
论文专题讲解:RingAttention:近无限上下文训练
- 论文:
Ring Attention with Blockwise Transformers for Near-Infinite Context - 方法:
Ring Attention - 链接:arXiv:2310.01889
- 版本:2023-10-03 首次提交,2023-11-27 更新到 v4
- 代码:GitHub
- 关键词:长上下文、精确注意力、Blockwise Transformer、sequence parallelism、通信计算重叠、百万 token
RingAttention 不是一个直接预测未来视频的世界模型,但它是 LWM 这类百万 token 视频语言世界模型的关键系统底座。它解决的是一个更底层的问题:如果世界经验是长视频、长文本、动作轨迹和多轮交互,Transformer 怎样在不做稀疏近似的情况下看完整序列?
论文的答案是:把序列维度切到多个设备上,每个设备持有一个 query block,让 key/value blocks 沿设备环流动;同时用 blockwise attention 让通信被计算覆盖。
论文位置
长上下文世界模型需要处理三类序列:
- 很长的视频帧序列;
- 很长的文本、代码、书本或网页;
- 很长的交互轨迹,例如状态、动作、奖励、反馈和试错历史。
这些序列都有一个共同问题:如果使用标准 self-attention,激活和 attention matrix 会被序列长度压垮。RingAttention 的价值是让模型仍然使用 exact attention,而不是滑窗、稀疏或检索近似。
| Route | What it changes | Tradeoff |
|---|---|---|
| Sparse / sliding attention | reduce which tokens can attend | cheaper, but loses exact global interaction |
| Retrieval / memory | select external chunks | scalable, but retrieval quality becomes bottleneck |
| FlashAttention / memory-efficient attention | compute attention without materializing full matrix | still limited by layer outputs on one device |
| Blockwise parallel transformer | blockwise attention + FFN | reduces activation memory, still bounded by single-device sequence storage |
| RingAttention | shard sequence across devices and rotate KV blocks | exact attention, context scales with device count |
因此,RingAttention 在世界模型专题中的意义不是“更快 attention”,而是:它让长视频和长交互历史可以被当作一个完整上下文来训练。
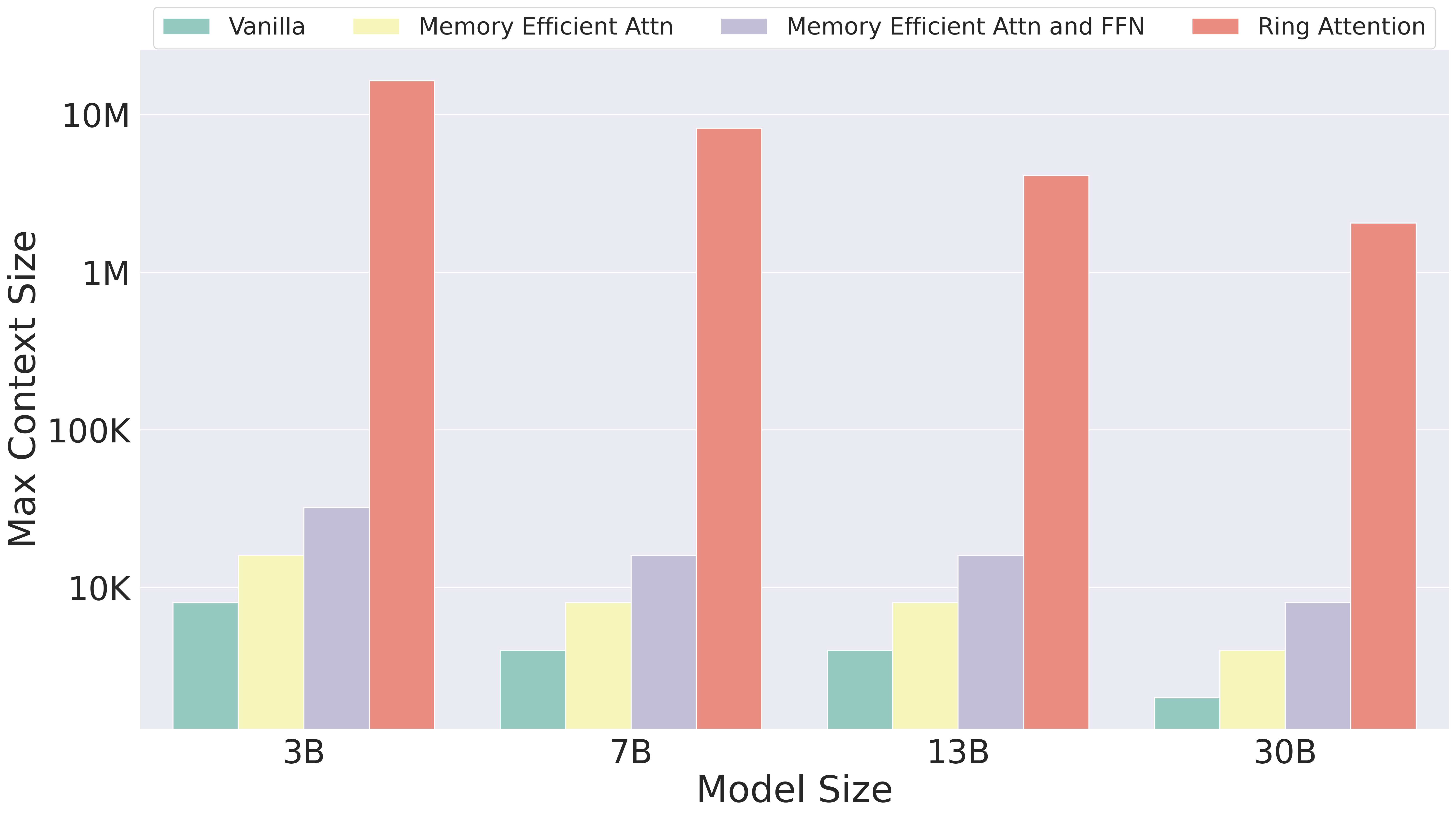
图源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Figure 1。原图比较 TPUv4-1024 上端到端大规模训练可支持的最大 context length,RingAttention 明显高于 vanilla、memory-efficient attention 与 BPT baseline。
