
训练:Scaling、课程学习与数据配比
很多训练讨论在谈模型结构,但真正决定大模型成长曲线的,往往是 Scaling、课程学习和数据混合。它们共同决定有限计算预算会被分给哪些样本、哪些阶段、哪些能力。
这页关注训练配方层的决策,和 训练数据系统与吞吐优化、数据质量、去重与治理、评测与消融方法 应该一起看。
Scaling 决定预算大致花在模型、数据还是训练步数上;数据混合决定模型每天“上什么课”;课程学习决定这些课按什么顺序出现。三者合在一起,才是一份真正的训练配方。
只增加训练时长不一定能让运动员变强。如果每天只练同一个动作,会偏科;如果第一天就上极限强度,会受伤。大模型也是类似:规模、数据比例和阶段顺序要一起设计。
Scaling 在讨论什么
最粗略地说,训练表现可以看作模型规模 、数据规模 、计算预算 的函数:
Scaling law 的价值不在于给出一个永远可照搬的指数,而在于把训练从“拍脑袋堆大”变成预算分配问题:
- 参数更大不自动更优;
- 数据太少时,大模型会浪费;
- 计算预算有限时,模型、数据和训练步数要平衡;
- 推理成本会反过来约束可接受的模型规模。
真实系统里,compute-optimal 和 product-optimal 经常不是一回事。某个模型规模也许训练损失最优,但如果上线后显存、延迟、缓存、路由和成本都显著恶化,它就未必是产品层最优。
成熟训练决策应同时看:
- 训练损失下降速度;
- 下游能力收益;
- 推理和服务成本;
- 系统复杂度与可靠性;
- 后续数据闭环和迭代成本。
数据混合是隐形目标函数
若训练分布由多个来源构成,可以写成:
这里 不是普通工程参数,它直接塑造模型能力和风格。网页文本多,知识广但噪声大;代码多,工程能力强但对话风格可能变硬;指令数据多,交互更顺但底层语言建模可能被冲淡;私域数据多,领域能力增强但泛化边界会变窄。
可以把数据混合比理解成模型的课程表。课程表不同,最后训练出的不是同一个系统:
| 数据侧重点 | 常见收益 | 常见副作用 |
|---|---|---|
| 网页/百科 | 通用知识、语言覆盖 | 噪声、重复、模板化 |
| 代码/仓库 | 编程、工具、结构化推理 | 对话自然度下降、版权和重复风险 |
| 数学/推理 | 长链推理、形式化能力 | 可能牺牲开放式表达 |
| 指令/偏好 | 交互、格式、产品可用性 | 过度模板化、基础能力遗忘 |
| 私域/企业 | 内部流程和 API 知识 | 数据孤岛、更新和权限治理复杂 |
