
基础知识:模型压缩、剪枝与 NAS:先问省的是哪张账
这篇回答的问题。 如何理解“模型压缩、剪枝与 NAS”背后的核心机制、适用边界和下一步阅读路径。
很多模型压缩项目的第一版都会遇到一个尴尬结果:参数量少了,模型文件小了,论文表里的 MACs 也降了,但线上请求并没有明显变快,P99 甚至更差。原因通常不是“压缩没用”,而是压缩方法改的是一张账,真实系统卡的是另一张账。
这页按高质量技术博客常用的讲法展开:先固定一个具体困惑,再把方法放回数据流和硬件路径里看。模型压缩不是“把模型变小”的同义词,而是在质量、成本和可部署结构之间重新设计模型。
把压缩目标写成成本账
假设原模型是 ,压缩后的模型是 。我们希望 的任务质量足够接近 ,同时降低某个真实成本:
这里 表示任务损失, 表示你真正想压低的成本, 表示质量和成本之间的取舍权重。这个式子不重要在求解形式,而重要在提醒你:如果 写成参数量,搜索会偏向小模型;如果 写成 A100 上 batch=1 的 P99 latency,结果可能完全不同;如果 写成手机 NPU 的能耗和内存峰值,又会得到第三种设计。
模型压缩常见方法其实在改不同账:
| 方法 | 主要改哪里 | 常见收益 | 最容易错读 |
|---|---|---|---|
| 蒸馏 | 学生模型的训练信号和行为 | 小模型质量、数据效率 | student 可能继承 teacher 偏差 |
| 量化 | 权重、activation、KV 的数值格式 | 显存、带宽、部分 kernel latency | 没有 kernel 支持时只是文件小 |
| 剪枝 | weight、channel、head、block、layer | 参数、MACs、dense shape 或稀疏路径 | 稀疏率不等于加速率 |
| NAS | 搜索结构、宽度、深度、block 组合 | 平台特定 accuracy/latency trade-off | proxy 指标不等于真实端到端 |
| Runtime / kernel | 编译、融合、layout、batch、cache | P50/P99、throughput、能耗 | 离开目标 shape/hardware 就失效 |
好文章会在开头就问清楚“省的是哪张账”。这比先列一堆方法名更有用,因为压缩失败通常不是方法名选错,而是成本账写错。
参数、MACs、latency 不是同一个东西
读压缩论文时,先把三个最常混用的指标拆开:
| 指标 | 它测什么 | 不能证明什么 |
|---|---|---|
| Params | 权重数量或权重存储 | 不证明每次推理都触达这些权重,也不证明请求更快 |
| MACs / FLOPs | 某个输入 shape 下的乘加量 | 不包含 HBM 读写、layout transform、dequant、launch、同步 |
| Latency | 指定硬件和 runtime 上的真实时间 | 不具备跨硬件、跨 batch、跨 shape 自动外推性 |
