
扩散模型:视频与多模态扩散:视频不是把图片多画几帧
图像扩散只要生成一个静态样本,视频扩散要生成一段会动的样本。这个变化看起来只是多了时间轴,实际会把训练、架构、条件控制和评测全部变复杂。
这篇只回答一个问题:为什么视频扩散不能简单照搬图像扩散,现代视频生成系统又是靠哪些接口把质量、运动和成本一起撑住?
视频扩散的核心不是“每帧都好看”,而是同时满足五件事:视频压缩器不能先丢掉运动,时空主干要能交换跨帧信息,条件要贯穿整段视频,采样路径要能在可接受步数内稳定生成,评测要把画质、运动、身份、条件和长时一致性拆开看。
视频比图像多出来的不是一维坐标
把一段视频记成:
是帧数, 是分辨率,最后的 3 是 RGB 通道。图像扩散处理的是一个 网格;视频扩散处理的是 个相互依赖的网格。难点不是张量多一维,而是每一帧都必须和前后帧解释同一个世界。
一个人从画面左边走到右边,模型要同时维持衣服、脸、手、背景透视、镜头运动和步态节奏。若逐帧单独生成,单帧可能都清楚,但连起来会闪烁、变脸、漂移或滑行。这就是视频扩散比图像扩散困难的起点。
训练目标仍然可以像图像扩散那样写成噪声预测:
是真实视频或视频 latent, 是加入的噪声, 是噪声时间, 是文本、首帧、音频、姿态、轨迹或动作等条件。和图像不同的是, 不能只理解单帧纹理,它必须在带噪视频里读出时空关系:谁在动、怎么动、镜头怎么变、条件是否还在生效。
第一接口:视频 tokenizer 决定后端能看见什么
现代高分辨率视频扩散几乎不会直接在像素上做完整扩散,而是先把视频压进 latent 空间:
这里 是压缩后的视频 latent, 是压缩后的时间和空间尺寸, 是 latent 通道数。压缩的好处是 token 数下降,DiT 或 U-Net 才能处理更长、更高分辨率的视频。代价是:如果 tokenizer 先把细小运动、接触、口型、手指或身份细节压没了,后面的生成主干很难凭空补回来。
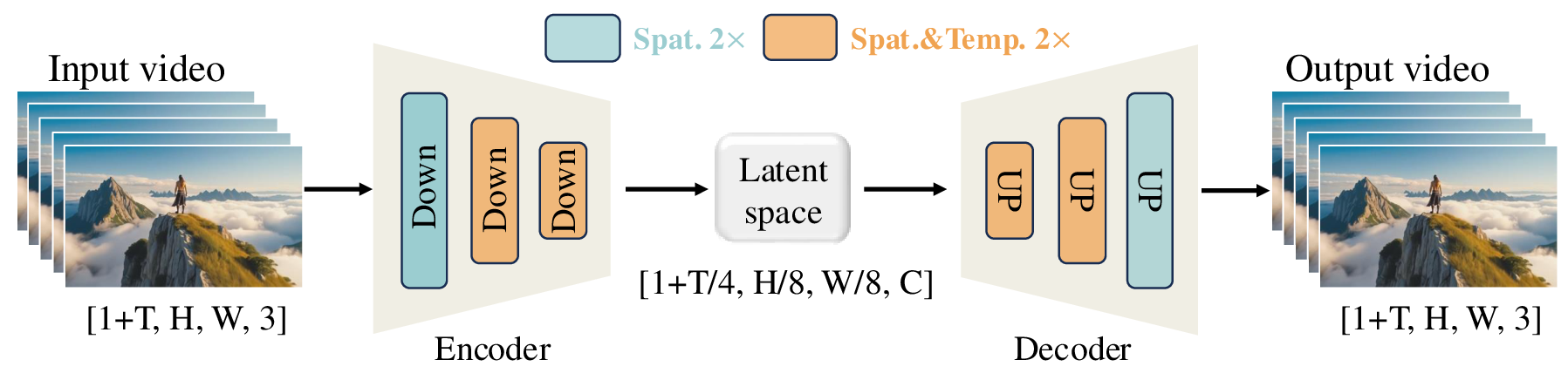
图源:Wan: Open and Advanced Large-Scale Video Generative Models,Figure 4。原图展示 Wan-VAE 如何把输入视频压到时空 latent,再解码回视频。本站读法:先看橙色时空压缩块和蓝色空间压缩块;视频 tokenizer 不是逐帧图像 VAE,而是在时间和空间上共同决定后端模型能看见什么。
这张图最重要的是中间 latent 的形状:Wan-VAE 把视频压成 这类更短的时空表示。时间压缩让训练成本下降,但也带来风险:压缩率越激进,越容易丢掉短时接触、快速运动和细微表情。视频论文里的 VAE 重建指标、时空压缩率、chunk cache、因果性和首帧处理,不是附录小事,而是质量地基。
因此读视频模型时,第一问应该是:它的 tokenizer 在时间上压了多少,第一帧是否特殊处理,重建是否只看单帧清晰度,还是也检查跨帧一致性。
第二接口:时空主干要决定谁和谁交换信息
视频 denoiser 可以用 3D U-Net、分解式时空注意力、Video DiT,或者这些结构的组合。它们本质上都在回答同一个问题:一个 token 在去噪时能不能读到前后帧里和自己相关的信息。
如果把所有视频 token 一次性做 full self-attention,token 数 ,复杂度接近 。帧数和分辨率稍微上去就很难承受。分解式时空注意力把它拆成两类:
spatial attention 主要看一帧内部的物体、布局和关系;temporal attention 主要看同一位置或相关位置随时间怎样变化。这种拆法省计算,也让图像模型的空间能力更容易迁移到视频里。
但它有一个不明显的坑:同一个物体在视频里会移动。若 temporal attention 只沿固定空间格子看时间,遇到大幅相机运动、人物跑动、遮挡再出现时,“同一个对象”已经不在同一个格子里。实际系统常要靠 3D RoPE、cross-frame attention、窗口移动、轨迹条件、全局层或更强的 DiT 来补。
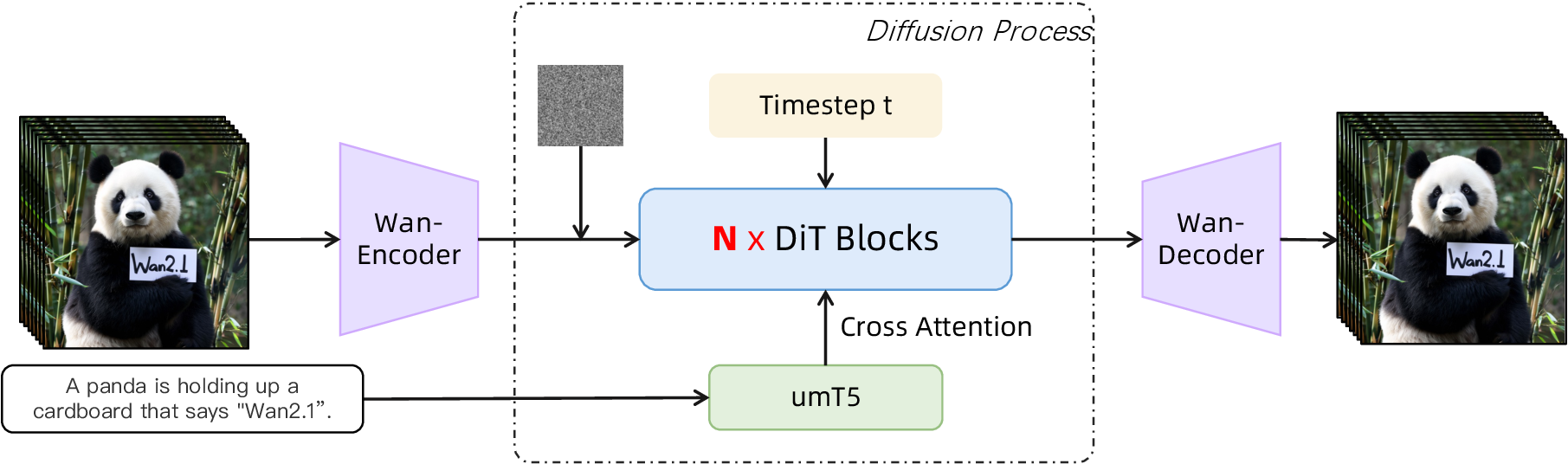
图源:Wan,Figure 5。原图展示 Wan-VAE、Video DiT、timestep 和文本编码器如何组成视频扩散系统。本站读法:左边 VAE 决定 latent 输入,中间 DiT blocks 负责时空去噪,底部文本通过 cross-attention 持续影响整段视频。
这张图把现代视频生成的主干关系讲得很清楚:视频不是先逐帧画完再补运动,而是在 video latent 上让 DiT 同时处理空间布局、时间运动和条件信息。文本条件也不是只给第一帧用;如果 cross-attention 或条件调度弱,视频后半段会 prompt drift,开头符合描述,后面逐渐跑题。
第三接口:条件不是标签,而是整段视频的控制信号
视频扩散里的条件 比图像复杂得多。文本控制对象、动作、场景和镜头;首帧控制身份和初始外观;姿态、深度、边缘、轨迹或相机路径控制结构;音频控制节奏、口型或环境声;动作条件则把视频生成接到世界模型和机器人策略。
最容易误解的是:条件不是一个“额外标签”。它必须在每个噪声时间、每个视频片段、每个空间区域里都能继续影响生成。否则模型会出现三类典型失败。
| 条件类型 | 应该约束什么 | 常见失败 |
|---|---|---|
| 文本 | 对象、动作、顺序、镜头、风格 | 开头对,后面漂;动作词被弱化 |
| 首帧/参考图 | 身份、外观、布局 | 主体变脸、衣服颜色漂、背景重画 |
| 姿态/轨迹/相机 | 空间结构和运动路径 | 路径不跟、人物滑行、镜头不稳 |
| 音频 | 节奏、口型、声画关系 | 口型不同步、动作节奏错 |
| 动作/控制 | 不同动作导致不同未来 | 视频好看但 action insensitive |
对于内容生成,条件漂移是观感问题;对于世界模型和机器人,这会变成因果问题。如果同一段历史视频在不同动作条件下生成出几乎一样的未来,画面再清晰也不能用于规划。
第四接口:Flow、少步蒸馏和视频成本是绑在一起的
视频扩散每一步都比图像贵,因为每次 forward 都要处理一段时空 latent。若一个模型需要 50 步,生成 5 秒、10 秒视频的成本很快不可接受。于是现代视频模型越来越常见三件事:latent video tokenizer 降 token 数,Flow Matching / velocity 目标让采样路径更适合 ODE,DMD/Consistency/AnyFlow/CausVid 这类后训练把步数继续压低。
Flow Matching 风格下,模型常被写成预测速度场:
是当前带噪 video latent, 是连续时间, 是条件, 是模型预测的生成方向。这里的 velocity 不是画面里人物的物理速度,而是 latent 样本从噪声流向干净视频时应该移动的方向。
采样器用少数步积分这条 ODE:
如果路径平滑、速度场稳定、时间网格覆盖了关键噪声区间,少步就可能可用;如果高噪声阶段没有建立大结构,或低噪声阶段没有补细节,少步视频会变慢、变钝、动作幅度下降、身份更容易漂。
这也是为什么视频少步蒸馏不能只看“4 steps 还能出视频”。要特别看 motion bucket:主体是否真的在动,镜头是否按 prompt 运动,动作幅度有没有被压小,长视频是否越滚越保守。
Sora、Wan 和视频世界模型的边界
OpenAI 的 Sora 把视频生成称为 world simulators,这个说法有启发,但不能直接等同于可闭环控制的世界模型。视频生成模型可以学到丰富的物理、相机和场景先验;但如果没有动作条件、因果 rollout、状态记忆、风险事件评测和闭环决策接口,它仍然主要是 open-loop 生成器。
Wan 的价值更像一个开放的视频 foundation model 配方:视频 VAE / tokenizer、Video DiT、Flow Matching 目标、多任务数据、T2V/I2V/编辑接口和分布式训练系统放在一起。它说明现代视频扩散不是单一网络,而是一套互相牵制的系统。
可以把关系分成三层:
| 层级 | 主要任务 | 需要证明什么 |
|---|---|---|
| 视频生成器 | 给文本/图像生成自然视频 | 画质、运动、身份、prompt alignment |
| 视频世界先验 | 预测 plausible future | 长时一致性、事件变化、条件敏感性 |
| 可交互世界模型 | 给不同动作生成不同后果 | action sensitivity、closed-loop utility、风险召回 |
因此,读 Sora、Wan、CausVid、Diffusion Forcing、DreamZero、LingBot-World 这类工作时,不要只问视频是否漂亮。更重要的问题是:它有没有因果接口,动作是否真的改变未来,少步后是否还保留风险事件,评测是否从 open-loop 走到了 closed-loop。
多模态扩散的共同点
扩散思想也用于语音、音乐、3D、机器人动作、蛋白质和科学建模。它们的共同点不是“都能加噪声”,而是目标空间往往多峰、连续、带复杂约束。逐步去噪或速度场生成给了模型一个从简单分布走到复杂分布的路径。
机器人里的 Diffusion Policy 就是一个典型例子:它不是生成图片,而是生成动作序列 。训练形式可以写成:
是加噪后的动作轨迹, 是观察、语言或目标条件。它和视频扩散共享“序列、多模态、多解”的建模困难,但评测对象不同:视频看时序质量和条件对齐,动作策略看任务成功率、碰撞、安全和闭环恢复。
这类连接应作为边界,而不是把所有多模态扩散塞进一篇文章。本站后续讲 VLA 和策略学习时,会专门讨论动作扩散为什么能表达多模态动作分布。
评测不能只看清晰度
视频评测最危险的是被 demo 欺骗。清晰样例可以掩盖运动变慢、身份漂移、条件丢失和长尾失败。更稳的报告要拆桶。
| 评测桶 | 关注点 | 常见指标或检查 |
|---|---|---|
| 单帧质量 | 清晰度、纹理、人物/物体细节 | 人评、FID/FVD 的图像侧信号 |
