
论文专题讲解:Muon:LLM 预训练优化器
- 论文:
Muon is Scalable for LLM Training - 团队:Kimi Team / Moonshot AI
- 链接:arXiv:2502.16982
- 代码与模型:MoonshotAI/Moonlight / Moonlight-16B-A3B
- 关键词:Muon、AdamW、matrix orthogonalization、Newton-Schulz、update RMS、distributed optimizer、Moonlight、MoE pre-training
这篇论文讨论的不是一个普通训练小技巧,而是一个更基础的问题:在大模型预训练里,AdamW 是否仍然是唯一足够稳、足够可扩展的默认优化器? 论文的答案比较激进:如果只看大规模 LLM 预训练,经过 weight decay、update scale 和分布式实现改造后的 Muon 可以直接替代 AdamW,并在 compute-optimal training 下达到约 2x 的训练效率。
但工程上不能把这句话读成“所有阶段都换成 Muon”。这篇论文真正有价值的部分在于,它把 Muon 从一个小模型优化器改造成能跑 5.7T token MoE 预训练的系统方案,并且清楚暴露了它和 AdamW 的边界:Muon 更适合矩阵权重的预训练更新,非矩阵参数、已有 AdamW checkpoint 的 SFT、以及很多短周期后训练任务,仍然要谨慎对待。
论文位置
AdamW 是当前 LLM 训练最常用的默认优化器。它受欢迎不是因为理论上永远最优,而是因为它有三个工程优势:对不同参数形状都能工作,学习率经验丰富,分布式训练实现成熟。
Muon 切入的是另一条路线。Transformer 里最重的参数大多是矩阵,例如 attention projection、MLP / expert projection、router projection。Muon 不按元素做二阶矩归一化,而是先积累动量,再把矩阵动量正交化,让更新方向不要被少数奇异方向主导。直觉上,它更像是给每个矩阵一个受谱范数约束的更新,而不是给每个元素一个独立自适应步长。
这篇论文的贡献可以压缩成四点:
| Contribution | What it solves |
|---|---|
| Weight decay for Muon | 防止权重 RMS 和层输出 RMS 在长训练里持续增大 |
| Consistent update RMS | 让不同形状矩阵的 Muon update 尺度可比,并能复用 AdamW 学习率 |
| Distributed Muon | 让需要全矩阵正交化的 Muon 能和 ZeRO-1 / Megatron-LM 风格分布式训练结合 |
| Moonlight pre-training | 用 Muon 训练 3B activated / 16B total MoE 模型到 5.7T tokens,验证可扩展性 |
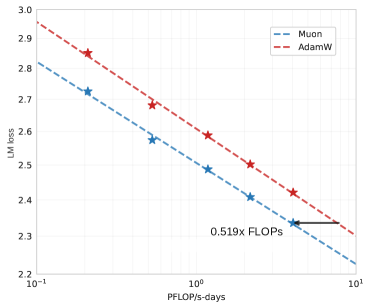
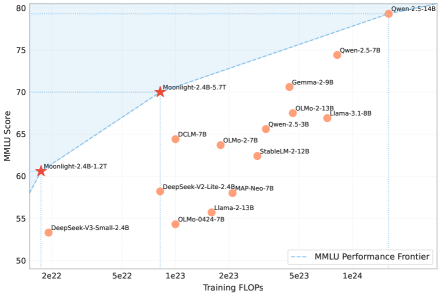
图源:Muon is Scalable for LLM Training,Figure 1。左图展示 Muon 与 AdamW 的 scaling law 对比,论文结论是 Muon 在 compute-optimal 设置下达到相同 loss 约需 0.519x FLOPs;右图展示 Moonlight 在 MMLU 与训练 FLOPs 平面上的 Pareto 位置。
左图不是单次跑分,而是 scaling law 拟合后的训练效率判断。论文先给 AdamW 做 grid search,建立较强 AdamW baseline,再让 Muon 复用 AdamW 的学习率与 weight decay。如果 Muon 只是在一个没调好的 AdamW baseline 上赢,结论意义会很弱;这篇论文真正想证明的是:在 compute-optimal 条件下,改造后的 Muon 仍能系统性降低达到同等 loss 所需的训练 FLOPs。
右图是模型层面的验证:Moonlight 不是 dense 3B,而是 2.24B activated / 15.29B total 的 MoE,算上 embedding 约 3B activated / 16B total。它用 5.7T tokens 训练,目标是证明优化器收益能落到真实模型和真实训练预算上。
先复习 AdamW
AdamW 的核心更新可以写成:
这里 是一阶动量, 是逐元素二阶矩, 是 decoupled weight decay。它的更新方向是 element-wise adaptive 的:某个参数元素最近梯度波动大,分母就大,实际步长就小。
这带来两个直接后果:
- 适用面很宽:矩阵、向量、norm gamma、embedding、LM head 都可以放进去。
- 状态内存更高:通常要保留一阶矩和二阶矩两个 optimizer states。
所以 AdamW 是很强的默认项。它的问题不在“不能训练 LLM”,而在于它是否已经把矩阵权重的更新几何用到了足够好。
Muon 的核心机制
