
世界模型:高效训练完整实验报告样例
这篇回答的问题。 如何理解“世界模型高效训练完整实验报告样例”背后的核心机制、适用边界和下一步阅读路径。
这页用仓库里的 world-model-mini-chain fixture 写成一份小型论文式实验报告。它的目标不是证明某个真实模型有效,而是给全站提供一个证据链模板:数据、训练配置、系统成本、闭环指标、失败归因和改进计划应该怎样放到同一页里。
摘要
任务是桌面机器人动作条件世界模型的最小评测:给定多相机历史、语言目标、本体状态和候选 action chunk,模型要预测不同动作下的未来风险和成功概率。当前 fixture 暴露两个关键问题:top1_safe_success_agreement=2/4 过低,说明候选动作排序会选错;action_sensitivity_pass=3/4 说明遮挡任务中动作分叉仍不稳。
| 报告项 | 内容 |
|---|---|
| 数据规模 | 4 条 episode,12 条候选 rollout |
| 成本瓶颈 | 多相机 token、候选动作排序、失败 replay |
| 主要指标 | compression ratio、action sensitivity、top-1 agreement、risk ECE |
| 结论 | 证据格式完整,但模型门禁不合格;需要补 hard negatives、risk calibration 和 action counterfactuals |
数据
数据位于 files/assets/examples/world-model-mini-chain/:
1 | episodes.jsonl |
episodes.jsonl 记录任务、相机 token、压缩 token、语言/本体/动作 token 和结果标签。4 条 episode 里有 2 条成功样本、2 条 hard negative:slip_after_fast_grasp 和 wrong_target_after_occlusion。
