
量化:QAT、Kernel 与 KV Cache
这一页把三件常被混在一起的事情拆开:QAT 解决模型怎样适应量化误差,kernel 决定低比特是否真的跑得快,KV cache quantization 解决长上下文推理里的动态显存和带宽。
这页先回答“QAT、Kernel 与 KV Cache”在「量化」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先懂张量、线性层和基本推理成本;遇到 FP8、KV Cache、outlier 时回前置页补概念。 必要时先回 量化入口、基础知识 或 术语表。
主线关系:把数值格式、误差来源、校准/训练方法、kernel 和服务部署连成一条效率链,而不是只比较 bit 数。
QAT 是训练方法,kernel 是执行路径,KV cache 是推理时不断增长的缓存。它们都和量化有关,但不在同一层。
QAT 在优化什么
QAT,quantization-aware training,会在训练时模拟量化误差。一个简化目标可以写成:
| 符号 | 含义 |
|---|---|
| 原始模型参数 | |
| 前向中经过 fake quant 或低比特模拟的参数 | |
| 训练输入 | |
| 标签或目标输出 | |
| 带量化噪声的模型输出 | |
| 训练损失 |
读作什么:训练时就让模型看到量化后的自己,让它学会在低比特误差存在时仍然输出正确结果。
fake quant 怎么理解
训练中常见 fake quant 形式:
| 符号 | 含义 |
|---|---|
| 高精度训练张量 | |
| 模拟量化再反量化后的张量 | |
| scale 和 zero-point |
读作什么:前向时加入量化误差,反向时通常用近似梯度让训练能继续。这和 PTQ 的区别是:PTQ 是训练完才压,QAT 是训练时就适应。
什么时候值得做 QAT
| 场景 | 为什么 PTQ 可能不够 |
|---|---|
| 低到 4bit/2bit 或更激进 | 误差太大,单纯校准难恢复 |
| W&A 同时量化 | activation 动态变化大 |
| 高质量生产服务 | 关键任务掉点不可接受 |
| 多模态/VLA | 视觉、动作、安全头更敏感 |
| 特定硬件低比特路径 | 模型要配合硬件格式和 kernel |
一句话:PTQ 是低成本起点;QAT 是质量门槛更高时,让模型主动适应低比特。
Kernel 决定收益是否兑现
量化线性层不只是 ,真实执行常包含:
1 | load packed low-bit weight |
两条常见路径:
| 路径 | 发生什么 | 主要收益 | 风险 |
|---|---|---|---|
| weight-only + dequant | 权重低比特存储,计算前反量化到 FP16/BF16 | 省权重显存和带宽 | GEMM 本身未必低比特 |
| W&A low-bit kernel | 权重和激活都低比特,直接走 INT/FP8 matmul | 有机会同时省带宽和计算 | 对硬件、layout、scale 粒度要求高 |
“runtime 支持 INT4”不等于每个请求都走高效 INT4 kernel。实际可能因为模型结构、group size、GPU 架构、batch shape 或 LoRA 组合而 fallback。
Q/DQ、packing、dequant fusion 分别是什么
| 名称 | 含义 | 初学者理解 |
|---|---|---|
| Q | quantize,把浮点转低比特 | 把数塞进格子 |
| DQ | dequantize,把低比特还原近似浮点 | 取出来再乘 scale |
| packing | 把多个低比特值塞进一个更大 word | 例如 8 个 INT4 放进 32bit |
| fusion | 把 dequant 和 GEMM 等操作合并 | 减少中间读写和 kernel launch |
| accumulation | 矩阵乘累加精度 | 低比特输入常用更高精累加 |
读作什么:量化收益常常死在 Q/DQ 和 scale 读取上。好的 kernel 会尽量把 unpack、scale 和 matmul 融合进一条高效路径。
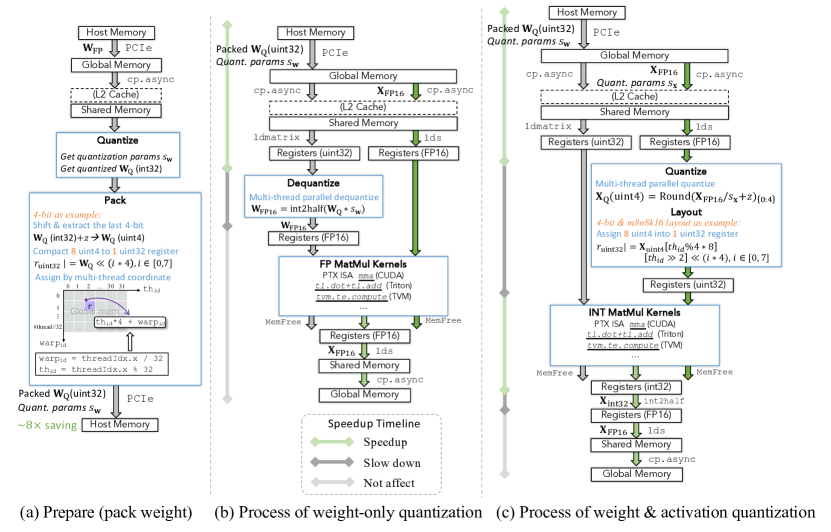
图源:A Survey of Low-bit Large Language Models,Figure 5。原论文图意:展示 quantized weight preparation、weight-only quantization 和 weight & activation quantization 的数据传输过程。
左边是离线准备和 packing;中间是 weight-only,搬运低比特权重但计算前可能 dequant 到 FP;右边是 W&A,目标是让 activation 和 MatMul 也进入低比特路径。绿色箭头是潜在收益,灰色箭头是新增开销。