这张图不是只在比较 attention kernel 的瞬时显存,而是在比较端到端训练能支撑多长 context。FlashAttention / memory-efficient attention 可以省掉显式 attention matrix,但层输出、KV 分块、前馈层和跨层状态仍会随序列长度增长。RingAttention 的意义是把长序列沿设备切分,并通过环形 KV 传递做 exact attention,让可训练 context 随设备数扩展。对世界模型来说,这决定了模型能不能直接读长视频和长交互历史,而不是只看短窗口摘要。
核心问题
普通 Transformer 的 attention 可以写成:
难点不是只有 attention matrix 本身。FlashAttention 这类方法已经可以避免显式 materialize 。更深的问题是:每一层输出仍然要保留整段序列的 hidden states,下一层 attention 还要访问全部 token。
如果序列长度是 ,hidden size 是 ,batch size 是 ,层输出的存储规模仍随 增长。对于百万级甚至千万级 token,单个设备根本放不下。
RingAttention 的关键观察是:blockwise attention 中,不同 key/value block 的处理顺序可以交换,只要正确维护 softmax 的归一化统计。于是可以把 blocks 放在设备环上轮转。
方法结构
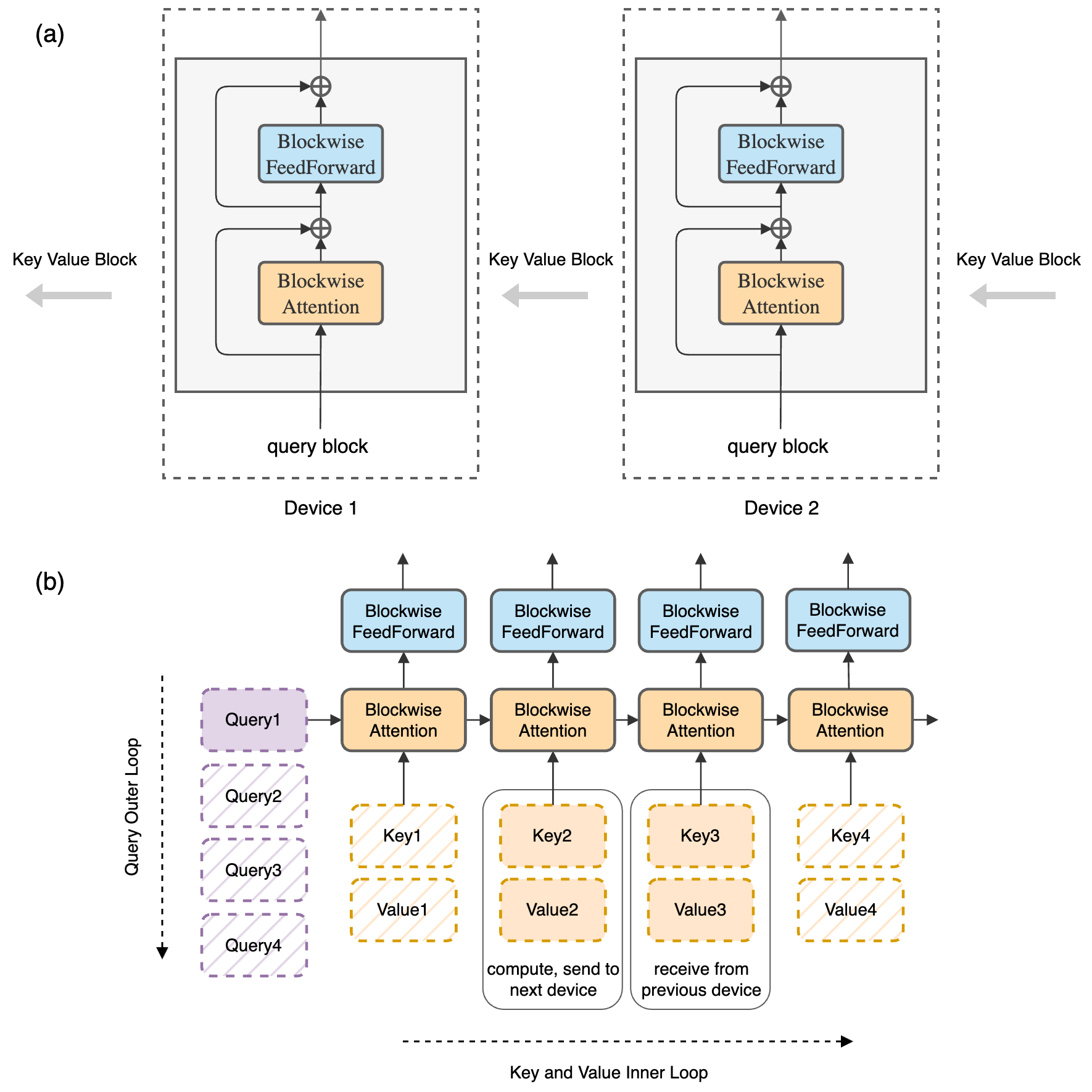
图源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Figure 2。原图上半部分展示多个 host 形成环,query block 留在本设备,key/value block 沿环传递;下半部分展示 query outer loop 和 key/value inner loop 的 blockwise attention 与 feedforward 组织方式。
这张图的核心是“query 不动,KV 转圈”。每个设备只持有长序列的一段 query block,同时也计算本地的 key/value block。随后 key/value block 沿设备环传递;每个设备拿自己的 query 依次和所有传来的 key/value block 做 blockwise attention,并用稳定 softmax 累积结果。
这样做和 sparse attention 不同:RingAttention 没有丢掉远处 token,每个 query 最终仍然 attends to 全序列,所以是 exact attention。它改变的是数据放置和计算顺序,而不是模型定义。读这张图时要注意下半部分的 nested loop:外层固定 query block,内层轮转 key/value block;只要通信能被当前 block attention 的计算时间覆盖,长上下文就可以近似随设备数线性扩展。
方法可以拆成五步:
1 | split long sequence across hosts |
这仍然是原始 Transformer 的精确计算,只是计算顺序和数据放置被重排。
为什么通信可以被覆盖
每个 host 在计算当前 query block 和某个 key/value block 的 attention 时,同时把自己的 key/value block 发给下一个 host,并从上一个 host 接收新的 key/value block。
只要:
通信就不会额外增加 wall-clock overhead。论文把这个条件化成 block size 与 FLOPS/bandwidth 的关系。直觉上,block 不能太小;太小时计算量不够,通信无法被隐藏。
算法直觉
论文的 Algorithm 1 可以改写成更工程化的伪代码:
1 | Given input sequence x and number of hosts Nh: |
这个算法的关键是“query block 不动,key/value blocks 转圈”。每个设备最终都看到了所有 key/value blocks,因此 attention 是全局的。
内存与硬件条件
RingAttention 要成立,不只是算法正确,还需要硬件上通信能被计算覆盖。论文给出不同设备的最小 block size 和最小单设备序列长度。
Table 2: Minimal sequence length needed on each device
| Spec | Per Host FLOPS (TF) | HBM (GB) | Interconnect Bandwidth (GB/s) | Minimal Blocksize (K) | Minimal Sequence Len (K) |
|---|---|---|---|---|---|
| A100 NVLink | 312 | 80 | 300 | 1.0 | 6.2 |
| A100 InfiniBand | 312 | 80 | 12.5 | 24.5 | 149.5 |
| TPU v3 | 123 | 16 | 112 | 1.1 | 6.6 |
| TPU v4 | 275 | 32 | 268 | 1.0 | 6.2 |
| TPU v5e | 196 | 16 | 186 | 1.1 | 6.3 |
表源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Table 2。原论文表格要点:该表把不同硬件的 FLOPS、HBM、互联带宽换算成可隐藏通信所需的最小 block size 和单设备序列长度;高带宽互联下 RingAttention 更容易做到计算覆盖通信。
这张表的工程含义很直接:
- 高带宽互联如 NVLink、TPU ICI 很适合 RingAttention;
- InfiniBand 下最小 block size 大很多,通信更难隐藏;
- RingAttention 更适合本来就很长的序列,因为 block 足够大时 arithmetic intensity 才够。
训练设置
论文实验基于 LLaMA 架构,覆盖 3B、7B、13B、30B 模型规模。baseline 包括:
- vanilla Transformer;
- memory-efficient attention;
- memory-efficient attention + feedforward,也就是 Blockwise Parallel Transformer;
- RingAttention。
训练配置要点:
| Item | Detail |
|---|---|
| Model family | LLaMA-style Transformer |
| Model sizes | 3B, 7B, 13B, 30B; MFU table also reports 65B setting |
| GPU settings | single DGX A100 8 GPUs; distributed 32 A100 GPUs |
| TPU settings | TPUv3, TPUv4, TPUv5e |
| Parallelism baseline | FSDP for max context evaluation |