数据混合的真正难点,是它不像新架构那样显眼,也不像更多 GPU 那样容易被量化。但很多能力变化其实来自某类数据被正确放大、某类噪声被压低、某类长尾被保留下来。
课程学习的作用
课程学习可以理解为训练分布随时间变化:
它不只是“从简单到困难”,而是沿多条轴设计训练路径:
- 长度轴:先短上下文,再长上下文;
- 噪声轴:先高质量稳定数据,再逐步放开开放域数据;
- 任务轴:先基础预测,再引入推理、工具、偏好和对齐;
- 模态轴:先高质量图文或短轨迹,再引入复杂文档、视频和动作序列。
课程学习有效的一个优化视角是:让模型先在更平滑、低噪的目标地形上找到合理 basin,再逐步提高任务复杂度。如果一开始就把低质 OCR、复杂图表、长文档、多轮工具调用、遥操作轨迹全部混在一起,早期表征可能非常不稳定。
它也不是免费午餐。坏课程常见于两种情况:早期数据过于理想化,导致后期接触真实分布时冲击很大;或者团队凭主观直觉定义简单/困难,但这个划分与真实任务结构不一致。
从 Wan Figure 3 看动态数据配方
视频模型把数据配方这件事讲得特别清楚。Wan2.1 论文里的 Figure 3 不是在画一个“数据清洗流水线”,而是在画训练过程里数据供给如何随阶段变化:图像、视频、文字数据从同一个 pool 出发,在 192P / 480P / 720P / SFT 等阶段不断经过 visual filter、motion filter、resolution filter 和训练采样。
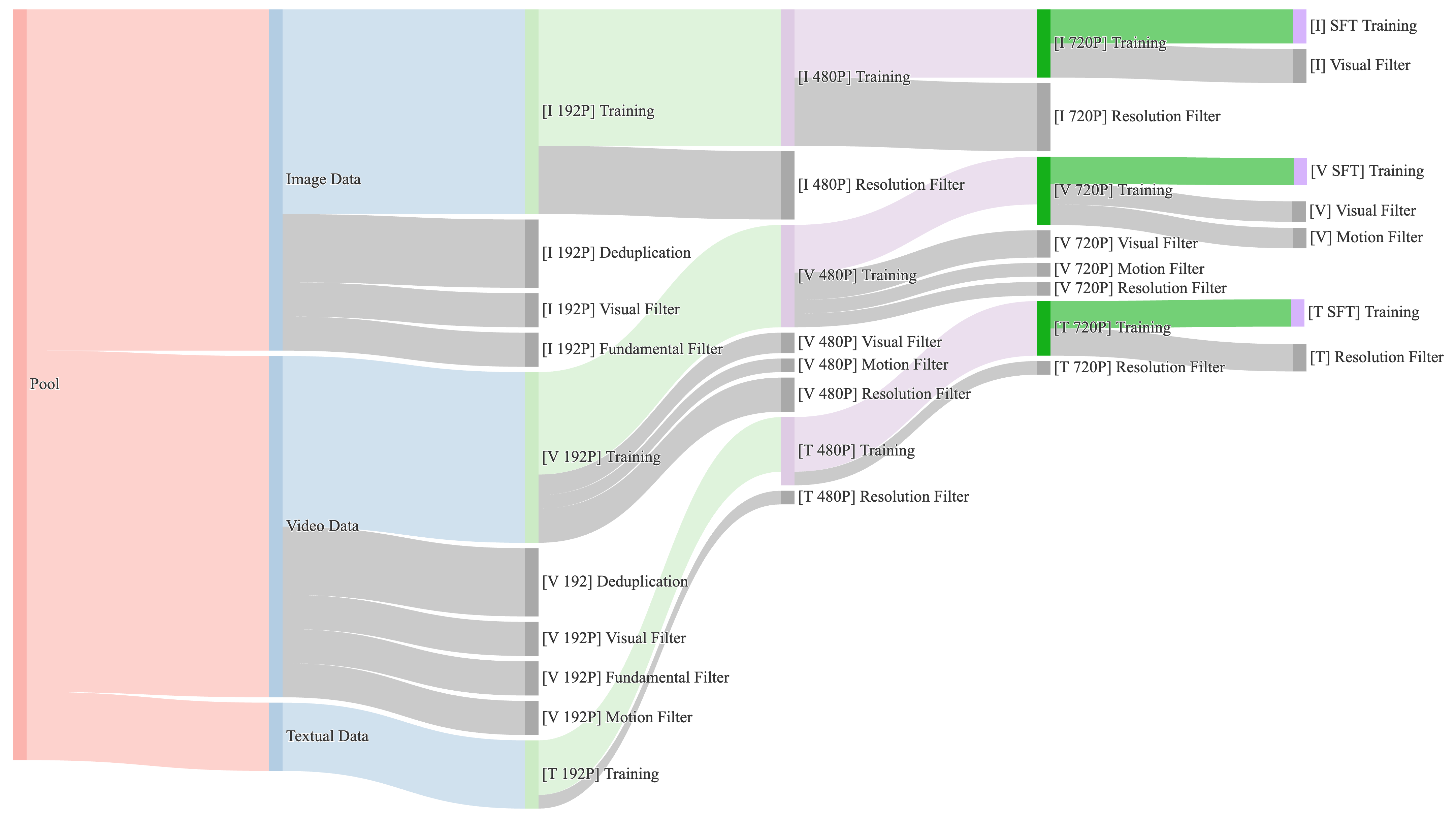
图源:Wan: Open and Advanced Large-Scale Video Generative Models,Figure 3。原论文图意:不同训练阶段的数据供给策略会动态调整 motion、quality 和 category 的比例。
很多初学者会把数据混合想成一张固定菜单:网页 40%、代码 20%、数学 10%、视频 30%。Wan 这张图提醒我们,真实大模型训练更像排学期课表:早期低分辨率阶段需要规模和覆盖面,先让模型见过足够多的对象、场景和粗运动;中后期高分辨率阶段更强调画质、运动质量和分辨率门槛;SFT 阶段再把数据收窄到最终用户更关心的观感、指令和偏好。
motion 控制模型看到多少真正有意义的运动,避免被静态视频、抖动镜头和低质量动作带偏;quality 控制清晰度、审美、压缩噪声和分辨率门槛;category 控制内容类别、图像/视频/文字比例和长尾覆盖。真正的课程学习不是“越高质越好”,而是每个阶段都问:这一阶段最需要模型补哪块能力?
