
论文专题讲解:LWM:百万 token 视频语言世界模型
- 论文:
World Model on Million-Length Video And Language With Blockwise RingAttention - 系统:
Large World Model (LWM) - 链接:arXiv:2402.08268
- 版本:2024-02-13 首次提交,2025-02-03 更新到 v4
- 项目页:Large World Models
- 代码与模型:GitHub、Hugging Face
- 关键词:长上下文、多模态自回归、视频语言模型、VQGAN、RingAttention、百万 token、any-to-any generation
LWM 的核心价值不是把视频扩散模型做得更好看,也不是像 Dreamer 那样训练一个能规划的 latent dynamics。它回答的是另一个世界模型问题:如果把长视频、图像和文本都离散成 token,能不能训练一个 7B 自回归 Transformer 在 1M token 上下文里同时理解和生成这些序列?
这篇论文最值得放进世界模型专题,是因为它把“世界模型”推向了长上下文记忆和多模态序列建模方向:模型不只看几秒钟视频,而是可以在上万帧、一本书、一个小时视频里做检索、问答和生成。
论文位置
在世界模型谱系里,LWM 和 DreamerV3、LingBot-World 的位置不同。
| Dimension | Dreamer / RSSM route | LingBot / video simulator route | LWM route |
|---|---|---|---|
| Core object | latent dynamics for control | video generation as interactive simulator | long multimodal token sequence |
| Main training signal | observation, reward, continuation | video/action/interaction data | next-token prediction |
| Time horizon | rollout horizon for RL | video chunks and interactive rollout | up to 1M tokens |
| Output | latent states, rewards, actions | future video frames | text, image tokens, video tokens |
| Key bottleneck | model-based RL stability | action conditioning and realtime generation | exact long-context attention and data packing |
因此,LWM 更像“长上下文多模态记忆型世界模型”。它不直接输出控制动作,也不保证物理一致的交互模拟;但它证明了一个重要方向:当模型能直接读入海量视频帧和文本时,很多过去需要外部检索或视频摘要的任务可以被统一进一个自回归序列模型。

图源:Large World Model 官方 GitHub/项目页,对应论文 Figure 1。原图展示 LWM 在 1 小时 YouTube compilation、超过 500 个 clips 上回答细粒度问题,并与 GPT-4V、Gemini Pro Vision、Video-LLaVA 做定性对比。
这张图的关键不只是“答对问题”,而是问题依赖长视频中很靠后的局部片段。普通 VLM 只能采样少量帧,容易错过证据;LWM 的目标是让模型直接把长视频帧 token 放进同一个上下文窗口。读这种图时要问三件事:证据是否在长视频远端,模型是否真的看到了足够帧,回答是否依赖细节而不是常识猜测。
核心问题
普通 VLM 常见做法是:
1 | image/video encoder |
这种路线很适合图像问答和短视频理解,但有三个限制:
- 视频通常被强烈下采样,长视频里的细节会丢;
- 视觉通常只能作为输入,模型不能自然生成图像或视频 token;
- 长上下文被 LLM context window 卡住,无法直接建模百万级序列。
LWM 选择了更统一但更重的路线:
1 | text tokens + image tokens + video frame tokens |
视频帧用 VQGAN 离散化,每帧 256 个 image tokens。文本用 BPE token。所有 token 拼成一个序列,模型只做一件事:预测下一个 token。
这样做的好处是统一:
- text-to-image 是从文本 token 继续生成 image tokens;
- image caption 是从 image tokens 继续生成 text tokens;
- text-to-video 是从文本 token 继续生成多帧 image tokens;
- video QA 是从 video tokens 和 question tokens 继续生成 answer tokens;
- pure text long-context retrieval 仍然是文本 next-token prediction。
