
世界模型:Rollout 服务、量化与 Kernel 全链路案例
这页把世界模型 rollout 从“模型能预测未来”推进到“系统能以可接受成本服务规划器”。它串起视频/world-model rollout、KV cache、低比特、MagiAttention、KVSlimmer、CausVid、SLO 和失败回放,重点回答:怎样证明系统成本下降没有把动作分叉、风险判断和闭环收益一起压坏。
本页复用论文原图和站内 toy fixture 组织工程路线。系统吞吐、视频生成质量和 KV 压缩都不能直接证明世界模型更会规划;规划收益必须用 action sensitivity、closed-loop success、risk calibration 和 failure replay 单独验收。
10 分钟版
| 瓶颈 | 首选路线 | 必须补的评测 |
|---|---|---|
| 视频 rollout 太慢 | CausVid / DMD 少步化、causal student、KV cache | 视频质量、动作因果、长时 drift |
| 长上下文 KV 太大 | GQA、KV cache 压缩、KVSlimmer、低比特 KV | top-k action ranking、risk recall、current-window 保护 |
| 训练长视频通信慢 | MagiAttention、AttnSlice、mask-aware dispatch | step time、负载均衡、dynamics quality |
| 显存带宽不足 | SmoothQuant、FP8/INT8、混合精度、敏感头保护 | task bucket、long-horizon consistency、安全头回归 |
| 服务延迟不稳 | batching、prefill/decode 分离、SLO、fallback | P95/P99、cost per success、失败回放 |
| Checked Date | Official Source | Repro Status | Notes |
|---|---|---|---|
| 2026-05-16 | SmoothQuant / MagiAttention docs / CausVid / KVSlimmer | Site Inference | 本页是跨论文与官方系统材料的 rollout 服务案例;各 claim 以局部 Evidence Snapshot 为准,不写成统一复现。 |
Evidence Snapshot
| Claim | Direct Source | Figure/Table/Setting | Evidence Type | Repro Status | Can Support | Cannot Prove |
