
训练:目标函数、优化器与 LR 日程
模型架构决定系统允许学什么,数据决定系统能看到什么,目标函数、优化器和学习率日程决定系统实际沿着怎样的路径学到什么。同一个模型、同一批数据,仅仅更换 loss 配方和 schedule,就可能得到截然不同的训练轨迹。
这页给训练目标和优化配置一个统一入口。更系统的数据配方见 Scaling、课程学习与数据配比,数值异常排查见 训练稳定性与故障排查。
训练配方可以先按“目标、步长、刹车”理解:loss 告诉模型什么叫错,optimizer 决定怎样改参数,learning rate schedule 决定每一步迈多大。三者必须一起看,单独换一个组件,往往会改变整条学习轨迹。
模型像厨师,loss 像食客反馈,optimizer 像改菜谱的方法,learning rate 像每次加盐的量。反馈再准确,如果一次加半罐盐,菜也会报废;如果每次只加一粒盐,改进又会慢到不可接受。
目标函数在定义学习压力
大多数训练问题可以写成:
现代基础模型复杂在于: 可能是下一个 token、噪声、偏好排序、奖励信号、图像 patch 或动作; 可能由多个子目标组成;样本分布是多源、分阶段、随时间变化的。
不同目标本质上在回答不同问题:
| 目标 | 问题 | 常见用途 |
|---|---|---|
| 交叉熵 | 怎样拟合数据分布 | LLM、代码、多模态 token |
| 扩散损失 | 怎样恢复被噪声破坏的信号 | 图像、视频、音频生成 |
| 对比损失 | 怎样塑造表示空间几何 | 检索、对齐、表征学习 |
| 偏好目标 | 怎样偏向更受欢迎的输出 | RLHF、DPO、对齐 |
| 强化学习目标 | 怎样最大化长期回报 | agent、机器人、工具使用 |
| 多任务目标 | 怎样同时保留多个能力 | VLM、VLA、世界模型 |
所以“哪种 loss 更好”没有统一答案,必须看它给模型施加了什么学习压力。
常见目标族
自回归语言模型最经典的目标是 next-token prediction:
它简单、稳定、可扩展,但不直接优化有用性、偏好和业务风险。
扩散模型常用噪声、 或 velocity 预测目标,例如:
不同参数化会影响梯度尺度、采样器兼容性和训练稳定性。
图文对齐和样本匹配常用 InfoNCE:
它优化的是表示几何,而不是直接分类。
偏好学习如 DPO 会比较优选回答和劣选回答,推动策略相对参考模型向偏好方向移动。这类目标对参考模型、偏好数据、KL 约束和学习率非常敏感。
强化学习目标比普通监督学习多一层间接性。监督学习里,目标答案 通常已经给定;强化学习里,模型先按当前策略采样动作或回答,再根据奖励判断这次采样是否值得加强。语言模型 RLHF 可以简化成:
这里 是当前模型, 是 reward model, 常是 SFT/reference 模型。这个目标和交叉熵最大的区别是:模型不是模仿固定答案,而是在一组可能回答里尝试提高高奖励回答的概率,同时用 KL 防止自己离参考模型太远。
Reward model 给的是完整回答的偏好分数,不是每个 token 的标准答案。PPO 这类算法要把“这个回答整体更好”转成 token 级概率更新,因此需要 value、advantage、旧策略概率、clip 和 KL 这些稳定装置。缺少这些装置,模型很容易为了追高 reward 走偏,例如变长、套模板、过度拒答或牺牲事实性。
GRPO / RLVR:同一道题多采样,再做组内比较
DeepSeek-R1、Qwen3 等技术报告里反复出现 GRPO 和 RLVR。这部分如果只理解成“又一种 PPO 变体”,会漏掉重点。它真正回答的是:当奖励来自数学答案、代码测试、选择题、格式检查这类 verifier 时,怎样把“最终是否成功”转成稳定的策略更新。
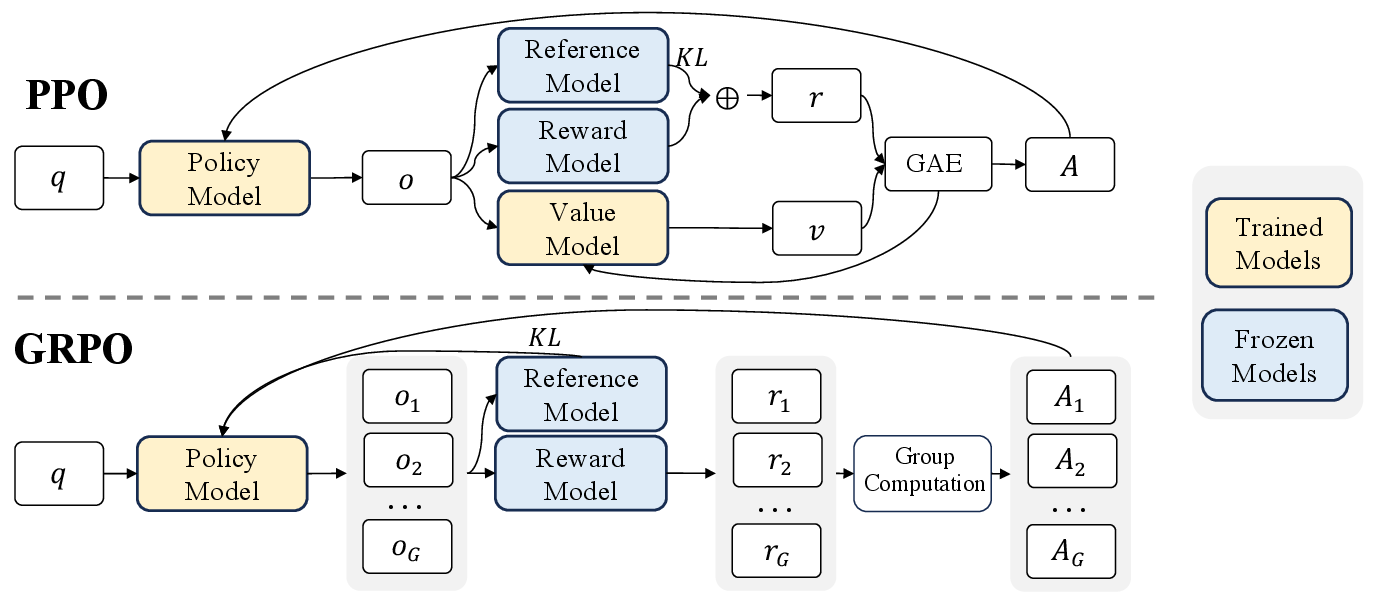