代价也很明显:每帧 256 个 token,长视频会迅速膨胀到百万 token 级别。LWM 因此必须依赖 RingAttention。
模型结构
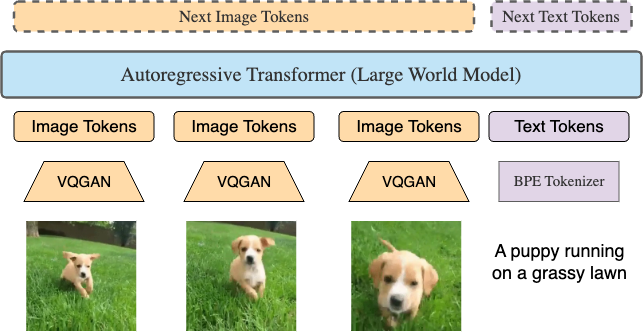
图源:Large World Model 官方 GitHub/项目页,对应论文 Figure 4。原图展示 LWM 是一个 autoregressive Transformer:视频帧经 VQGAN 转为 image tokens,文本经 BPE tokenizer 转为 text tokens,然后拼接进同一个 Transformer 预测下一个 token。
LWM 没有走“视觉编码器输出 embedding,再接 LLM”的常见路线,而是把文本、图像和视频都离散成 token,拼成同一个自回归序列。这样 text-to-image、video QA、image caption 和长文本任务都变成 next-token prediction 的不同格式。代价是 token 数暴涨:视频帧经过 VQGAN 后每帧有大量 image tokens,长视频很快到百万 token,所以 LWM 必须和 RingAttention 这类 exact long-context 训练方法绑定起来读。
LWM 从 LLaMA-2 7B 初始化,保留 decoder-only Transformer 形态。视觉侧使用 aMUSEd 的 VQGAN tokenizer,把图像或视频帧转成离散 token。
| Component | Design |
|---|---|
| Base model | LLaMA-2 7B |
| Text tokenizer | BPE tokenizer |
| Vision tokenizer | pretrained VQGAN from aMUSEd |
| Image tokenization | each image/frame becomes 256 discrete tokens |
| Video tokenization | apply image VQGAN frame by frame, concatenate frame codes |
| Sequence model | autoregressive Transformer |
| Context target | up to 1M tokens |
| Modality delimiters | <vision>, </vision>, <eof>, <eov> |
| Training objective | next-token prediction over text and vision tokens |
特殊 token 的作用很实际:
<vision>和</vision>告诉模型何时进入或退出视觉 token 区段;<eof>表示中间视频帧结束;<eov>表示单张图像或最后一帧视频结束。
这让模型可以学习多种输入输出格式,而不是只能做“视觉输入、文本输出”。
大模型训练路线图
LWM 的训练分两大阶段:
1 | Stage I: Long-context language model |

图源:Large World Model 官方 GitHub/项目页,对应论文 Figure 3。原图展示 Stage 1 从 Books3 做 32K 到 1M context extension;Stage 2 混合图像、短视频、长视频和文本数据,总计约 495B text-vision tokens 与 33B text tokens。
LWM 的训练图不是简单说“最后训练到 1M context”,而是在展示一种成本可控的 progressive curriculum。Stage I 先只做文本长上下文,把 LLaMA-2 7B 从 32K 逐步扩到 1M;Stage II 再把视觉 token 加进同一个自回归序列,从短图文、短视频开始,最后才进入 128K 和 1M 的长视频问答。
这个顺序很重要。每帧视频有 256 个离散视觉 token,长视频很快会变成百万 token 级别;如果一开始就用 1M 视频训练,单步成本太高,视觉语义也还没对齐。LWM 的做法是先在短上下文阶段大量学习视觉-文本对齐,再用少量长上下文阶段学习远程检索和长视频记忆。读这张图时要注意 token 预算分布:真正的大头在 1K/8K,1M 阶段更多是能力延展。
这个图最重要的是“progressive context extension”。直接在 1M token 上训练每一步都很贵,论文估算 7B 模型在 1M 序列上每个 gradient step 约 7 分钟。LWM 因此先学短上下文,再逐步拉长。
Stage I:长上下文语言模型
Stage I 使用 Books3 过滤数据,把 LLaMA-2 7B 扩展到 1M context。RoPE 通过增大 来适配更长上下文。
Table 11: LWM-Text Training Stages
| 32K | 128K | 256K | 512K | 1M | |
|---|---|---|---|---|---|
| Parameters | 7B | 7B | 7B | 7B | 7B |
| Initialize From | LLaMA-2 7B | Text-32K | Text-128K | Text-256K | Text-512K |
| Precision | float32 | float32 | float32 | float32 | float32 |