Muon 只考虑可以表示成矩阵的参数。对某个矩阵权重 ,它先维护梯度动量:
然后不直接用 更新,而是对 做矩阵正交化:
最后更新:
论文采用 Newton-Schulz iteration 近似计算正交化结果。如果 ,理想的正交化方向接近 ,也就是保留左右奇异向量,削弱奇异值大小差异带来的主方向垄断。
这和 AdamW 的差别很大:
| Optimizer | Update geometry | Intuition |
|---|---|---|
| AdamW | element-wise adaptive update | 每个元素按历史二阶矩缩放 |
| Muon | matrix-level orthogonalized momentum | 每个矩阵沿更均衡的奇异方向更新 |
Muon 的直觉不是“更精细地调每个元素”,而是“别让一个矩阵只沿少数大奇异方向学习”。这对 attention、MLP、MoE expert、router 这类矩阵权重尤其重要。
为什么原始 Muon 不能直接上大模型
论文指出原始 Muon 在小模型上很有潜力,但大规模 LLM 预训练至少有三个障碍。
第一,没有 weight decay 会让长训练不稳。论文观察到 vanilla Muon 在训练后期可能出现权重 RMS 和层输出 RMS 持续变大,超过 bf16 高精度有效范围后会伤害性能。因此他们把 AdamW 风格的 decoupled weight decay 引入 Muon:
第二,不同形状矩阵的 Muon update RMS 不一致。对形状为 的满秩矩阵,理想正交化更新的理论 RMS 约为:
如果直接用同一个 learning rate,宽矩阵和窄矩阵的实际更新尺度会差很多。论文的做法是按矩阵形状缩放 Muon update,使不同矩阵的 update RMS 更一致;然后再把 Muon 的 update RMS 匹配到 AdamW 常见的 0.2 到 0.4 范围。这样做的最大好处是:Muon 可以直接复用 AdamW 已经调好的 learning rate 和 weight decay。
第三,分布式训练需要全矩阵正交化。AdamW 是逐元素更新,ZeRO-1 把 optimizer states 切到不同 DP rank 后仍然好处理。Muon 需要完整矩阵做 Newton-Schulz,如果只拿本地 shard 正交化,数学含义就变了。因此论文提出 Distributed Muon:先在 DP 内 gather 出完整矩阵动量,做正交化后只保留本 rank 对应的参数分片更新。
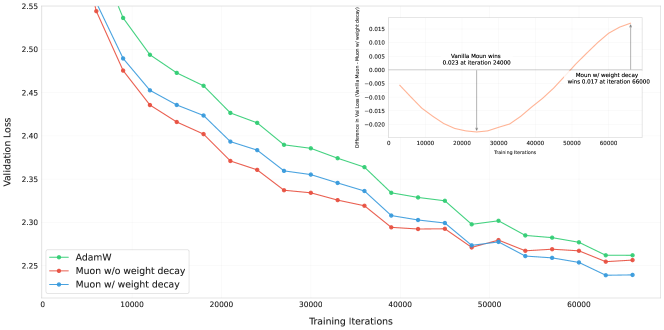
图源:Muon is Scalable for LLM Training,Figure 2。原图比较 AdamW、vanilla Muon 和带 weight decay 的 Muon,重点说明 vanilla Muon 早期收敛快但长训练收益会被权重尺度增长限制,加入 weight decay 后更适合 over-train regime。
如果 Muon 需要重新为每类矩阵单独调学习率,它在大规模训练里的工程价值会大幅下降。论文把 update RMS 调到和 AdamW 接近,本质是在降低迁移成本:已有 AdamW 配方里的 global learning rate、weight decay 和 schedule 可以直接作为 Muon 起点。这个设计比“Muon 在某个固定小实验更低 loss”更重要,因为它决定了 Muon 能不能进入真实训练系统。
论文对 update RMS 做了一个早期训练消融,原表英文列名保留如下:
| Methods | Training loss | Validation loss | query weight RMS | MLP weight RMS |
|---|---|---|---|---|
| Baseline | 2.734 | 2.812 | 3.586e-2 | 2.52e-2 |
| Update Norm | 2.720 | 2.789 | 4.918e-2 | 5.01e-2 |
| Adjusted LR | 2.721 | 2.789 | 3.496e-2 | 4.89e-2 |
表源:论文 Table 1。Update Norm 直接把 update RMS 归一到固定值,Adjusted LR 按矩阵形状调整学习率。论文最终选择 Adjusted LR,因为效果接近但成本更低。
Distributed Muon 怎么跑
Muon 的分布式难点来自一句话:AdamW 的 update 是逐元素的,Muon 的 update 是矩阵级的。 如果一个 被 data parallel optimizer 分片,AdamW 可以每个 rank 更新自己的部分;Muon 则必须先看到完整矩阵,才能做正交化。
论文的 Distributed Muon 流程可以简化成:
1 | DP reduce-scatter gradients |
工程上它有几个重要特征:
| Aspect | Distributed AdamW | Distributed Muon |
|---|---|---|
