
VLM/VLA:动作表示与控制接口
VLA 之所以难,不只是因为感知复杂,还因为“动作”本身不是一个天然统一的对象。
同样一句指令“把杯子放到左边”,在不同系统里可能被表示成末端位姿增量、关节角命令、离散动作 token、未来动作块、子目标状态,或技能标识 / 潜在代码。
这页先回答“动作表示与控制接口”在「VLA」里的位置:它解决什么局部问题,依赖哪些前置,最后会影响哪类工程或研究判断。
前置:先补 VLM/VLA 符号、动作表示和基础评测口径,再看数据与部署细节。 必要时先回 VLA 入口、基础知识 或 术语表。
主线关系:把视觉语言模型落到动作空间、闭环反馈和安全部署中,理解策略不是只输出文本,而是要驱动真实或仿真环境。
所以动作表示与控制接口其实是 VLA 成败的底层结构之一。很多系统看起来都是“图像 + 语言 -> 动作”,但真正决定它能不能学、能不能迁移、能不能落地的,常常就是动作这一层怎么定义。
一句话结论:动作接口决定 VLA 的训练成本、控制风险和世界模型 action sensitivity。
适合读者:正在比较离散 action token、连续控制、动作 chunk、低层控制器和安全门禁的人。
先看哪张表:先看“硬证据模块:动作接口要用成本和失败一起验”,再看各类动作表示。
VLA 的输出不是“把语言翻译成命令”这么简单。一个动作可能同时包含位置、旋转、夹爪、速度、力和模式切换。不同分量的尺度、频率和风险都不同,动作接口定义错了,模型再大也很难稳定执行。
先看动作到底由哪些子变量组成,再看这些变量用什么坐标系、连续还是离散、单步还是 chunk。符号不熟时可以对照 VLM/VLA 符号与最小数学地图。
玩家说“抓左边那只熊”,但机器真正需要的是横向移动多少、前后移动多少、爪子降多深、什么时候合拢、失败后是否再试一次。VLA 也是这样:语言目标很短,动作接口却很细。
硬证据模块:动作接口要用成本和失败一起验
动作接口不是风格选择,而是训练成本、闭环风险和世界模型 action sensitivity 的共同约束。每种动作表示都应该配一张证据卡。
| 证据项 | 最小可复算例子 | 失败案例 | 验收指标 |
|---|---|---|---|
| 本页解决哪项成本 | 逐步动作 vs 8-step chunk 的 token/标量数量对比 | chunk 省 token,但第二步出错后连续错 0.8s | action token count、rollout latency |
| 动作敏感性 | 固定观测,替换 noop / grasp / push / wait | 世界模型对不同动作预测同一未来 | latent delta、event divergence |
| 控制平滑 | 比较 action L2、jerk、控制器拒绝率 | 离散 token 边界导致抖动 | jerk、controller reject、retry rate |
| 风险路径 | 高接触动作保留更高频或高精度 | 低频 chunk 漏掉滑落前 200ms | near-miss recall、contact event F1 |
| 证据边界 | 区分离线动作误差、仿真闭环、真机闭环 | BC loss 低但真实抓取失败 | closed-loop success、cost per success |
