
VLM/VLA:动作分块、层级策略与潜在技能
VLA 若直接逐步输出低层动作,往往很快遇到两个问题:一是时序太长,语言到动作的因果链条难学;二是细粒度控制噪声大,模型容易把高层意图和低层执行搅在一起。动作分块(action chunking)、层级策略(hierarchical policies)和潜在技能(latent skills)正是为了解决这个问题。它们的共同目标,是让模型在时间上看得更远、在接口上更稳定。
VLA 不一定要每 20 毫秒都重新“思考人生”。动作分块让模型一次输出一小段动作,层级策略让高层决定目标或技能,低层负责具体控制,潜在技能则把常见动作片段变成可复用单元。
人做饭时不会每一毫米都重新规划,而是先决定“切菜”“开火”“翻炒”这些技能,再在执行时微调。VLA 的 action chunk 和 latent skill 也是为了把长任务拆成更可学、更可控的行为块。
1. 为什么逐步动作建模不够
设机器人控制频率为 10Hz 到 50Hz,一个简单家务任务就可能包含数百到数千个动作步。若策略直接学习
它需要同时解决:
- 当前细微位姿调整;
- 任务阶段判断;
- 长时目标跟踪;
- 失败恢复与重规划。
这会让学习问题高度纠缠。
2. 动作分块的基本思路
动作分块不是每步输出一个动作,而是一次输出未来 步动作块:
优点包括:
- 减少决策频次;
- 增强短时平滑性;
- 让高层意图覆盖更长时间窗;
- 更适合离线模仿长序列示范。
但缺点是灵活性下降,需要闭环重规划补偿。
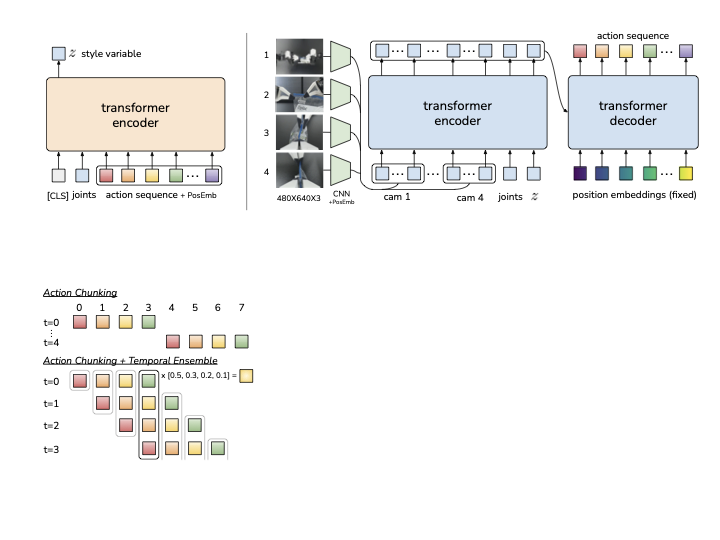
图源:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,Figure 2。原论文图意:Action Chunking with Transformers (ACT) 用 CVAE 编码动作序列和关节观测,测试时用多视角图像、关节状态和 latent 生成一段 action sequence,并配合 temporal ensembling。
ACT 图里的彩色小块就是连续动作序列。模型一次预测多个未来动作,而不是每个控制周期只吐一个点;执行时还会把多个时刻预测出的动作块做 temporal ensembling,减少抖动。对初学者来说,关键是分清:chunk 让策略在短时间内更连贯,但它不是开环到底,仍然需要重新观察、重新预测和安全层过滤。
3. Chunk size 的权衡
太小,和逐步动作差别不大; 太大,又容易在执行中偏离真实状态。一个理想的 应与技能时间尺度匹配。例如:
- 桌面抓取可用较短 chunk;
- 导航或接近阶段可用较长 chunk;
- 接触瞬间需要更细粒度控制。
这说明 chunk size 很可能应随任务阶段动态变化。
4. 层级策略的两个层面
典型层级策略可分为:
- 高层策略:产生子目标、技能标识或潜在代码;
- 低层策略:根据当前观测执行具体动作。
形式上可写成:
这里 可以是离散技能 ID、连续 latent,或子目标状态。
5. 潜在技能的意义
若没有明确人工定义技能,模型也可以从数据中学潜在技能表示。直观上,潜在技能把“抓起杯子”“调整对准把手”“把物体放入盒中”这类常重复出现的时序模式压缩成可组合单元。
这样做的价值是:
- 更容易重用行为片段;
- 更容易迁移到新任务;
- 高层规划可以在技能空间中思考,而不是每次从零规划微动作。
6. 技能学习的几种方式
6.1 基于分段标注
人工或规则把轨迹切成若干技能段,最可解释,但成本高。
6.2 基于时序压缩
用 VAE、离散 tokenizer 或 sequence model 把动作序列压缩成 latent code,再学习 code 到动作的解码器。
