
世界模型:Masked / JEPA 与潜变量预测:先学状态,再接动作
世界模型常被想象成“给当前画面和动作,生成未来视频”。这当然是一条路线,但不是唯一入口。对规划和控制来说,模型真正需要保住的是会改变动作选择的状态:物体位置、速度、接触、遮挡、任务阶段、风险、奖励和终止。高清纹理、背景光照、阴影细节有时只是昂贵的旁枝。
Masked / JEPA 路线的核心问题是:**能不能先学一个更像状态的表征,再把动作条件、奖励、风险和 planner 接上去。**它不是把像素预测全部否定,而是把“训练信号”和“决策接口”分开看。
先把四类目标分清
很多误读来自把 masked modeling、JEPA 和 action-conditioned world model 混成一件事。它们确实都在预测缺失信息,但回答的问题不同。
| 训练目标 | 简化写法 | 它证明了什么 | 它没有证明什么 |
|---|---|---|---|
| Pixel reconstruction | 模型能从可见上下文复原被遮像素。 | 复原像素不等于会选动作。 | |
| Masked latent reconstruction | 模型能补全被遮挡的表征。 | latent 是否保留 reward、risk 和接触仍要验证。 | |
| JEPA / joint embedding prediction | 模型能从上下文预测目标区域的高层表示。 | 原始 JEPA 通常不含动作、奖励和终止。 | |
| Action-conditioned latent dynamics | 模型开始回答“做这个动作会怎样”。 | 多步漂移、planner exploit 和闭环安全仍要单独评测。 |
这张表要按接口读。MAE 问“被遮住的像素能不能还原”;JEPA 问“被遮住或未来区域的表示应该是什么”;action-conditioned dynamics 才问“如果采取动作 ,未来状态 怎么变”。世界模型用于控制时,最后一个问题躲不开。
MAE:像素补全是强训练信号,但不是最终接口
Masked Autoencoder 的直觉很干净:把图像 patch 遮掉大部分,只让 encoder 看可见 patch,再让轻量 decoder 重建被遮像素。
是可见 patch, 是被遮 patch, 是 mask。这个目标的好处是监督信号密集、训练稳定、结果可视化;模型必须理解局部结构和全局上下文,才能把缺失区域补回来。
但它也会把大量容量花在低层细节上。纹理、光照、背景和压缩噪声都能影响 pixel loss;而机器人下一步动作可能只关心杯沿、夹爪接触点和目标物是否滑动。于是很多世界模型会把像素重建当作塑造表示的工具,而不是让 planner 在像素空间里评估每条候选未来。
一个更实用的链路是:
1 | 原始观测 x |
重点不是“永远不要生成视频”,而是“控制主链路不一定需要每个候选动作都解码成高清视频”。
MWM:先学视觉状态,再学动作后果
Masked World Models for Visual Control 是很适合放在 JEPA 前面的桥。它没有说 masked reconstruction 本身已经会规划,而是把问题拆成两层:先用 masked visual autoencoder 学更干净的视觉表示,再在这个 latent space 里训练 dynamics model。
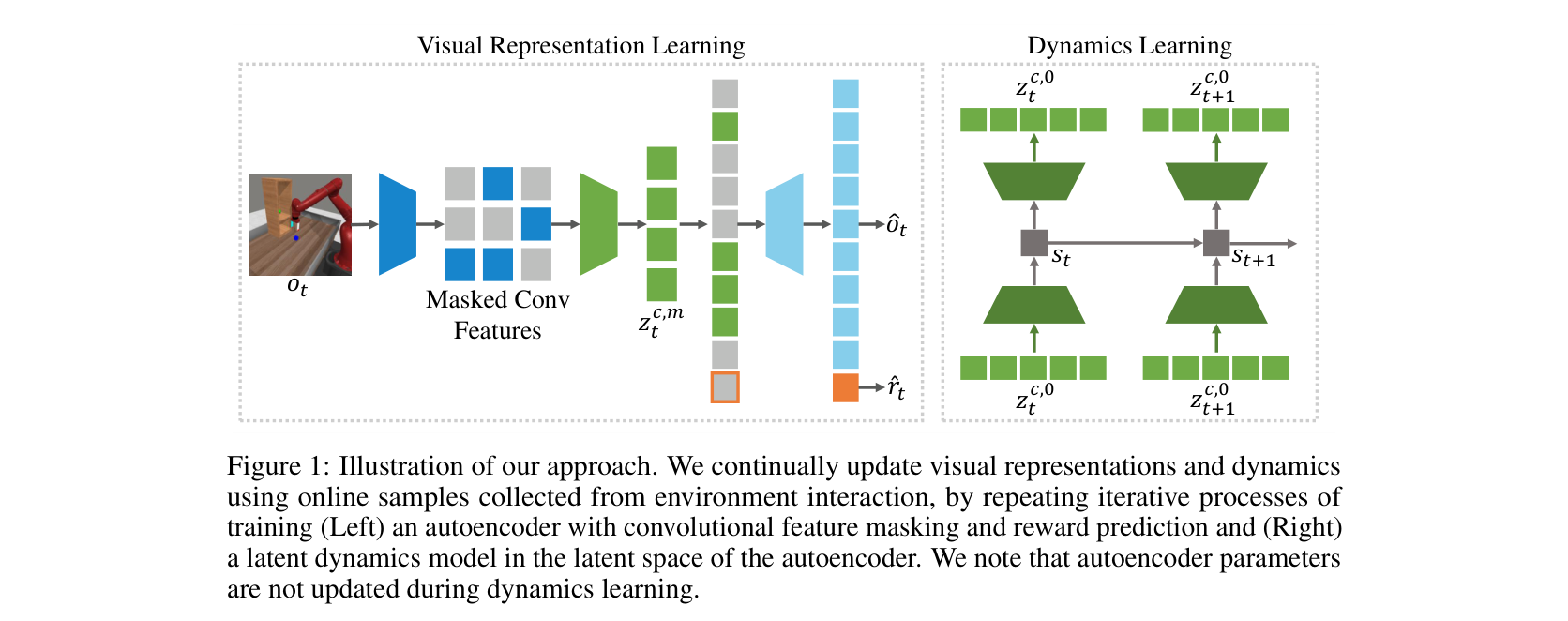
图源:Masked World Models for Visual Control,Figure 1。本站复用已有论文图,未使用 image2 生成新图。原图表达:左侧训练 masked visual autoencoder 并预测 reward,右侧在 autoencoder latent space 中训练 latent dynamics。本站读法:左边负责“看懂并压缩”,右边负责“动作之后怎么变”;两者解耦是为了减少视觉噪声对 dynamics 的干扰。