一个硬反例是 fast_grasp -> slip:模型给 fast grasp 高成功、低风险,但真实事件是滑落。此时不能只说“动作预测误差小”,而要追问动作接口是否把接触速度、夹爪时序和力/阻抗状态表达出来;世界模型是否在候选动作排序时惩罚了高风险动作。
统一问题定义
从策略视角看,模型学习的是:
| 符号 | 含义 | 红杯例子 |
|---|---|---|
| VLA policy | 决定夹爪下一步怎么动 | |
| 动作表示 | 位姿增量、夹爪开合、动作 token 或 action chunk | |
| 当前及历史观测 | 图像、深度、关节状态、夹爪宽度 | |
| 语言指令 | “把红杯放到托盘上” |
读作什么:模型根据历史观测和语言指令输出动作。
这个公式不说明什么:它没有规定动作单位、坐标系、控制频率、是否可中断,也没有保证控制器能安全执行。
但 到底是什么,会直接决定学习难度、跨机器人迁移难度、控制平滑性、低层控制器接口、安全约束方式,以及数据采集和标注的统一性。
动作并不是一个标量,而是一组子变量
很多机器人动作可被拆成:
分别表示:
- :位置或平移;
- :姿态或旋转;
- :夹爪开合;
- :模式切换,如抓取、导航、对齐;
- :力或阻抗相关量。
读作什么:一个动作不是一个数字,而是一组物理含义不同的子变量。
| 子变量 | 常见单位 | 学习风险 |
|---|---|---|
| 米、厘米或归一化坐标 | 尺度不统一会导致位移过大或过小 | |
| 弧度、欧拉角、四元数或旋转 token | 姿态表示不连续会抖 | |
| 0/1、毫米开度或归一化值 | 夹爪时序错会抓空或夹坏 | |
| 离散模式 ID | 技能边界错会导致状态机混乱 | |
| 力、阻抗或柔顺参数 | 风险高,常需要安全约束 |
这件事很重要,因为现实任务里这些分量的统计性质完全不同:平移通常连续且范围较大,旋转存在角度表示问题,夹爪往往接近离散开关,力控制则更稀疏也更危险。
如果把它们粗暴地塞进同一种 token 范式里,模型常会在某一维学得很好、在另一维很差。
绝对动作与相对动作
3.1 绝对动作
直接给出下一时刻目标位姿或目标状态。
优点是语义明确,更接近“把末端移到这里”这种高层意图;缺点是对坐标系极敏感,跨平台泛化差,误差累积后容易和真实状态脱节。
3.2 相对动作
让模型预测增量而不是绝对目标。
优点是更易泛化,更适合闭环修正,也更能适应不同起始状态。
很多真实机器人数据更适合这种表示,因为人类示范和控制器本来就是在不断做局部修正。
一个直观例子
若任务是“把杯子移到托盘中央”,绝对动作像是直接说“杯子最后应该在世界坐标 这里”;
相对动作则像是不断说“向左 2 厘米、再向前 1 厘米、再下降一点”。
对真实闭环系统来说,后者常更稳。
坐标系选择会决定迁移上限
动作表示还依赖参考系。常见选择包括:
4.1 世界坐标系
适合固定工位,但对标定和场景重建要求高。
4.2 机器人基座坐标系
硬件接口友好,但换平台或移动底座后需要重新适配。
4.3 相机坐标系
更贴近视觉输入,适合视觉伺服,但会受相机外参漂移影响。
4.4 目标物体局部坐标系
