
量化:PTQ、GPTQ、AWQ 与 SmoothQuant
这一页讲最常见的后训练量化路线。它们都在回答同一个问题:模型已经训练好了,不想重新大规模训练,怎样把权重或激活压低 bit,同时让输出尽量不变。
这页先回答“PTQ、GPTQ、AWQ 与 SmoothQuant”在「量化」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先懂张量、线性层和基本推理成本;遇到 FP8、KV Cache、outlier 时回前置页补概念。 必要时先回 量化入口、基础知识 或 术语表。
主线关系:把数值格式、误差来源、校准/训练方法、kernel 和服务部署连成一条效率链,而不是只比较 bit 数。
PTQ 是大类,意思是 post-training quantization,训练后再量化。GPTQ、AWQ 和 SmoothQuant 是 PTQ 里的代表方法:GPTQ 做误差补偿,AWQ 保护激活敏感通道,SmoothQuant 把 activation outlier 的难度迁移到权重侧。
PTQ 先解决什么
PTQ 的基本形式仍然是量化和反量化:
| 符号 | 含义 |
|---|---|
| 原始浮点权重或激活 | |
| 低比特整数值 | |
| 反量化后的近似值 | |
| scale,控制格子宽度 | |
| zero-point,让真实 0 对齐整数格点 | |
| 当前 bit 数可表示的整数范围 |
读作什么:PTQ 不改变原始训练过程,而是在模型训练完成后,把部分张量映射到低比特表示,再尽量让推理输出保持接近。
初学者直觉:像把一张高清照片压缩。大块颜色可能没问题,小字、边缘和暗部细节最容易先坏。量化里,小字和边缘常对应 outlier 通道、敏感层、长上下文 KV 或高风险任务。
量化后真正要保的是矩阵乘输出
线性层原本是:
量化后希望:
| 符号 | 含义 | 常见 shape |
|---|---|---|
| 输入激活 | ||
| 权重矩阵 | ||
| 原始输出 | ||
| 量化再反量化后的激活 | 同 | |
| 量化再反量化后的权重 | 同 |
读作什么:量化不是让每个数字都一模一样,而是让这些数字参与矩阵乘后,输出还足够像原模型。
权重 MSE 小,不一定代表模型输出好。某些权重误差虽小,但如果正好落在高敏感方向或高激活通道上,输出会明显变差。
基础 PTQ:便宜,但不懂哪里敏感
最朴素的 PTQ 会按层或按组估计 scale,然后直接 round。它的优点是快、便宜、容易跑通,适合做第一个 baseline。
| 设计点 | 初学者问题 | 常见选择 |
|---|---|---|
| 压什么 | 只压权重,还是权重和激活都压 | 先从 weight-only 更稳 |
| scale 粒度 | 一个 scale 管整层还是一组通道 | group-wise 常是折中 |