| Sequence Length | 2^15 | 2^17 | 2^18 | 2^19 | 2^20 |
| RoPE θ | 1M | 10M | 10M | 25M | 50M |
| Tokens per Batch | 4M | 4M | 4M | 4M | 4M |
| Total Tokens | 4.8B | 12B | 12B | 3B | 1.8B |
| Total Steps | 1200 | 3000 | 3000 | 720 | 450 |
| LR Schedule | Constant | Constant | Constant | Constant | Constant |
| LR Warmup Steps | 100 | 200 | 200 | 50 | 25 |
| LR | 4e-5 | 4e-5 | 4e-5 | 4e-5 | 4e-5 |
| Compute (TPU) | v4-512 | v4-512 | v4-512 | v4-512 | v4-512 |
| Mesh Sharding | 1,-1,4,1 | 1,-1,8,1 | 1,-1,16,1 | 1,-1,16,2 | 1,-1,16,4 |
表源:World Model on Million-Length Video And Language With Blockwise RingAttention,Table 11。原论文表格要点:该表列出 LWM-Text 从 32K 到 1M 的 progressive context extension 配置;随着上下文变长,训练 token 数和 step 数下降,但 RoPE 、mesh sharding 和 sequence parallelism 强度逐步提高。
这里的关键不是 token 总量最大,而是训练顺序。越长上下文阶段训练 token 反而更少,因为每一步成本太高。LWM 的假设是:短上下文阶段先学语言和局部依赖,长上下文阶段重点学习位置外推和远程检索。
长上下文 Chat 数据
论文还构造了 model-generated QA 数据来训练长上下文对话能力:
- 把 Books3 文档切成 1000-token chunks;
- 用短上下文模型为每个 chunk 生成一个 QA pair;
- 把相邻 chunks 拼成 32K/128K/更长上下文;
- 在序列末尾追加相关 QA,以 chat 格式训练模型回答。
Chat 微调混合 UltraChat 和自构 QA,大致比例是 7:3。论文特别强调要把 UltraChat 和长文档 QA 分开 packing,因为两类样本 loss token 比例差异很大:UltraChat 是密集短对话,长文档 QA 的 answer token 占比可能小于 1%。
Stage II:视频语言模型
Stage II 从 LWM-Text-1M 初始化,再加入视觉 token。训练不是一次直接上 1M 视频,而是按 1K、8K、32K、128K、1M 逐步做。
Table 13: LWM / LWM-Chat Training Stages
| 1K | 8K | 32K | 128K | 1M | |
|---|---|---|---|---|---|
| Parameters | 7B | 7B | 7B | 7B | 7B |
| Initialize From | Text-1M | 1K | 8K | 32K | 128K |
| Precision | float32 | float32 | float32 | float32 | float32 |
| Sequence Length | 2^10 | 2^13 | 2^15 | 2^17 | 2^20 |
| RoPE θ | 50M | 50M | 50M | 50M | 50M |
| Tokens per Batch | 8M | 8M | 8M | 8M | 8M |
| Total Tokens | 363B | 107B | 10B | 3.5B | 0.4B |
| Total Steps | 45000 | 14000 | 1200 | 450 | 50 |
| LR Schedule | Cosine | Cosine | Cosine | Cosine | Cosine |
| LR Warmup Steps | 1000 | 500 | 100 | 50 | 5 |
| Max LR | 6e-4 | 6e-4 | 8e-5 | 8e-5 | 8e-5 |
| Min LR | 6e-5 | 6e-5 | 8e-5 | 8e-5 | 8e-5 |
| Compute (TPU) | v4-1024 | v4-1024 | v4-1024 | v4-1024 | v4-1024 |
| Mesh Sharding | 1,-1,1,1 | 1,-1,1,1 | 1,-1,4,1 | 1,-1,8,1 | 1,-1,16,4 |
表源:World Model on Million-Length Video And Language With Blockwise RingAttention,Table 13。原论文表格要点:该表列出 LWM / LWM-Chat 的视觉语言训练阶段;大部分 token 和 step 集中在 1K、8K 短上下文视觉对齐,128K 和 1M 阶段主要用于教模型处理长视频上下文。