MACs 降了但 latency 不降,常见原因很具体:shape 变碎导致 Tensor Core 吃不满,非结构化稀疏走不到硬件稀疏路径,dequant 或 gather/scatter 抵消了算力节省,layout transform 变多,batch 太小导致 launch overhead 占主导,或者服务瓶颈本来在 KV cache、memory bandwidth、queue wait,而不是乘加。
所以更可靠的压缩证据不是“参数少了 50%”,而是同硬件、同 batch、同输入分布、同 runtime 下的端到端延迟、P95/P99、内存峰值、功耗或成本 per successful request。模型越接近上线,越应该把 metric 从“模型形状”挪到“系统行为”。
Deep Compression 的启发:先看存储和带宽
Deep Compression 的经典路线是 pruning、trained quantization、Huffman coding 三段式。它很适合建立第一层直觉:早期压缩并不只是为了少算 FLOPs,很多时候是为了让模型权重从昂贵的 off-chip memory 移到更近、更便宜的存储层,或者减少带宽压力。
这条思路到今天仍然成立,但要补上新的系统边界。LLM/VLM/扩散模型里,权重只是成本的一部分;activation、KV cache、optimizer state、routing buffer、scale metadata、temporary workspace 也会占资源。权重文件变小,如果 decode 阶段卡在 KV 读取,用户体验未必改善;INT4 权重如果没有 fused dequant GEMM,可能省了显存却多了 kernel 和搬运。
因此,压缩页不能只讲“更小”,要讲“更接近哪条硬件路径”。能被 Tensor Core、Sparse Tensor Core、TensorRT、cuSPARSELt、移动端 NPU 或图编译器真正消费的压缩,才更可能变成真实加速。
剪枝:先分清稀疏模式和结构变化
剪枝的直觉是删掉贡献小的东西,再通过继续训练恢复质量。但“删掉”可以发生在很多粒度:
| 剪枝粒度 | 删除对象 | 部署含义 |
|---|---|---|
| Unstructured pruning | 单个 weight | 稀疏率高,但普通 dense GEMM 不会自动变快 |
| Semi-structured pruning | 固定模式,例如 2:4 | 如果硬件和库支持,可以换到稀疏 Tensor Core 路径 |
| Structured pruning | channel、filter、head、block | 改变 dense tensor shape,更容易转成真实加速 |
| Layer / block dropping | 整层或整块 | 路径长度变短,但质量恢复更难 |
Lottery Ticket Hypothesis 说明大网络中可能存在更小的可训练子网络,这对理解冗余很有启发。但它不是部署结论。它不能保证任意稀疏 mask 都能让你的 GPU 更快,也不能替代 runtime、kernel 和质量恢复实验。