| 时间一致性 | 闪烁、身份保持、背景稳定 | VBench temporal quality、人评回放 |
| 运动合理性 | 步态、相机、接触、速度变化 | motion smoothness、dynamic degree、人工分桶 |
| 条件遵循 | prompt、首帧、姿态、音频、动作 | text alignment、I2V consistency、控制误差 |
| 长时稳定 | 事件顺序、漂移、滚动生成退化 | 长视频分段评测、prefix consistency |
| 部署成本 | 步数、首帧延迟、吞吐、显存 | NFE、P50/P95 latency、peak memory |
VBench 这类 benchmark 有价值,因为它把视频质量拆成多个维度,而不是只给一个总分。但自动指标仍不能替代人评和任务评测。尤其是世界模型或机器人场景,open-loop 视频自然度不能直接推出 closed-loop utility。
读完以后怎么判断
视频与多模态扩散可以按五句话记:
- 视频扩散的难点不是多画几帧,而是同一个世界要在时间上自洽。
- 视频 tokenizer 决定后端模型能否看见运动、身份和细节。
- 时空主干必须同时处理空间布局、跨帧运动和条件持续注入。
- Flow / velocity 目标和少步蒸馏降低视频生成成本,但会放大运动、细节和条件失败。
- 视频生成器、视频世界先验和可交互世界模型是三层不同要求,不能只靠漂亮 demo 混在一起。
继续读相邻内容时,可以接 一致性模型与 Rectified Flow、一步生成、蒸馏与整流、Wan2.1 专题讲解、CausVid 论文精读 和 Diffusion Policy / 动作策略学习。
外部精读
- Video Diffusion Models:看图像扩散如何扩展到 space-time U-Net。
- Latent Video Diffusion Models:理解为什么高分辨率视频生成需要 latent 空间。
- Lumiere:理解一次性生成完整时长视频和 Space-Time U-Net 的取舍。
- Sora technical report:把视频生成和世界模拟器关系放在一起读,但要保守区分 open-loop 和 closed-loop。
- Wan technical report:看现代开源视频基础模型如何组织 VAE、Video DiT、Flow Matching、多任务和系统训练。
- VBench:理解视频生成评测为什么必须拆 temporal quality、motion、alignment 等维度。
- Diffusion Policy:理解扩散思想怎样迁移到动作序列生成。
- Title: 扩散模型:视频与多模态扩散:视频不是把图片多画几帧
- Author: Charles
- Created at : 2025-05-18 09:00:00
- Updated at : 2025-05-18 09:00:00
- Link: https://charles2530.github.io/2025/05/18/ai-files-diffusion-video-and-multimodal-diffusion/
- License: This work is licensed under CC BY-NC-SA 4.0.