| 校准数据 | 用什么输入估计分布 | 要贴近真实流量 |
| bit 数 | INT8、INT4 还是混合 | 越低越需要保护 |
它的短板:基础 PTQ 通常不知道哪些层、哪些通道、哪些方向更敏感。因此 8bit 可能还好,4bit 或 W&A 量化就容易出现明显掉点。
GPTQ:用补偿减少一层输出误差
GPTQ 常用下面的目标来理解:
| 符号 | 含义 |
|---|---|
| 原始权重 | |
| 量化后的权重 | |
| 校准集激活,用来代表真实输入 | |
| 输出差异的平方和 |
读作什么:GPTQ 不只是让 接近 ,而是让它们乘上校准激活后,输出尽量接近。
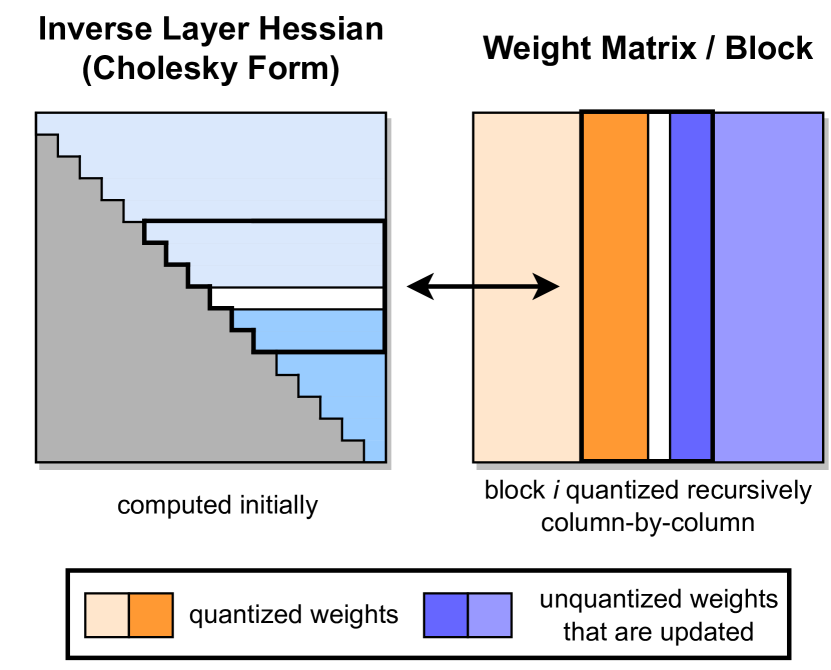
图源:GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,Figure 2。原论文图意:左侧是层内 inverse Hessian 的 Cholesky 形式,右侧是按列递归量化的权重块;已量化列固定,未量化列会根据量化误差被更新补偿。
右边的矩阵块可以想成一排待量化的列。GPTQ 量化一列后,不是把误差丢掉,而是用近似二阶信息把误差传播给后面还没量化的列。这样做的目标不是让每个权重数值最像,而是让这一层在校准输入上的输出最像。
GPTQ 的关键直觉
如果某个方向对输出或 loss 很敏感,同样大小的量化误差会造成更大伤害。GPTQ 使用 Hessian 或近似二阶信息来判断这些敏感方向,并在逐列量化时做补偿。
| 优点 | 代价 |
|---|---|
| 对 4bit weight-only 友好,离线效果常较稳 | 量化预处理比基础 PTQ 更复杂 |
| 不需要重新训练全模型 | 强依赖校准数据和具体实现 |
| 适合已有大模型 checkpoint | 速度收益仍取决于 runtime 和 kernel |
AWQ:重要不只看权重,还看激活
AWQ 的核心可以用通道贡献来理解:
| 符号 | 含义 |
|---|---|
| 输入通道或 hidden 维索引 | |
| 第 个通道的激活 | |
| 第 个通道对应的权重 | |
| 该通道对输出的贡献 |
读作什么:某个权重是否重要,不只取决于它自己多大,还取决于真实输入里对应激活是否经常很大。
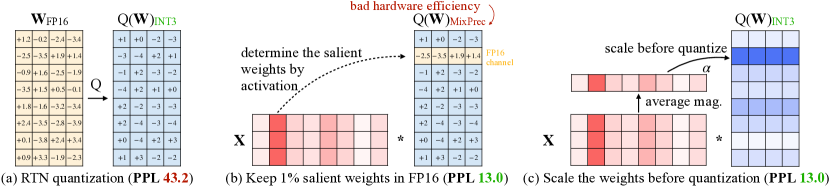
图源:AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration,Figure 1。原论文图意:普通 RTN 量化会明显升高困惑度;保留少量 activation-salient weights 或在量化前按激活幅度缩放权重,可以显著恢复质量。
这张图的重点是“少量关键权重很重要”。AWQ 用校准激活找出那些被真实输入频繁放大的通道,并通过缩放或保护让这些通道在量化后少受伤。