| Optimizer states | first moment + second moment | one momentum buffer |
| Update locality | element-wise shard update | full matrix orthogonalization, then shard update |
| Extra communication | 常规 ZeRO-1 通信 | 额外 DP gather 完整矩阵动量 |
| Main extra compute | element-wise ops | Newton-Schulz iterations |
| Paper’s latency note | optimizer 时间通常小于 forward/backward | 约 5 次 Newton-Schulz,优化器延迟通常仍远小于模型前后向 |
论文的结论是:Muon 的 optimizer state 只有一个 momentum buffer,状态内存相对 AdamW 更低;通信会增加,但由于只在 DP group 内 gather、本体可用 bf16、并且 optimizer 时间通常被 forward/backward 掩盖,实际大规模训练中没有明显端到端延迟开销。
Scaling law 实验
优化器论文最容易犯的错误是拿一个没调好的 AdamW baseline 当靶子。Moonshot 这篇论文专门强调:AdamW baseline 做了 grid search,并遵循 compute-optimal training 设置。
Scaling law 用的是 Llama 架构 dense models,模型和训练规模如下:
| # Params. w/o Embedding | Head | Layer | Hidden | Tokens | LR | Batch Size* |
|---|---|---|---|---|---|---|
| 399M | 12 | 12 | 1536 | 8.92B | 9.503e-4 | 96 |
| 545M | 14 | 14 | 1792 | 14.04B | 9.143e-4 | 128 |
| 822M | 16 | 16 | 2048 | 20.76B | 8.825e-4 | 160 |
| 1.1B | 18 | 18 | 2304 | 28.54B | 8.561e-4 | 192 |
| 1.5B | 20 | 20 | 2560 | 38.91B | 8.305e-4 | 256 |
表源:论文 Table 2。* 表示 batch size 以 8K context 的 example 数计。
这里的关键设置是:Muon 没有重新单独调一套超参数,而是利用 update RMS matching 直接复用 AdamW 的最优超参数。论文由此得到 Figure 1(a) 的结论:在 compute-optimal setting 下,Muon 达到 AdamW 同等 loss 约需要 0.519x FLOPs。
Moonlight 预训练细节
论文为了验证 Muon 的真实可扩展性,训练了 Moonlight:一个基于 DeepSeek-V3-Small 风格架构的 MoE LLM。正文给出的规模是 2.24B activated / 15.29B total,若计入 embedding 则约为 3B activated / 16B total。
模型和训练设计里有几处需要特别注意:
| Item | Detail |
|---|---|
| Base architecture | DeepSeek-V3-Small style MoE |
| Activated params | 2.24B excluding embedding, about 3B including embedding |
| Total params | 15.29B excluding embedding, about 16B including embedding |
| Context length | 8K during pre-training |
| Training tokens | 5.7T |
| Optimizer | Muon for matrix parameters, Adam-style optimizer for non-matrix parameters |
| Weight decay | 0.1 for all stages |
| Muon momentum | 0.95 |
| Newton-Schulz steps | 5 |
| MTP | not used |
| Gate scaling factor | 2.446 |
| Auxfree bias update | 1e-3 in stage 1 and 2, 0.0 in stage 3 |
训练阶段如下:
| Stage | Tokens | Learning rate / batch | Data emphasis |
|---|---|---|---|
| Stage 1 | 0 to 33B | LR linearly warms up to 4.2e-4 in 2K steps; batch size 2048 examples |