图源:DeepSeek-R1,Supplementary Fig. 1。原论文图意:PPO 使用 value model 估计 advantage;GRPO 省去 value model,直接从同一问题的一组 sampled outputs 的 reward scores 中估计相对 advantage。
PPO 里通常有 policy、reference、reward model 和 value model。value model 要猜“当前前缀未来大概能拿多少奖励”,这在长 CoT 里很难,因为中间推理可能被后面推翻。GRPO 换了一个更朴素的比较方式:同一道题一次采样多条回答,谁通过 verifier、谁格式正确、谁结果更好,就在这一组里相对更高。
GRPO 的 advantage 通常来自同题组内标准化:
这里 是同一道题采样的回答数, 是第 条回答的奖励。直觉很像同一场考试里比较多份草稿:不是问“这份草稿绝对值多少分”,而是问“它比同题其他解法更好吗”。这样可以省掉 critic / value model,也减少一个大模型训练和显存负担。
RLVR 指的是 reinforcement learning with verifiable rewards。它最适合这类任务:
| 任务 | Verifier 例子 | 为什么适合 RL |
|---|---|---|
| 数学 | 最终答案匹配、符号化检查 | 中间步骤难标,但结果可验证 |
| 代码 | 单元测试、编译器、执行结果 | 真实成功信号比偏好打分更可靠 |
| 选择题 / STEM | 标准答案、格式检查 | reward 稳定,采样成本可控 |
| 工具调用 | schema、返回码、任务完成信号 | 能评价完整轨迹是否闭环 |
但它也有边界。开放写作、主观审美、复杂安全判断没有天然 verifier,这时仍要依赖 reward model、judge、人审或规则组合。即使有 verifier,也可能出现 reward hacking:模型学会迎合格式、利用测试漏洞、输出不可读但能过检查的答案。因此 GRPO / RLVR 应和 rejection sampling、格式约束、人工抽检、长度监控、通过率分桶和真实任务评测一起看。
老师不给每一步打分,只看最后答案是否正确。学生同一道题写 16 种解法,正确且清楚的解法下次更可能被采用,明显错的解法概率下降。GRPO 就是在把这种“同题多解、组内比较”的信号变成模型参数更新。
多目标训练
实际系统很少只优化一个损失。多模态、具身和世界模型常写成:
真正难点不是写公式,而是:
- 权重如何设;
- 不同 loss scale 是否可比;
- 哪些目标早期强、后期弱;
- 不同数据源上的目标是否要分开归一化;
- 一个目标提升时,另一个目标是否退化。
多目标训练常常要和 curriculum、分阶段训练、冻结/解冻策略一起设计。否则辅助目标很容易压制主目标,或者后训练目标把预训练能力冲掉。
Loss 是训练压力的代理,不是最终能力本身。某个辅助 loss 下降,可能只是模型学会了更容易的中间任务;偏好 loss 改善,也可能伴随事实性、长上下文或格式稳定性退化。更稳的读法是:每次改 loss、权重或 schedule,都要同步看分桶评测、失败样本和关键能力回归。
优化器的角色
一阶优化器可以抽象为:
其中 是基于梯度和历史统计构成的更新方向, 是学习率。
| 优化器 | 特点 | 常见注意点 |
|---|---|---|
| SGD | 简单、经典 | 大模型中通常不如自适应方法方便 |
| Momentum SGD | 平滑更新方向 | 视觉和表征任务仍常见 |
| Adam | 一阶/二阶矩自适应 | 状态内存高,超参经验成熟 |
| AdamW | 解耦 weight decay | Transformer 默认选择 |