更利于抓取和操作泛化,但前提是物体姿态估计足够准。
4.5 末端工具坐标系
适合局部精细接触任务,例如擦拭、插入、贴合。
如果目标是做跨平台或高层策略,很多系统更偏向先学更稳健的相对表示,再通过中间适配层映射到具体机器人控制接口。
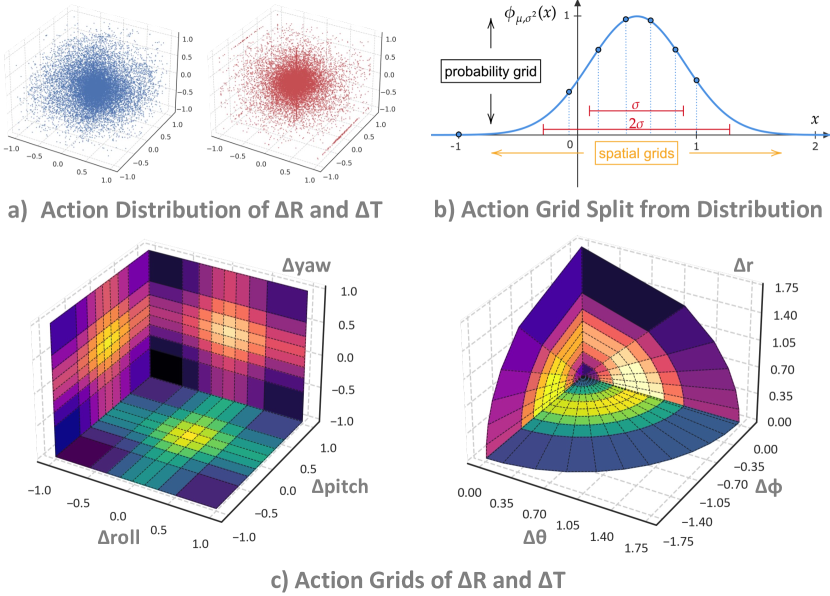
图源:SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models,Figure 2。原论文图意:Adaptive action grids 先统计 translation 和 rotation action movement 的分布,再根据 Gaussian fitting 对每个动作变量划分等概率区间,形成空间动作 token。
先看哪里:translation 和 rotation 的动作分布,以及如何被切成 adaptive grids。
它证明什么:动作离散化不是随便分桶,分桶方式会影响跨机器人、跨动作尺度的适配。
它不证明什么:更聪明的动作网格不自动解决深度误差、接触控制和长时恢复。
和红杯例子的关系:如果“下降 1cm”和“下降 5cm”被粗暴放在同一个桶里,夹杯时就可能撞杯或抓空。
笛卡尔空间与关节空间
5.1 笛卡尔空间动作
动作是末端执行器位置和姿态变化。
更贴近任务语义,例如“向前推一点”“向下放一点”。
优点是和语言更容易对齐,更适合跨机械臂迁移,也更容易插入碰撞检查和路径平滑;缺点是需要逆运动学或底层控制器支持,奇异位形、关节限位等问题会被推迟到接口层处理。
5.2 关节空间动作
动作是各个关节角、角速度或力矩命令。
更贴近硬件接口,但学习难度通常更高。
优点是执行直接,对专用平台可做到高频闭环;缺点是语义弱、跨平台迁移差,非专业数据下很难学稳。
连续动作与离散 token
6.1 连续动作
最自然,也更接近真实控制。
常见训练方式是回归:
优点是精细、无量化误差,对接触和插入类任务更友好;缺点是对尺度和归一化很敏感,序列建模时也不如离散 token 方便。
6.2 离散动作 token
把连续动作量化成若干 token:
优点是容易接入 Transformer 序列建模,更接近语言模型训练范式,也能与动作字典、技能字典结合;缺点是会引入量化误差,在精细接触任务中容易不够平滑,离散边界附近还可能出现控制抖动。
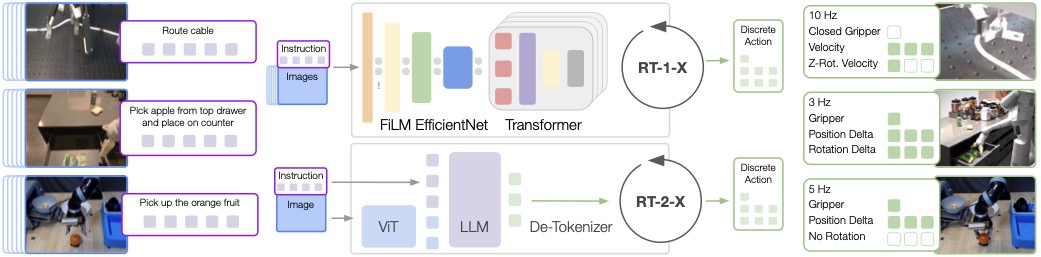
图源:Open X-Embodiment: Robotic Learning Datasets and RT-X Models,Figure 2。原论文图意:RT-1-X 与 RT-2-X 都以图像和文本指令为输入并输出离散 end-effector actions;RT-2-X 把动作表示成另一种语言 token,与视觉语言数据一起训练。
先看哪里:输入仍是图像和指令,输出却变成 gripper、位置增量、旋转等动作 token。
它证明什么:动作可以接入 Transformer/LLM 的序列建模和多任务训练框架。
它不证明什么:连续控制被分桶后不会抖,或者精细接触一定够准。
和红杯例子的关系:token 可以表达“下降、闭爪、抬起”,但低层控制器仍要保证动作平滑、安全、不过界。