启动训练,稳定早期优化 |
| Stage 2 | 33B to 5.2T | LR cosine decays from 4.2e-4 to 4.2e-5; batch 2048 until 200B, then 4096 |
主预训练阶段 |
| Stage 3 / cooldown | 5.2T to 5.7T | LR increases to 1e-4 in 100 steps, then linearly decays to 0 over 500B tokens; batch size 4096 |
高质量 math、code、reasoning 数据 |
这组细节说明论文没有只做小规模 proxy。它把 Muon 放进了完整大模型训练链路:8K context、MoE routing、aux-free load balancing、cooldown 高质量数据、以及大规模分布式优化。
如果只看前 1.2T token,结论更像优化器加速实验;跑到 5.7T 并加入高质量 math/code/reasoning cooldown,才更接近真实 LLM 训练。Cooldown 会改变数据分布和学习率轨迹,因此能检验 Muon 在阶段切换、低学习率尾段和高质量数据上是否仍然稳定。
Moonlight 和 AdamW baseline 的结果
论文先在约 1.2T token checkpoint 比较同架构模型:Moonlight-A 使用 AdamW,Moonlight 使用 Muon。
| Benchmark (Metric) | DSV3-Small | Moonlight-A@1.2T | Moonlight@1.2T |
|---|---|---|---|
| Activated Params† | 2.24B | 2.24B | 2.24B |
| Total Params† | 15.29B | 15.29B | 15.29B |
| Training Tokens | 1.33T | 1.2T | 1.2T |
| Optimizer | AdamW | AdamW | Muon |
| MMLU | 53.3 | 60.2 | 60.4 |
| MMLU-pro | - | 26.8 | 28.1 |
| BBH | 41.4 | 45.3 | 43.2 |
| TriviaQA | - | 57.4 | 58.1 |
| HumanEval | 26.8 | 29.3 | 37.2 |
| MBPP | 36.8 | 49.2 | 52.9 |
| GSM8K | 31.4 | 43.8 | 45.0 |
| MATH | 10.7 | 16.1 | 19.8 |
| CMath | - | 57.8 | 60.2 |
| C-Eval | - | 57.2 | 59.9 |
| CMMLU | - | 58.2 | 58.8 |
表源:论文 Table 4。† 表示参数量不包含 embedding。
这个表最明显的不是 MMLU,而是 code/math:HumanEval、MBPP、MATH、CMath 上 Muon 优势更明显。论文也明确建议后续研究继续分析为什么 Muon 在这些能力上更有效。
完整 5.7T 训练后,Moonlight 与同量级公开模型的结果如下:
| Benchmark (Metric) | Llama3.2-3B | Qwen2.5-3B | DSV2-Lite | Moonlight |
|---|---|---|---|---|
| Activated Param† | 2.81B | 2.77B | 2.24B | 2.24B |
| Total Params† | 2.81B | 2.77B | 15.29B | 15.29B |
| Training Tokens | 9T | 18T | 5.7T | 5.7T |
| Optimizer | AdamW | Unknown | AdamW | Muon |
| MMLU | 54.7 | 65.6 | 58.3 | 70.0 |
| MMLU-pro | 25.0 | 34.6 | 25.5 | 42.4 |
| BBH | 46.8 | 56.3 | 44.1 | 65.2 |
| TriviaQA‡ | 59.6 | 51.1 | 65.1 | 66.3 |
| HumanEval | 28.0 | 42.1 | 29.9 | 48.1 |
| MBPP | 48.7 | 57.1 | 43.2 | 63.8 |
| GSM8K | 34.0 | 79.1 | 41.1 | 77.4 |
| MATH | 8.5 | 42.6 | 17.1 | 45.3 |
| CMath | - | 80.0 | 58.4 | 81.1 |
| C-Eval | - | 75.0 | 60.3 | 77.2 |
| CMMLU | - | 75.0 | 64.3 | 78.2 |
表源:论文 Table 5。† 表示参数量不包含 embedding;‡ 表示论文使用完整 TriviaQA 集合测试。