KV cache 为什么是长上下文主角
生成模型每生成一个 token,都要保存每层历史 token 的 Key 和 Value。KV cache 显存可粗略估算为:
| 符号 | 含义 |
|---|---|
| K 和 V 两份缓存 | |
| Transformer 层数 | |
| batch 或并发序列数 | |
| 上下文长度 | |
| KV head 数 | |
| 每个 head 的维度 | |
| 每个元素占用字节数 |
读作什么:上下文越长、并发越高、层数越多,KV cache 越大。权重已经量化后,KV cache 可能成为新的显存瓶颈。
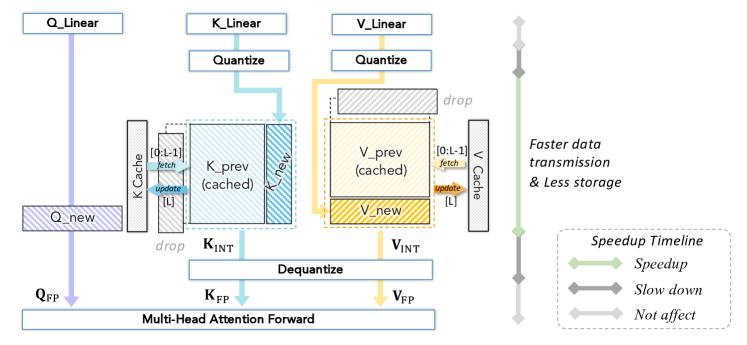
图源:A Survey of Low-bit Large Language Models,Figure 6。原论文图意:quantized KV cache 减少缓存存储和数据传输,并在 attention forward 前 dequantize。
图里的低比特 KV 主要省缓存存储和读写带宽。attention 真正计算前可能仍然要 dequant,所以要同时看显存下降、decode 带宽、dequant 开销和长程任务质量。
KV 量化的小账
假设:
| 变量 | 值 |
|---|---|
| 32 层 | |
| 8 | |
| 16k | |
| 4096 | |
| BF16 bytes | 2 |
则:
如果 KV 改成 INT8,bytes 从 2 降到 1,理论上 KV 本体接近减半。但实际还要加 scale 元数据、page 管理、碎片、workspace,以及 dequant 成本。
KV cache 量化的质量风险
| 风险 | 表现 |
|---|---|
| 长程记忆变弱 | 前文事实引用错、跨段一致性下降 |
| attention 排名变化 | 原本应该关注的 token 被弱化 |
| 工具/代码任务掉点 | 细节 token、括号、变量名更容易丢 |
| 多轮对话漂移 | 越到后面越不稳定 |
| VLA/世界模型 drift | 长 horizon 状态和风险判断变差 |
验收重点:KV 量化不能只看短问答。必须看长文档、代码、多轮、RAG 引用、长推理和业务高风险样本。
QAT、kernel、KV 的端到端链路
flowchart LR
A["训练好模型"] --> B["PTQ 或 QAT"]
B --> C["导出量化权重和 scale"]
C --> D["Runtime 加载"]
D --> E["低比特 GEMM / dequant fusion"]
D --> F["KV cache dtype"]
E --> G["TTFT / TPOT / 吞吐"]
F --> G
G --> H["任务桶质量回归"]
H --> I["上线或回退"]
这张图的重点是:QAT 只解决模型能否适应量化误差;kernel 才决定速度;KV cache 决定长上下文并发;最终仍要由任务桶质量决定是否可上线。
实践检查清单
| 问题 | 要看什么 |
|---|---|
| QAT 是否值得做 | PTQ 掉点是否不可接受,训练预算是否允许 |
| 低比特 kernel 是否命中 | profiler、kernel name、fallback、dequant 时间 |
| scale 粒度是否匹配 kernel | group size、alignment、layout |
| packing 是否带来收益 | 权重加载带宽、unpack 开销 |
| KV 量化是否划算 | 长上下文显存、TPOT、任务一致性 |
| 是否有回退路径 | 敏感层保高精、KV dtype 可切换、全精 checkpoint |
本页结论
QAT、kernel 和 KV cache 是量化落地的三块拼图。QAT 让模型适应误差,kernel 把低比特转成真实速度,KV cache 解决长上下文动态显存。只有三者和任务质量一起过关,量化才算从论文数字变成可用系统。
- 回到本专题入口:量化,确认这页在整条路线中的位置。
- 按导航顺序继续:FP8 与混合精度推理。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 量化:QAT、Kernel 与 KV Cache
- Author: Charles
- Created at : 2026-01-03 09:00:00
- Updated at : 2026-01-03 09:00:00
- Link: https://charles2530.github.io/2026/01/03/ai-files-quantization-qat-kernels-and-kv-cache/
- License: This work is licensed under CC BY-NC-SA 4.0.