| Precision note | paper reports results using full precision rather than mixed precision |
| Attention implementation | blockwise attention and feedforward; JAX implementation uses jax.lax.ppermute |
| Code knobs | query_chunk_size, key_chunk_size, causal_block_size, cache_idx, mesh_dim |
论文还强调 RingAttention 和 tensor parallelism 是互补的。模型太大时可以先用 tensor/FSDP 切参数,再用剩余维度做 sequence parallelism。
最大上下文实验
Table 3: Max context size supported
下面按论文 Table 3 的英文格式重绘。数值单位是 x1e3 tokens。
| Compute | Model | Vanilla | Memory Efficient Attn | Memory Efficient Attn and FFN | Ring Attention (Ours) | Ours vs SOTA |
|---|---|---|---|---|---|---|
| 8x A100 NVLink | 3B | 4 | 32 | 64 | 512 | 8x |
| 8x A100 NVLink | 7B | 2 | 16 | 32 | 256 | 8x |
| 8x A100 NVLink | 13B | 2 | 4 | 16 | 128 | 8x |
| 32x A100 InfiniBand | 7B | 4 | 64 | 128 | 4096 | 32x |
| 32x A100 InfiniBand | 13B | 4 | 32 | 64 | 2048 | 32x |
| TPUv3-512 | 7B | 1 | 4 | 8 | 2048 | 256x |
| TPUv3-512 | 13B | 1 | 2 | 8 | 1024 | 128x |
| TPUv4-1024 | 3B | 8 | 16 | 32 | 16384 | 512x |
| TPUv4-1024 | 7B | 4 | 8 | 16 | 8192 | 512x |
| TPUv4-1024 | 13B | 4 | 8 | 16 | 4096 | 256x |
| TPUv4-1024 | 30B | 2 | 4 | 8 | 2048 | 256x |
| TPUv5e-256 | 3B | 4 | 8 | 32 | 4096 | 128x |
| TPUv5e-256 | 7B | 2 | 8 | 16 | 2048 | 128x |
表源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Table 3。原论文表格要点:该表比较 vanilla、memory-efficient attention、BPT 和 RingAttention 在不同硬件/模型规模下支持的最大 context;RingAttention 的可用 context 随 sequence-parallel 设备数近似线性扩展。
这张表比较的是“端到端训练能放下多长 context”,不是某个 attention kernel 单独能算多长。vanilla、memory-efficient attention 和 BPT 的瓶颈都不只在 矩阵,还包括每层 hidden states、FFN 激活和跨层存储。RingAttention 把 sequence dimension 切到多个设备上,因此长序列的 hidden states 也被分摊。
