
ML-paper-GPTQ
GPTQ
**核心问题:**如何对大型生成式预训练变换器(如 GPT 或 OPT)进行高效的量化,以减少计算和存储成本,同时保持模型性能。
核心方法(贡献):
- GPTQ: 提出了一种新的一次性权重量化方法,基于近似二阶信息,能够在几小时内量化具有 1750 亿参数的 GPT 模型,并将权重的位宽降低到每个权重 3 或 4 位,几乎不会降低相对于未压缩基线的准确性。
- 量化精度: GPTQ 能够在极端量化情况下(如 2 位或三元量化)仍提供合理的准确性。
- 执行效率: 开发了执行框架,使得压缩后的模型能够在单个 GPU 上进行生成式推理,显著提高了推理速度。
实验效果:
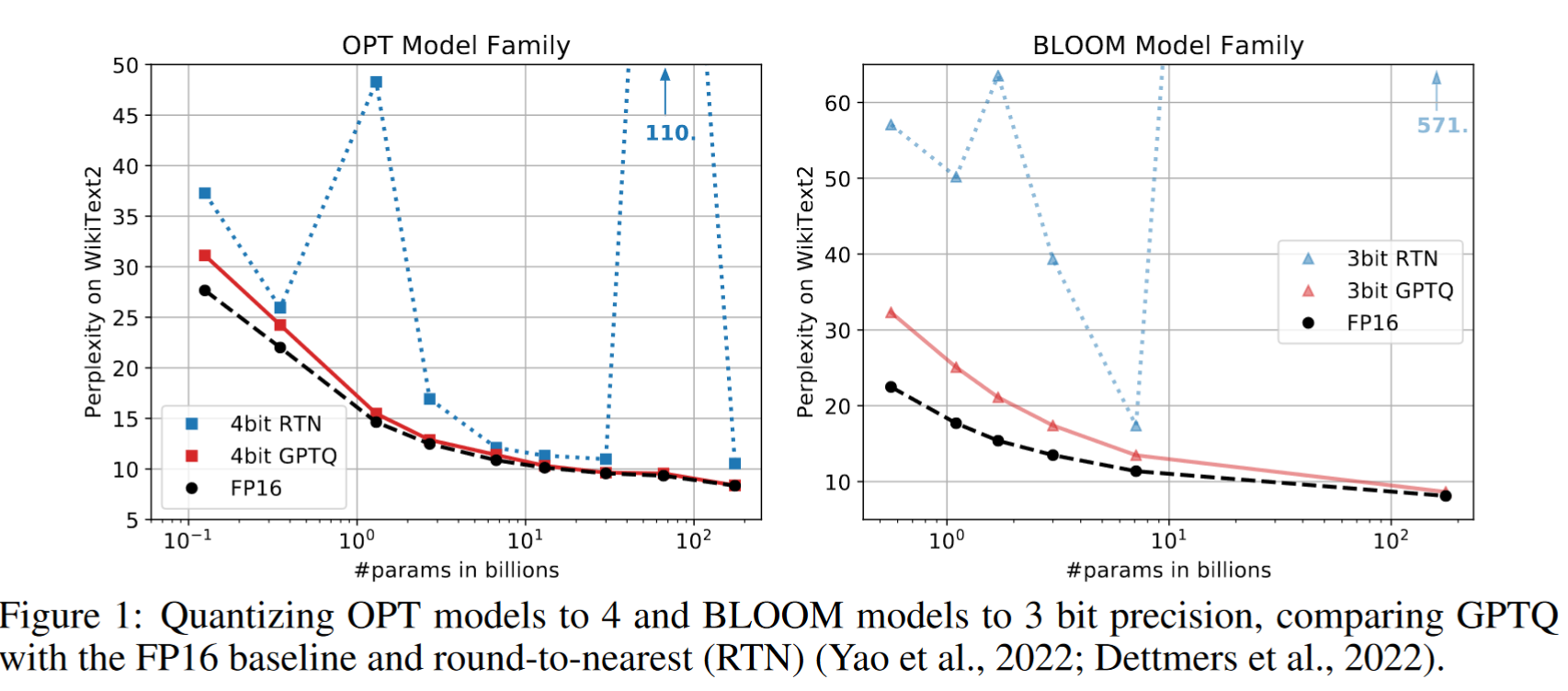
- 在 WikiText2 等语言生成任务上,GPTQ 量化的模型在 4 位和 3 位精度下的表现优于现有的量化方法(如最近邻量化 RTN)。
- 实现了在单个 NVIDIA A100 GPU 上运行 175 亿参数模型的端到端推理,速度提升约为 3.25 倍(使用高端 GPU)和 4.5 倍(使用成本效益更高的 GPU)。
改进方向:
- 硬件支持: 当前方法主要通过减少内存移动来获得速度提升,并未直接减少计算量。未来的工作可以探索更先进的硬件支持,如混合精度操作(例如 FP16 x INT4)。
- 激活量化: 目前的研究未考虑激活量化,这可能是未来工作的一个方向。
- 更细粒度的量化: 通过更细粒度的量化策略,如分组量化,可能进一步提高模型的压缩率和性能。
背景与相关工作
-
量化方法主要分为训练期间量化和训练后量化两大类。训练期间量化在模型训练或微调期间进行量化,而训练后量化则在预训练模型上进行一次性量化。
-
训练后量化方法特别适用于大规模模型,因为重新训练或微调的成本非常高。
-