MWM 的关键词是 decoupling。视觉 encoder 如果一边为像素重建服务,一边被 dynamics 反复拉扯,容易在“画得像”和“对控制有用”之间互相干扰。先学表示,再学 dynamics,相当于把世界模型拆成两个问题:状态怎么表示,状态怎么随动作变化。
这也给后面的 JEPA 一个阅读线索:masked / latent prediction 的价值不在于替代 dynamics,而在于给 dynamics 提供一个更便宜、更稳、更接近状态的输入空间。
JEPA:预测目标表示,而不是目标像素
JEPA 的转向是把目标从“补像素”换成“补 target encoder 的 embedding”。一个简化流程是:
1 | 完整图像或视频 x |
可以写成:
是 context encoder, 是 target encoder, 是 predictor, 表示 stop-gradient。读这行公式时抓两点:第一,模型输出的是目标区域表示,不是 RGB;第二,target encoder 给学习目标,但不会被 predictor 这条梯度直接拖着走。
这样做的动机是把容量更多花在对象、空间关系、运动和场景结构上,而不是逐点纹理。I-JEPA 把这个思想落到图像 block;V-JEPA 把它扩展到视频时空块;V-JEPA 2 再把 action-free 表征接到 action-conditioned planning。
V-JEPA:视频预测表征,不是生成视频
V-JEPA 的论文标题是 feature prediction。它训练的是视频表示:context encoder 看 masked sequence,predictor 根据可见上下文和 mask token 预测目标位置的 feature,target encoder 从完整输入提供 latent target。
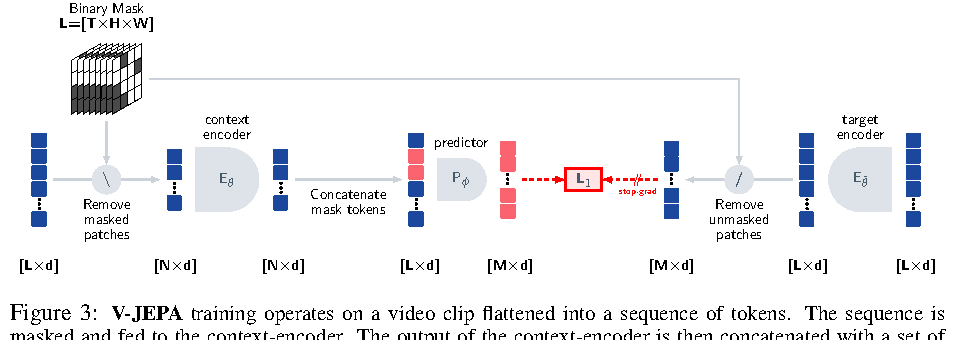
图源:V-JEPA: Revisiting Feature Prediction for Learning Visual Representations from Video,Figure 3。本站复用已有论文图,未使用 image2 生成新图。原图表达:context encoder 处理 masked sequence,predictor 用 mask tokens 预测目标位置,target encoder 处理完整输入并提供 latent target。本站读法:老师网络给目标表示,学生网络根据可见上下文预测;输出不是 RGB,而是 representation。
这让 V-JEPA 更接近“状态学习”而不是“视频生成”。它可以学习时空连续性、对象关系和运动线索,但原始 V-JEPA 仍是 action-free:它从视频上下文预测视频表示,不直接回答“如果机器人采取动作 ,未来会怎样”。
所以读 V-JEPA 时要把两个结论同时放住:
| 可以说 | 不应直接说 |
|---|---|
| latent video prediction 能形成强视频表征。 | 原始 V-JEPA 已经是完整可规划世界模型。 |
| 不预测像素能减少低层重建负担。 | latent loss 自动保留所有控制关键变量。 |
| video pretraining 可以成为世界模型状态层候选。 | 只靠 action-free video pretraining 就能做机器人闭环控制。 |
这个边界非常重要。一个表征 benchmark 证明 latent 里有信息;闭环控制还要证明动作条件、目标成本、reward/risk、真实观测刷新和 planner 都工作。
V-JEPA 2:把表征接回 action-conditioned planning
V-JEPA 2 的关键进展,是把前面的 action-free 表征预训练接到少量机器人交互视频上,形成 V-JEPA 2-AC。它的规划接口更接近世界模型:给当前观测、目标图像和候选动作序列,在 latent space 里 rollout,选择让未来表示接近目标表示的动作。
它可以写成:
是当前观测表示, 是候选动作序列, 是想象出的未来 latent。Planner 问的不是“哪段视频最漂亮”,而是“哪条动作序列让未来 latent 更接近目标 latent,并且满足任务约束”。
截至 2026 年 6 月,JEPA 路线还在继续推进。V-JEPA 2.1 把重点放到 dense features、层级 self-supervision 和图像/视频统一训练;另一些 2026 工作开始直接比较 latent video prediction 模型在 corruption、occlusion、fine-grained contact 和 temporal direction 上的世界模型相关鲁棒性。这些结果支持“latent prediction 有潜力成为更稳的状态层”,但仍应按论文证据读:它们不是任意机器人平台上的部署安全证明。
和 RSSM / Dreamer 的关系
RSSM / Dreamer 和 JEPA 不是同一层东西。
| 路线 | 它主要学什么 | 控制接口 |
|---|---|---|
| MAE / masked autoencoder | 从缺失像素学视觉表征。 | 通常没有动作条件。 |
| I-JEPA / V-JEPA | 从上下文预测目标 embedding。 | 原始版本通常没有动作、reward、done。 |
| MWM | masked 表示 + latent dynamics 解耦。 | dynamics 接动作,并服务视觉控制。 |
| RSSM / Dreamer | belief state、prior/posterior、reward/continuation 和 imagined rollout。 | actor 或 planner 直接消费 latent future。 |
| V-JEPA 2-AC | action-free 表征预训练 + action-conditioned latent planning。 | MPC 用目标表示比较候选动作序列。 |
可以把 JEPA 看成世界模型状态层的候选,把 Dreamer 看成“状态 + 动作 + reward/value + policy”的控制链路。前者帮助模型少被像素细节牵着走,后者把未来变成动作选择信号。真正的机器人世界模型往往需要两者的交叉:一个强视觉状态层,加上动作条件 dynamics、风险/目标头和闭环刷新。
工程上怎么选路线
| 目标 | 更自然的起点 | 为什么 |
|---|---|---|
| 从像素做样本效率高的控制 | RSSM / Dreamer / MWM | 直接围绕 latent dynamics、reward 和 policy 训练。 |
| 大规模视频表征预训练 | V-JEPA / VideoMAE 类 masked objective | 不需要动作标注,能吃大规模视频。 |
| 目标图像驱动的短 horizon 规划 | V-JEPA 2-AC / latent MPC | 在 representation space 中比较候选动作后果。 |
| 人审、反事实回放和数据引擎 | action-conditioned video world model | 输出视频便于检查,但成本和一致性压力更大。 |
| 真实机器人实时闭环 | latent dynamics + 短 horizon refresh | 延迟、漂移、动作敏感性和安全边界比像素质量更重要。 |
一个务实判断是:如果缺动作数据,先用 masked / JEPA 学表征;如果有动作和 reward / done,尽快接 dynamics;如果要部署控制,闭环评测必须早于漂亮 demo。
失效模式要提前测
Masked / JEPA 路线最容易出现几类“看起来学到了,其实 planner 不能用”的问题。
| 失效模式 | 典型症状 | 验收办法 |
|---|---|---|
| action-insensitive latent | 换候选动作,未来表示几乎不变。 | 固定起点做 counterfactual action rollout。 |
