
训练:预训练、微调与对齐
今天的大模型几乎都不是一次训练出来的。它们通常经历三层递进过程:预训练、监督微调和偏好对齐。三层做的事情不同,混成一个概念会让模型设计和问题诊断失真。
一个简化记法是:
- 预训练:决定模型“能不能”;
- SFT:决定模型“怎么做”;
- 对齐:决定模型“倾向怎么选”和“边界在哪里”。
三层训练的分工
| 阶段 | 核心目标 | 主要塑造 |
|---|---|---|
| 预训练 | 从大规模数据中学习通用分布 | 知识、语言、代码、表示和能力边界 |
| SFT | 学习高质量示范行为 | 指令遵循、格式、任务流程 |
| 偏好对齐 | 在多个可行答案中偏向更好答案 | 风格、风险偏好、拒答边界、简洁度 |
把模型看作新员工:预训练像多年教育背景和阅读积累,SFT 像岗位培训,对齐像企业文化、服务规范和风险制度。
预训练主要塑造能力边界,SFT 主要塑造任务格式和行为,对齐主要塑造选择倾向和风险边界。后训练可以组织和调动已有能力,但很难凭空补出底座从未学到的知识和推理结构。
预训练像让员工读很多行业资料,SFT 像教他按工单流程回答,对齐像告诉他什么时候要拒绝、升级或更礼貌。只做礼貌培训,不能补上行业知识;只读资料,也不代表会按公司流程服务。
预训练:能力边界
语言模型最常见的预训练目标是 next-token prediction:
这个目标迫使模型从海量文本、代码和多模态 token 中学习语法、常识、事实共现、代码模式、长程依赖和推理痕迹。它主要塑造能力边界。
但预训练损失低不代表下游一定强,因为它优化的是平均 token 预测,而真实任务可能关心严格格式、长链推理、工具使用、安全边界和交互体验。预训练打底,但不直接定义产品行为。
若模型缺少数学推导、代码修复或长上下文建模能力,后续对齐通常很难凭空补出来。能力短板更可能来自预训练数据、规模、目标或训练阶段设计。
SFT:行为克隆
监督微调通常仍是条件交叉熵:
其中 是输入, 是高质量目标回答。SFT 的作用通常不是重建整个世界知识,而是让模型学会按任务格式回答、遵循指令、组织输出和执行流程。
从训练角度看,SFT 很像语言行为克隆。它高度依赖示范数据质量。如果示范数据模板僵硬、逻辑不严谨、过度冗长、拒答错误或风格不稳定,模型会一并学进去。
SFT 常见问题包括:
- 模板化严重,回答像流水线;
- 训练数据覆盖窄,出分布任务行为不稳;
- 长答案学会了格式,但事实和推理没跟上;
- 私域流程学得好,但通用能力被冲淡;
- 与预训练底座能力不匹配,出现过拟合式“听话”。
偏好对齐:选择倾向
即使经过 SFT,模型仍可能在多个合理答案之间选出不符合人类偏好的回答。偏好对齐引入成对或排序数据,例如优选 和劣选 。
InstructGPT 原论文的流程图很适合先建立全局直觉:对齐不是直接让人类给每个 token 标答案,而是先收集示范,再收集人类排序训练 reward model,最后用强化学习让策略朝高奖励回答移动。
