
强化学习:世界模型中的强化学习
世界模型的核心不是“生成未来帧”,而是“预测动作后果,并让这些预测能改善决策”。强化学习在这里有三种作用:训练策略、训练或校准世界模型、把世界模型接入规划闭环。
这页先回答“世界模型中的强化学习”在「强化学习」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先懂概率、优化和基本训练曲线;PPO/GRPO 不必先记公式,先抓更新对象。 必要时先回 强化学习入口、基础知识 或 术语表。
主线关系:把状态、动作、奖励、策略优化和世界模型闭环连起来,看模型如何通过反馈改进决策。
这页负责回答:什么时候用 learned model 替代真实环境试错,什么时候 imagined rollout 反而会放大模型误差。强化学习能把人工轨迹、真实机器人时间和在线试错成本降下来,但会新增 imagined rollout、value learning、reward 校准和 model exploitation 的成本。
从 MDP transition 接到世界模型
在 MDP 里,真实环境 transition 是:
逐项读法:给定当前状态 和动作 ,真实环境以某个概率分布产生下一状态 。
世界模型学习一个近似:
逐项读法: 是参数为 的模型,它不是环境本身,只是对环境 transition 的近似。帽子 提醒你:这是预测,不是真相。
| 符号 | 含义 |
|---|---|
| 真实环境 transition | |
| 学出来的 world model transition | |
| 当前状态或 latent state | |
| 当前动作 | |
| 下一状态 |
如果还预测 reward、done、risk 或 uncertainty:
逐项读法:世界模型输入当前状态和动作,输出下一状态、奖励、终止信号和不确定性估计。规划器或 actor 可以用这些输出先评估候选动作。
| 输出 | 含义 | 为什么对 RL 重要 |
|---|---|---|
| 预测下一状态 | 决定后续还能做什么 | |
| 预测奖励 | 提供 imagined rollout 的即时反馈 | |
| done / termination | 判断任务是否结束或失败 | |
| uncertainty | 给高不确定预测加惩罚,减少模型漏洞被利用 |
普通视频预测可能只关心画面像不像。世界模型必须对动作敏感:换一个动作,未来应该不同;同一个动作在不同状态下,风险也应该不同。真正服务 RL 的 world model 要预测对决策有用的状态、奖励、终止和不确定性。
逼真的未来帧可能仍然缺少控制需要的细节,例如接触力、遮挡后物体位置、动作导致的反事实差异。world model 的关键验收不是只看 open-loop video quality,而是看它接入 policy、planner 或 verifier 后是否提高 closed-loop success。
PlaNet:学 latent dynamics,再在线规划
PlaNet 是从像素控制走向现代世界模型 RL 的关键节点。它先学 RSSM latent dynamics,再用 CEM 在 latent space 里搜索未来动作序列。
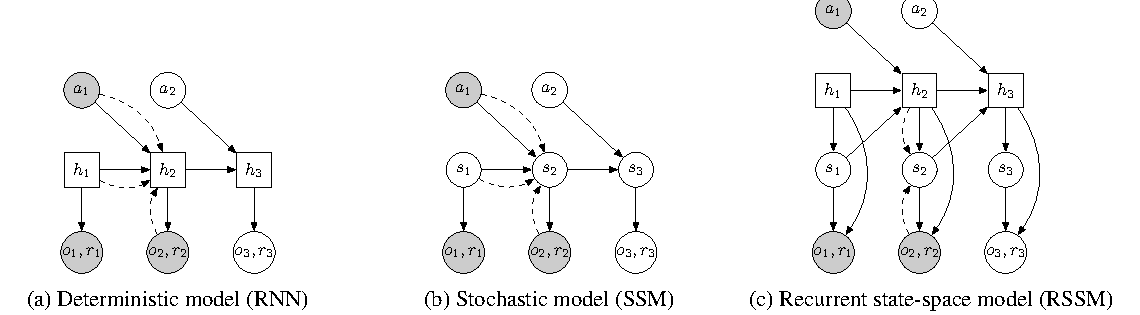