更复杂的低位宽量化或模型剪枝的方法通常需要重新训练模型,这对于十亿参数的模型来说是极其昂贵的,所以 GPT 这类模型很少这样量化
-
大多数训练后的方法都集中在视觉模型上。通常,精确的方法通过量化单个层或连续层的小块来操作
-
AdaRound 方法通过退火一个惩罚项来计算与数据相关的舍入,它鼓励权重向量化级别对应的网格点移动
-
Bit Split 使用残差平方误差目标逐位构造量化值
-
AdaQuant 基于直通估计进行直接优化
-
BRECQ ( Li et al , 2021)在目标中引入 Fisher 信息,联合优化单个残差块内的层
-
Optimal Brain Quantization,OBQ 推广了经典的 Optimal Brain Surgeon,OBS 二阶权重剪枝框架应用于量化,OBQ 对权值进行逐个量化,按照量化误差的大小顺序,不断调整剩余权值
虽然这些方法可以在几个 GPU 小时内对高达 1 亿个参数的模型产生很好的结果,但将它们扩展到更大数量级的网络是很有挑战性的。
-
方法理论

-
层级量化: GPTQ 按层进行量化,为每层解决相应的重构问题,目标是找到量化权重矩阵,使得相对于全精度层输出的平方误差最小化。
-
最优脑量化 (OBQ): GPTQ 基于最近提出的 OBQ 方法,对其进行了重大修改,使其能够扩展到大型语言模型,并提供了三个数量级的计算加速。

任意顺序洞察(Arbitrary Order Insight):
- OBQ(Optimal Brain Quantization)方法按特定顺序量化权重,但 GPTQ 发现,任意固定顺序的量化也能表现良好,尤其是在大型、高度参数化的层中。这是因为量化误差的累积效应在量化过程的后期会减少。
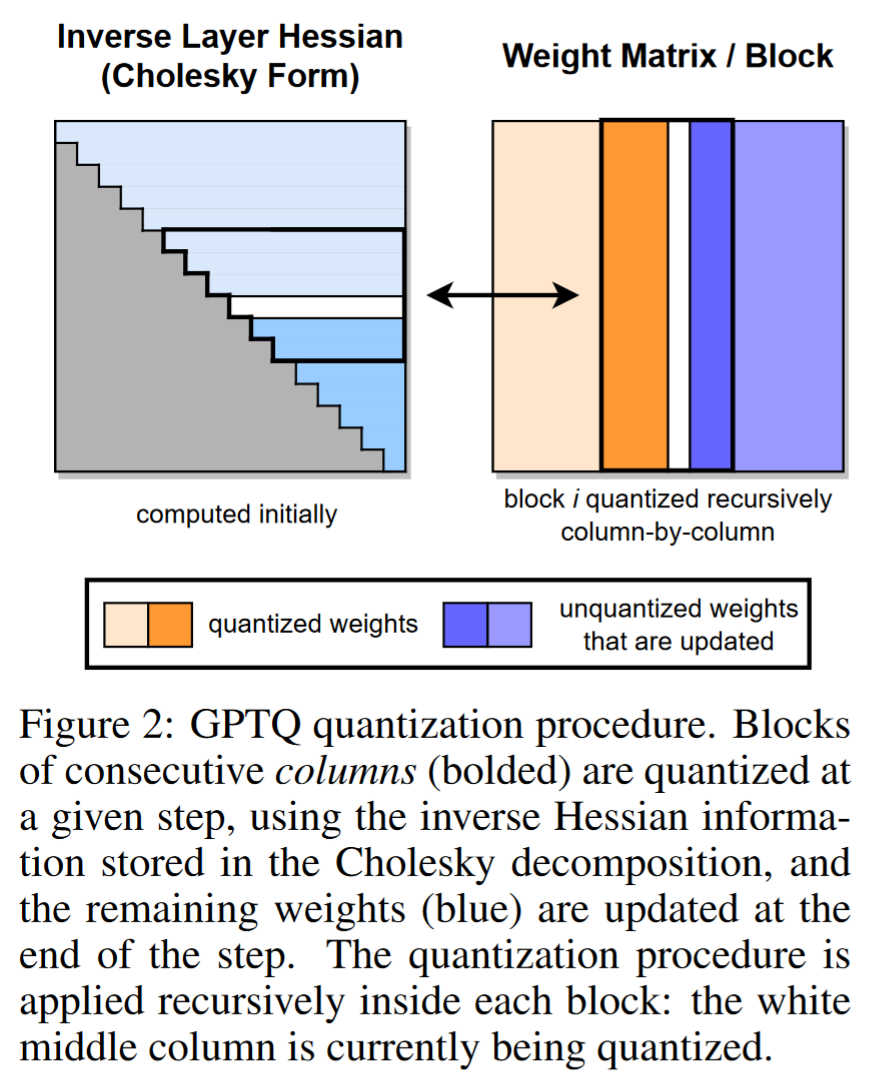
逆层 Hessian(Inverse Layer Hessian):
