
VLM/VLA:评测与数据引擎
VLA 真正难的地方,不只是模型结构,而是数据非常贵、benchmark 很容易和真实部署脱节、离线成功不代表实机稳定。
因此 VLA 的 benchmark 和数据引擎必须放在一起看。它们之间不是“先有 benchmark,后有数据”,而是相互塑造:你如何评测,就会决定你收集什么样的数据;你回流什么数据,又会决定下一轮 benchmark 上哪些能力会被放大。
VLA benchmark 不能只看最终是否成功,还要看动作是否稳定、失败是否可恢复、是否靠运气、人工接管多少。评测标准会反过来决定团队收集什么数据。
只看“有没有落地”不够,还要看动作质量、稳定性、是否踩线、是否靠补救才站稳。VLA 任务也是这样,单次成功率会高估真实能力。
1. 为什么 VLA benchmark 比纯视觉 benchmark 更脆弱
因为同一个任务成功与否,往往不只是“最终结果对不对”,还取决于轨迹是否稳定、动作是否安全、是否靠运气成功、是否能从轻微偏差中恢复。
这意味着简单的成功率并不总够。
1.1 为什么“做成一次”不等于“真的会做”
机器人任务里存在大量偶然成功。例如夹爪姿态本来不对,但物体恰好被桌边卡住;或者放置偏了,但容器足够大,最终仍然被判成功。这类成功在离线表格上会被算 1 分,但对部署价值远低于稳定、可重复的成功。
因此 VLA benchmark 如果只统计单次成功率,往往会显著高估系统真实成熟度。
2. 常见 benchmark 维度
一个更完整的 VLA 评测至少应覆盖任务成功率、平均执行时长、失败类型分布、人工接管率和场景变化鲁棒性。
如果只给一个总成功率,很容易掩盖系统的脆弱点。
2.1 建议增加的两个核心指标
首次成功率:反映策略在不依赖恢复时的直接能力;最终成功率:反映含恢复链路时的真实完成能力。
二者一起看,才能判断模型是在“本来就会做”,还是“做错后还能救回来”。
2.2 长任务应单独统计阶段完成率
对“开抽屉取勺子再放到盒中”这类任务,最好分开记录接近目标、操作部件、识别目标物、抓取、放置或收尾各阶段是否成功。
否则只看终局结果,很难知道失败到底发生在哪一段。
3. 离线数据集的局限
很多 VLA 数据集来自示范轨迹:
它们很好用,但天然更偏成功轨迹,失败轨迹少,场景分布受限,机器人平台单一,标注语言粒度也不一致。
所以一个模型在离线 benchmark 上高分,并不自动意味着现实部署可用。
3.1 离线数据为什么尤其容易高估系统
因为它们常隐含了“人类已经把环境整理好”的前提:相机位姿固定、起始状态规整、物体集合有限、操作员知道正确动作,恢复和异常过程也被弱化。
模型因此更容易学出一种“实验室中的正确行为”,而不是现实中的鲁棒行为。
4. 为什么数据引擎是 VLA 的关键
现代机器人系统最终必须走向闭环数据流程:先用示范或仿真冷启动,再上线收集失败与长尾,经过筛选、标注和回灌后重训或继续微调。
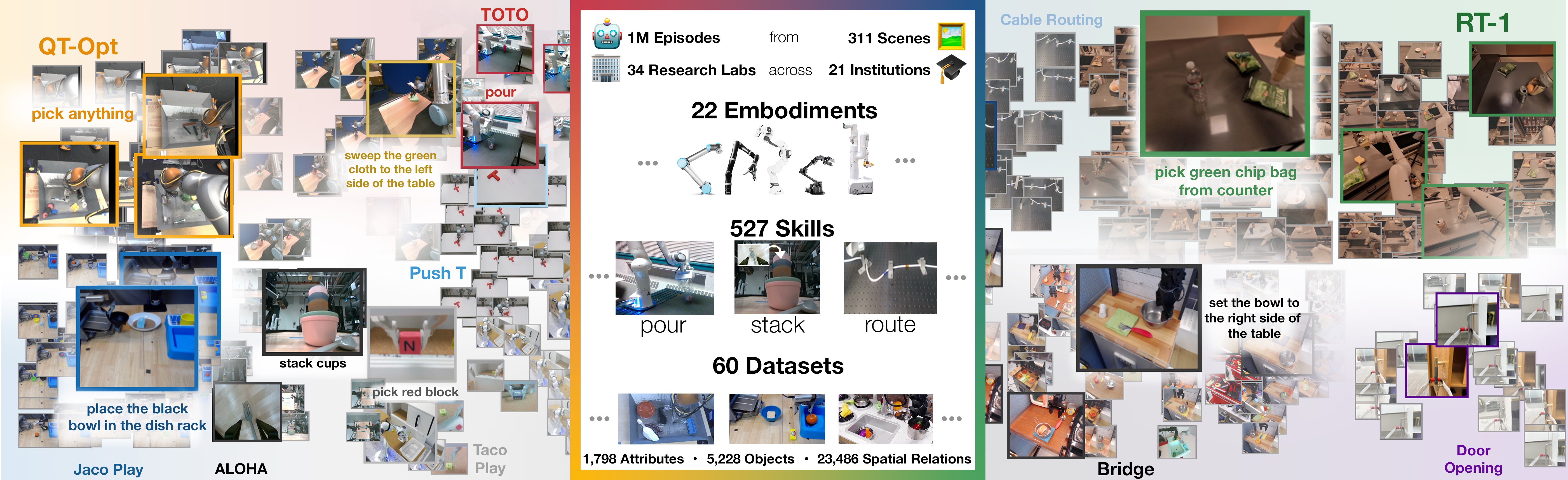
图源:Open X-Embodiment: Robotic Learning Datasets and RT-X Models,Figure 1。原论文图意:展示来自全球多家机构的开放大规模机器人学习数据集,覆盖不同机器人形态、环境和行为。
Open X-Embodiment 的图强调了数据多样性:不同机器人、不同场景、不同任务会产生完全不同的观测和动作分布。VLA 的评测如果只在单一平台、单一桌面、单一任务上做,很容易高估模型。数据引擎的作用就是持续把新 embodiment、新物体、新失败模式和 near-failure 样本回灌进训练与 hard set,让 benchmark 不再只是固定表格分数。
可写成:
其中 是本轮新回流样本。
4.1 数据引擎的作用不是“把日志存下来”
高质量数据引擎至少要回答四个问题:哪些样本最值得回流,它们应该进入训练集还是 hard set,它们属于哪类失败,下一轮如何验证这些样本确实带来了收益。
没有这几步,数据引擎很容易退化成日志仓库。
5. 哪些样本最值得回流
并不是所有实机日志都有同样价值。通常更值得优先回流的是任务失败、接近失败的边界样本、人工接管样本,以及新物体、新布局、新光照场景。