图源:Learning Latent Dynamics for Planning from Pixels,Figure 2。原论文图意:比较 RNN、SSM 和 RSSM 三种 dynamics 结构;RSSM 同时保留 deterministic memory 和 stochastic latent state。
机器人和控制任务经常是部分可观测的:当前画面不一定包含速度、接触历史和遮挡信息。RSSM 用 deterministic state 记历史,用 stochastic state 表达不确定性。训练时 posterior 可以看真实观测,规划时 prior 只能根据过去状态和动作往前 rollout。这个结构正好对应“执行前先想象未来”的需求。
PlaNet 的规划闭环可以理解为:
1 | 当前观测 -> 编码成 latent belief |
这里的 RL 语言对应关系是:
| MDP/RL 概念 | PlaNet 中的角色 |
|---|---|
| state | latent belief / RSSM state |
| action | 候选控制序列里的动作 |
| transition | RSSM dynamics |
| reward | learned reward model |
| policy | CEM 搜索出的下一步动作 |
| rollout | 在 latent dynamics 里展开候选未来 |
PlaNet 每一步都重新规划,能利用最新观测修正模型误差;代价是执行时要持续搜索。它适合帮初学者理解 model-based RL 的核心思想:不是直接背一个 policy,而是先学一个内部环境,再在内部环境里比较候选动作。
Dreamer:在想象中训练 Actor-Critic
PlaNet 每一步都要在线搜索,成本高。Dreamer 的关键变化是:在 learned world model 的 imagined trajectories 上训练 actor 和 value model,执行时 actor 直接给动作。

图源:Dream to Control: Learning Behaviors by Latent Imagination,Algorithm 1。原论文图意:Dreamer 交替进行 dynamics learning、behavior learning 和 environment interaction。
Dreamer 先用真实 replay 训练 world model;再固定 world model,从真实 latent states 出发展开 imagined rollout;最后用 imagined reward 和 value bootstrap 训练 actor/critic。这里的强化学习不完全依赖真实环境每一步试错,而是在 world model 中获得大量便宜的训练信号。
Dreamer 的重点是把世界模型变成策略训练器:
| 组件 | 训练信号 | 用途 |
|---|---|---|
| representation / transition | 真实轨迹的观测、动作、reward | 学 latent dynamics |
| reward model | 真实 reward | 给 imagined rollout 打分 |