| episode | split | task | result | failure_type |
|---|---|---|---|---|
wm_mini_001 |
mini_eval | pick red mug and place on rack | success | none |
wm_mini_002 |
mini_eval | put sponge in drawer | success | none |
wm_mini_003 |
mini_hard_negative | lift glass near table edge | failure | slip_after_fast_grasp |
wm_mini_004 |
mini_hard_negative | pick occluded red mug | failure | wrong_target_after_occlusion |
训练配置
training-config.yaml 是 toy config,不是生产训练配方。它定义了 4 秒上下文、1.6 秒 rollout horizon、10Hz 控制频率、8-step delta end-effector pose + gripper action chunk,以及 action sensitivity、event head、risk head 等损失权重。
| 字段 | 当前设置 | 读法 |
|---|---|---|
context_seconds |
4.0 |
当前状态来自短历史,不覆盖长任务记忆 |
rollout_horizon_seconds |
1.6 |
只测短 horizon 动作后果 |
latent_dim |
1024 |
toy latent,不代表真实模型容量 |
attention |
block_causal |
需要保持 episode boundary 和动作时间戳 |
risk_ece_max |
0.15 |
小样本校准门禁,仅用于格式示范 |
系统账
运行:
1 | python3 files/assets/examples/world-model-mini-chain/eval_mini_chain.py |
当前输出:
| Metric | Value |
|---|---|
| episodes | 4 |
| raw_patch_tokens | 82368 |
| compressed_state_tokens | 12292 |
| compression_ratio | 6.70x |
| action_sensitivity_pass | 3/4 |
| top1_safe_success_agreement | 2/4 |
| risk_ece_3bin | 0.103 |
这个系统账说明视觉压缩有数量级收益,但也暴露出关键边界:token 省下来以后,候选动作排序仍然会错。世界模型评测不能只报告 compression ratio 或 token/s。
原图证据:报告应该怎么写机制
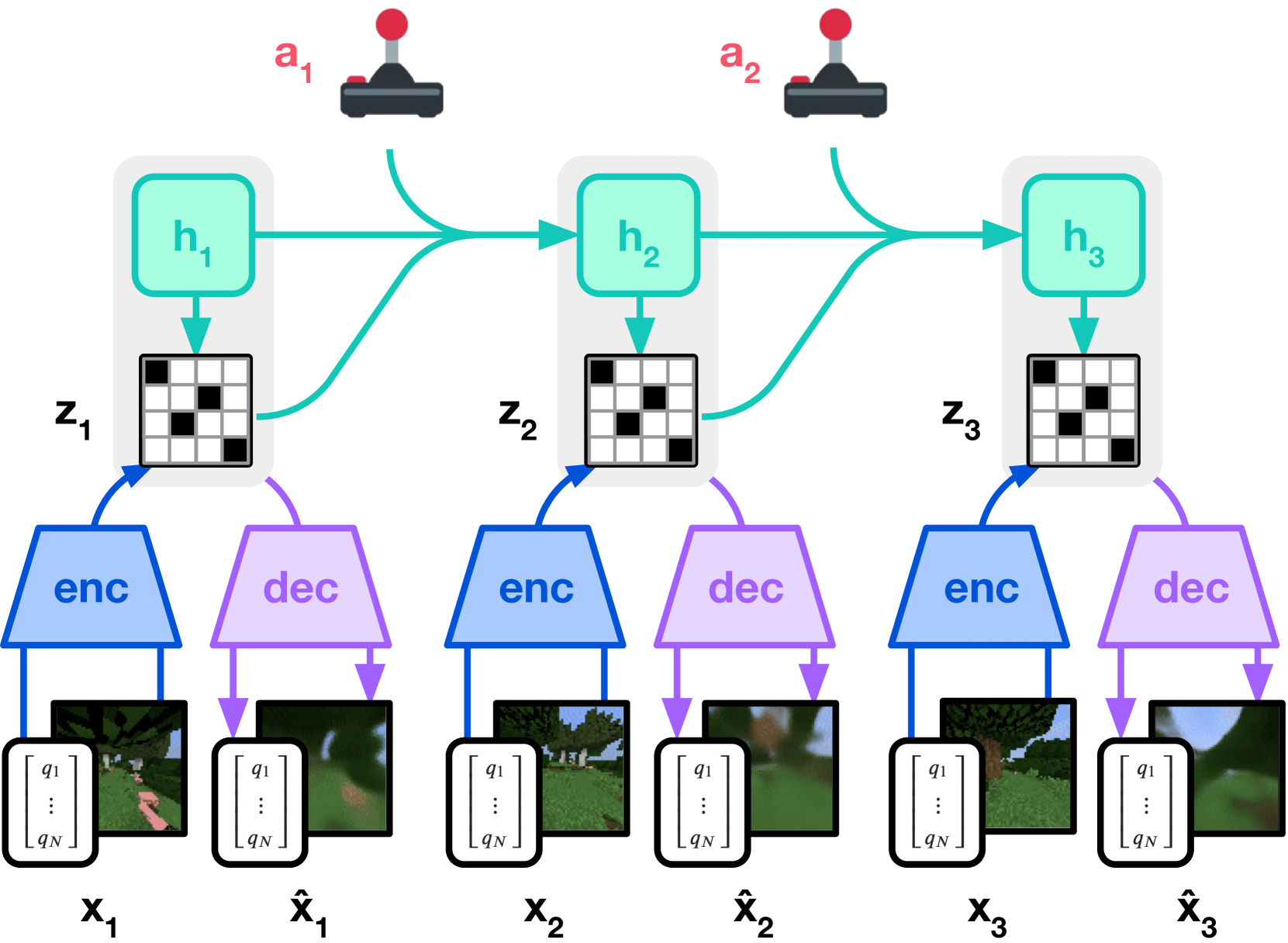
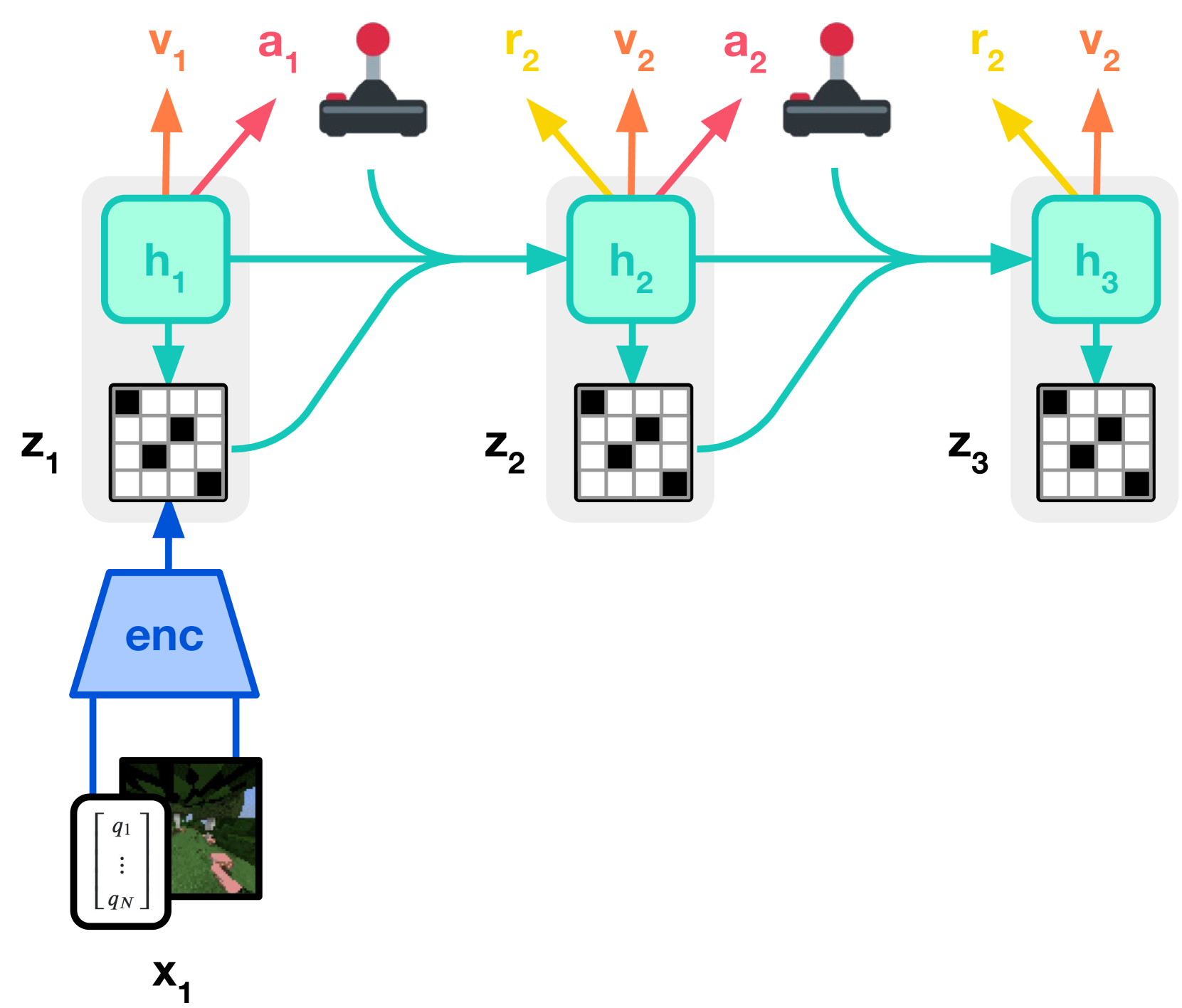
图源:DreamerV3: Mastering Diverse Domains through World Models,Figure 3(a)/(b)。原图意:Figure 3(a) 展示 world model learning,Figure 3(b) 展示 actor-critic 在 imagined latent trajectories 上学习。
DreamerV3 图先区分模型学习和策略学习。
Figure 3(a) 的输入是真实环境经验,输出是 latent state、reward 和 continuation 的预测模型;Figure 3(b) 的输入则是 world model 想象出来的 latent rollout,输出是 actor/critic 的动作和值函数更新。这里的效率机制不是“视频预测更清楚”,而是策略学习可以大量发生在 latent imagination 中,减少真实环境交互成本。