|---|---|---|---|---|---|---|
| 模型规模增长使显存/带宽成为量化动机 | SmoothQuant | Figure 1 | Paper Result | Paper Only | 量化首先是部署边界和带宽问题 | 不能证明某个 bitwidth 在世界模型上质量无损 |
| 异构 mask 长上下文需要 mask-aware attention 调度 | MagiAttention docs | Figure 1/3/4/6/9, official benchmark | System Throughput | Author Code / Official Repo | 异构 mask、AttnSlice、dispatch 和 overlap 能降低系统成本 | 不证明 dynamics 更准确或闭环成功率更高 |
| KV cache 可以用非对称合并降低推理成本 | KVSlimmer | Figure 1/4/5/6 | System Throughput | Author Code / Official Repo | 长上下文 decoder latency 和 KV memory 有压缩路线 | 不证明动作分叉和风险判断不受损 |
| 视频扩散可被改造成少步 causal streaming rollout | CausVid | Figure 1/5, latency setting | Paper Result | Author Code / Official Repo | 双向 teacher 到 causal student 是实时视频 rollout 路线 | 不证明 action-conditioned planning utility |
| mini-chain 可展示系统压缩后必须回归的任务指标 | 完整实验报告样例 | eval_mini_chain.py |
Toy Fixture | Toy Fixture | 说明压缩后要验 action sensitivity、risk ECE、failure replay | 不是生产服务或真实模型复现 |
链路一:量化先回答部署边界
量化不只是“模型文件变小”。对 rollout 服务来说,它决定同一块 GPU 能同时保留多少历史、多少候选动作、多少并发请求,以及是否能在规划器等待窗口内返回结果。
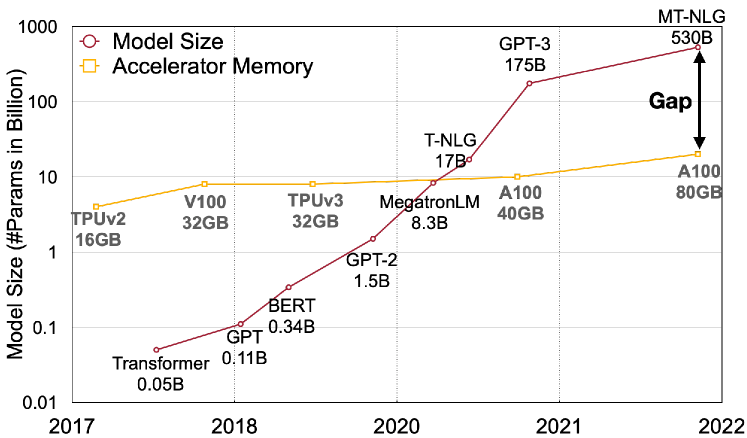
图源:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,Figure 1。原图意:模型规模增长速度明显快于单卡 GPU 显存增长速度,量化要解决的是模型越来越难装进有限显存和带宽预算的问题。