6.3 基于目标条件
直接把技能定义成“达到某个子目标状态”的策略,而非命名标签。
7. 潜在技能与语言对齐
对 VLA 来说,技能若能与语言片段对齐,就更有价值。例如用户指令“先打开抽屉,再把勺子放进去”,系统最好能把“打开抽屉”映射到一个稳定技能单元,而不是让所有动作细节都从语言 token 直接控制。
这意味着一个好的 VLA 常需要在语言-技能-动作三层之间建立桥梁。
8. 动作分块与闭环控制并不冲突
有人担心 action chunking 会让系统变开环。更合理的做法是:
- 每次生成 chunk;
- 执行其中前若干步;
- 重新观察并再规划。
可写成 receding horizon 形式:
这兼顾了长时视野和闭环修正。
9. 与世界模型的结合
高层技能空间通常比原始动作空间更适合做 imagined rollout。若世界模型能在技能层面预测未来,那么规划开销更低,也更贴近任务结构。这也是 VLA 与世界模型天然契合的一个接口。
10. 常见失效模式
10.1 Chunk 太长导致漂移
执行到一半环境已变,但系统还在按旧计划走。
10.2 技能边界不自然
学到的技能切分与任务逻辑不一致,导致高层很难组合。
10.3 低层执行器太弱
高层决策合理,但低层无法稳定完成技能。
10.4 语言与技能未对齐
模型能做出动作,但很难按自然语言分解任务步骤,影响可解释性和泛化。
11. 例子:开门取物
这个任务可自然拆成:
- 接近把手
- 对准与抓住
- 拉开门或抽屉
- 定位目标物
- 抓取目标
- 放到指定位置
如果策略逐步输出底层动作,它必须从头到尾在一个空间里协调;若有层级技能,则高层只需决定当前处于哪一段、下一段是什么,低层负责局部执行。
12. 例子:移动操作
在移动机器人取送任务中,导航、定位、拾取、避人和递交本质上是不同时间尺度的控制。统一平铺成原始动作序列虽理论上可行,但训练和部署都很困难。层级策略能把问题结构显式化。
13. 设计建议
- 对长时任务优先考虑动作分块或技能抽象,而不是纯逐步动作预测。
- 技能空间应兼顾可组合性和执行可实现性。
- Chunk 大小与闭环重规划频率要一起设计。
- 语言到技能的对齐通常比语言到原始动作更稳定。
- 评测时不仅看总成功率,还要看技能切换是否合理、恢复是否容易。
14. 小结
动作分块、层级策略与潜在技能,本质上是在给 VLA 增加时间结构和行为结构。它们帮助模型把“长任务”拆成可管理的行为单元,把“语言意图”映射到更稳定的控制接口,再通过闭环重规划把执行误差吸收掉。没有这层结构,VLA 往往很难在真实长时任务中保持稳定。
工程收束
动作分块不是把动作序列切短这么简单,而是决定错误在哪里暴露、由哪一层恢复、哪些状态需要传给下游控制器。验收时应按短、中、长任务分桶,把恢复场景单列,并比较 chunk 内外误差传播;否则 chunk 太大、层级接口不清和闭环恢复差,都可能被平均成功率掩盖。
- Title: VLM/VLA:动作分块、层级策略与潜在技能
- Author: Charles
- Created at : 2026-03-26 09:00:00
- Updated at : 2026-03-26 09:00:00
- Link: https://charles2530.github.io/2026/03/26/ai-files-vla-action-chunking-hierarchical-policies-and-latent-skills/
- License: This work is licensed under CC BY-NC-SA 4.0.