| Muon | 对矩阵权重的动量做正交化 | 主要用于大规模预训练,通常与 AdamW/Adam 混合处理非矩阵参数 |
| Adafactor | 节省优化器状态 | 行为和调参经验不同于 AdamW |
| Lion 等变体 | 试图减少状态或改变更新几何 | 需要充分大规模证据 |
工业大模型训练里,AdamW 仍常作为默认起点,不是因为它理论上永远最优,而是因为稳定、可预期、经验最丰富。
Muon 代表另一类思路:把 Transformer 中的矩阵参数当作线性算子来更新,通过 Newton-Schulz 近似正交化 momentum,减少少数奇异方向主导训练的问题。它在 Muon 专题讲解 中被系统验证到 5.7T token MoE 预训练,但在 SFT、后训练和已有 AdamW checkpoint 迁移上仍要单独验证。
学习率日程
学习率日程几乎和优化器同样重要。常见形式是 warmup + decay:
Warmup 的作用不只是平滑优化,它还能让混合精度、梯度统计、dataloader 和分布式通信进入稳定区间。Decay 可以是 cosine、linear、constant with decay 或多阶段 schedule。
学习率设计要和以下因素一起看:
- effective batch;
- 训练阶段和数据切换;
- loss 组成和权重;
- 梯度裁剪;
- 混合精度和 loss scaling;
- checkpoint 恢复后的 global step。
很多“模型不稳定”其实是 schedule 和阶段切换不匹配。
正则、裁剪与稳定项
常见稳定手段包括:
- weight decay;
- gradient clipping;
- dropout / stochastic depth;
- label smoothing;
- KL / reference constraint;
- auxiliary loss;
- norm、logit、activation 相关约束。
这些手段都不是越多越好。它们会改变优化几何和能力分布。比如过强 KL 会限制偏好学习收益,过强 clipping 会掩盖真正的数值异常,过强 auxiliary loss 会让模型偏向容易优化的中间任务。
使用这些项时要记录触发频率、实际 loss scale、对主指标的影响,以及是否在特定数据桶上造成退化。
配置验收清单
目标函数、优化器和日程上线前至少要回答:
- 主 loss 和辅助 loss 的权重如何确定;
- loss scale 是否随数据源或阶段变化;
- 学习率、warmup、decay 和 effective batch 是否匹配;
- optimizer state、scheduler state 和 scaler 是否能完整 checkpoint;
- gradient clipping、weight decay、KL 等稳定项是否有监控;
- 数据切换点、loss 切换点和 LR 切换点是否对齐;
- 是否按能力桶观察收益和退化;
- 恢复训练后曲线是否连续。
训练目标不是静态公式,优化器也不是默认选项。它们共同定义训练轨迹。成熟训练系统会把 loss 配方、数据阶段、学习率、batch、数值稳定和 checkpoint 状态作为同一个配置资产管理。
- Title: 训练:目标函数、优化器与 LR 日程
- Author: Charles
- Created at : 2026-03-09 09:00:00
- Updated at : 2026-03-09 09:00:00
- Link: https://charles2530.github.io/2026/03/09/ai-files-training-objectives-optimizers-and-schedules/
- License: This work is licensed under CC BY-NC-SA 4.0.