AWQ 和 GPTQ 的区别
| 方法 | 更关注什么 | 初学者理解 |
|---|---|---|
| GPTQ | 量化误差如何通过一层输出传播 | 量一部分,补后一部分 |
| AWQ | 哪些权重通道被真实激活放大 | 重要通道别粗暴压 |
AWQ 往往适合工程部署,因为它流程相对轻,和 weight-only 低比特服务路径结合得比较自然。
SmoothQuant:把 activation outlier 的难度迁移到权重
激活量化比权重量化难,主要因为 activation 是动态的,且容易出现 outlier。SmoothQuant 的核心等价变换是:
| 符号 | 含义 |
|---|---|
| 原始 activation | |
| 原始 weight | |
| 对角缩放矩阵,每个通道一个缩放因子 | |
| 被平滑后的 activation | |
| 承接缩放后的 weight |
读作什么:输出 不变,但 activation 的尖峰被压平一部分,难度被转移到更容易离线处理的权重上。
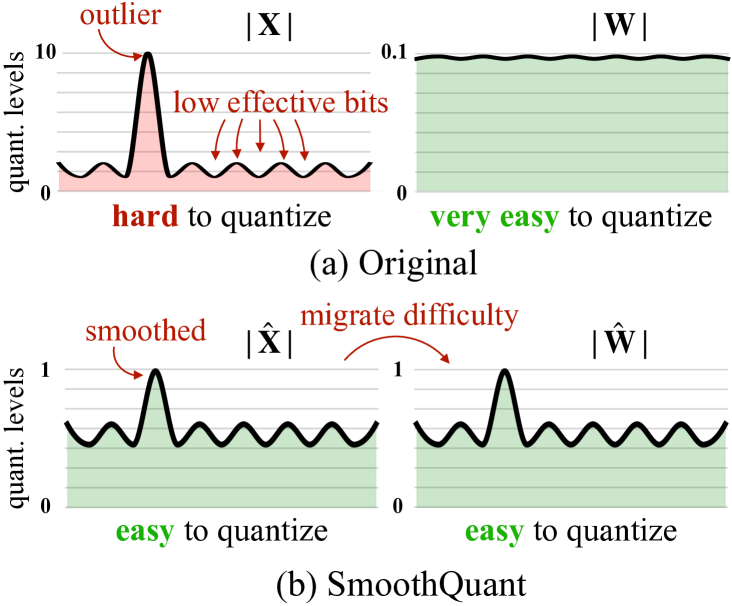
图源:SmoothQuant,Figure 2。原论文图意:原始激活 含有 outlier,导致有效量化 bit 变少;SmoothQuant 将一部分难度从 activation 迁移到 weight,让两侧都更容易量化。
左边说明 activation outlier 会占据量化范围,让主体数值只有很少格子可用。右边说明 SmoothQuant 不是简单裁剪 outlier,而是通过等价缩放把 activation 变平滑,同时让权重吸收相反缩放。
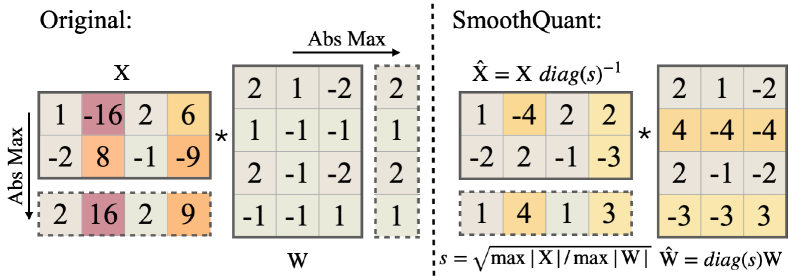
图源:SmoothQuant,Figure 5。原论文图意:通过离线迁移 activation 的量化难度,让权重和激活都更适合 INT8 量化。
这张图强调“迁移”。activation 是线上动态生成的,处理 outlier 更麻烦;权重是静态的,可以离线吸收一部分缩放。因此 SmoothQuant 更适合推动 W8A8 这类权重和激活都低比特的路径。
哪些算子该低精,哪些要保高精
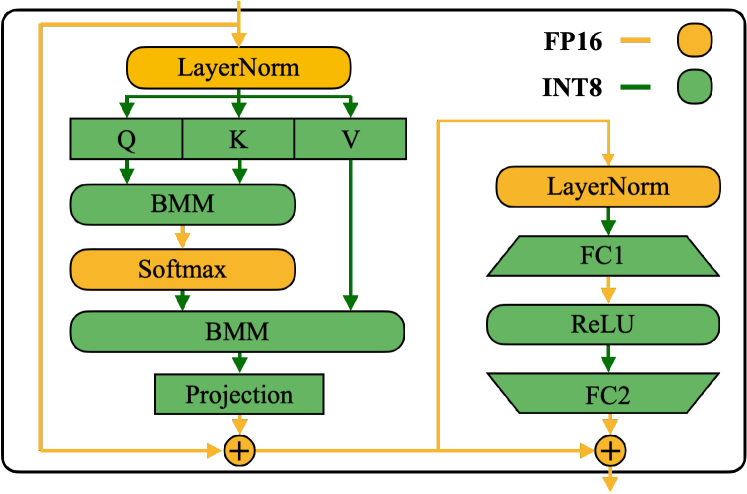
图源:SmoothQuant,Figure 6。原论文图意:Transformer block 中,部分矩阵乘可以走 INT8 路径,LayerNorm、Softmax、残差加法等敏感或不适合低精度的算子仍保留 FP16。
这张图告诉你:成熟部署通常是混合精度。GEMM 更适合低比特加速,但 LayerNorm、Softmax、residual add、某些输出头和安全/动作模块常常要保高精。