| 丢失小但关键变量 | 抓取接触点、透明物边界、遮挡身份被压掉。 | 设计接触、遮挡、小物体和失败恢复桶。 |
| mask shortcut | 模型靠局部纹理或数据偏置补目标。 | 改 mask 尺度、时间跨度和跨场景评测。 |
| goal distance 不等于任务成功 | latent 接近目标,但真实执行失败。 | 同时看 goal distance、success、risk 和 failure replay。 |
| 多步漂移 | 一步 latent prediction 好,多步 planning 崩。 | 分 horizon 报告 drift、ranking accuracy 和 closed-loop success。 |
这也是本站反复强调的证据顺序:先看 representation,再看 action sensitivity,再看 reward/risk,再看 planner ablation,最后看 closed-loop。只停在任意一层,都不能把 claim 外推到完整世界模型。
最后判断
Masked / JEPA 的价值不是“把像素藏起来再补出来”,而是把预测目标从原始像素移到更抽象的 latent。这样能省容量、降低输出维度,让模型更多关注对象、空间关系和运动结构。
但 latent prediction 只是世界模型的一层。要进入规划和控制,还必须接动作条件 dynamics、goal / reward / risk / done、planner 或 policy,以及真实闭环评测。最容易误读的地方正是在这里:会预测表示,不等于已经会规划;但一个好表示,能让规划模型少背很多像素负担。
外部精读
- Masked Autoencoders Are Scalable Vision Learners:理解 masked pixel reconstruction 的强训练信号和非对称 encoder-decoder。
- Masked World Models for Visual Control:看 masked representation 如何接 model-based RL。
- A Path Towards Autonomous Machine Intelligence:理解 JEPA、world model、actor、cost 和规划模块在路线图里的分工。
- I-JEPA:理解图像 JEPA 如何预测 embedding 而不是像素。
- V-JEPA:看 latent video prediction 和 3D masking 设计。
- V-JEPA 2 官方研究页:看从视频理解到机器人 planning 的证据边界。
- V-JEPA 2.1:看 2026 年 dense video self-supervised features 的进展。
- Latent Video Prediction Learns Better World Models:看 latent-prediction 视频模型在鲁棒性维度上的系统评测。
相关阅读与下一步
- 外部材料:World Models 论文。
- 外部材料:DeepMind Genie 2。
- 外部材料:Meta V-JEPA 2。
- 站内下一步:世界模型专题。
- 站内下一步:RSSM、Dreamer 与规划。
- 站内下一步:世界模型评测与失效模式。
- Title: 世界模型:Masked / JEPA 与潜变量预测:先学状态,再接动作
- Author: Charles
- Created at : 2026-03-21 09:00:00
- Updated at : 2026-03-21 09:00:00
- Link: https://charles2530.github.io/2026/03/21/ai-files-world-models-masked-jepa-and-latent-prediction/
- License: This work is licensed under CC BY-NC-SA 4.0.