NVIDIA Ampere/Hopper 的 2:4 structured sparsity 是另一个好例子。它要求每 4 个连续权重里至少 2 个为零,模式比任意稀疏更受约束,但正因为模式固定,硬件可以存非零值和少量 metadata,并让 Sparse Tensor Core 处理。部署世界经常如此:自由度少一点,硬件收益反而更真实。
结构化剪枝要先画依赖图
结构化剪枝比单个 weight pruning 更接近真实加速,因为它会改变 dense tensor shape。但它也更容易剪坏接口。剪掉卷积的第 17 个输出通道,后续消费这个特征图的层也要同步删除对应输入通道;剪掉 attention head,Q/K/V 和 output projection 通常要成组处理;剪掉 recurrent state 的一部分,下一步状态更新也要跟着改。
| 结构 | 为什么不能局部乱剪 |
|---|---|
| residual add | 两条分支输出 channel 必须一致 |
| concat | 后续层输入 channel 要按拼接结果重算 |
| attention head | Q/K/V 和 output projection 通常按 head 成组 |
| recurrent state | 的通道会被下一步 消费 |
| fixed output head | 类别数、mask 通道、disparity 输出格式不能改 |
DepGraph 这类工作强调 dependency graph,就是因为结构化剪枝必须先找出哪些参数是一个不可分割的组。否则剪枝代码可能直接 shape 报错;更糟的是 shape 不报错,但语义已经错了。
Fast-FoundationStereo 的 refinement pruning 图很适合作为部署型剪枝案例。
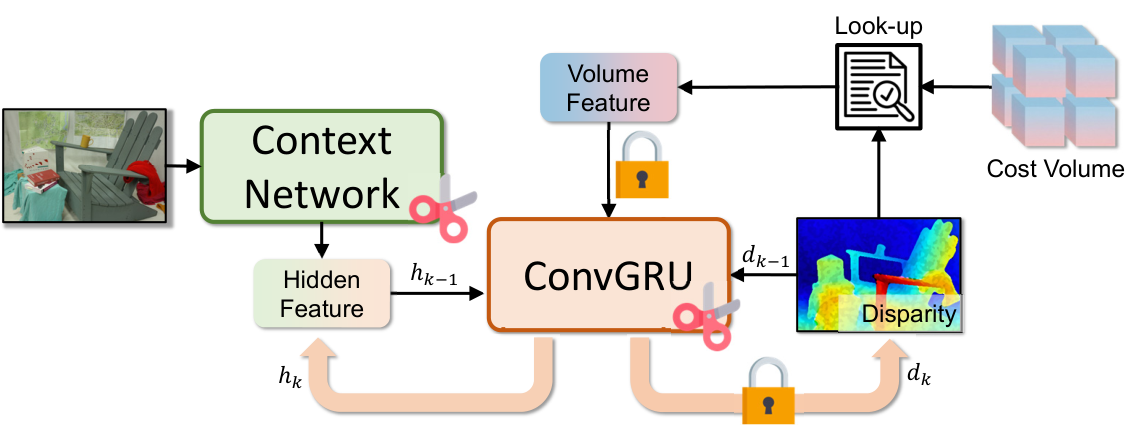
图源:Fast-FoundationStereo,Figure 5。原图表达 refinement module 里的 ConvGRU 存在 recurrent dependency,剪枝时要区分可剪通道、固定通道和依赖关系。本站使用这张图说明:结构化剪枝不是简单按通道重要性排序,还要保证迭代模块前后接口一致。
图里最关键的是 recurrent dependency。ConvGRU 会反复更新 hidden state,上一轮输出的 hidden channel 下一轮还要继续用。若只按某一层局部重要性剪掉通道,后续迭代可能接口不一致。真正可部署的剪枝流程通常是:构建依赖图,按组评估重要性,剪掉结构组,短期恢复训练,再测真实 runtime。
Taylor 重要性是排队工具,不是最后证据
剪枝需要估计“删谁伤害最小”。一种常见方法是一阶 Taylor 近似。对参数 ,可以写成:
这里 表示删掉第 个参数后损失可能增加多少, 是训练样本上 loss 对该参数的梯度, 是参数值本身。直觉是:参数越大、loss 对它越敏感,删掉越危险。