这张表里最反直觉的是:上下文越长,训练 token 和 step 反而越少。原因不是作者不重视 1M,而是 1M 序列的每个 step 太贵;如果把视觉语义、图文对齐、短视频动态都放到 1M 阶段从零学,成本会不可承受。
因此 LWM 的 recipe 是分工式的:1K 主要学图像-文本和基本视觉 token 语言;8K 学短视频;32K/128K 学视频 QA 和较长上下文;1M 只做少量长视频上下文适配。这个表告诉我们,长上下文训练不一定意味着大部分算力都花在最长序列上,更常见的做法是短上下文密集学习、长上下文少量校准。
这张表说明 LWM 的视觉训练主体算力集中在短上下文视觉对齐阶段:1K 和 8K 分别训练 363B、107B tokens;真正到 1M 阶段只有 0.4B tokens、50 steps。原因很现实:1M 训练用于教模型“能处理极长视频上下文”,不是从零学视觉语义。
数据配比
| Data block | Source | Context | Tokens | Examples | Role |
|---|---|---|---|---|---|
| Text-image | LAION-2B-en + COYO700M | 1K | 400B | 1B | image-text alignment, image generation/caption |
| Short video | WebVid10M + InternVid10M subset | 8K | 90B | 13M | 30-frame video at 4FPS |
| Video instruct | Valley-Instruct-73K + Video-ChatGPT-100K | 32K | 3.2B | 173K | video QA / chat |
| Longer video instruct | Valley-Instruct-73K + Video-ChatGPT-100K | 128K | 1.2B | 173K | 450-frame video chat |
| 1M long video instruct | Valley-Instruct-73K + Video-ChatGPT-100K | 1M | 200M | 173K | 4000-frame long video chat |
| Text | Books3 filtered | 32K-1M | 33B | varies | preserve language and long retrieval |
前两个视觉阶段还额外混入 16% OpenLLaMA 纯文本数据,目的是在引入视觉 token 时保住语言能力。
Masked sequence packing
LWM 一个容易被低估的工程点是 masked sequence packing。普通 packing 会把多个样本拼到一个长序列里,让不同样本互相 attention;这在多模态训练里会产生两个问题:
- 不同 image-text 或 video-text pair 之间相互污染;
- 长视频样本 token 多,短答案样本 token 少,loss 权重会被视觉 token 数量淹没。
LWM 的做法是:
- packing 后用 attention mask 保证每个 text-vision pair 只看自己;
- 重新加权 loss,让它等价于 non-packed + padding 的训练口径;
- 在下游四类任务中做均衡采样:text-image generation、image understanding、text-video generation、video understanding 各占 25%。
Table 10: Masked sequence packing ablation
| Method | VQAv2 | SQA | POPE |
|---|---|---|---|
| Naive Packing | 48.3 | 34.8 | 62.5 |
| LWM (Ours) | 55.8 | 47.7 | 75.2 |
表源:World Model on Million-Length Video And Language With Blockwise RingAttention,Table 10。原论文表格要点:该表消融 masked sequence packing;相比 naive packing,LWM 的 attention mask 与 loss reweighting 在 VQAv2、SQA 和 POPE 上都有明显提升,说明多模态长序列训练不能只靠简单拼接样本。
这张表支持一个很工程化的结论:长上下文训练不只是把更多 token 塞进去。多模态样本长度差异极大,如果 packing 和 loss weighting 不对,模型会明显掉图像理解能力。
RingAttention 为什么必要
LWM 使用 RingAttention 的原因很直接:1M token 精确 attention 不能靠单设备显存硬撑。
RingAttention 的思想是把序列维度切到多个设备上。每个设备持有一个 query block,key/value blocks 在设备环上流动。只要 blockwise attention 的计算时间大于 key/value block 通信时间,通信就能被计算覆盖。
从 LWM 的角度看,RingAttention 不是普通加速 trick,而是训练可行性的前提:
- 允许 exact full attention,不需要滑窗或稀疏近似;
- context length 随 sequence-parallel 设备数线性扩展;
- 可以与 FSDP、tensor parallelism、Pallas/FlashAttention 融合;
- 让视频和书本这种百万 token 序列进入同一个 Transformer。
论文报告 LWM 使用 TPUv4-1024,batch size 8M tokens,并在各训练阶段保持较好的 MFU。推理 1M 序列时至少需要 v4-128,并使用 32 tensor parallelism 和 4 sequence parallelism。
实验结论
长视频理解
LWM 最醒目的能力是 1 小时视频 QA。论文强调,Video-LLaVA 等模型通常只能均匀采样少量帧,例如 8 帧;LWM 可以把上千帧以 token 形式放入上下文,因此更可能保留细粒度时间证据。
这类能力的意义是:世界模型不一定必须“预测未来画面”才有用。能在很长视频历史中检索关键事件、连接前后因果,也是一种世界建模能力。
Image understanding benchmarks
| Method | Visual Token | VQAv2 | GQA | VisWiz | SQA | TextVQA | POPE | MM-Vet |
|---|---|---|---|---|---|---|---|---|
| MiniGPT-4 | CLIP | - | 30.8 | 47.5 | 25.4 | 19.4 | - | 22.1 |
| Otter | CLIP | - | 38.1 | 50.0 | 27.2 | 21.2 | - | 24.6 |
| InstructBLIP | CLIP | - | 49.2 | 34.5 | 60.5 | 50.1 | - | 26.2 |
| LLaVA-1.5 | CLIP | 78.5 | 62.0 | 38.9 | 66.8 | 58.2 | 85.9 | 30.5 |
| LWM (ours) | VQGAN | 55.8 | 44.8 | 11.6 | 47.7 | 18.8 | 75.2 | 9.6 |
表源:World Model on Million-Length Video And Language With Blockwise RingAttention,image understanding benchmark table。原论文表格要点:该表比较 CLIP-based VLM 与 VQGAN-token LWM 在常见图像理解 benchmark 上的表现;LWM 的优势不在短图像理解 SOTA,短板主要来自离散视觉 tokenizer 和从头对齐视觉 token 的难度。
这张表提醒我们不要把 LWM 误读成“短图像理解 SOTA”。它在普通图像理解 benchmark 上明显不如强 CLIP/VLM 路线。原因也合理:VQGAN token 对 OCR 和细文字重建不友好,且 LWM 从离散视觉 token 上从头学习语言-视觉对齐。
Video understanding benchmarks
| Method | Visual Token | MSVD-QA Accuracy | MSVD-QA Score | MSRVTT-QA Accuracy | MSRVTT-QA Score | TGIF-QA Accuracy | TGIF-QA Score |
|---|---|---|---|---|---|---|---|
| VideoChat | CLIP | 56.3 | 2.8 | 45.0 | 2.5 | 34.4 | 2.3 |
| LLaMA-Adapter | CLIP | 54.9 | 3.1 | 43.8 | 2.5 | - | - |
| Video-LLaMA | CLIP | 51.6 | 2.5 | 29.6 | 1.8 | - | - |
| Video-ChatGPT | CLIP | 64.9 | 3.3 | 49.3 | 2.8 | 51.4 | 3.0 |
| Video-LLaVA | CLIP | 70.7 | 3.9 | 59.2 | 3.5 | 70.0 | 4.0 |
| LWM (ours) | VQGAN | 55.9 | 3.5 | 44.1 | 3.1 | 40.9 | 3.1 |
表源:World Model on Million-Length Video And Language With Blockwise RingAttention,video understanding benchmark table。原论文表格要点:该表比较短视频问答 benchmark 上的 CLIP-based 视频 VLM 与 LWM;LWM 在短视频指标上不占优,论文真正强调的是 1M 上下文下的长视频完整输入和长程检索能力。
短视频 benchmark 上,LWM 也不是最强。它的优势主要在“长上下文完整输入”,而不是短视频语义对齐。
生成能力
LWM 可以做 text-to-image 和 text-to-video,因为视觉 token 是模型词表的一部分。生成时使用类似 classifier-free guidance 的 logits guidance:unconditional branch 用 <bos><vision> 初始化,然后和 conditional logits 做混合。
