
VLM/VLA:最小数学:理解、行动与预测后果
VLM/VLA 里的公式不应该被当成符号表背诵。它们大多在回答三件事:
1 | 看到了什么 -> 该做什么 -> 做了以后会怎样 |
读公式时先问四个问题:输入是什么,输出是什么,时间下标 表示哪一刻,模型是在回答“理解”“行动”还是“预测后果”。只要这四件事清楚,公式就不再是装饰。
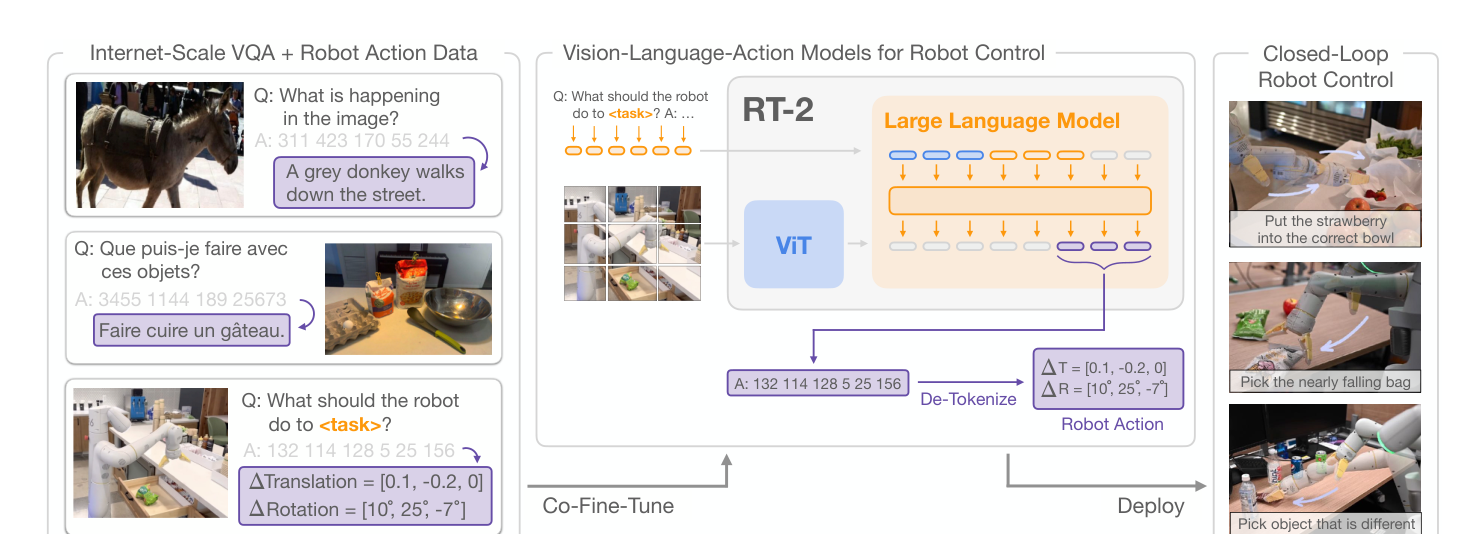
图源:RT-2 project page / 论文。原图表达视觉语言模型如何把网络知识和机器人动作 token 接起来;本站读法是把公式里的 、、、 对应到真实系统接口。它不能证明 VLA 一定能闭环完成任务,只说明“看图回答”和“输出动作”之间多了动作接口和环境反馈。
三类最常见公式
VLM:看图回答问题
这行表示:给定视觉输入 和文本输入 ,模型生成或选择输出 。比如输入是一张桌面图和问题“红杯在哪里”,输出是“红杯在桌边”。它不保证模型会移动机械臂,也不说明动作执行后世界会怎样变化;它只回答静态理解或语言输出问题。
VLA:从观察到动作
这行表示:策略根据到目前为止看到的观测 和语言目标 ,输出当前动作 的分布。观测到红杯靠近桌边,指令是“放到托盘上”,策略可能输出“夹爪向红杯移动并准备闭合”。但它只说动作从哪里来,不保证动作安全、平滑,也不保证动作之后一定成功。
世界模型:预测动作后果
这行表示:如果从状态 开始执行一段动作 ,模型预测未来 latent、收益 和是否结束 。如果快速从侧面推红杯,世界模型应该预测滑落风险上升;如果从上方夹取并慢速移动,风险更低。未来预测不是执行保证,真实系统仍要用控制器、安全层和重新观测来纠错。
视觉 token 的最小数学
一张图像常写成:
把图像切成 patch 后:
图像越大、patch 越小,token 越多。若图像是 ,patch 是 ,则 。如果是 16 帧、4 路相机,就变成 个视觉 token,训练成本会迅速上升。
这里的 是图像高度,世界模型里的 是预测 horizon。很多论文都用 ,读教程时最好在脑子里把它们分开。
训练数据、损失和分布
数据集
其中 表示第 条示范在时刻 的观测, 表示语言指令, 表示对应动作, 表示示范数量。这一行是在说:VLA 数据不是普通图文对,而是带时间、动作和机器人状态的轨迹样本。
行为克隆损失
这行表示:专家在某个观测和语言条件下做了动作 ,训练就让模型也更倾向于输出这个动作。示范数据里专家从上方夹红杯,行为克隆就让模型在类似观测下也学会从上方接近。它的局限也很直接:行为克隆只模仿数据中出现过的动作。部署时模型一旦走偏,后续观测可能不再像训练集,错误会越滚越大。
高斯策略和 MSE
这行公式的第 1 个位置 是“这次专家动作/候选动作有多可能”,第 2 个位置 是模型认为最典型的动作,第 3 个位置 描述动作维度的尺度和相关性。
如果固定协方差,最大似然常会变成类似 MSE 的回归:
表示把所有时间步的误差加起来; 是数据里的专家动作, 是模型预测动作; 是平方距离。
常见误解:MSE 小不等于机器人一定成功。若同一场景有“从左绕”和“从右绕”两种合理动作,MSE 可能学到两者中间的平均轨迹,反而不可执行。
观测、状态和 latent 的区别
| 名称 | 常用符号 | 初学者理解 | 例子 |
|---|---|---|---|
| 观测 | 传感器当前看到的东西 | 当前 RGB、深度、关节角 | |
| 真实状态 | 足以预测未来的完整世界信息 | 杯子真实位置、速度、摩擦、是否已被夹住 | |
| latent 状态 | 模型内部压缩出来的状态 | 视觉 encoder 或世界模型记忆里的向量 | |
| 文本/语言 | 问题、类别文本或任务指令 | “把红杯放到托盘上” |
真实机器人通常看不到完整 ,只能从 推断。VLA 和世界模型都在努力把历史观测压成一个足够有用的 。
动作符号怎么读
| 形式 | 公式 | 含义 | 风险 |
|---|---|---|---|
| 单步动作 | 当前一步动作 | 高频决策可能抖 | |
| 动作序列 | 从 到 的动作 | horizon 长时成本高 | |
| action chunk | 一次预测未来一小段动作 | chunk 内出错时恢复慢 | |
| 离散 token | 把连续动作分桶成 token | 量化误差和边界抖动 | |
| 连续动作 | 末端位姿增量和夹爪控制 | 单位、坐标系和频率必须统一 |
读公式的安全检查
读 VLM/VLA 论文时,看到一个公式就用下面四句检查:
- 这是在看懂当前输入,还是在输出动作,还是在预测动作后果?
- 时间下标 指的是观测时刻、动作时刻,还是预测未来时刻?
- 公式里的变量是原始数据、模型内部 latent,还是控制器真正会执行的命令?
- 训练目标优化的指标,能不能代表闭环成功和安全?
如果这四句答不清,先不要急着比较模型强弱。VLM/VLA 最常见的阅读陷阱,就是把“静态理解分数”“离线动作误差”和“真实闭环成功率”混在一起。
相关阅读与下一步
- 外部材料:CLIP 论文。
- 外部材料:LLaVA 论文。
- 外部材料:Flamingo 论文。
- 站内下一步:VLM 专题。
- 站内下一步:视觉 Tokenizer 与连接器。
- 站内下一步:多模态评测与失败模式。
- Title: VLM/VLA:最小数学:理解、行动与预测后果
- Author: Charles
- Created at : 2026-04-05 09:00:00
- Updated at : 2026-04-05 09:00:00
- Link: https://charles2530.github.io/2026/04/05/ai-files-vlm-vlm-vla-symbols-and-minimal-math/
- License: This work is licensed under CC BY-NC-SA 4.0.