| value model | imagined return | 估计长时收益 |
| action model | value gradients 或 policy objective | 输出真实执行动作 |
DreamerV2 的 actor-critic 图更直观地展示了“想象轨迹上训练行为”的形态:
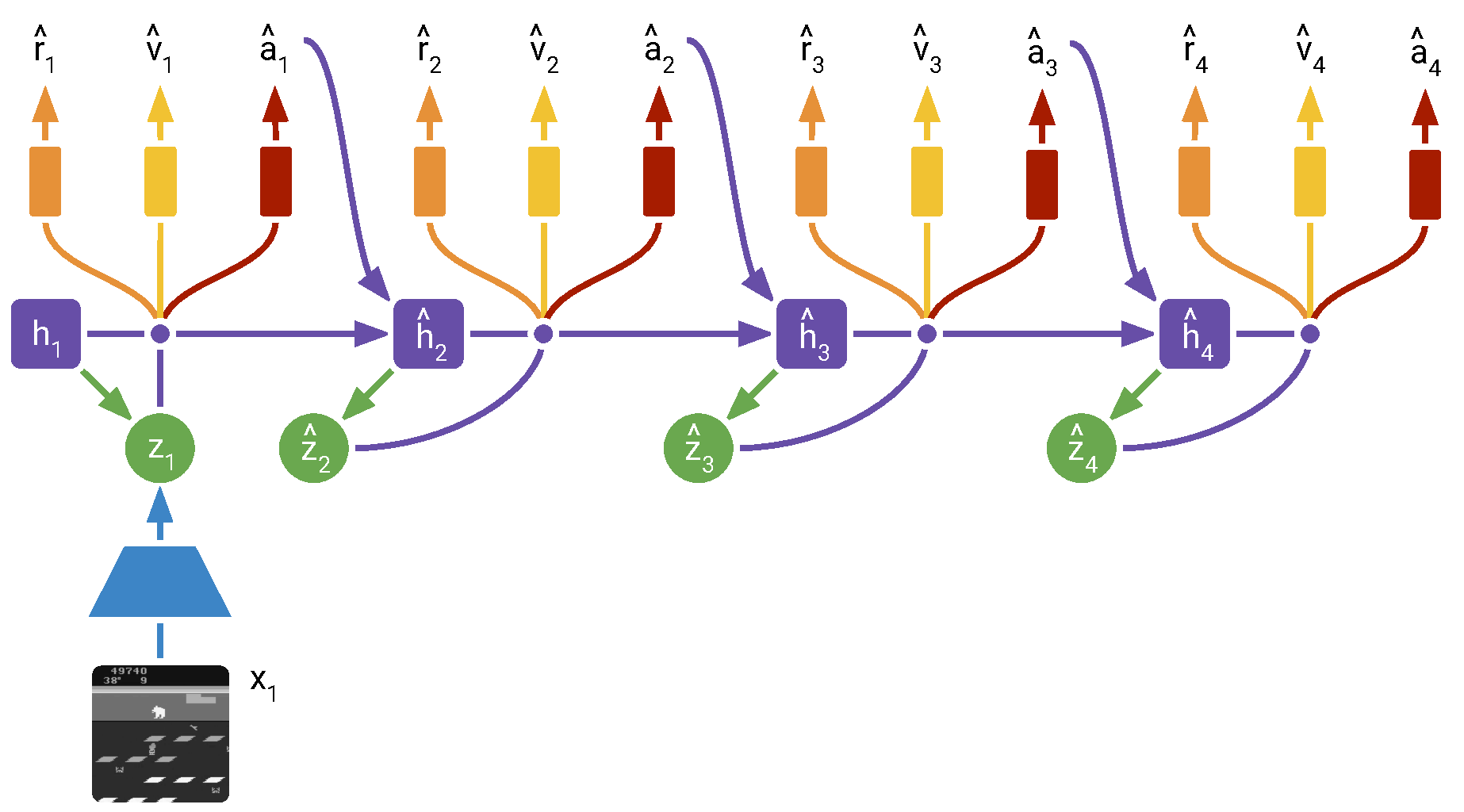
图源:Mastering Atari with Discrete World Models,Figure 3。原论文图意:在 learned world model 中从真实状态开始展开 imagined trajectories,并用这些轨迹训练 actor 和 critic。
先看 imagined trajectory 从真实 replay state 出发,而不是凭空生成无限未来;再看 reward、discount/value 和 action model 如何连在一起。它对应前面 Bellman 的语言:world model 提供 和 ,critic 估计未来价值,actor 选择让 imagined return 更高的动作。
算一遍:真实机器人时间和 latent imagination 的差距
假设一个机器人以 20Hz 收集真实交互。一次训练 round 如果需要 1024 个起点、每个起点 rollout horizon 15、每个状态比较 16 个 action samples,则 imagined transition 数是:
如果 latent world model 的单步 transition 平均 0.04ms,这一轮想象约 9.8s。同样数量的真实机器人 transition 在 20Hz 下需要:
这就是 model-based RL 的价值来源:它不是让决策免费,而是把真实世界时间换成 GPU 上的 latent rollout。
但误差也会随 horizon 叠加。若每一步有 1% 的关键接触误判概率,15 步里至少一次误判的概率约为:
所以设计取舍是:
1 | 问题症状:真实样本贵,策略在少量数据上学不稳 |
rollout 越长,策略越能看到长期后果,但 world model 错误也越容易累积。很多实践会用较短 horizon、value bootstrap、不确定性惩罚、真实 replay 校准和 closed-loop validation 来控制这个问题。
Decision Transformer:轨迹 token 化的另一条入口
Decision Transformer 给世界模型和 VLA 一个重要启发:轨迹不一定只能通过 Bellman backup 学,也可以被组织成序列建模问题。
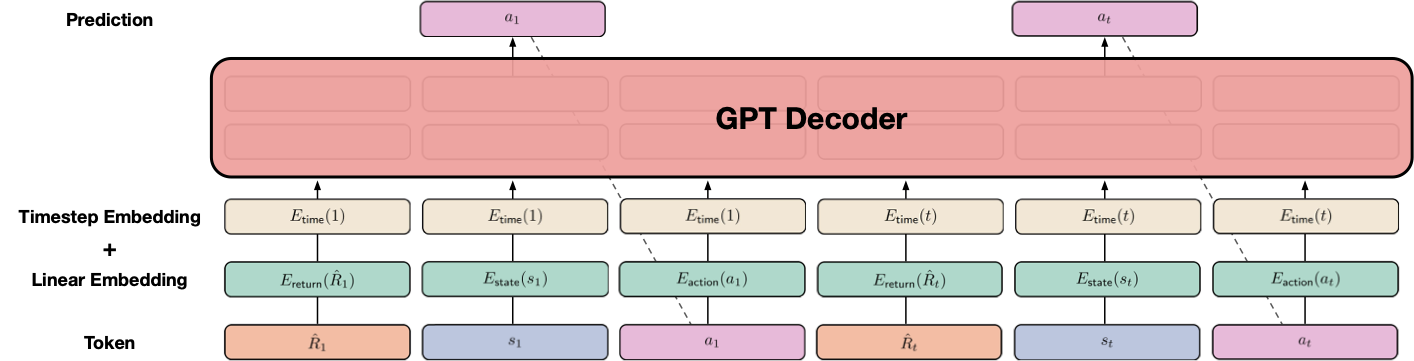
图源:Decision Transformer: Reinforcement Learning via Sequence Modeling,Figure 1。原论文图意:把 return-to-go、state、action 交替输入 GPT decoder,用目标回报条件化动作预测。
世界模型常建模 ,Decision Transformer 则建模 。前者更像“预测动作后果”,后者更像“给定目标回报生成动作”。如果把二者结合起来,可以先用世界模型评估候选未来,再把高回报轨迹作为条件策略学习材料。