一个直观例子:透明包装抓取
如果系统 95% 的样本都是普通纸盒成功抓取,新增 1000 条同类日志的价值可能不高。反而那 30 条透明包装失败样本,更可能直接决定下一轮模型有没有明显提升。
5.1 near-failure 往往和失败一样值钱
比如机器人已经抓住目标,但抬升时轻微滑脱;或放置时姿态偏了一点但最终侥幸成功。这类样本特别适合训练恢复能力和边界控制。
6. Benchmark 为什么必须更新
如果 benchmark 永远固定在老场景,系统会越来越擅长“做 benchmark”,而不是真正变强。更稳健的方式是保留一套稳定主 benchmark,同时持续增加 hard set 和长尾集。
这样既能横向比较,又能逼模型面对真实进化中的难题。
6.1 不更新 benchmark 的代价
不更新意味着团队会逐渐把模型调到特别擅长固定场景,新物体、新环境和新失败类型永远不进入评测,线上真实退化也越来越难被离线指标捕捉。
这会形成一种非常危险的“表格持续变好,但现场没有变稳”的假象。
7. 三类 VLA benchmark
| Benchmark | 适合回答的问题 | 主要风险 |
|---|---|---|
| 仿真 benchmark | 快速迭代和大规模消融 | sim2real gap 大 |
| 实验室 benchmark | 中等成本、较稳定的版本比较 | 仍可能过于规整 |
| 真实部署 benchmark | 系统能不能在目标环境里工作 | 成本高、噪声大 |
实际项目里,这三类通常需要同时存在,而不是只选一种。
如果把三者混成一个总分,很多重要结论会被抹平。
8. 评测里最容易忽略的两件事
运气成功
机器人有时会“误打误撞做成”,但轨迹其实非常不稳。
恢复能力
很多系统一旦偏离示范分布就完全崩溃,缺少 recover from near-failure 的能力。
这两点如果不测,benchmark 会过度乐观。
8.1 还容易忽略的第三件事:环境耦合
很多系统对某个固定桌面、某个固定操作员、某个固定相机位置表现很好,但一换布局就掉点。如果 benchmark 不显式控制这些因素,就无法知道模型学到的是任务本身,还是环境偶然性。
9. 工程建议
若你在搭建 VLA 项目,建议把 benchmark 和数据引擎一起设计:稳定 benchmark 用于比较版本,hard set 专门盯长尾,失败样本回流链路负责制造下一轮训练资产,失败分类规范负责让问题可统计、可复盘。
9.1 再进一步的建议
如果资源允许,再加入任务阶段标签、首次成功 / 最终成功双指标、near-failure 标注、接管事件自动归档,以及每轮回流后的专项分桶复盘。
10. 一个具体例子:仓库拣选 VLA
假设你的主 benchmark 主要覆盖常见纸箱、固定货架高度、规则照明和单步抓取成功率,而真实场景最棘手的可能是透明塑封件、倾斜堆叠、反光遮挡、人工临时移动物体,以及抓起后转运过程中的滑移。
如果这些只存在于现场而不进入 hard set 和回流机制,那么离线成绩再好,也不说明系统真的成熟。
11. 一个总判断
VLA benchmark 的价值,不在于给出一个漂亮总分,而在于帮助你知道:系统到底在哪些边界内可靠、在哪些场景下脆弱、哪些失败值得优先采样回流。数据引擎则负责把这些判断持续转化成下一轮训练资产。只有两者真正接上,VLA 才会从“演示能动”变成“系统能进化”。
工程收束
VLA 评测不应只给一个总分,而要产出可回流的失败分布:哪些任务阶段脆弱、哪些场景条件触发失败、哪些错误值得优先采样。数据引擎的价值,就是把这些失败转成下一轮训练、回放和小规模闭环验证的资产。
- Title: VLM/VLA:评测与数据引擎
- Author: Charles
- Created at : 2026-03-31 09:00:00
- Updated at : 2026-03-31 09:00:00
- Link: https://charles2530.github.io/2026/03/31/ai-files-vla-benchmarks-and-data-engines/
- License: This work is licensed under CC BY-NC-SA 4.0.