Ours vs SOTA 接近设备数,是这张表最重要的信号。例如 32 张 A100 上能从 128K 到 4096K,TPUv4-1024 上能到数百万 token。对长视频世界模型来说,这意味着模型可以把更长的视频、轨迹或文档当成同一个全局上下文训练,而不是依赖滑窗或检索近似。
这张表是论文最核心的结果。RingAttention 的 context 增长近似等于 sequence-parallel 设备数。例如 32 张 A100 上,7B 模型从 prior SOTA 的 128K 到 4096K;TPUv4-1024 上,7B 模型达到 8192K。
MFU 与吞吐
论文不是只追求“能跑”,还关心 MFU。RingAttention 会让 self-attention 的 FLOPs 比例变高,而 attention 的 MFU 通常低于 FFN,因此 MFU 可能略降;但换来的是数量级更长的 context。
Table 4: Model flops utilization setting
| 7B | 13B | 13B | 30B | 65B | |
|---|---|---|---|---|---|
| Compute | 8x A100 | 8x A100 | 32x A100 | TPUv4-1024 | TPUv4-1024 |
| Memory efficient attention & FFN Context size (x1e3) | 32 | 16 | 64 | 16 | 8 |
| Ring Attention Context size (x1e3) | 256 | 128 | 2048 | 2048 | 1024 |
表源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Table 4。原论文表格要点:该表在 MFU 评估设置下对比 memory-efficient attention + FFN 与 RingAttention 的 context size;RingAttention 支持的上下文显著更长,同时论文强调额外开销较小。
这张表的重点是:在同类训练配置下,RingAttention 支持的 context length 大幅提高,同时论文声称开销很小。对世界模型来说,这比单纯提升 kernel 速度更重要,因为很多任务首先卡在“上下文放不下”。
In-context RL 实验
RingAttention 还被用于长交互轨迹建模。论文在 ExoRL 上比较 BC、Decision Transformer、Algorithm Distillation 类模型,以及使用不同 attention 实现的 AT。
Table 5: Application of Ring Attention on improving Transformer in RL
| Task | BC-10% | DT | AT + ME N Trajs = 32 | AT + BPT N Trajs = 32 | AT + BPT N Trajs = 128 | AT + RA N Trajs = 128 |
|---|---|---|---|---|---|---|
| Walker Stand | 52.91 | 34.54 | oom | 95.45 | oom | 98.23 |
| Walker Run | 34.81 | 49.82 | oom | 105.88 | oom | 110.45 |
| Walker Walk | 13.53 | 34.94 | oom | 78.56 | oom | 78.95 |
| Cheetah Run | 34.66 | 67.53 | oom | 178.75 | oom | 181.34 |