这对本实验报告有一个很硬的要求:报告必须分开写 world model 训练指标和 policy/planning 消费指标。只报 reconstruction、compression ratio 或 rollout loss,还不能说明模型能帮机器人选动作;必须继续报告候选动作排序、风险校准、closed-loop 成功率或至少 action-conditional counterfactual 评测。本页 toy fixture 只是在示范这种证据链,并没有证明真实控制收益。
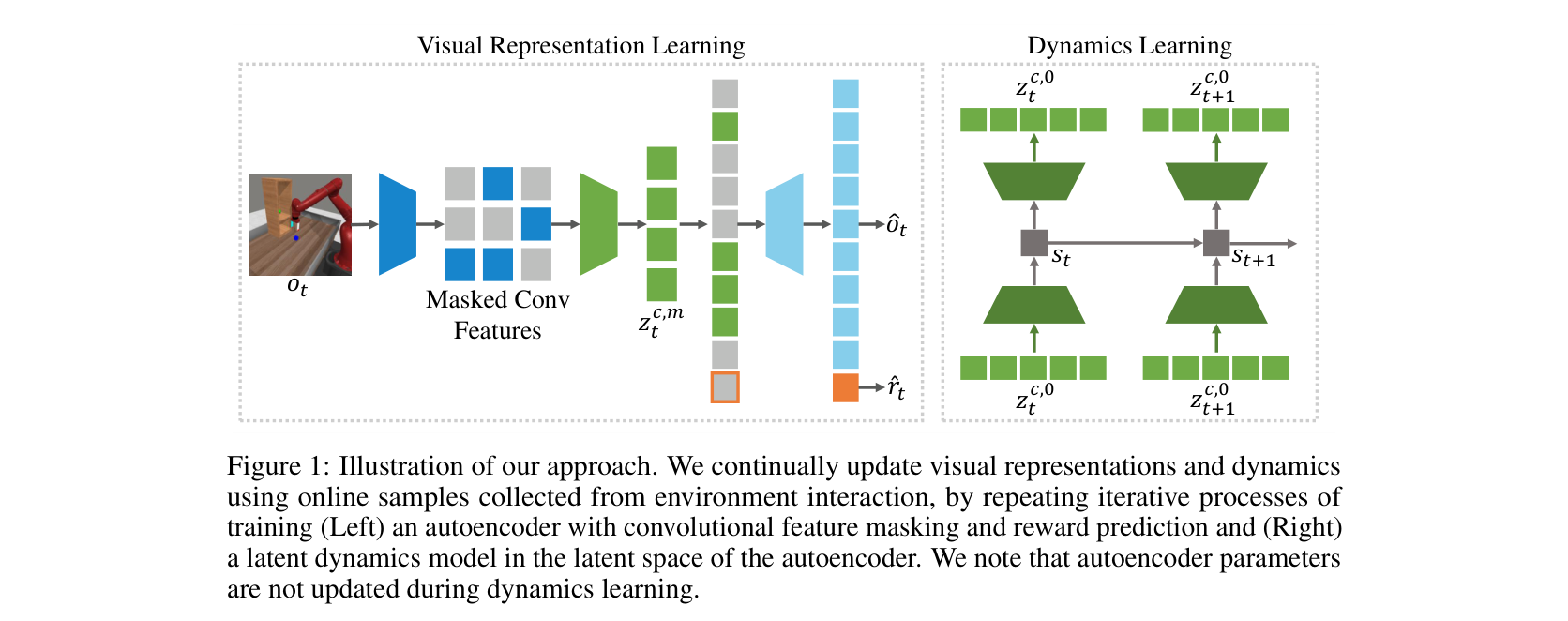
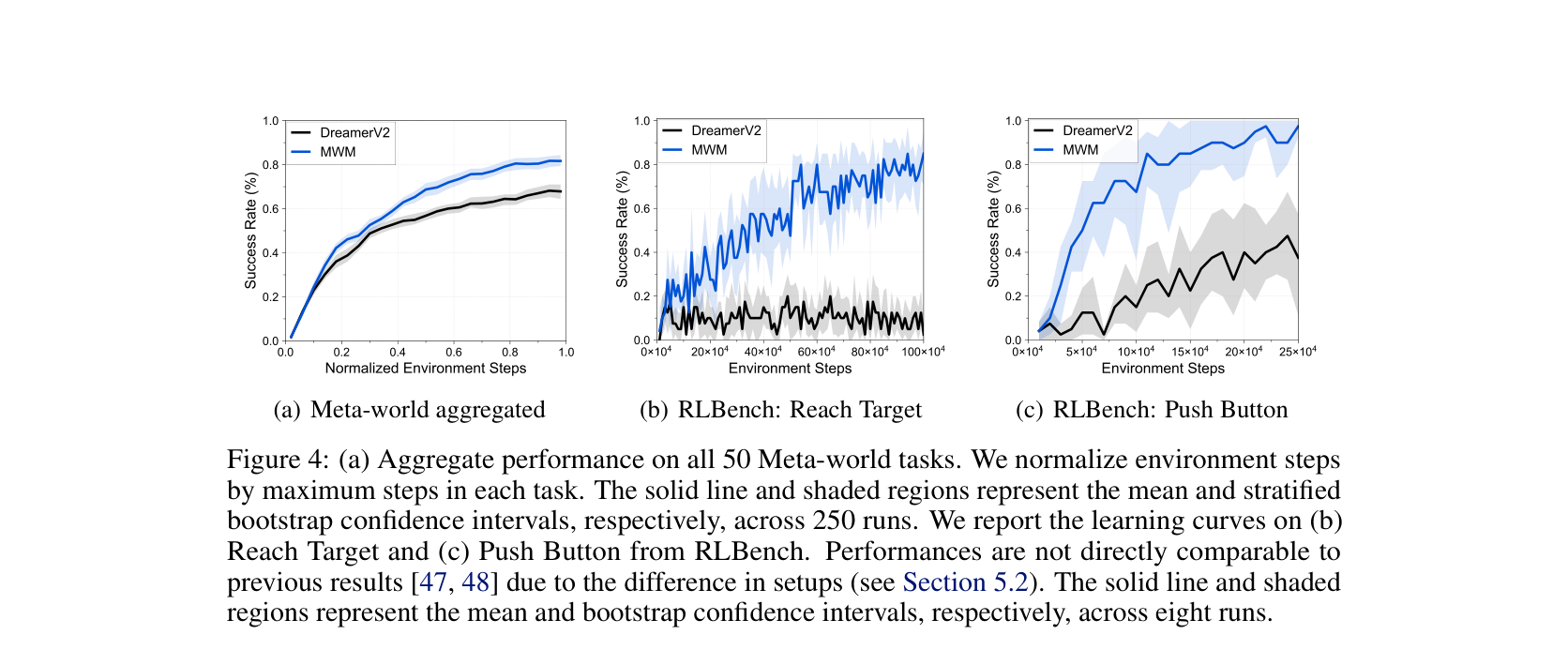
图源:Masked World Models for Visual Control,Figure 1 与 Figure 4。原图表达:Figure 1 展示 masked visual representation learning 与 latent dynamics learning 的解耦;Figure 4 展示 Meta-world / RLBench 设置中的 success rate 学习曲线。本站读法:这组图提醒实验报告要同时写表征学习和控制收益,不能只报视频或重建指标。
MWM 这组图补上了另一个视角:世界模型报告不能把 representation learning 和 dynamics learning 混在一起。masked visual representation 解决“状态怎么压缩得有语义”,latent dynamics 解决“动作以后状态怎么变”,success rate 曲线才说明这些中间学习有没有被控制任务消费。真实报告里如果只看到预训练 loss 下降,却没有任务曲线或动作反事实,证据链就断在中间。
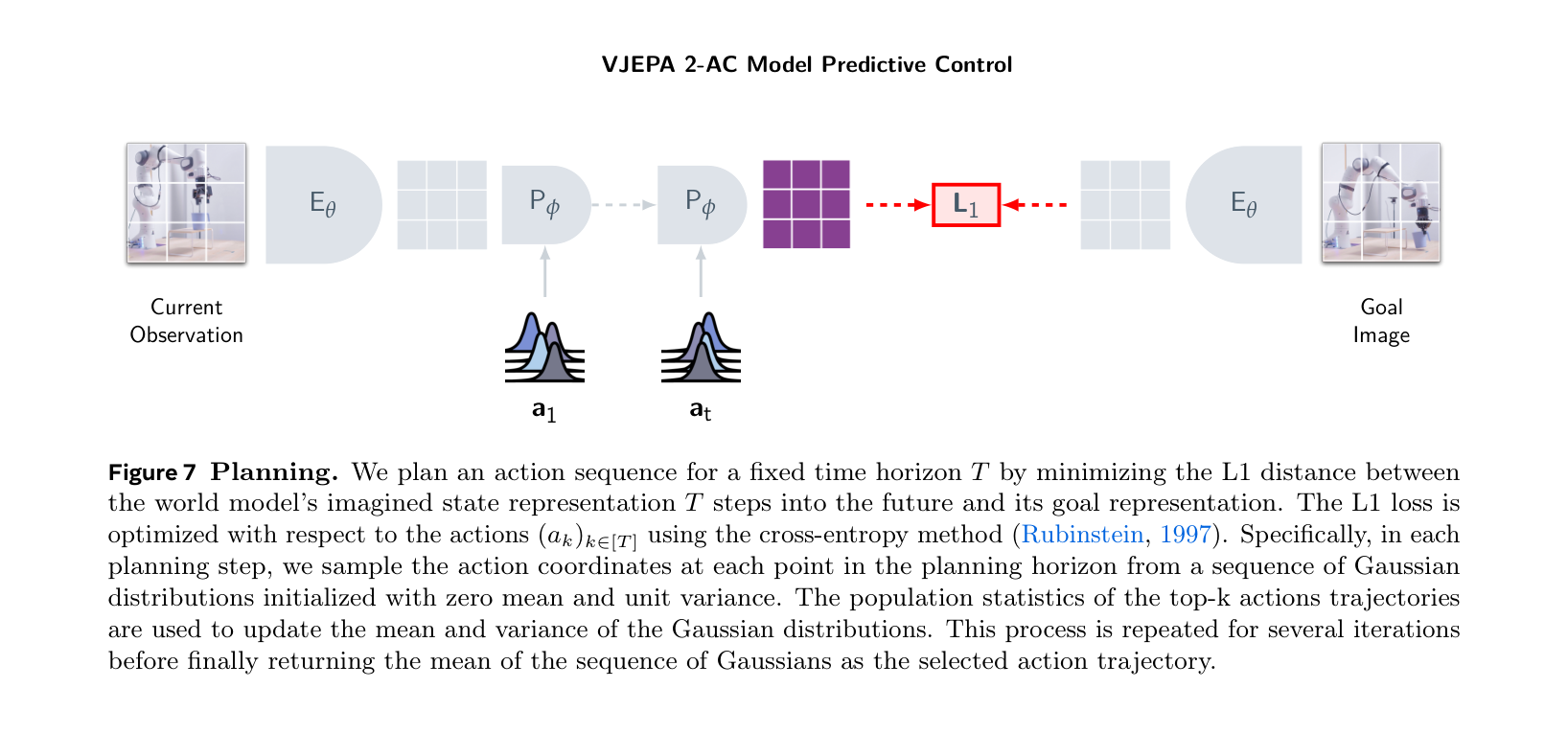