但这个分数只是局部一阶近似。剪掉一组 channel 后,其他参数会重新适应;剪枝后的质量常常取决于 retraining、蒸馏、学习率和数据分布,而不是剪完那一刻的 loss。结构化剪枝里还要把单个参数分数聚合成 channel、head、block 或 dependency group 分数,再和真实 latency 一起看。
NAS 搜索的是结构空间,不是魔法模型
NAS 的核心不是“自动发现通用最优架构”,而是在给定搜索空间和预算下选择结构组合。搜索空间可以包含 depth、width、kernel size、expansion ratio、attention head、block 类型、输入分辨率等;目标可以包含准确率、延迟、能耗或内存峰值。
一个平台感知 NAS 目标可以写成:
这里 表示候选架构, 表示搜索空间, 表示验证集质量, 表示在目标硬件 上测到或预测的延迟, 是延迟预算。MnasNet 的关键就在于把移动端真实 latency 放进目标,而不是只用 FLOPs proxy。
Once-for-All 的思路则是先训练一个 supernet,再从里面抽出适配不同设备和预算的 subnet。它的价值是降低“每个设备重新训练一个网络”的成本;边界是 supernet 训练、progressive shrinking、子网采样、校准和最终微调本身也会带来复杂度。
Blockwise NAS:把全局搜索拆成局部候选
Fast-FoundationStereo 的 cost filtering 阶段直接结构剪枝收益有限,于是论文改用 blockwise NAS:每个 block 提供多个候选结构,先让候选 block 局部蒸馏 teacher block,再测候选替换后的误差变化和耗时变化,最后用 ILP 选组合。
可以把选择问题写成:
这里 表示第几个 block, 表示该 block 的候选结构, 表示选择候选 后的误差变化, 表示耗时变化, 是 0/1 决策变量, 是总 latency 预算。读作:在总耗时约束内,为每个 block 选一个候选,让误差增加尽量小。
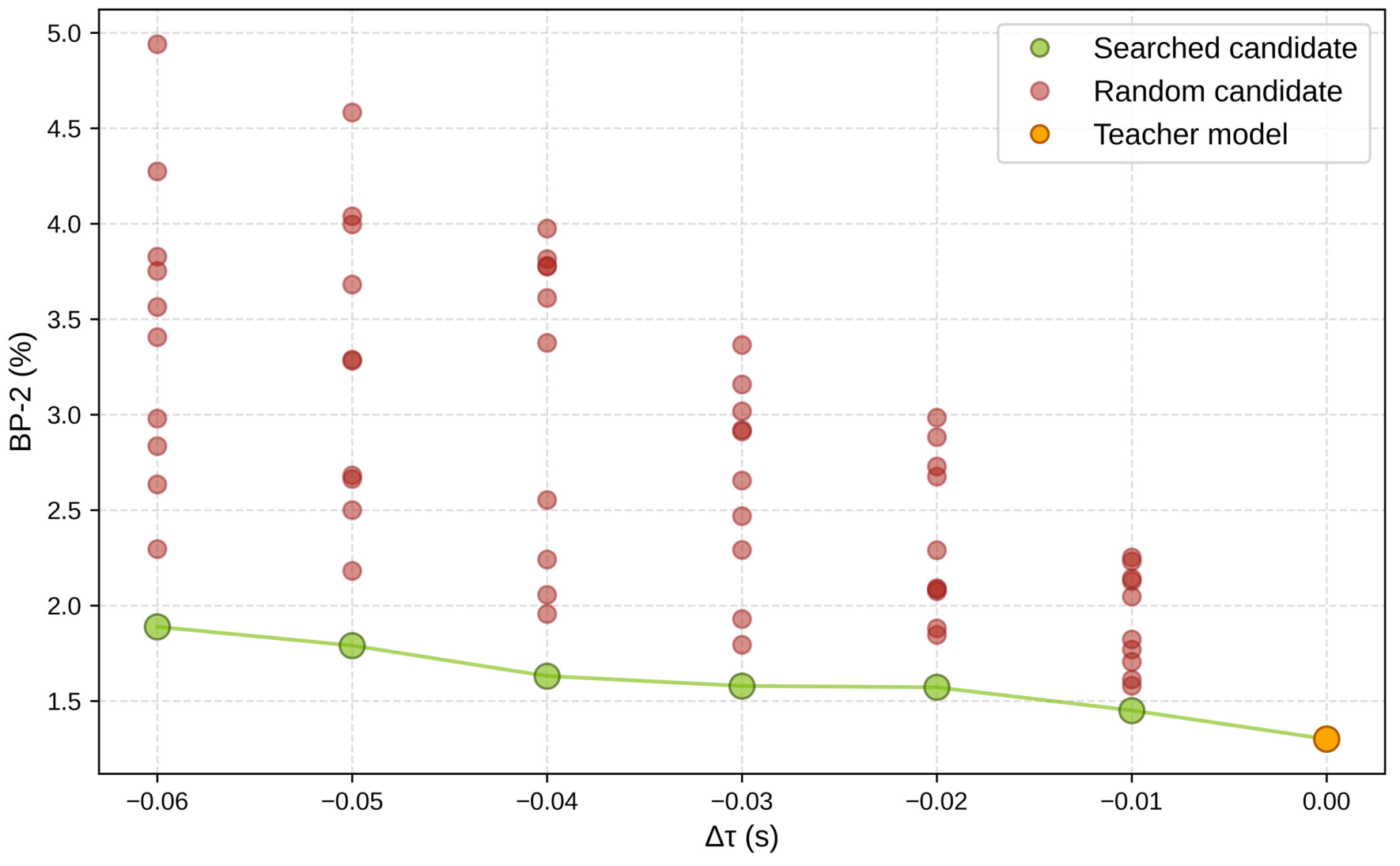
图源:Fast-FoundationStereo,Figure 8。原图比较不同 latency budget 下 searched candidate 和 random candidate 的精度/速度。本站使用这张图说明:NAS 的价值不是搜索空间听起来很大,而是在明确预算下找到比随机选择更好的结构组合。
这类 blockwise proxy 有代价:局部误差不一定完全可加,候选之间可能有交互,最终仍要端到端 retrain 和评测。但它给了一个清晰工程模式:先把昂贵的全局搜索拆成局部候选,再用可解释的成本约束组合。
系统里常常要混用多种压缩
真实高效模型很少只靠一种技术。Fast-FoundationStereo 的总体框架很典型:不同瓶颈对应不同工具。
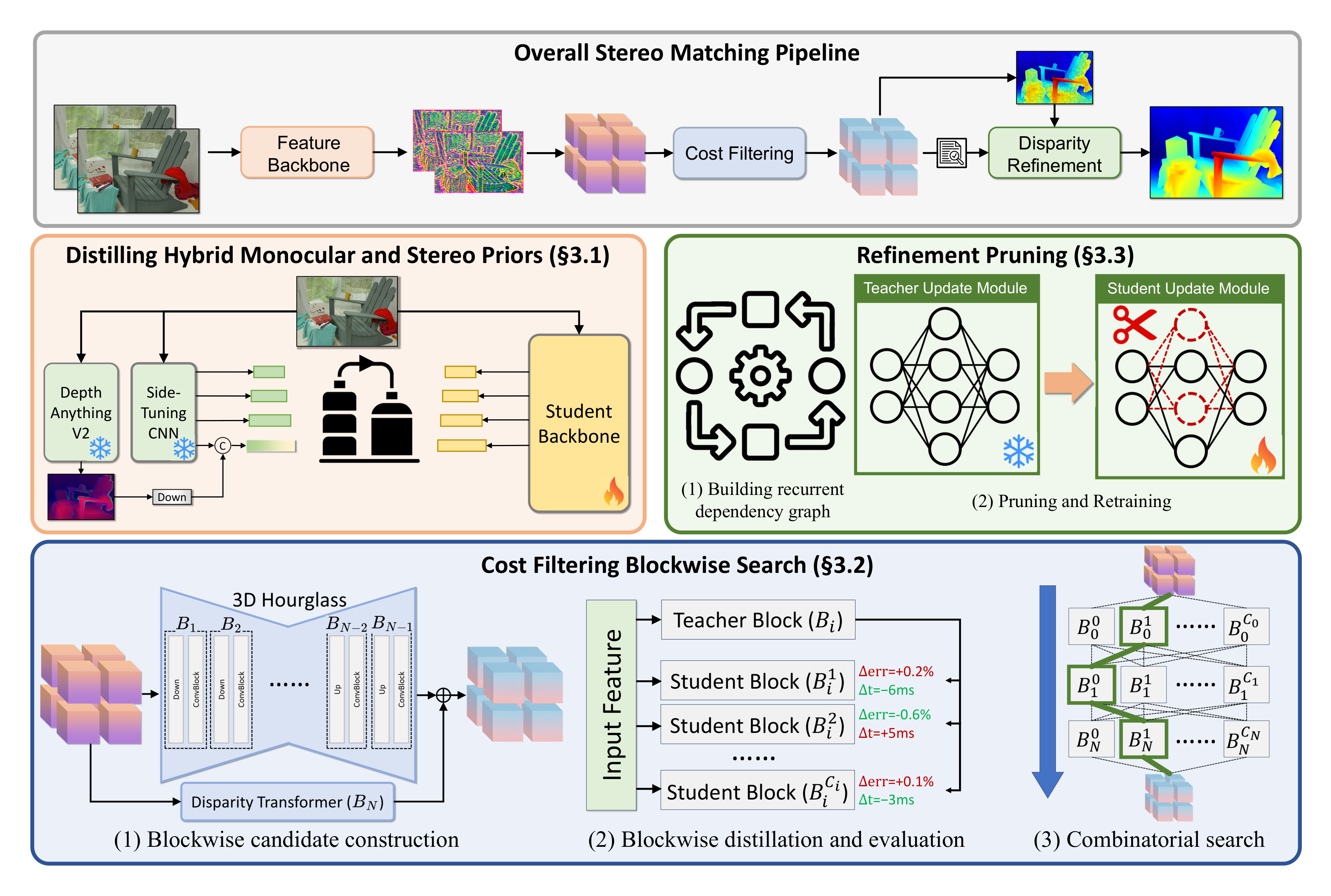