| Jaco Reach | 23.95 | 18.64 | oom | 87.56 | oom | 89.51 |
| Cartpole Swingup | 56.82 | 67.56 | oom | 120.56 | oom | 123.45 |
| Total Average | 36.11 | 45.51 | oom | 111.13 | oom | 113.66 |
表源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Table 5。原论文表格要点:该表把 RingAttention 用到 ExoRL in-context RL,比较 BC、Decision Transformer 和 Algorithm Distillation 类模型;更长 trajectory context 让 AT + RA 在多个任务上略高于短上下文或 OOM 的设置。
这张表和世界模型的关系很强:长交互历史本身就是 agent 的经验记忆。RingAttention 让模型能 condition on 更多 trajectories,而不是只看短窗口。
长文本检索实验
论文还把 LLaMA-13B finetune 到 512K context,并在 line retrieval 上评估。
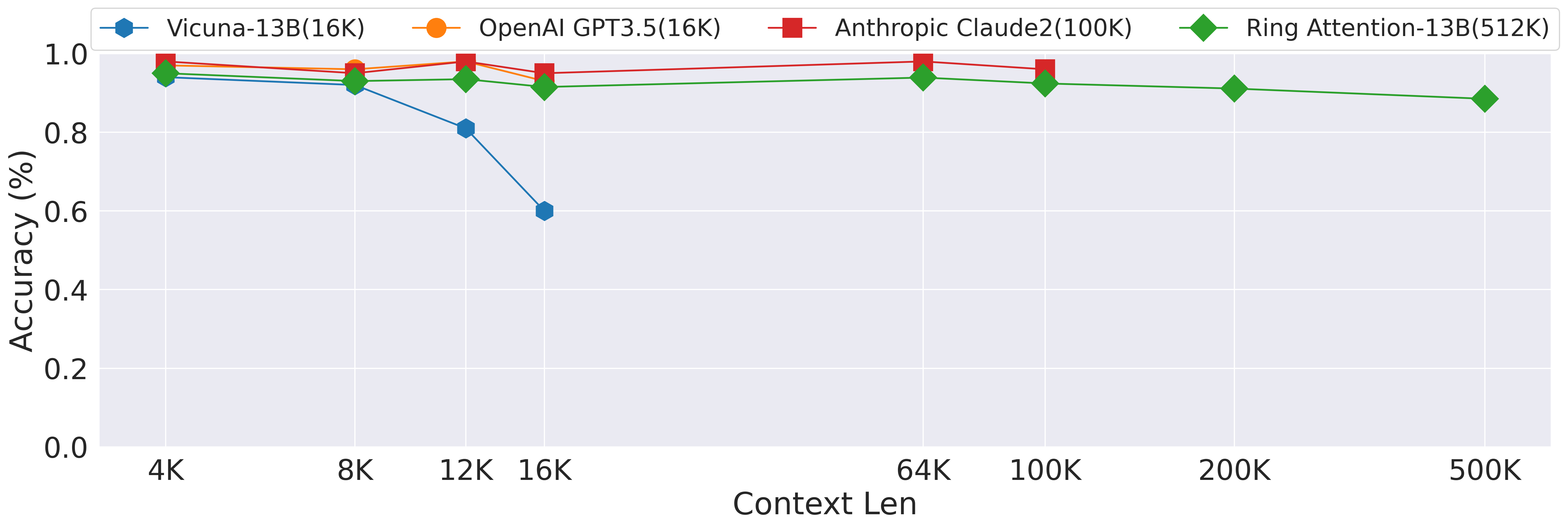
图源:Ring Attention with Blockwise Transformers for Near-Infinite Context,Figure 3。原图展示 Ring Attention-13B-512K 在长上下文 line retrieval 上维持高准确率,而短上下文模型无法覆盖更长范围。
如果只是把 context window 标大,但模型无法在远处找回信息,长上下文就只是配置数字。Line retrieval 把目标行放在很长文本的不同位置,检查模型是否能从远距离取回答案。图里的 RingAttention-13B-512K 维持高准确率,说明长上下文训练确实让模型利用了更远 token。它并不等于复杂推理完全解决;后续 LWM 中也能看到 multi-needle 任务会随难度上升退化。
和 LWM 的关系
RingAttention 和 LWM 的关系可以压缩成一句话:RingAttention 让 1M token exact attention 可训练,LWM 把这个能力用于视频、图像和文本的统一自回归建模。
| Layer | RingAttention | LWM |
|---|---|---|
| Main problem | sequence too long for exact Transformer training | train a 1M-context multimodal model |
| Main object | attention/FFN computation over sharded sequence | text, image, video token sequence |
| Contribution | context scales with device count | long video-language understanding and generation |
| Evaluation | context length, MFU, RL, line retrieval | long video QA, needle retrieval, VLM benchmarks |
| Failure mode | depends on hardware bandwidth and block size | depends on tokenizer, data balance, multimodal alignment |