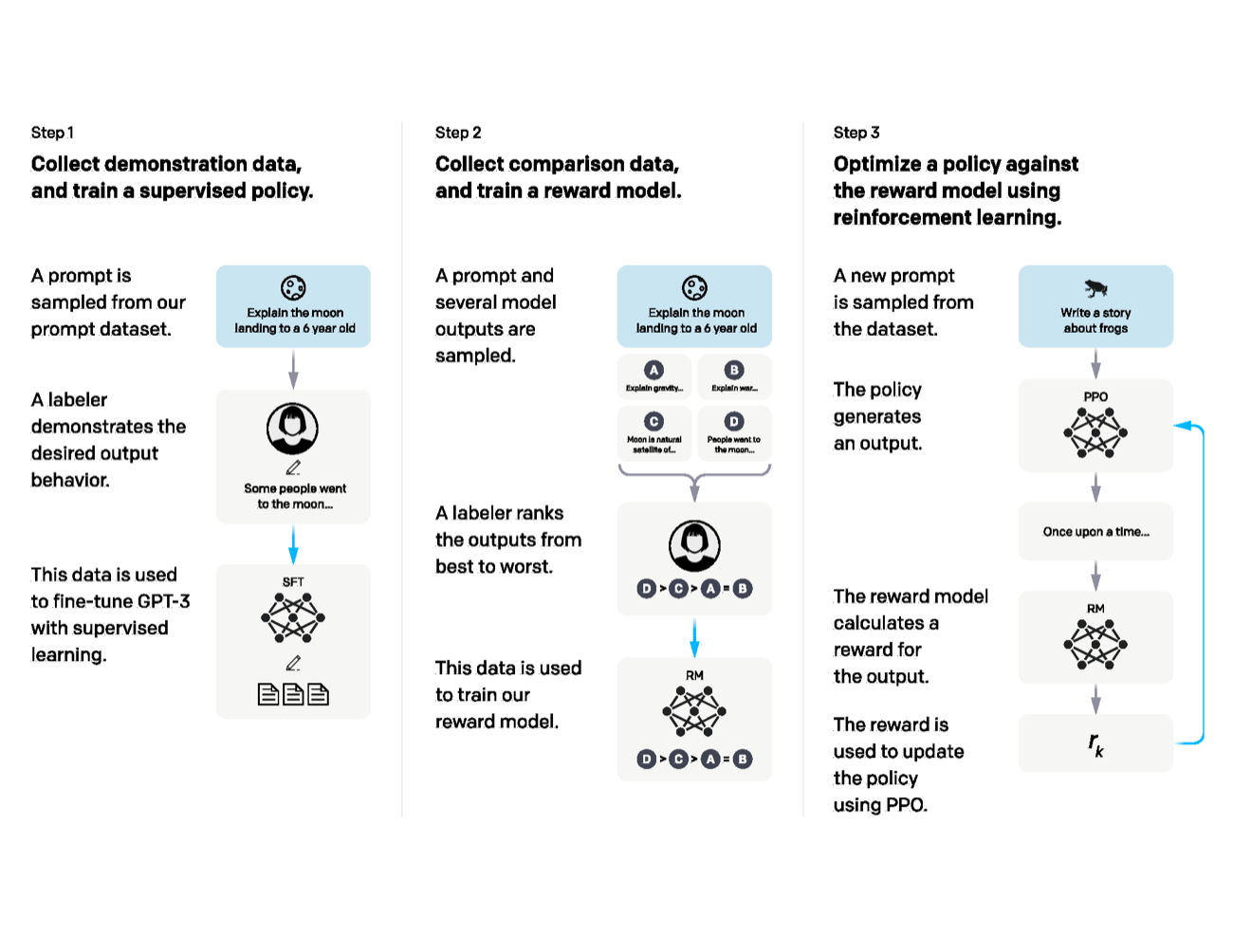
图源:Training language models to follow instructions with human feedback,Figure 2。原论文图意:展示 InstructGPT 的三步训练流程:收集 demonstration data 做 SFT,收集模型输出排序训练 reward model,再用 PPO 按 reward model 优化 policy。
Step 1 是监督学习:人写出理想回答,模型学习模仿。Step 2 是偏好建模:同一个 prompt 下采样多个回答,让标注者排序,再训练 reward model 预测人类更偏好哪个。Step 3 才是强化学习:当前模型作为 policy 生成回答,reward model 给回答打分,PPO 根据奖励更新 policy。也就是说,RLHF 不是“人类实时教模型每一步怎么写”,而是“先学一个奖励函数,再用这个奖励函数训练生成策略”。
以 DPO 为例:
它推动策略相对参考模型提高优选回答概率,压低劣选回答概率。RLHF、DPO、RLAIF 等方法细节不同,但都在回答:模型已经会做很多事,怎样让它更符合人类或系统偏好。
对齐特别敏感,因为它依赖偏好标签质量、参考模型、KL/reference constraint、学习率和样本分布。很多体验问题,例如啰嗦、拒答边界奇怪、自信但不确定,往往更像 SFT/对齐问题,而不是预训练问题。
没有强化学习基础时怎么理解 RLHF
强化学习最小直觉是:一个 policy 在环境里做 action,环境给 reward,训练目标是让未来奖励更高。把这个翻译到语言模型里:
| 强化学习词 | 普通 RL 例子 | RLHF 里的对应物 |
|---|---|---|
state |
游戏画面、机器人当前状态 | prompt 加上已经生成的前缀 |
action |
往左走、夹爪闭合 | 生成下一个 token |
policy |
看到状态后选择动作的模型 | 当前语言模型 |
trajectory |
一串状态和动作 | 从 prompt 到完整回答的 token 序列 |
reward |
得分、成功、碰撞惩罚 | reward model 对完整回答的分数 |
reference policy |
更新前的稳定策略 | SFT 模型或旧策略,用来限制别跑太远 |
value |
估计当前状态未来能拿多少分 | 估计当前前缀最终会得到多少奖励 |
advantage |
这个动作比预期好多少 | 这个 token/回答相对 value 估计是否更好 |
语言模型的特殊之处在于,reward 通常不是每个 token 都有一个明确分数,而是完整回答结束后才由 reward model 评分。设 prompt 为 ,回答为 ,策略概率是:
RLHF 想最大化的是类似下面的目标:
这里 是 reward model 给完整回答的分数;KL 项是“别离参考模型太远”的刹车。没有 KL,模型可能学会钻 reward model 的空子,例如变得异常啰嗦、过度自信、固定模板化,甚至输出 reward model 偏爱的奇怪格式。
完整回答结束后才知道奖励,但更新发生在许多 token 决策上。value 用来估计“生成到当前前缀时,未来大概能拿多少分”;advantage 用来估计“这次采样出来的结果比预期好多少”。如果 advantage 为正,PPO 会倾向提高这段生成路径的概率;如果 advantage 为负,就倾向压低。没有 advantage,训练信号会很吵,因为每个 token 都很难知道自己对最终奖励贡献了多少。
PPO 原论文给出的算法框架可以帮助你把这件事从“抽象奖励”落到训练步骤上:
1 | collect rollouts -> estimate advantages -> optimize clipped surrogate -> refresh old policy |
流程源:Proximal Policy Optimization Algorithms,Algorithm 1。原论文算法要点:多个 actor 用旧策略收集固定长度轨迹,计算 advantage estimates,再用若干个 minibatch epoch 优化 surrogate objective,最后把旧策略更新为当前策略。
原始 PPO 图里的 actor 在环境里跑 步;RLHF 里可以理解成模型对一批 prompts 采样回答。Compute advantage estimates 对应根据 reward model 分数、value 估计和 KL 惩罚计算训练信号;Optimize surrogate 对应用 minibatch 更新语言模型。PPO 名字里的 proximal 重点是“不要一步改太远”:模型要朝高奖励回答移动,但不能突然远离 SFT/reference 模型,否则容易牺牲事实性、格式稳定和基础能力。
PPO 的 clipped surrogate 图进一步解释了这个“别改太远”。
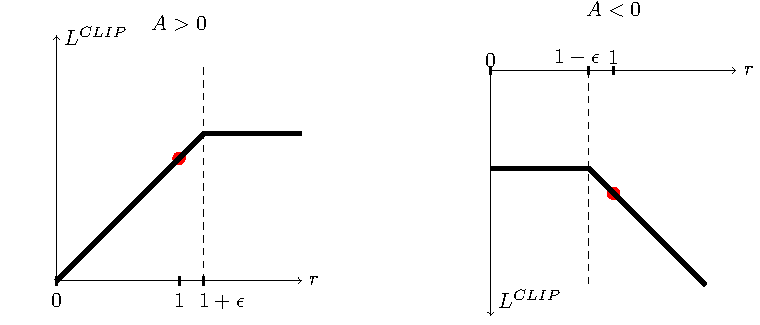
图源:Proximal Policy Optimization Algorithms,Figure 1。原论文图意:展示 clipped surrogate objective 中单个 timestep 项如何随概率比率 变化;当 advantage 为正或负时,clip 会限制策略概率变化带来的收益。
表示新策略相对旧策略把同一动作概率改了多少。若 advantage 为正,模型想把这个动作概率调高;若 advantage 为负,模型想调低。clip 会在 到 附近限制收益,防止模型因为 reward model 的局部偏好一下子把概率推得太远。放到 RLHF 里,这就是为什么 PPO 训练既看 reward,也要看 KL、clip fraction、回答长度、事实性和拒答边界。