图源:Fast-FoundationStereo,Figure 3。原图表达 FoundationStereo pipeline 包含 feature extraction、cost filtering 和 disparity refinement,论文分别用 backbone distillation、cost filtering blockwise search、refinement pruning 加速。本站使用这张图说明:部署型压缩要先做瓶颈拆解,再为每段选择不同方法。
这张图的读法是先找热路径,而不是先找“用了什么算法”。Feature backbone 重,适合用 distillation 换成轻量 student;cost filtering 的结构空间复杂,但直接剪枝收益有限,适合 blockwise NAS;refinement 是反复迭代模块,有结构冗余,适合 dependency-aware structured pruning;最后再接 TensorRT/runtime 验证。它的核心经验是:压缩策略应该跟瓶颈形态匹配,而不是拿同一种方法扫全模型。
压缩上线前的六个门禁
压缩前先写清目标资源。如果目标是移动端安装包,Deep Compression 式存储压缩、权重量化和编码很重要;如果目标是 LLM decode TPOT,KV cache、attention kernel、batching 和 speculative decoding 可能比剪枝更关键;如果目标是机器人实时感知,端到端 P99、输入分辨率、TensorRT 支持和失败场景更关键。
| 门禁 | 要问的问题 | 为什么 |
|---|---|---|
| 瓶颈 | 是权重、activation、KV、算力、带宽、P99 还是能耗? | 不同瓶颈对应不同压缩方法 |
| 口径 | 硬件、batch、shape、runtime、精度格式是否固定? | 防止 benchmark 漂移 |
| 方法 | 量化、蒸馏、剪枝、NAS、kernel 哪个正中瓶颈? | 避免为了压缩而压缩 |
| 恢复 | 是否需要 retrain、KD、QAT、校准或继续训练? | 压缩后质量通常要恢复 |
| Trace | 是否报告模块分解、P50/P99、throughput、内存峰值? | 局部快不等于整体快 |
| 失败桶 | OOD、长尾、小目标、透明材质、长上下文是否掉点? | 压缩常先伤难例 |
压缩评审最好把“省下什么、损失什么、哪些请求会变慢”写在同一张表里。只看平均精度和平均 latency,会把长尾任务、冷启动、fallback、稀有 shape 和安全边界藏起来。
容易踩坑的判断
| 看起来合理的说法 | 更准确的说法 |
|---|---|
| 参数少就一定快 | 只有当计算、带宽或 runtime 热路径真的减少,才会快 |
| 稀疏率高就一定加速 | 稀疏模式必须被硬件、kernel 和 runtime 支持 |
| 剪枝就是按重要性排序删除 | 结构化剪枝还要满足 dependency graph |
| NAS 找到的是通用最优架构 | 它通常只在某个搜索空间、数据、硬件和预算下最优 |