输入输出:输入是不断增长的模型规模和有限 GPU 显存,输出是必须采用量化、分片或服务栈优化的部署压力。
效率机制:低比特减少权重、activation 或 KV 的 bytes,缓解 HBM 容量和带宽瓶颈。
对主线意义:世界模型 rollout 常常比单次回答更吃上下文和候选动作,量化必须纳入 cost per success。
不能证明什么:SmoothQuant 的动机图不能证明 VLA 动作头、risk head 或视频 latent 在低比特下无损。
链路二:长视频训练不是单 kernel 问题
世界模型训练经常出现多相机、不同 episode 长度、局部 causal mask、memory token 和 action chunk。此时 full attention / causal attention 的简单 kernel 视角不够,需要把 mask、dispatch、通信和 overlap 放到同一张账。
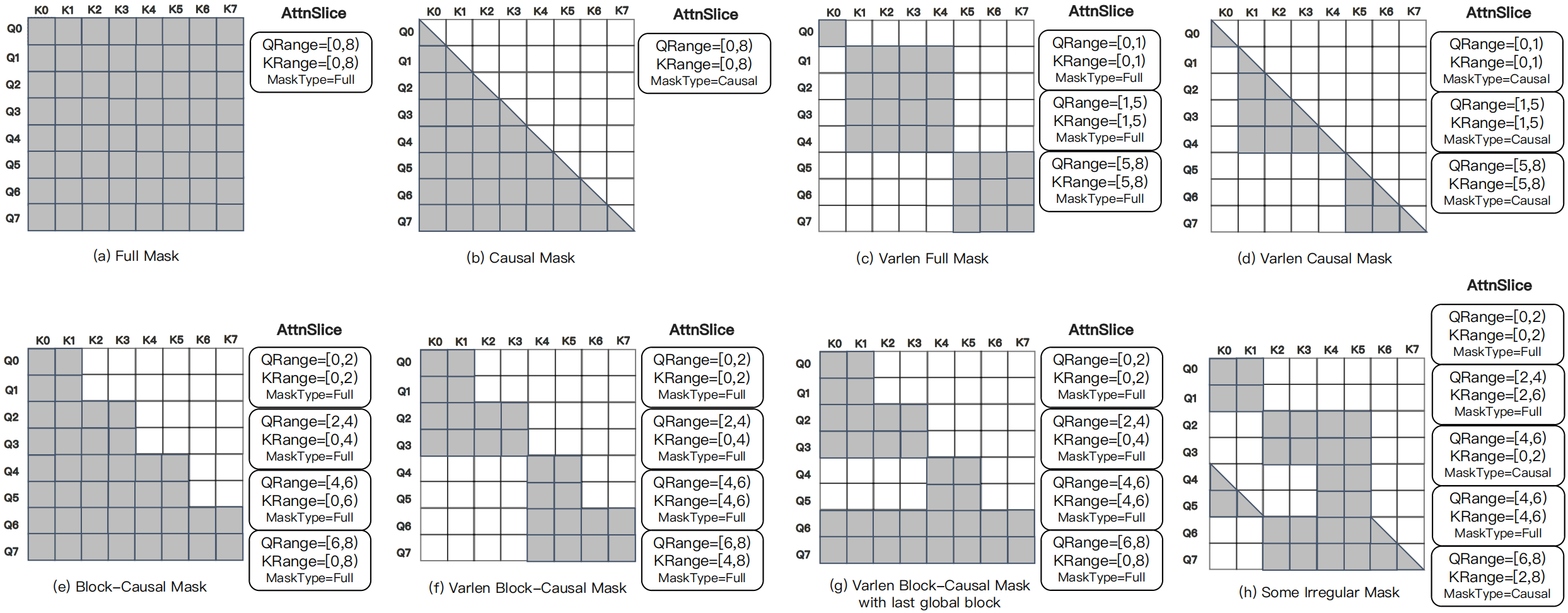
图源:MagiAttention 官方文档 / 博客,Figure 4。原图意:展示 full、causal、block-causal、heterogeneous 等不同 attention mask pattern,说明长上下文训练中的有效 attention 区域可能高度不均匀。
输入输出:输入是全局序列和复杂 mask,输出是不同 rank / slice 上实际需要计算的 attention 区域。
效率机制:按有效 mask area 而不是 token 数调度,减少空算、负载不均和冗余通信。
对主线意义:世界模型轨迹 packing 必须保留 episode boundary、action timestamp 和 causal/block mask。
不能证明什么:mask 调度更快不证明 world model dynamics 更准,也不证明闭环策略更安全。
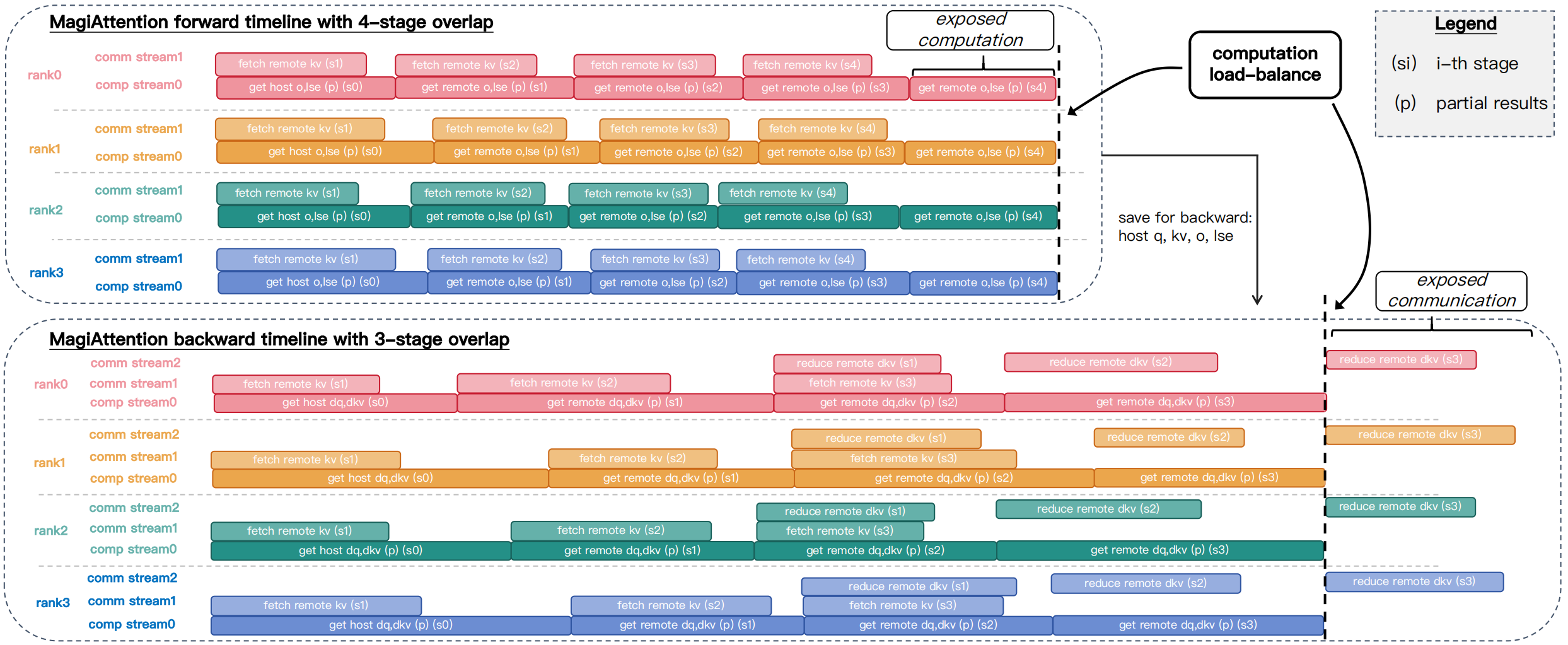
图源:MagiAttention 官方文档 / 博客,Figure 9。原图意:展示多阶段通信与计算 overlap 如何降低 context parallel 训练中的等待时间。
输入输出:输入是 attention slice 的计算和跨 rank 通信任务,输出是被 overlap solver 重新排布后的时间线。
效率机制:把通信隐藏到计算后面,减少长上下文训练 step time。
对主线意义:世界模型训练报告不能只写 kernel speedup,要写端到端 step time、通信占比和 checkpoint I/O。
不能证明什么:overlap 时间线不能证明模型质量、动作分叉或风险校准有改善。