从 Qwen3 看现代后训练流水线
如果只用“预训练、SFT、对齐”三段来概括今天的模型训练,会有点太粗。技术报告里的后训练已经更像一条生产线:先让模型会按格式推理,再用可验证奖励把推理拉强,再把 thinking / non-thinking、工具、RAG、格式、安全和偏好合回同一个产品模型里。
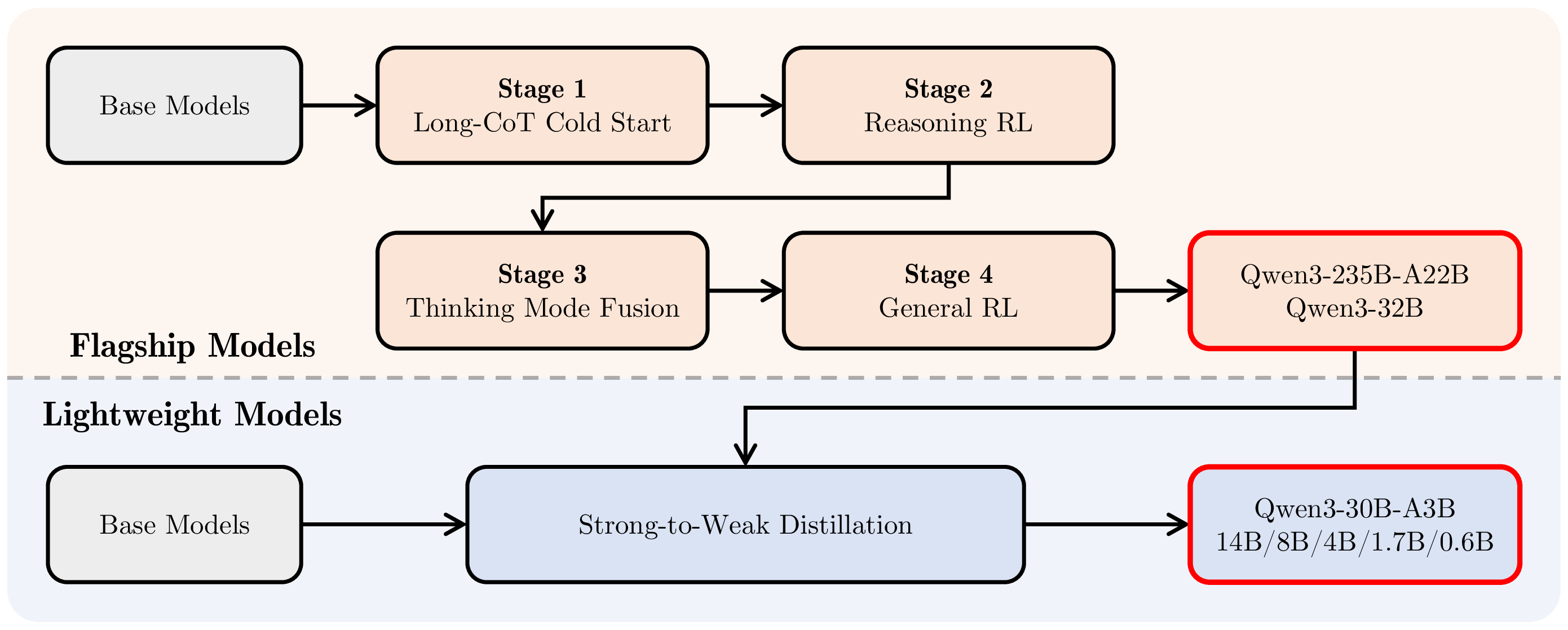
图源:Qwen3 Technical Report,Figure 1。原论文图意:Qwen3 系列的 post-training pipeline,旗舰模型经过 Long-CoT Cold Start、Reasoning RL、Thinking Mode Fusion、General RL;轻量模型通过 strong-to-weak distillation 继承大模型能力。
这张图说明 SFT、RL 和 distillation 不是三种互相替代的训练菜谱,而是在流水线上承担不同工序。Cold start SFT 像先教模型“怎么把解题过程写成可读格式”;Reasoning RL 像让模型在可验证题目上反复试错,提高正确率;Thinking Mode Fusion 像把“认真写草稿”和“快速直接答”两种产品行为合进一个模型;General RL 再负责工具、格式、偏好、安全和通用交互。
可以把这条线拆成四个更容易记的动作:
| Stage | 更通俗的理解 | 为什么不是可有可无 |
|---|---|---|
| Long-CoT Cold Start | 先给模型几份清楚的解题范文 | 没有基础格式,RL 采样容易又乱又难筛 |
| Reasoning RL | 在有 verifier 的题上自己试错 | 让模型探索人类示范没覆盖的长推理路径 |
| Thinking Mode Fusion | 把长思考和短回答合到同一模型 | 产品里不是所有问题都值得长 CoT |
| General RL | 修工具、格式、偏好和安全边界 | 会推理不等于好用,agent 任务还要会执行流程 |
这也解释了为什么 DeepSeek-R1 和 Qwen3 都很重视 verifiable rewards。数学、代码、选择题、格式检查、单元测试这类任务,可以自动判断最终答案是否对;一旦 reward 足够可靠,RL 就能让模型在同一道题上采样多条路径,通过“哪条真的成功”来更新策略。
Cold start SFT 像老师先给你几份优秀解题卷,告诉你步骤该怎么写。Reasoning RL 像刷题系统只看最终答案和代码测试是否通过,让你自己摸索更稳的解法。General RL 像入职后处理真实工单:不只要答案对,还要格式对、工具用对、风险边界对、用户能看懂。
