
量化:FP8 与混合精度推理
FP8 是低精度路线里很重要的一类:它比 FP16/BF16 更省显存和带宽,又比 INT4/INT8 更保留浮点的动态范围直觉。很多生产系统会把 FP8 放进混合精度方案,而不是全模型统一压到最低 bit。
这页先回答“FP8 与混合精度推理”在「量化」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先懂张量、线性层和基本推理成本;遇到 FP8、KV Cache、outlier 时回前置页补概念。 必要时先回 量化入口、基础知识 或 术语表。
主线关系:把数值格式、误差来源、校准/训练方法、kernel 和服务部署连成一条效率链,而不是只比较 bit 数。
FP8 不是“8bit 的 INT”。它仍然是浮点数,有 sign、exponent 和 mantissa。指数位让它更擅长覆盖大动态范围,尾数位决定局部精度。
FP8 在解决什么问题
大模型推理和训练常被三类成本卡住:
| 成本 | FP8 可能帮什么 |
|---|---|
| 权重显存 | 每个元素从 2 bytes 降到 1 byte |
| 激活/中间张量 | 减少 HBM 读写和缓存压力 |
| GEMM 吞吐 | 新 GPU 上可走 FP8 tensor core |
但 FP8 的收益不是自动的。它需要硬件、kernel、scale 策略、累加精度和敏感层保护一起成立。
E4M3 和 E5M2 怎么读
FP8 常见两种格式:
| 格式 | 拆法 | 直觉 | 常见用途 |
|---|---|---|---|
| E4M3 | 4 个 exponent bit,3 个 mantissa bit | 精度相对好,范围较小 | 前向权重、激活 |
| E5M2 | 5 个 exponent bit,2 个 mantissa bit | 范围更大,精度更粗 | 梯度、反向或范围更大的张量 |
一个浮点数可以粗略理解成:
| 符号 | 含义 |
|---|---|
| 符号位,决定正负 | |
| exponent,决定数量级范围 | |
| mantissa/significand,决定这个数量级里的细节 |
读作什么:exponent 管“能表示多大或多小”,mantissa 管“表示得多细”。E5M2 范围更宽,E4M3 细节更多。
同样是 8bit,FP8 和 INT8 误差形态不同。INT8 依赖 scale 把真实数映射到均匀整数格子;FP8 用指数覆盖动态范围,但每个数量级里的精度有限。
FP8 也需要 scale
深度学习里的 FP8 通常不会直接裸用,而是配合 scale:
| 符号 | 含义 |
|---|---|
| 原始 BF16/FP16/FP32 张量 | |
| scale,用来把张量范围放进 FP8 可表示区间 | |
| FP8 格式下的低精度值 | |
| 还原到较高精度参与后续计算的近似值 |
读作什么:scale 让张量整体落到 FP8 舒适区间。scale 选太小会 overflow,选太大会损失细节。
| scale 策略 | 含义 | 代价 |
|---|---|---|
| per-tensor | 整个张量一个 scale | 简单但怕局部 outlier |
| per-channel/per-block | 每通道或每块一个 scale | 更稳但元数据和 kernel 更复杂 |
| delayed scaling | 用历史 amax 更新 scale | 稳定但可能滞后 |
| dynamic scaling | 当前 batch 即时统计 | 灵活但有在线开销 |
为什么 FP8 常比 INT4 更容易进生产
| 维度 | FP8 | INT4/W4A16 |
|---|---|---|
| 动态范围 | 浮点指数更自然 | 强依赖 scale 和 group |
| 压缩率 | 约 FP16 的 1/2 | 权重可约 1/4 |
| kernel 生态 | 新 GPU 上路径更标准 | 依赖具体格式和实现 |
| 质量风险 | 通常更温和 | 低 bit 更激进 |
| 适用对象 | 权重、激活、训练中间态 | 多用于 weight-only 或特定 kernel |
读作什么:FP8 不一定压得最狠,但它常常是质量、硬件和维护成本之间更稳的折中。
混合精度不是妥协,而是资源分配
成熟系统不会把所有东西都降到同一精度。常见混合方式:
| 模块 | 常见精度策略 | 原因 |
|---|---|---|
| 大部分 Linear/GEMM | FP8、INT8 或 W4A16 | 算力和带宽收益最大 |
| LayerNorm/RMSNorm | FP16/BF16 | 归一化对小数值变化敏感 |
| Softmax | FP16/BF16 或更高保护 | 指数和概率归一化敏感 |
| residual add | FP16/BF16 | 误差会跨层累积 |
| embedding/lm head | 任务相关,常保守 | 词表和输出分布敏感 |
| KV cache | FP16/BF16/FP8/INT8 按场景 | 长上下文显存大,但质量风险要验 |
| 多模态 projector/action head | 常保高精 | 对齐、坐标、动作更敏感 |