链路三:KV 压缩要保护动作分叉帧
长历史 rollout 的 KV cache 可能比权重更早成为瓶颈。KVSlimmer 说明 KV 合并可以更细:Key 和 Value 不应被当成同一种对象压缩;但世界模型还要额外保护当前窗口、接触帧、动作切换帧和失败 replay。
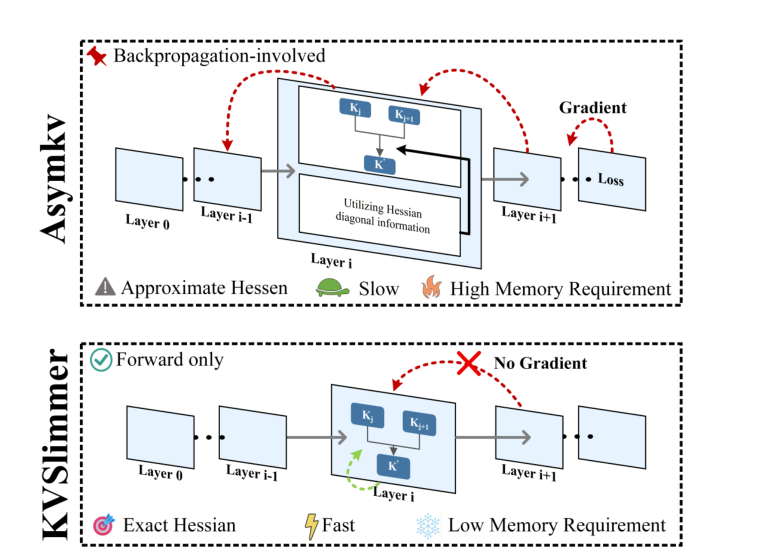
图源:KVSlimmer: Theoretical Insights and Practical Optimizations for Asymmetric KV Merging,Figure 1。原图意:AsymKV 依赖反向传播和近似 Hessian;KVSlimmer 用 forward-only 变量构造 Key 合并权重,避免 gradient 路径。
输入输出:输入是长上下文推理时积累的 K/V cache,输出是压缩后的 Key 与保留/处理后的 Value。
效率机制:利用 K/V 非对称性减少 cache memory 和 decoder latency,同时避免 backprop 额外开销。
对主线意义:world model rollout 可以考虑压远期 memory KV,但要保护动作分叉和风险关键帧。
不能证明什么:文本长上下文质量保持不能证明机器人动作候选排序和 risk recall 不变。
KVSlimmer 的结果主要是长上下文文本任务和系统效率;用于世界模型时必须补 action sensitivity、top-k candidate agreement、risk ECE 和 failure replay。
链路四:流式视频不等于可规划世界模型
CausVid 提供了把高质量双向视频模型蒸馏成 causal streaming student 的路线。它对交互式世界模型很有启发,但如果没有动作条件、reward/risk head 和 closed-loop eval,它仍然只是低延迟视频 rollout 模块。
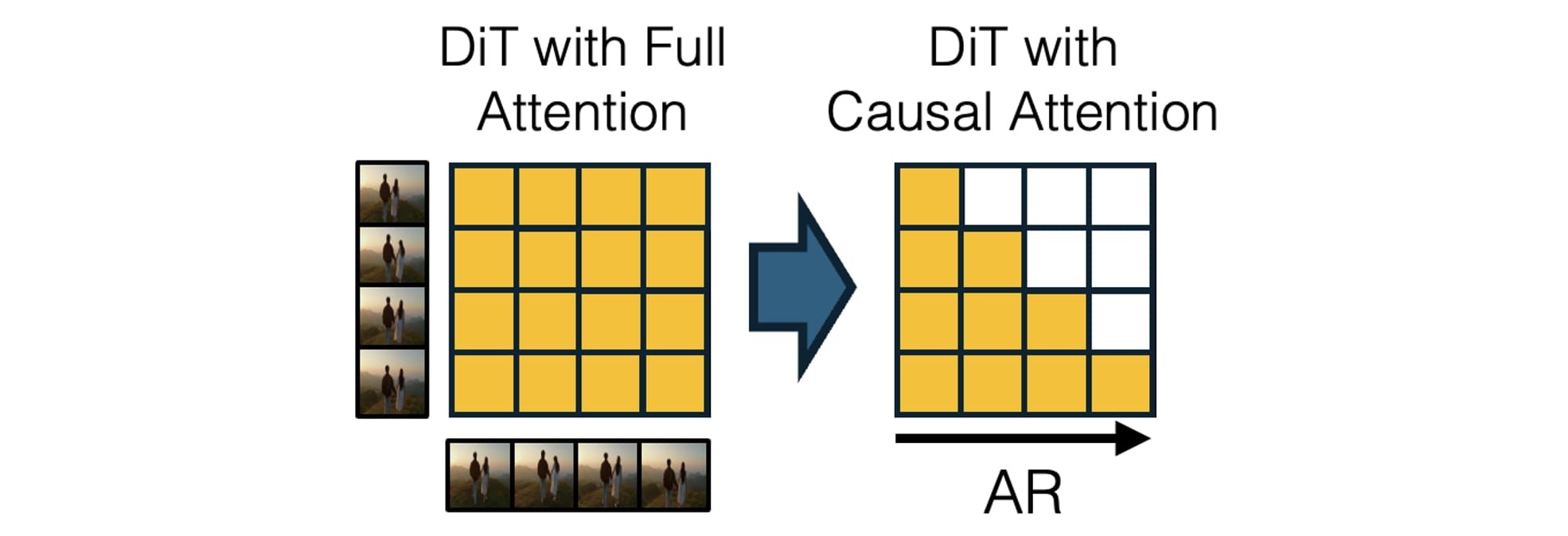
图源:From Slow Bidirectional to Fast Autoregressive Video Diffusion Models,CausVid 机制图。原图意:将强 bidirectional video diffusion teacher 迁移/蒸馏为 causal autoregressive student,用少步生成和 KV cache 支持流式视频 rollout。
输入输出:输入是历史 chunk 和当前条件,输出是 causal student 逐 chunk 生成的未来视频。