轻量模型的 strong-to-weak distillation 也很关键。大模型完整跑一遍后训练很贵,小模型直接做 RL 又可能探索不动;用强模型产出数据和轨迹,再蒸馏到小模型,是把“旗舰模型的经验”压缩给边缘或低成本模型。这不是简单复制答案,而是在复制任务格式、推理风格、工具流程和偏好边界。
问题归因
诊断模型问题时,可以按下面表格初步归因:
| 症状 | 更可能的问题层 |
|---|---|
| 基础知识、数学、代码能力弱 | 预训练数据、规模、目标或训练预算 |
| 不会按格式输出、不会跟指令 | SFT 数据和任务覆盖 |
| 会做但风格差、啰嗦或拒答怪 | 偏好数据和对齐目标 |
| 工具调用流程不稳 | SFT 流程数据 + 对齐反馈 |
| 私域知识不足 | 预训练/继续训练/检索数据覆盖 |
| 长上下文丢信息 | 预训练长上下文、packing、位置编码和推理系统 |
| 安全边界不稳 | 对齐、策略、评测和拒答数据 |
不要指望对齐补所有能力短板,也不要把所有产品体验问题都归咎于底座不够强。
数据与阶段切换
三层训练的关键不是机械串联,而是阶段切换时保持能力和行为的平衡。
需要重点控制:
- 预训练到 SFT 时,示范数据是否覆盖目标任务;
- SFT 是否过度改变底座输出分布;
- 对齐是否把模型推得过远,造成能力或事实性退化;
- reference model、KL 约束和学习率是否匹配;
- 每阶段是否保留 anchor eval,防止遗忘;
- 数据是否存在评测污染、模板污染和偏好偏置。
很多后训练事故不是单个算法错,而是阶段切换没有定义清楚验收边界。
评测清单
每个阶段应有不同验收重点:
- 预训练:perplexity、通用能力、代码/数学/长上下文、多语言、数据污染;
- SFT:指令遵循、格式稳定性、任务覆盖、私域流程、拒绝无关任务的能力;
- 对齐:偏好胜率、安全边界、简洁度、拒答准确性、事实性退化;
- 跨阶段:能力保持、风格漂移、长尾任务、线上 A/B、成本和延迟。
预训练、微调和对齐不是独立孤岛。真正成熟的训练管线,会把能力边界、行为格式、偏好选择和风险边界作为连续系统来管理,而不是把每个阶段当作单独刷榜步骤。
实践中还应保留跨阶段追踪表:每个模型版本都记录底座来源、SFT 数据版本、偏好数据版本、reference model、关键超参和已知退化项。这样线上问题回溯时,团队才能判断应回到哪一层修,而不是反复在最后一层对齐上打补丁。
- Title: 训练:预训练、微调与对齐
- Author: Charles
- Created at : 2026-03-18 09:00:00
- Updated at : 2026-03-18 09:00:00
- Link: https://charles2530.github.io/2026/03/18/ai-files-training-pretraining-finetuning-alignment/
- License: This work is licensed under CC BY-NC-SA 4.0.