- GPTQ 量化连续列块的权重,使用存储在 Cholesky 分解中的逆 Hessian 信息,并在步骤结束时更新剩余权重。
延迟批量更新(Lazy Batch-Updates):
-
为了解决直接实现的计算与内存访问比率较低的问题,GPTQ 采用延迟批量更新策略。这意味着只有当一个块完全处理完毕后,才会对整个 Hessian 矩阵进行全局更新。
该策略虽然没有降低理论计算量,但有效地解决了内存吞吐量瓶颈问题。这对于实际中非常大的模型提供了一个数量级的加速比,使其成为我们算法的关键组成部分。
Cholesky 重构(Cholesky Reformulation):
- 为了解决数值不准确性问题,GPTQ 使用 Cholesky 分解预先计算所有需要的 Hessian 信息,并通过轻微的阻尼来增强数值稳定性。
实验工作
- 模型压缩: 在 OPT 和 BLOOM 模型家族上进行了 2/3/4 位的压缩。
- 语言生成任务: 在 WikiText2、Penn Treebank 和 C4 数据集上评估了量化模型的困惑度。
- 零样本任务: 在 LAMBIDA、ARC 和 PIQA 等零样本任务上评估了量化模型的性能。
- 实际速度提升: 在 NVIDIA A100 和 A6000 GPU 上进行了生成任务的端到端推理速度测试。
- Title: ML-paper-GPTQ
- Author: Charles
- Created at : 2024-07-27 09:35:21
- Updated at : 2024-07-29 14:38:06
- Link: https://charles2530.github.io/2024/07/27/ml-paper-gptq/
- License: This work is licensed under CC BY-NC-SA 4.0.