从工程项目角度看,二者不能分开理解。只读 LWM 会低估系统实现难度;只读 RingAttention 会看不出它为什么对世界模型有意义。
最值得复用的设计经验
1. Exact attention 和长上下文可以通过系统重排获得
很多长上下文方法从算法上牺牲 attention 范围。RingAttention 的路线相反:保持 exact attention,把序列维度跨设备分布,通过 blockwise computation 和 ring communication 解决显存问题。
2. 通信不是一定要成为瓶颈
如果 block 足够大,计算可以覆盖通信。这个原则对大模型训练很重要:不是所有分布式切分都会慢,关键是 arithmetic intensity 和通信拓扑是否匹配。
3. sequence parallelism 应和 FSDP / TP 组合设计
RingAttention 切的是序列维度;FSDP 切参数和优化器状态;TP 切矩阵乘。大模型项目里不能孤立选择一种并行策略,而要根据模型大小、context length 和硬件拓扑共同分配 mesh。
4. 对世界模型,长上下文是能力边界
视频、动作轨迹和试错历史天然很长。如果系统只能看短窗口,模型会被迫依赖摘要、检索或稀疏采样。RingAttention 给了另一种选择:直接训练模型看完整长序列。
局限与风险
- 硬件依赖强:高带宽互联是关键,A100 InfiniBand 的最小 block size 明显更大。
- 不是免费长上下文:单个 dataset token 的训练 FLOPs 仍会随 context 增长,只是显存瓶颈被解除。
- 只解决可计算性,不解决数据质量:模型能看 1M token,不代表数据里有可学习的长程结构。
- 长上下文利用仍需评测:needle retrieval 容易,复杂多跳、因果和规划任务仍可能退化。
- 实现复杂度高:需要 blockwise attention、通信重叠、mesh sharding、checkpointing 和框架支持。
- 不直接产生世界模型能力:它是训练基础设施,真正的世界建模仍取决于 LWM、视频模型或 agent 模型的目标函数和数据。
读完应该记住什么
RingAttention 的核心贡献是把 Transformer 长上下文瓶颈从“单设备显存上限”改成“设备数和互联带宽共同决定的系统问题”。这让百万 token 的视频、语言和交互轨迹训练变得实际可行。
在世界模型方向,它的意义可以概括为:
1 | world experience is long |
参考资料
- Liu et al. Ring Attention with Blockwise Transformers for Near-Infinite Context. arXiv:2310.01889.
- 官方代码:haoliuhl/ringattention.
- 论文 HTML 版本:ar5iv:2310.01889.
- LWM 项目页:Large World Models.
- Title: 论文专题讲解:RingAttention:近无限上下文训练
- Author: Charles
- Created at : 2025-12-23 09:00:00
- Updated at : 2025-12-23 09:00:00
- Link: https://charles2530.github.io/2025/12/23/ai-files-paper-deep-dives-world-models-ringattention/
- License: This work is licensed under CC BY-NC-SA 4.0.