图源:V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning,Figure 7 与 Table 3。原图表达:Figure 7 展示用 V-JEPA 2-AC 做 model predictive control;Table 3 比较 V-JEPA 2-AC 与 Cosmos world model 在机器人操作任务中的规划性能与时间。本站读法:这组图用于区分“学到预测表征”和“能被规划器消费”,两者都要进实验报告。
V-JEPA 2-AC 的图和表适合用来提醒“规划接口”要写清楚。action-conditioned world model 不是只生成未来 latent,它还要能被 MPC 或候选动作搜索调用:输入候选 action sequence,预测未来表征或代价,再由规划器选动作。因此实验报告要写 planner 的候选数量、horizon、评分函数、耗时和失败模式;否则读者看不出提升来自世界模型本身、规划器预算,还是任务分布更简单。
评测
| 指标 | 当前值 | 解释 | 门禁判断 |
|---|---|---|---|
| compression ratio | 6.70x |
raw patch token 到 compressed state token 的压缩 | 格式可用,但需看状态是否保真 |
| action_sensitivity_pass | 3/4 |
固定历史下换动作,latent 是否有足够变化 | 不合格,遮挡任务仍需补 |
| top1_safe_success_agreement | 2/4 |
预测 top-1 安全成功动作是否真实成功 | 不合格,排序会选错 |
| risk_ece_3bin | 0.103 |
三桶风险校准误差 | 小样本下仅作格式示范 |
失败归因
| episode | top_candidate | predicted_risk | predicted_success | actual_event | 归因 |