效率机制:双向 teacher 保质量,causal student 保流式依赖,DMD 少步化降低首块延迟和持续 rollout 成本。
对主线意义:世界模型服务需要边生成边决策,不能每次等待完整视频离线生成。
不能证明什么:流式视频质量和 FPS 不能证明动作因果、规划收益或真实机器人闭环成功。
CausVid 的强证据是视频生成质量、少步化和延迟;它不是动作条件控制论文。若接到 VLA,必须额外报告动作反事实、risk head、closed-loop success 和恢复失败样本。
上线验收表
| 验收项 | 最低要求 | 不合格信号 |
|---|---|---|
| 系统成本 | P50/P95/P99 latency、tokens/s、GPU memory、KV GiB、cost per rollout | 只给 kernel speedup,没有端到端 trace |
| 动作质量 | top-k candidate agreement、action sensitivity、closed-loop gain | 压缩后候选动作排序频繁翻转 |
| 风险质量 | risk ECE、near-miss recall、false negative replay | 低比特或 KV 压缩后漏报危险 |
| 视觉/latent 一致性 | long-horizon drift、chunk boundary、object persistence | 视频顺滑但状态错、接触帧丢失 |
| 回退路径 | 高精敏感头、保护当前窗口、fallback runtime | 出错时只能整体关量化或重启服务 |
结论写法
更稳的结论不是“量化和 KV 压缩让世界模型更好”,而是:
在指定硬件、runtime、context、batch 和候选动作数下,某条系统路线降低了 rollout 成本;同时 action sensitivity、risk calibration、candidate ranking 和 failure replay 没有超过预设退化门槛。若只满足前半句,它只是系统优化候选,不是闭环世界模型改进。
- Title: 世界模型:Rollout 服务、量化与 Kernel 全链路案例
- Author: Charles
- Created at : 2026-05-03 09:00:00
- Updated at : 2026-05-03 09:00:00
- Link: https://charles2530.github.io/2026/05/03/ai-files-world-models-rollout-serving-quantization-kernel-case/
- License: This work is licensed under CC BY-NC-SA 4.0.