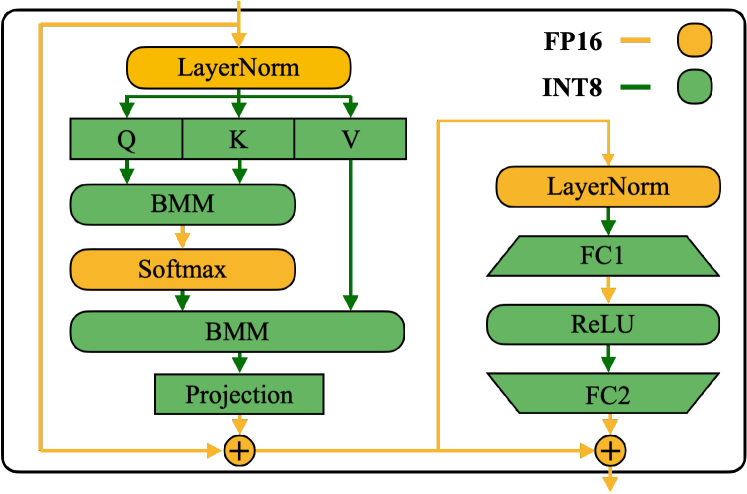
图源:SmoothQuant,Figure 6。原论文图意:Transformer block 中,部分矩阵乘可以走 INT8 路径,LayerNorm、Softmax、残差加法等敏感或不适合低精度的算子仍保留 FP16。
虽然这张图来自 SmoothQuant 的 INT8 路线,但它表达的系统原则同样适用于 FP8:低精度优先放在收益最大的矩阵乘路径,数值敏感或不划算的路径保高精。
FP8 服务要看哪些收益
| 指标 | 为什么重要 |
|---|---|
| peak memory | 权重和激活是否真的省显存 |
| TTFT | prefill 和调度是否受益 |
| TPOT | decode 每 token 是否变快 |
| throughput | batch 后单位时间 tokens 是否增加 |
| P95/P99 | 低精度路径是否引入长尾 |
| kernel trace | 是否命中 FP8 GEMM 或 fallback |
| quality buckets | 代码、数学、长上下文、多模态是否掉点 |
一个更实用的判断式:
| 符号 | 含义 |
|---|---|
| quality kept | 任务质量保留程度 |
| throughput gain | 吞吐或延迟收益 |
| engineering complexity | 格式转换、kernel、监控和维护成本 |
| fallback risk | 不同 shape 或模块回退到高精路径的风险 |
读作什么:FP8 是否值得,不是只看快了多少,还要看质量和维护成本。
哪些层优先尝试 FP8
| 优先级 | 模块 | 原因 |
|---|---|---|
| 高 | 大型 Linear、MLP、attention projection | GEMM 密集,硬件收益明显 |
| 中 | attention 中间路径、部分 expert | 需要看实现和任务质量 |
| 低 | LayerNorm、Softmax、残差、采样逻辑 | 数值敏感或收益小 |
| 保守 | 多模态 projector、动作头、安全头 | 局部误差可能放大成任务失败 |
实用做法:先让大块 GEMM 进 FP8,再用混合精度保护掉点层,而不是一开始追求全模型 FP8。
三个部署场景
场景 A:70B 文本模型服务
目标是降低显存和提高吞吐。可以先评估 FP8 权重/激活路径,保留 LayerNorm、Softmax 和输出相关路径高精。验收时看长上下文、代码、数学和工具调用。
场景 B:企业文档 VLM
FP8 可以用于 LLM 主体和部分视觉 MLP,但 projector、OCR 相关层和表格结构头要保守。验收不能只看问答,要看金额、小数点、字段定位和跨页关联。
场景 C:VLA 或世界模型
低精度优先放在高吞吐的中间 backbone;动作头、risk head、控制接口和短 horizon 纠错路径优先保高精。验收看闭环成功率、动作抖动、near-miss recall 和长时 latent drift。
FP8 的短板
| 短板 | 说明 |
|---|---|
| 不如 INT4 压缩激进 | 主要是 8bit,压缩率较温和 |
| 依赖新硬件和 kernel | 没有原生路径时收益有限 |
| scale 管理复杂 | outlier、amax、delayed scaling 会影响稳定 |
| 不适合所有算子 | 归一化、softmax、残差常要保高精 |
| 仍需专项回归 | 平均 benchmark 不足以证明生产稳定 |
落地顺序
- 固定 BF16/FP16 baseline,记录质量、显存、TTFT、TPOT、吞吐。
- 确认目标硬件和 runtime 是否支持 FP8 GEMM、FP8 KV 或相关格式。
- 先把大块 Linear/GEMM 迁到 FP8,保留敏感算子高精。
- 记录 scale 策略、amax、overflow/fallback 和 kernel trace。
- 对任务桶做回归,尤其是长上下文、代码、数学、多模态细节和安全/动作模块。
- 如果掉点集中在少数层,优先混合精度保护,而不是整体放弃 FP8。
本页结论
FP8 的价值不是最低 bit,而是把显存、带宽、硬件吞吐和质量稳定性放进同一个折中点。它适合和混合精度一起理解:大块矩阵乘低精,敏感路径保高精,最终用端到端指标和任务桶决定是否上线。
- 回到本专题入口:量化,确认这页在整条路线中的位置。
- 按导航顺序继续:量化服务栈与硬件选择。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 量化:FP8 与混合精度推理
- Author: Charles
- Created at : 2025-12-31 09:00:00
- Updated at : 2025-12-31 09:00:00
- Link: https://charles2530.github.io/2025/12/31/ai-files-quantization-fp8-and-mixed-precision-serving/
- License: This work is licensed under CC BY-NC-SA 4.0.