|---|---|---|---|---|---|
wm_mini_003 |
fast_grasp |
0.20 | 0.80 | slip | 风险头低估快速抓取导致的滑落 |
wm_mini_004 |
grasp_visible_decoy |
0.16 | 0.76 | wrong_target | 遮挡后对象身份漂移,模型把可见干扰物当目标 |
失败归因比平均分更重要。risk_ece_3bin=0.103 看起来不糟,但 top-1 排序仍然会选错动作,说明校准指标必须按 hard-negative 桶拆开看。
改进计划
| 问题 | 下一步改进 | 验收 |
|---|---|---|
| 快速抓取滑落 | 增加 slip hard negatives、接触状态 probe、risk head 权重 | near-miss recall 提升,top-1 不选高风险动作 |
| 遮挡后 wrong target | 增加多相机 object permanence 标签和反事实动作 | occlusion bucket 的 action sensitivity 通过 |
| 排序不可靠 | 加 candidate ranking loss 或 pairwise preference eval | top1_safe_success_agreement 达到门禁 |
| 证据仍是 toy fixture | 替换为真实 checkpoint、固定 seed、真实 rollout 日志 | 报告升级为 Paper Result 或 Closed-loop |
读完以后怎么判断
本页给的是实验报告形状,不是模型胜利宣言。一个合格的世界模型高效训练报告,必须同时报告:省了什么成本、预测是否动作敏感、闭环或候选排序是否变好、失败是否能回放、证据等级和复现状态是什么。