| MACs 是最公平指标 | MACs 方便比较,但不能替代真实 latency 和能耗 |
| 压缩只影响平均精度 | 长尾、OOD、校准、安全边界和失败模式常先被压坏 |
最后判断
模型压缩的核心不是“把模型变小”,而是“把模型变成目标平台愿意执行的形态”。剪枝要看结构依赖,量化要看数值分布和 kernel,NAS 要看搜索空间和真实 latency,蒸馏要看 teacher 信号和 student 容量,runtime 要看端到端热路径。
读任何压缩、剪枝或 NAS 论文时,先画三件事:原模型的热路径,压缩方法改动的位置,目标硬件实际省下的成本。只要这三件事没对齐,参数表再漂亮也可能只是纸面压缩。
外部精读
- Deep Compression:理解 pruning、trained quantization、Huffman coding 如何共同降低存储和带宽。
- The Lottery Ticket Hypothesis:理解稀疏子网络和剪枝现象,但不要把它直接等同于部署加速。
- DepGraph: Towards Any Structural Pruning:理解 dependency graph 为什么是结构化剪枝的核心。
- NVIDIA Structured Sparsity:理解 2:4 稀疏为什么要匹配硬件和 TensorRT / cuSPARSELt 路径。
- MnasNet:理解平台感知 NAS 为什么要把真实 latency 放进目标。
- Once-for-All:理解 supernet 和多设备子网选择。
- PyTorch Pruning Tutorial:看工程上 mask、parameter reparameterization 和 pruning API 如何落地。
- PyTorch Semi-Structured Sparsity:对照 2:4 sparse training 的工程边界。
- Fast-FoundationStereo:看蒸馏、blockwise NAS、结构化剪枝如何在同一个实时感知系统里配合。
相关阅读与下一步
- 外部材料:The Illustrated Transformer。
- 外部材料:Dive into Deep Learning。
- 外部材料:Distill Circuits。
- 站内下一步:基础概念专题。
- 站内下一步:Transformer 输入与注意力。
- 站内下一步:数值、内存与运行时基础。
- Title: 基础知识:模型压缩、剪枝与 NAS:先问省的是哪张账
- Author: Charles
- Created at : 2026-04-27 09:00:00
- Updated at : 2026-04-27 09:00:00
- Link: https://charles2530.github.io/2026/04/27/ai-files-foundations-model-compression-pruning-and-nas-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.