生成能力的意义在于架构统一,但质量不应和扩散模型路线直接比较。LWM 是离散 token 自回归生成,视觉细节和运动质量会受 VQGAN tokenizer 与长序列采样误差限制。
和 RingAttention 的关系
LWM 是 RingAttention 最直接的应用之一。可以把二者关系理解成:
| Layer | Paper | Role |
|---|---|---|
| System primitive | RingAttention | exact long-context Transformer training across many devices |
| Multimodal model | LWM | use that primitive to train million-token video-language AR world model |
RingAttention 解决“怎么让 1M token exact attention 跑起来”;LWM 解决“跑起来后怎么组织视频、图像、文本数据并训练一个多模态模型”。
和 LingBot-World 的关系
LWM 和 LingBot-World 都可以被叫作 world model,但目标完全不同。
| Dimension | LWM | LingBot-World |
|---|---|---|
| Main capability | long video-language understanding and generation | interactive video world simulation |
| Architecture | LLaMA-style autoregressive Transformer | video diffusion / DiT simulator |
| Visual representation | discrete VQGAN tokens | continuous video latent |
| Context | up to 1M tokens | long video rollout / memory |
| Control | no explicit action interface | action-conditioned generation |
| Deployment goal | long-context multimodal reasoning | realtime interactive environment |
两者可以互补。LWM 提供长上下文记忆和多模态 token 统一建模;LingBot-World 提供动作条件和实时视频生成。未来更强的世界模型可能需要同时具备二者:既能保留很长历史,又能根据动作生成可交互未来。
局限与风险
- 不是动作条件世界模型:LWM 没有显式学习 ,不能直接用于闭环控制。
- 视觉 tokenizer 成为瓶颈:每帧 256 个 token 过重,且 VQGAN 对文字、细节和视频一致性不够理想。
- 短图像/短视频 benchmark 不占优:表格显示它在常规 VLM 指标上落后强 CLIP-based 系统。
- 1M context 利用仍不完美:论文在多 needle retrieval 中也看到复杂检索任务随难度上升会退化。
- 训练和推理成本极高:TPUv4-1024 训练、v4-128 级别推理说明这不是轻量路线。
- 生成质量不是视频扩散级别:自回归离散视觉 token 可以生成视频,但视觉保真和运动质量不是这篇论文的强项。
读完应该记住什么
LWM 最重要的启发是:世界模型不一定只能是 latent dynamics 或视频扩散模拟器。另一条路线是把世界经验压成极长的多模态 token 序列,让一个自回归 Transformer 同时学习书本、图像、短视频、长视频和对话。
它的工程经验也很清楚:
- 先扩长文本 context,再做多模态;
- 从短视觉上下文逐步扩到长视频;
- 视觉 token、文本 token 和特殊分隔符统一进 next-token prediction;
- masked sequence packing 和 loss weighting 是多模态长序列训练的必要条件;
- 没有 RingAttention,1M token exact attention 基本不可行。
参考资料
- Liu et al. World Model on Million-Length Video And Language With Blockwise RingAttention. arXiv:2402.08268.
- 官方项目页:Large World Models.
- 官方代码:LargeWorldModel/LWM.
- 论文 HTML 版本:ar5iv:2402.08268v4.
- Title: 论文专题讲解:LWM:百万 token 视频语言世界模型
- Author: Charles
- Created at : 2025-12-19 09:00:00
- Updated at : 2025-12-19 09:00:00
- Link: https://charles2530.github.io/2025/12/19/ai-files-paper-deep-dives-world-models-lwm/
- License: This work is licensed under CC BY-NC-SA 4.0.