最核心的知识点是:世界模型的“高效”必须穿过三层证据。第一层是表征和动态模型有没有学到可压缩、可预测的 latent;第二层是 action-conditioned rollout 是否真的改变候选动作排序;第三层是这些排序或规划是否带来 closed-loop 成功率、风险下降或更低真实交互成本。本页的 fixture 故意让 top1_safe_success_agreement=2/4 不合格,就是为了避免把完整报告格式误读成模型已经可用。
外部精读
- DreamerV3:重点看 world model learning 与 actor-critic learning 如何分工。
- Masked World Models for Visual Control:重点看 masked representation、latent dynamics 和控制 success rate 的证据链。
- V-JEPA 2:重点看 action-conditioned planning、MPC 接口和机器人任务表格。
- Meta V-JEPA 2 research page:适合核对官方对 understanding、prediction、planning 三阶段的解释。
相关阅读与下一步
- 外部材料:World Models 论文。
- 外部材料:DeepMind Genie 2。
- 外部材料:Meta V-JEPA 2。
- 站内下一步:世界模型专题。
- 站内下一步:RSSM、Dreamer 与规划。
- 站内下一步:世界模型评测与失效模式。
- Title: 世界模型:高效训练完整实验报告样例
- Author: Charles
- Created at : 2026-03-24 09:00:00
- Updated at : 2026-03-24 09:00:00
- Link: https://charles2530.github.io/2026/03/24/ai-files-world-models-world-model-efficient-training-experiment-report/
- License: This work is licensed under CC BY-NC-SA 4.0.