6.3 何时离散更合适
若任务偏高层技能选择、长时序规划或动作模板重用,离散化常有帮助;但若任务偏插孔、螺丝装配、贴边放置或柔顺接触,连续动作通常更稳。
动作 chunk 为什么常常比单步更有效
真实机器人控制里,很多系统不会每次只预测一步,而是预测未来一个动作块:
| 符号 | 含义 |
|---|---|
| 模型预测的一段未来动作 | |
| chunk horizon,动作块长度 | |
| 当前及历史观测 | |
| 语言指令 |
读作什么:策略一次输出未来几步动作,而不是只输出下一步。
这个公式不说明什么:chunk 内每一步是否真的会执行、是否可中断、执行中是否重新观察,都需要数据 schema 和控制接口额外记录。
优点是减少抖动、学出更完整的技能片段,降低感知噪声对每步决策的影响,并让模型在时间上看得更远。
一个直观例子:开抽屉
如果每 40ms 只决定一个极小动作,模型很容易在把手附近来回犹豫。
如果一次预测“接近 -> 闭合夹爪 -> 后拉”的小段动作,轨迹会稳定得多。
7.1 但 chunk 也有代价
动作块过长时,系统会变得不够灵活。
环境一旦变化,整段动作都可能过时。
所以常见设计是预测较短 chunk,只执行前半段或前几步,然后重新观察与重规划。
这本质上是滚动时域控制思想在 VLA 里的体现。
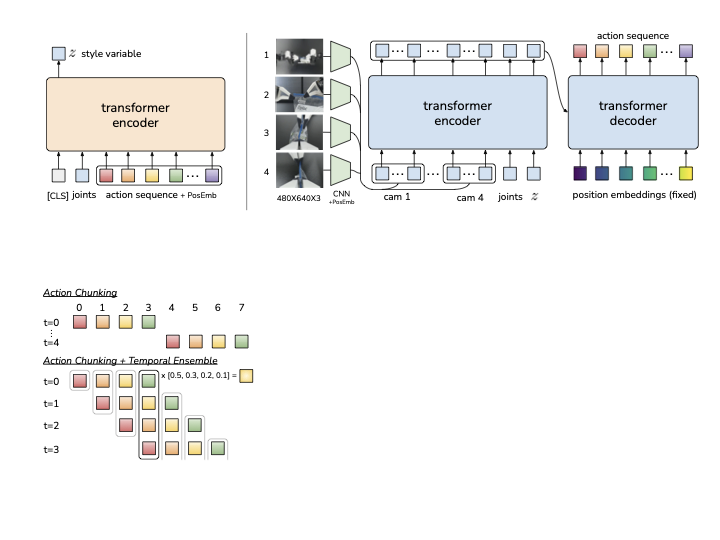
图源:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,Figure 2。原论文图意:Action Chunking with Transformers (ACT) 用 CVAE 编码动作序列和关节观测,测试时根据多视角图像、关节状态和 latent 生成一段 action sequence,并用 temporal ensembling 平滑执行。
先看哪里:模型输出的是 action sequence,并用 temporal ensembling 平滑执行。
它证明什么:一段短动作能保留技能内部结构,减少逐帧抖动。
它不证明什么:chunk 越长越好。环境变化时,长 chunk 会让系统更偏开环。
和红杯例子的关系:抓杯动作适合用短 chunk 表达“对准、闭爪、抬起”,但杯子滑动时必须能打断和重规划。
7.2 算一遍:chunk 从 4 提到 16
假设低层控制频率是 20Hz,一个任务片段要 rollout 10s,也就是 200 个控制 step。若 VLA 每次前向输出一个 action chunk:
| chunk size | 决策次数 | 重规划间隔 | 如果单次 VLA 前向是 120ms |
直觉 |
|---|---|---|---|---|
4 |
200 / 4 = 50 次 |
0.2s |
每秒约 600ms 在跑策略 |
反馈频繁,恢复快,但推理压力大 |
16 |
ceil(200 / 16) = 13 次 |
0.8s |
每秒约 150ms 在跑策略 |
前向成本约降 4x,但更偏开环 |
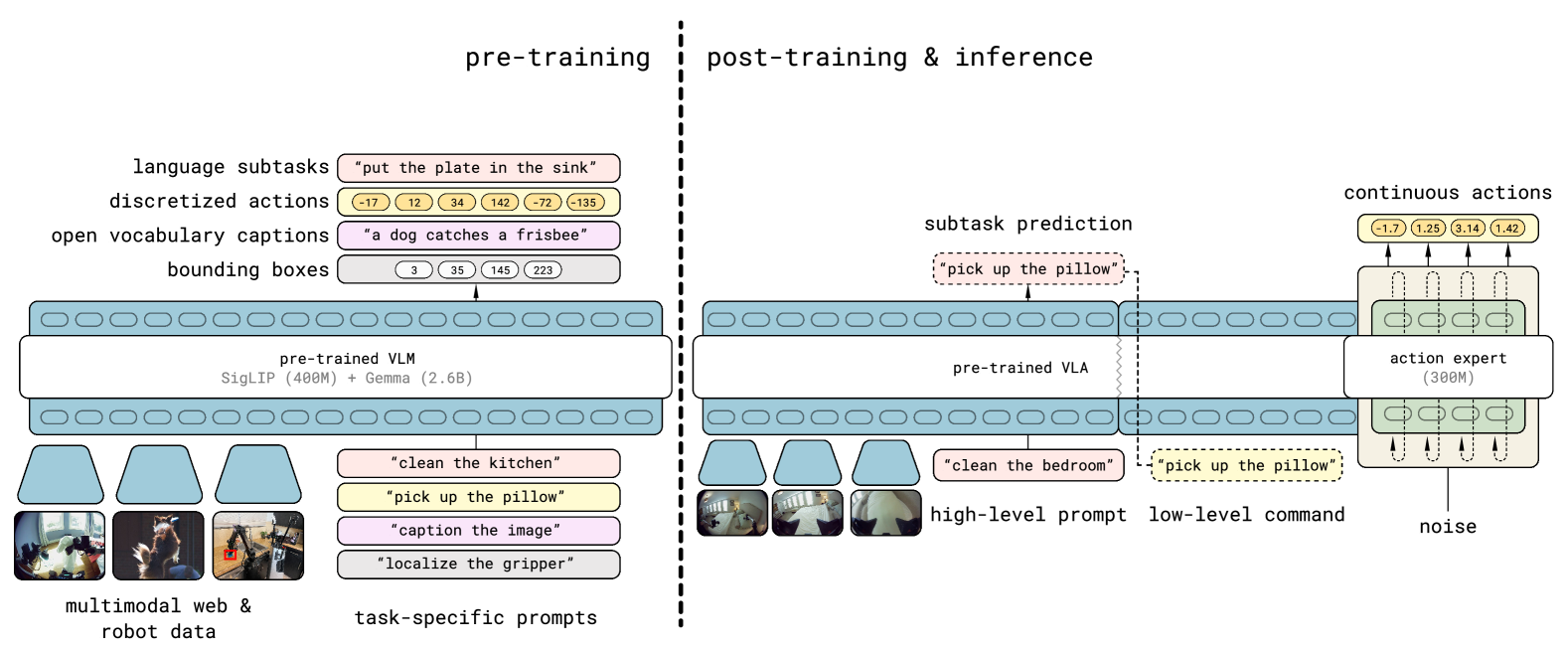
