling_timesteps |
50 |
beta_schedule |
linear |
snr_clip |
5.0 |
cum_snr_decay |
0.98 |
open_loop_horizon |
10 |
sampling guidance_scale |
commonly tuned from 1 to 5 in README examples |
Planning 里最关键的不是网络规模,而是 token 设计和采样 schedule。把 token 定成 ,模型才会被迫学习“动作导致什么观测”。如果只生成状态轨迹,再用外部 controller 找动作,动作一致性问题会被评测掩盖。
4. Robot 配置
官方 paper 分支中的 robot 配置继承了 video 配置,但对目标和步数做了调整:
| Item | Detail |
|---|---|
z_shape |
[32, resolution, resolution] |
frame_stack |
1 |
weight_decay |
1e-4 |
warmup_steps |
2500 |
gt_first_frame |
0.5 |
objective |
pred_x0 |
sampling_timesteps |
25 |
beta_schedule |
cosine |
network_size |
32 |
num_gru_layers |
1 |
和视频预测相比,机器人控制更重视闭环反应和动作输出,因此采样步数降到 25,并使用 pred_x0。这也提醒一个实践点:DF 是训练范式,不绑定某一种扩散参数化。视频里可以用 pred_v,控制里可以用 pred_x0,关键是每个 token 的噪声水平独立、模型保持因果。
和普通视频扩散的关系
Diffusion Forcing 很容易被误读成“一个视频生成模型”。更准确地说,它是一个序列扩散训练范式。视频只是最直观的连续 token 序列之一。
| Dimension | Standard video diffusion | Diffusion Forcing |
|---|---|---|
| Training unit | fixed video clip | sequence with per-token noise |
| Noise level | usually shared across all frames | independent for every token |
| Architecture | often non-causal UNet/DiT | causal RNN or masked transformer |
| Sampling | denoise whole clip | denoise through a time-noise schedule matrix |
| Long rollout | sliding window or fixed horizon | recurrent latent rollout with stabilization |
| Guidance | whole clip guidance | long-horizon causal guidance and MCTG |
| Best current use | high-quality offline video generation | sequential prediction, planning, online control |
这也解释了它和 LingBot-World 一类视频世界模型的关系。LingBot-World 更像“把强视频生成底座工程化成可交互世界模拟器”;Diffusion Forcing 更像“从训练目标层面说明怎样让扩散模型拥有因果、变长和不确定性控制”。两者可以互补:大型视频模型提供画质和语义先验,DF 类 schedule 提供更自然的因果 rollout 训练信号。
最值得复用的设计经验
1. 把噪声当成连续 mask
很多序列任务不只是“知道或不知道”。现实中常见的是不确定程度不同:近处未来更确定,远处未来更不确定;传感器观测可能部分损坏;模型生成的历史帧不应被当成真值。DF 把这种不确定性直接编码到噪声水平里。
2. 训练时覆盖多种条件形态
如果训练只见过“过去全干净、未来全未知”,推理时遇到部分 noisy 的过去或未来就会分布外。DF 每个 token 独立采噪声,相当于训练时系统性覆盖许多 conditioning pattern。
3. 规划要让动作和后果同 token 化
规划模型最怕生成的动作和状态不一致。DF 把 token 定成 ,让模型直接学习 action-conditioned transition。这比“先生成状态,再另找控制器”更接近真实闭环系统。
4. Guidance 不一定要压成单未来
MCTG 的价值在于把未来当分布而不是单条轨迹。当前动作应该优化期望未来,而不是只对一条 sampled future 过拟合。这个观点对机器人、自动驾驶和游戏 agent 都很重要。
局限与风险
- 规模还小:论文主实验使用小型 RNN,作者也明确指出高分辨率视频和复杂分布很可能需要大 transformer。
- 不是图像质量论文:它证明序列训练范式有效,但没有和 SVD、Sora、Veo 这类大视频模型做画质级比较。
- 采样 schedule 变成新超参:二维噪声日程很强,但也带来设计空间。不同任务需要不同 schedule。
- 长 rollout 不等于物理正确:视频稳定不代表学到了真实动力学,仍需动作敏感性、闭环收益和反事实评测。
- guidance 成本可能高:MCTG 需要多未来样本,规划效果和计算预算之间有明显 tradeoff。
- 训练数据仍决定边界:如果数据里没有动作分叉、长时依赖或异常观测,DF 的训练目标也不能凭空补出这些能力。
读完应该记住什么
Diffusion Forcing 的关键贡献是把扩散模型从“一段序列共享一个噪声水平”推广到“每个 token 拥有独立噪声水平”。这个简单变化让同一个因果模型同时具备:
- next-token 模型的变长生成和在线更新;
- full-sequence diffusion 的整段 guidance;
- 对未来不确定性的显式表示;
- 长视频 rollout 的稳定机制;
- 规划和模仿学习中的闭环记忆。
从工程角度看,它最值得借鉴的不是某个 RNN 结构,而是一个训练原则:不要把所有未来 token 都当成同等不确定,也不要把模型自己生成的历史当成完全可信。把不确定性做成每个 token 的噪声水平,训练和采样就能表达更真实的序列状态。
参考资料
- Chen et al. Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion. arXiv:2407.01392.
- 官方项目页:Diffusion Forcing.
- 官方代码:buoyancy99/diffusion-forcing.
- 论文 HTML 版本:ar5iv:2407.01392.
- Title: 论文专题讲解:Diffusion Forcing:next-token 与全序列扩散
- Author: Charles
- Created at : 2025-10-11 09:00:00
- Updated at : 2025-10-11 09:00:00
- Link: https://charles2530.github.io/2025/10/11/ai-files-paper-deep-dives-diffusion-diffusion-forcing/
- License: This work is licensed under CC BY-NC-SA 4.0.