这张表不能简单读成“Muon 一定比所有 optimizer 强”。Qwen2.5-3B 的 optimizer 未披露,而且不同模型的数据、架构和训练策略都不完全一致。更稳的读法是:Moonlight 用公开可对照的 MoE 架构和 5.7T token 训练,证明 Muon 可以支撑一个有竞争力的真实模型,而不是只在小模型 loss 曲线上好看。
奇异谱证据
Muon 的核心假设是:矩阵正交化能让权重沿更多方向学习。论文用 SVD entropy 检查训练中不同权重组的奇异谱,发现 Muon 训练出的矩阵通常有更高的 SVD entropy,尤其 router 权重差异更明显。
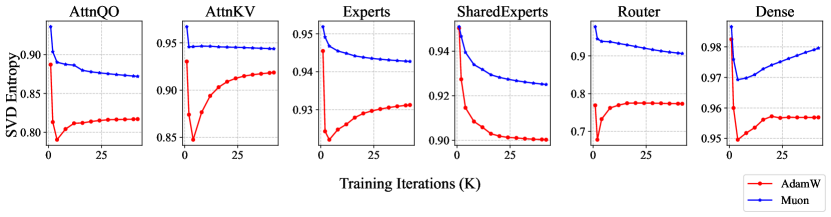
图源:Muon is Scalable for LLM Training,Figure 4。原图把权重分成 AttnQO、AttnKV、Experts、SharedExperts、Router、Dense 六组,比较 AdamW 与 Muon 在训练迭代中的平均 SVD entropy。
SVD entropy 更高意味着奇异值分布更均衡,说明权重矩阵没有被少数奇异方向过度主导。这和 Muon 的设计动机一致。但它不是最终能力指标,也不能单独证明因果。它更适合作为机制证据:Muon 的确改变了矩阵权重的谱结构,而不是只靠学习率或 batch 差异赢。
SFT 阶段的结果要谨慎读
论文也测试了 Muon 在 SFT 中的表现。结论比预训练部分更克制:Muon 预训练加 Muon SFT 效果最好,但当预训练优化器和 SFT 优化器不一致时,收益不稳定。
| Benchmark (Metric) | # Shots | Muon pretrain + Muon SFT | AdamW pretrain + Muon SFT | Muon pretrain + AdamW SFT | AdamW pretrain + AdamW SFT |
|---|---|---|---|---|---|
| MMLU (EM) | 0-shot (CoT) | 55.7 | 55.3 | 50.2 | 52.0 |
| HumanEval (Pass@1) | 0-shot | 57.3 | 53.7 | 52.4 | 53.1 |
| MBPP (Pass@1) | 0-shot | 55.6 | 55.5 | 55.2 | 55.2 |
| GSM8K (EM) | 5-shot | 68.0 | 62.1 | 64.9 | 64.6 |
表源:论文 Table 6。论文使用 Moonlight@1.2T 与 Moonlight-A@1.2T,在 tulu-3-sft-mixture 上 SFT 两个 epoch。
对已有 AdamW 预训练模型,论文还在 Qwen2.5-7B 上做了 SFT 对比:
| Benchmark (Metric) | # Shots | Adam-SFT | Muon-SFT |
|---|---|---|---|
| MMLU (EM) | 0-shot (CoT) | 71.4 | 70.8 |
| HumanEval (Pass@1) | 0-shot | 79.3 | 77.4 |
| MBPP (Pass@1) | 0-shot | 71.9 | 71.6 |
| GSM8K (EM) | 5-shot | 89.8 | 85.8 |
表源:论文 Table 7。论文结论是 Muon 更适合优先用于预训练阶段,而不是简单替换已有 AdamW checkpoint 的 SFT 优化器。
这部分很重要,因为它防止我们把 Muon 泛化过头。预训练阶段从头塑造权重谱,Muon 的矩阵几何可能持续积累收益;SFT 阶段步数少、数据小、目标不同,已有 AdamW checkpoint 的权重状态也未必适合突然切换到 Muon。
和 AdamW 的系统对比
| Dimension | AdamW | Muon | Practical implication |
|---|---|---|---|
| Main update unit | Element | Matrix | AdamW 更通用;Muon 只对矩阵权重有完整意义 |
| Historical state | First moment + second moment | Momentum only | Muon 管理的矩阵参数 optimizer state 更省内存 |
| Adaptivity | Element-wise second moment | Orthogonalized momentum | AdamW 抑制元素级梯度尺度差异;Muon 抑制矩阵奇异方向垄断 |
| Weight decay | Decoupled weight decay is standard | 论文补入 AdamW-style weight decay | 大规模 Muon 不能省略 weight decay |
| Learning rate | 经验最成熟 | 通过 update RMS matching 复用 AdamW LR | Muon 的可用性很大程度来自 LR 迁移 |