图源:π0.5: a Vision-Language-Action Model with Open-World Generalization,Figure 3。原论文图意:模型把视觉语言上下文、高层任务理解和动作专家连接起来,面向真实机器人输出连续动作 chunk。
先看哪里:上方 high-level subtask prediction 和下方 action expert 的分工。
它证明什么:长任务常需要先决定语义子任务,再生成短时连续动作。
它不证明什么:有 high-level subtask 不等于动作一定安全执行,仍要控制器、反馈和失败恢复。
和红杯例子的关系:高层可以决定“先拿红杯”,低层 action expert 负责约 1 秒内怎么靠近和夹取。
这里有两个容易混淆的成本:
| 成本 | chunk 变大后一定下降吗 | 原因 |
|---|---|---|
| VLA 前向次数 | 通常下降 | 每次前向覆盖更多低层控制 step |
| 底层控制动作数 | 不下降 | 10 秒 20Hz 仍然要执行 200 个低层动作 |
| 训练监督 token | 取决于建模方式 | 若每个低层动作都监督,动作点数不变;若学习 chunk latent 或 skill token,序列监督会变短 |
| 误差纠正频率 | 下降 | chunk=16 时系统最多可能 0.8s 才重新观察和重规划 |
再看误差传播。假设每个低层动作带来约 1cm 的局部位姿误差:
| 误差假设 | chunk 4 | chunk 16 | 含义 |
|---|---|---|---|
| 系统性偏差同向累积 | 4cm |
16cm |
接触任务里最危险,偏差会一路推着物体走 |
| 随机误差近似独立 | sqrt(4)=2cm |
sqrt(16)=4cm |
噪声被部分抵消,但恢复频率仍下降 |
所以 chunk size 的正确问题不是“越大越省吗”,而是:
| 问题链 | chunk 4 常见答案 | chunk 16 常见答案 |
|---|---|---|
| 问题症状 | 推理占用高、动作可能抖、训练序列长 | 正常轨迹平滑,但被扰动后继续执行旧动作 |
| 指标观察 | token/s 或 control loop 占用高,action variance 大 | near-miss 上升,人工接管率和恢复时间上升 |
| 技术机制 | 高频重规划让噪声进入每步决策 | 长 chunk 降低前向次数,也降低闭环纠错频率 |
| 设计取舍 | 更贵但更敏捷 | 更省但更开环 |
| 失败反例 | 接触稳定性差时,短 chunk 可能一直小幅来回修正 | 抽屉卡住、人手干预、物体滑动时,长 chunk 可能把错误执行完整 |
| 适用边界 | 高扰动、强反馈、安全敏感任务 | 轨迹稳定、扰动少、低层 controller 很可靠的任务 |
训练时也要把这个取舍写进数据 schema:chunk 起点时间、chunk 内每个 action 的时间戳、是否执行完整 chunk、是否被中途打断、打断原因和观测延迟都要记录。否则离线 loss 会把“模型预测的动作序列”和“机器人实际执行的闭环轨迹”混在一起,世界模型学到的 rollout 就会偏。
动作归一化、单位与频率不能乱