Decision Transformer 在离线数据上很自然,但真实机器人和世界模型会遇到分布外状态。模型可能会在数据中没见过的高 return 条件下输出看似合理、实际不可执行的动作。因此读这类论文时,要额外看 closed-loop evaluation、数据覆盖和失败恢复。
RLVR-World:用可验证奖励训练世界模型本身
PlaNet/Dreamer 主要把 world model 用于规划或策略学习。RLVR-World 进一步强调:世界模型本身的训练目标也可以从 MLE/SFT 转向任务指标。
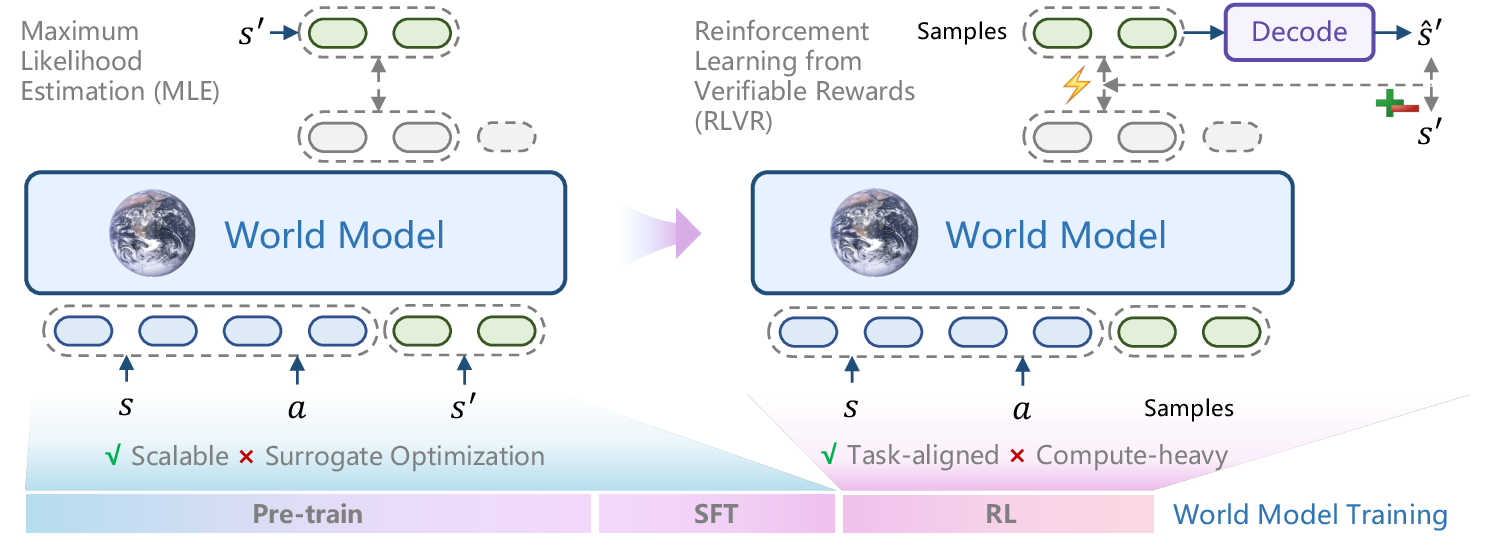
图源:RLVR-World: Training World Models with Reinforcement Learning,Figure 1。原论文图意:左侧是用 MLE 等 surrogate objective 训练 world model,右侧是用 RLVR 直接优化 decoded prediction 的可验证任务指标。
MLE 让模型提高训练数据序列的似然,但世界模型最终常被下游拿来做 state prediction、web navigation、robot trajectory prediction 或 real2sim evaluation。似然高不一定代表预测状态更准,视频 MSE 低也不一定代表控制相关细节正确。RLVR 的思路是把 decoded prediction 与 ground truth 比较,直接用 Accuracy、F1、MSE、LPIPS、SSIM 等可验证指标作为 reward。
RLVR-World 的训练逻辑可以压缩成:
1 | 状态 s + 动作 a |
这和 GRPO 的组内比较非常贴近:
| GRPO 语言模型后训练 | RLVR-World 类比 |
|---|---|
| prompt | 当前状态、动作和上下文 |
| response | 预测的下一状态或未来视频 |
| reward | 正确性、F1、MSE、LPIPS、SSIM |
| group | 同一输入下的多种预测 |
| policy update | 让高指标预测更可能 |
可验证奖励降低了 reward model 主观性,但仍可能遗漏真实任务关心的东西。比如视频指标可能奖励像素相似,却没有检查物理一致性;结构化状态 F1 可能忽略长期可执行性。因此 RLVR 适合补齐任务指标错位,但仍需要闭环评测和失败样本回放。
强化学习给世界模型带来的五个增量
| 增量 | 具体作用 | 常见风险 |
|---|---|---|
| 数据收集闭环 | policy 会把数据推向任务相关状态,而不是只停在随机分布 | 采样分布变窄、失败样本不足 |
| 长期信用分配 | reward/value 把未来结果反馈到早期动作或预测 | value target 错误会被放大 |
| 任务指标对齐 | RLVR 可以直接优化 decoded prediction 的任务指标 | 指标与控制目标错位 |
| 规划与反事实 | world model 支持“如果换个动作会怎样”的内部模拟 | action sensitivity 不足 |
| 风险敏感控制 | reward 可以显式加入碰撞、失败、不可恢复状态和不确定性惩罚 | 惩罚过强会让策略保守 |