| Parameter coverage | Matrix, vector, norm, embedding, LM head | Primarily matrix parameters | 真实系统通常是 Muon + Adam/AdamW hybrid |
| Distributed implementation | ZeRO/FSDP 成熟 | 需要 full-matrix gather + Newton-Schulz | Muon 要改 optimizer kernel 和 sharding 流程 |
| Pre-training | 稳定默认项 | 论文主战场,显示明显训练效率收益 | 从零大规模预训练可考虑 Muon |
| SFT / post-training | 仍是最稳默认项 | 收益依赖 pretraining optimizer,迁移不一定好 | 已有 AdamW checkpoint 不建议盲目切 Muon |
| Stability observability | 指标和经验丰富 | 需要额外看 update RMS、weight RMS、attention logits、SVD spectrum | Muon 上线要加监控,不只是换 optimizer name |
从今天的工程默认看,AdamW 仍然是最稳的起点。它适合绝大多数训练阶段,尤其是 SFT、DPO/RLHF/RLVR、adapter tuning、LoRA、embedding-heavy 任务和短周期实验。Muon 更像是一个面向大规模预训练的强候选:当训练预算足够大、矩阵权重占主要计算、基础设施能支持 full-matrix orthogonalization 时,它可能给出更高 token / FLOP efficiency。
论文里的 Muon 是 hybrid optimizer:矩阵参数用 Muon,RMSNorm、LM head、embedding 等非矩阵参数仍由 Adam/AdamW 风格优化器处理。并且论文附录提到 Moonlight 训练中仍要监控 max attention logit,AdamW 在控制某些 attention logit 行为上更健康。Kimi K2 后续使用的 MuonClip,也可以理解为 Moonshot 在更大规模 MoE 上继续补 Muon 稳定性短板。
如果自己复现实验,优先盯哪些点
- 先做强 AdamW baseline。Muon 论文的可信度来自强 AdamW 对照,不能拿随便调的 AdamW 做结论。
- 只把 Muon 用在矩阵权重上。Norm、bias、embedding、LM head、标量或向量参数继续用 AdamW / Adam。
- 加 decoupled weight decay。论文明确把 weight decay 作为 Muon 大规模可扩展的关键。
- 做 update RMS matching。否则不同形状矩阵的实际步长会错位,学习率迁移也不成立。
- 分布式实现必须保留全矩阵正交化语义。只对 shard 做 Newton-Schulz 不是同一个算法。
- 监控权重 RMS、层输出 RMS、update RMS、grad norm、loss spike 和 max attention logit。
- SFT 不要默认切换。对已有 AdamW checkpoint,先小规模验证 AdamW-SFT、Muon-SFT 和混合方案。
结论
这篇论文最值得记住的不是“Muon 比 AdamW 强”这句口号,而是它给出了一套把新优化器推向大规模 LLM 预训练的标准流程:
- 先解释 optimizer 的更新几何;
- 再解决 weight decay、update scale 和学习率迁移;
- 再解决 ZeRO / DP 下的分布式正交化;
- 然后用 scaling law 和真实 5.7T token 训练同时验证;
- 最后再单独检查 SFT 和稳定性边界。
对高效训练学习来说,Muon 是一个很好的例子:优化器不是只改一行 optimizer = ...,它会牵动参数分组、学习率尺度、数值范围、通信拓扑、checkpoint 状态和后训练可迁移性。AdamW 仍然是大多数项目的默认起点;Muon 则提示我们,在矩阵权重占主导的大模型预训练中,优化器的几何假设本身仍然有很大改进空间。
参考链接
- 论文:Muon is Scalable for LLM Training.
- 论文 HTML 与原图:ar5iv:2502.16982.
- 代码与模型入口:MoonshotAI/Moonlight.
- 模型权重:moonshotai/Moonlight-16B-A3B.
- Title: 论文专题讲解:Muon:LLM 预训练优化器
- Author: Charles
- Created at : 2025-11-10 09:00:00
- Updated at : 2025-11-10 09:00:00
- Link: https://charles2530.github.io/2025/11/10/ai-files-paper-deep-dives-foundations-muon-is-scalable/
- License: This work is licensed under CC BY-NC-SA 4.0.