很多 VLA 系统离线 loss 很好,实机却抖动严重,问题并不总在模型,而在动作统计没有统一好。
常见要素包括:
8.1 范围归一化
不同维度的量级差异很大,例如平移以厘米计,旋转以弧度计,夹爪可能是 0/1 或毫米开度。
如果不做归一化,模型会偏向先优化大尺度维度。
8.2 频率对齐
示范数据可能是 10Hz,真实控制器却跑在 50Hz 或 100Hz。
这时动作语义会发生变化:同样的位移增量对应完全不同的速度。
8.3 延迟补偿
相机、推理和控制执行之间的延迟会让“正确动作”在真正执行时已经偏晚。
因此很多系统需要显式考虑观测时间戳、推理延迟、控制器刷新频率和动作外推。
动作接口成本账
同一个任务,动作表示不同,训练和推理成本会完全不同:
| 设计 | 序列成本 | 控制收益 | 主要风险 |
|---|---|---|---|
| 20Hz 单步动作 | 1 分钟任务约 1200 个动作 step | 反馈频繁,恢复快 | 序列长、模型易抖、训练吞吐差 |
| 1 秒 action chunk | 1 分钟任务约 60 个决策点 | 动作更连贯,训练序列短 | 环境变化时整段动作可能过时 |
| 高层 skill token | 1 分钟任务可能只有十几个决策 | 适合规划和长任务 | 技能边界难标注,失败原因不透明 |
| 连续 action expert | 保留控制精度 | 精细接触更稳 | 训练目标、归一化和实时推理更复杂 |
所以动作接口不是“越抽象越好”或“越细越好”。如果目标是训练动作条件世界模型,最重要的是动作能稳定解释未来差异:同一状态下换动作,未来应该发生可理解的分叉。
控制接口为什么必须显式设计
很多 VLA 演示看起来像“模型直接控机器人”,但真实部署里通常有至少两层:
中间接口负责坐标变换、逆运动学、速度 / 加速度限制、平滑滤波、安全投影、碰撞检查和超界裁剪。
如果这层接口设计不好,哪怕模型输出“语义上正确”,机器人也可能执行得很糟。
三类典型接口设计
10.1 高层目标接口
例如目标位姿或目标抓取点。
更适合把 VLA 当策略规划层。
10.2 中层动作块接口
例如未来若干步末端位姿增量。
兼顾可学性和可执行性,是很多系统最实用的折中。
10.3 低层力矩/关节接口
更直接,但通常不适合大模型端到端学习,除非系统对硬件非常专用且数据极多。
跨平台迁移为什么难
同样动作表示换到不同机器人上,问题会立刻出现:工作空间大小、夹爪形态、机械臂自由度、控制频率、相机布局和安全边界都可能不同。
因此动作表示要么尽量抽象得更稳健,要么显式引入平台适配层。
11.1 常见适配方式
常见做法包括统一末端语义空间再映射到底层控制,对每个平台学习单独 adapter,把动作改写成对象中心或任务中心表示,或用技能层代替原始动作层。
常见失败模式
失败 1:离线学得好,实机抖动严重
往往说明动作表示与控制接口没有对齐。
失败 2:同任务跨平台直接失效
说明动作编码强绑定了某个平台坐标和控制习惯。
失败 3:量化或离散动作后接触任务精度骤降
说明动作表示过粗,无法覆盖细粒度控制需求。
失败 4:动作 chunk 很稳,但恢复能力很差
说明时间结构有了,闭环重规划却不够快。
失败 5:动作语义对了,安全约束没兜住