和 VLA 的连接
VLA 学的是:
逐项读法:给定历史观测 和语言指令 ,策略输出当前动作 的概率。
世界模型学的是:
逐项读法:给定历史观测、未来候选动作序列和语言指令,预测未来观测、奖励和终止信号。
强化学习把两者连起来:
- 用 world model 预测 action 的后果;
- 用 reward/value 判断哪条后果更好;
- 更新 policy,使它更倾向于高回报动作;
- 用真实闭环数据修正 world model 的盲点。
机器人场景里,很多真实数据来自历史实验或遥操作日志,不能像游戏一样无限重开。Offline RL 教会我们:历史数据不只是“模仿材料”,也可以通过 value learning 变成决策材料,但必须处理分布外动作和价值高估。

图源:Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems,Figure 7。原论文图意:展示大规模机器人抓取数据收集,相关工作用超过 500,000 次抓取试验训练视觉抓取策略,并比较纯离线训练与在线微调。
行为克隆会学习“人或旧策略在这些画面下怎么做”,但它不会天然知道“换一个动作会不会更稳”。Offline RL / model-based RL 尝试从历史轨迹里估计动作后果:哪些抓取姿势长期成功率高,哪些动作看似接近目标但会导致碰撞或滑落。世界模型进一步把这种动作后果预测显式建出来,让策略可以先在内部比较候选动作。
VLA 可能学会看到杯子就伸手。世界模型会预测从左侧推可能把杯子推倒,从上方夹取更稳。RL 再把“成功夹起、没有碰撞、动作平滑”变成 reward,让策略在类似状态中更倾向于安全动作。
读论文时的检查清单
| 检查项 | 要问的问题 |
|---|---|
| 动作条件是否真实生效 | 换动作时,未来预测是否真的变化 |
| reward 是否任务相关 | 优化指标是否接近下游规划或控制目标 |
| rollout horizon 多长 | 长时预测是否只靠短期视觉质量支撑 |
| 是否有闭环验证 | 只做 open-loop prediction,还是进入控制或规划 |
| 是否评估 model exploitation | policy 或 planner 会不会利用模型漏洞拿虚高回报 |
| 是否有真实回放校准 | imagined rollout 的错误有没有被 replay / online data 修正 |
- 回到本专题入口:强化学习,确认这页在整条路线中的位置。
- 按导航顺序继续:verl 训练流程。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: 强化学习:世界模型中的强化学习
- Author: Charles
- Created at : 2026-01-16 09:00:00
- Updated at : 2026-01-16 09:00:00
- Link: https://charles2530.github.io/2026/01/16/ai-files-reinforcement-learning-rl-for-world-models/
- License: This work is licensed under CC BY-NC-SA 4.0.