这几种方法怎么选
| 场景 | 推荐起点 | 原因 |
|---|---|---|
| 先让大模型放进单卡 | AWQ 或 GPTQ 的 W4A16 | weight-only 成熟,部署风险较低 |
| 追求 INT8 W&A 服务 | SmoothQuant | 重点处理 activation outlier |
| 只有少量校准数据 | 先用基础 PTQ 或 AWQ 小步试 | 复杂方法也需要代表性校准 |
| 高质量生产服务 | 混合精度 + 任务桶回归 | 关键层不必都压到最低 bit |
| 长上下文并发压力大 | 权重量化后继续看 KV cache | 权重不是唯一显存大头 |
不要只根据“论文里哪个困惑度最低”选方案。还要看目标模型结构、校准集、runtime 支持、目标 GPU、batch/context 分布和任务桶。
一个最小实践顺序
- 先跑 FP16/BF16 baseline,记录质量、显存、TTFT、TPOT、吞吐。
- 先试 W8 或 W4 weight-only,确认模型能加载、质量基本可接受。
- 对比 GPTQ/AWQ 的校准样本和 group size,观察任务桶差异。
- 如果要推进 activation 量化,再看 SmoothQuant 或更稳的 FP8/W8A8 路线。
- 用 profiler 确认低比特 kernel 是否命中,记录 dequant 时间和 fallback。
- 对长上下文、多轮工具、多模态、代码、数学和高价值业务样本单独回归。
本页结论
PTQ 是训练后压缩的大框架;GPTQ 用补偿保护层输出;AWQ 用激活统计保护关键通道;SmoothQuant 把激活离群值迁移到权重侧,让 W&A 量化更容易。它们都不是“越低 bit 越好”的证明,而是在不同约束下,把误差安排到更不伤模型输出的位置。
下一步建议读 激活离群值与校准策略,因为理解 outlier 和 calibration 后,GPTQ、AWQ、SmoothQuant 的取舍会清楚很多。
- 回到本专题入口:量化,确认这页在整条路线中的位置。
- 按导航顺序继续:激活离群值与校准策略。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 量化:PTQ、GPTQ、AWQ 与 SmoothQuant
- Author: Charles
- Created at : 2026-01-01 09:00:00
- Updated at : 2026-01-01 09:00:00
- Link: https://charles2530.github.io/2026/01/01/ai-files-quantization-ptq-gptq-awq-smoothquant/
- License: This work is licensed under CC BY-NC-SA 4.0.