这也适用于语言、多模态和机器人模型。长上下文训练不是一开始就把 1M token 塞进去;机器人也不是先把所有失败轨迹混在一起。更稳妥的做法,是让模型先学稳定表征,再逐步提高长度、分辨率、任务复杂度和动作多样性。
不同场景的配方重点
| 场景 | 数据混合重点 | 课程重点 | 主要风险 |
|---|---|---|---|
| 通用语言模型 | 多样性、去重、长尾知识 | 从稳定高质语料到更广覆盖 | 高质量多样性不足、验证集污染 |
| 代码模型 | 仓库级去重、文档/测试/issue 比例 | 从函数级到仓库级和工具链 | 只会写片段,不懂工程上下文 |
| 数学/推理模型 | 题目、解析、验证器、失败样本 | 从短链到长链,从单步到多步 | 过拟合格式,泛化差 |
| VLM | 图文配对、OCR、图表、屏幕 | 从自然图像到文档/图表/长上下文 | 视觉聊天强,结构理解弱 |
| VLA/机器人 | 遥操作、失败恢复、环境多样性 | 从短技能到长任务和真实长尾 | 什么都见过,但闭环不稳 |
| 企业助手 | 代码、文档、FAQ、工单、事故复盘 | 从通用能力到私域流程 | 通用助手化,缺少内部系统知识 |
企业代码助手是一个直观例子。只加入 GitHub 代码,模型可能会写函数;加入内部文档、工单、事故复盘和发布规范后,模型才可能理解服务依赖、上线流程、历史故障和内部 API 使用边界。
配方要成为版本化资产
成熟团队不会只维护一个“全量语料池”,而会维护可版本化的数据配方:
- 数据源分层和标签;
- 去重、过滤、质量打分版本;
- 各源采样比例;
- 不同阶段的 curriculum 配方;
- sampler、packer 和 shard 版本;
- 每轮训练后的能力变化报表。
一个训练阶段的配方可以显式写成:
然后把它和 benchmark 变化、人工评测、线上指标和服务成本对应起来。哪怕不是严格因果分析,也比“凭感觉加一点代码数据”更可解释。
评测与消融
数据混合和课程学习最容易产生伪收益。一次配方调整看起来有效,可能只是训练步数、样本难度、评测污染或随机波动造成的。
建议固定三类评测:
- 能力桶:通用知识、代码、数学、长上下文、工具、私域、多模态;
- 阶段桶:预训练中期、预训练末期、后训练前后、对齐前后;
- 成本桶:有效 token、GPU 小时、吞吐、数据处理成本、推理成本。
关键消融不需要一次做很大,但要回答清楚:
- 变的是数据质量、数据比例,还是训练顺序;
- 收益发生在哪些能力桶;
- 是否有能力退化;
- 是否在小规模 pilot 和大规模训练中方向一致;
- 是否能被下一轮训练复现。
没有这些记录,数据配方会变成玄学经验,团队很难积累。
常见失败模式
| 失败模式 | 表现 | 处理方向 |
|---|---|---|
| 数据源权重过高 | 某类能力变强,通用能力退化 | 降低比例,增加保持集评测 |
| 课程切换过猛 | loss 抖动、能力突然漂移 | 平滑过渡,混入 anchor 数据 |
| 高质数据过窄 | 评测好看,开放场景弱 | 增加多样性和长尾覆盖 |
| 指令数据过量 | 回答模板化,底层能力变弱 | 控制后训练比例,保留预训练能力 |
| 长上下文课程失败 | 长文本不稳,短任务退化 | 分阶段扩窗,按长度桶评估 |
| 私域数据污染 | 模型背诵敏感内容 | 权限、脱敏、记忆评测和回收机制 |
Scaling、课程学习和数据混合的核心不是“某个比例最优”,而是建立一套可被复盘的预算分配机制。真正成熟的训练配方,会把模型规模、数据质量、阶段顺序、评测桶和系统成本放在同一张表里讨论。
- Title: 训练:Scaling、课程学习与数据配比
- Author: Charles
- Created at : 2026-03-20 09:00:00
- Updated at : 2026-03-20 09:00:00
- Link: https://charles2530.github.io/2026/03/20/ai-files-training-scaling-curriculum-and-data-mixture/
- License: This work is licensed under CC BY-NC-SA 4.0.