例如目标位姿落在障碍物内部,控制接口没有做约束投影。
真实排查案例:chunk 很稳,但失败恢复变慢
| 环节 | 观察 |
|---|---|
| 输入症状 | 把单步动作改成 1 秒 action chunk 后,正常轨迹更平滑,但物体滑动、抽屉卡住或人手干预时,机器人继续执行旧动作 |
| 指标 | 平均成功率略升,抖动下降;near-miss、人工接管率和失败后恢复时间上升 |
| Trace / 回放观察 | policy 在 chunk 开始时判断正确,但执行中真实状态已变化;controller 只做限幅,没有把风险反馈打断到高层 |
| 判断 | chunk 解决了局部平滑,却让系统更偏开环;动作接口缺少中途验证和可中断语义 |
| 修复 | 只执行 chunk 前半段再重规划;给 chunk 加 abort condition;用世界模型或 risk head 预测“继续执行是否会进入不可恢复状态” |
| 反例 | 如果任务是稳定传送带分拣或离线轨迹回放,长 chunk 可能很划算。问题出在高扰动闭环任务中把平滑性收益外推成恢复能力 |
工程建议
如果你在设计 VLA 系统,建议优先问:模型到底输出高层目标还是低层控制,动作坐标系是否稳定且可迁移,是否需要 action chunk,控制频率和示范频率是否对齐,是否有独立低层控制器兜底平滑与安全,以及跨平台迁移是不是目标之一。
这几个问题通常比“换一个 backbone”更决定系统能否落地。
本页结论
动作表示与控制接口是 VLA 的底层语法。它决定模型到底是在学高层意图、中层技能,还是低层控制信号。
如果这一层没设计清楚,后面的训练规模、模型大小和数据量都会很快碰到上限。真正成熟的 VLA 系统,通常不是让一个模型生硬输出所有控制量,而是把动作表示、时间结构、控制接口和安全投影一起设计成一条连续的执行链。
快速代码示例
1 | import torch # 使用张量拼接、重复和裁剪 |
这段代码把动作接口里最常见的两步拆开:chunk_actions 负责把长序列动作重排成固定块,便于策略按块预测;safe_project 负责把动作约束在执行器允许范围内,降低越界风险。
工程收束
动作接口的核心问题不是“离散还是连续”这么简单,而是模型输出能否被执行器稳定消费。上线前要确认动作单位、坐标系、chunk 边界、频率、约束投影和安全停止都写成明确契约;否则模型能力会被接口抖动、坐标错配或越界动作吞掉。
- 回到本专题入口:VLA,确认这页在整条路线中的位置。
- 按导航顺序继续:动作分块、层级策略与潜在技能。
- 概念或符号卡住时,先查 术语表,再回到当前页。
- Title: VLM/VLA:动作表示与控制接口
- Author: Charles
- Created at : 2026-03-08 09:00:00
- Updated at : 2026-03-08 09:00:00
- Link: https://charles2530.github.io/2026/03/08/ai-files-vla-action-representation-and-interfaces/
- License: This work is licensed under CC BY-NC-SA 4.0.